Oracle Solaris Cluster Concepts Guide • May 2011, Revision a Contents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Updating Systems and Adding Software in Oracle® Solaris 11.4
Updating Systems and Adding Software ® in Oracle Solaris 11.4 Part No: E60979 November 2020 Updating Systems and Adding Software in Oracle Solaris 11.4 Part No: E60979 Copyright © 2007, 2020, Oracle and/or its affiliates. License Restrictions Warranty/Consequential Damages Disclaimer This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. Warranty Disclaimer The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. Restricted Rights Notice If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial -

Solaris 10 End of Life
Solaris 10 end of life Continue Oracle Solaris 10 has had an amazing OS update, including ground features such as zones (Solaris containers), FSS, Services, Dynamic Tracking (against live production operating systems without impact), and logical domains. These features have been imitated in the market (imitation is the best form of flattery!) like all good things, they have to come to an end. Sun Microsystems was acquired by Oracle and eventually, the largest OS known to the industry, needs to be updated. Oracle has set a retirement date of January 2021. Oracle indicated that Solaris 10 systems would need to raise support costs. Oracle has never provided migratory tools to facilitate migration from Solaris 10 to Solaris 11, so migration to Solaris has been slow. In September 2019, Oracle decided that extended support for Solaris 10 without an additional financial penalty would be delayed until 2024! Well its March 1 is just a reminder that Oracle Solaris 10 is getting the end of life regarding support if you accept extended support from Oracle. Combined with the fact gdpR should take effect on May 25, 2018 you want to make sure that you are either upgraded to Solaris 11.3 or have taken extended support to obtain any patches for security issues. For more information on tanningix releases and support dates of old and new follow this link ×Sestive to abort the Unix Error Operating System originally developed by Sun Microsystems SolarisDeveloperSun Microsystems (acquired by Oracle Corporation in 2009)Written inC, C'OSUnixWorking StateCurrentSource ModelMixedInitial release1992; 28 years ago (1992-06)Last release11.4 / August 28, 2018; 2 years ago (2018-08-28)Marketing targetServer, PlatformsCurrent: SPARC, x86-64 Former: IA-32, PowerPCKernel typeMonolithic with dynamically downloadable modulesDefault user interface GNOME-2-LicenseVariousOfficial websitewww.oracle.com/solaris Solaris is the own operating system Of Unix, originally developed by Sunsystems. -

Solaris-Cluster-Businesscontinuity-168285.Pdf
An Oracle White Paper September 2010 Oracle Solaris and Oracle Solaris Cluster: Extending Oracle Solaris for Business Continuity Oracle White Paper— Oracle Solaris and Oracle Solaris Cluster: Extending Oracle Solaris for Business Continuity Executive Summary.............................................................................1 Introduction..........................................................................................3 Traditional Solution Components ....................................................5 Oracle Solaris Cluster for Business Continuity....................................6 Oracle Solaris Cluster......................................................................6 Introduction—Basic Clustering ........................................................8 Data Availability .............................................................................10 Applications Availability .................................................................11 Network Availability .......................................................................12 Virtualization and Oracle Solaris Cluster .......................................13 Disaster Recovery—Campus and Beyond ....................................16 A Single HA and DR Solution for Multitier Oracle Applications and Databases ..........................................................17 Oracle Solaris ....................................................................................19 Resource Management .................................................................19 -

Wdd-Ebook.Pdf
The illumos Writing Device Drivers Sun Microsystems, Inc. has intellectual property rights relating to technology embodied in the product that is described in this document. In particular, and without limitation, these intellectual property rights may include one or more U.S. patents or pending patent applications in the U.S. and in other countries. U.S. Government Rights – Commercial software. Government users are subject to the Sun Microsystems, Inc. standard license agreement and applicable provisions of the FAR and its supplements. This distribution may include materials developed by third parties. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, the Solaris logo, the Java Coffee Cup logo, docs.sun.com, Java, and Solaris are trademarks or registered trademarks of Sun Microsystems, Inc. or its subsidiaries in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. Sun holds a non-exclusive license from Xerox to the Xerox Graphical User Interface, which license also covers Sun’s licensees who implement OPEN LOOK GUIs and otherwise comply with Sun’s written license agreements. -

Oracle Solaris and Veritas Cluster
Oracle Solaris and Veritas Cluster An Easy-build Guide Vijay Shankar Upreti Oracle Solaris and Veritas Cluster: An Easy-build Guide Copyright © 2016 by Vijay Shankar Upreti This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. Exempted from this legal reservation are brief excerpts in connection with reviews or scholarly analysis or material supplied specifically for the purpose of being entered and executed on a computer system, for exclusive use by the purchaser of the work. Duplication of this publication or parts thereof is permitted only under the provisions of the Copyright Law of the Publisher’s location, in its current version, and permission for use must always be obtained from Springer. Permissions for use may be obtained through RightsLink at the Copyright Clearance Center. Violations are liable to prosecution under the respective Copyright Law. ISBN-13 (pbk): 978-1-4842-1832-7 ISBN-13 (electronic): 978-1-4842-1833-4 Trademarked names, logos, and images may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, logo, or image we use the names, logos, and images only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. -

Deploying Highly Available Zones with Solaris Cluster 3.2
Deploying highly available zones with Solaris Cluster 3.2 http://prefetch.net/blog/index.php/2009/04/10/deploying-high... BLOG O’ MATTY HOME BLOG HOME ARTICLES CODE PRESENTATIONS Deploying highly available zones with Solaris Cluster 3.2 Recommended Books I discussed my first impressions of Solaris Cluster 3.2 a while back, and have been using it in various capacities ever since. One thing that I really like about Solaris Cluster is its ability to manage resources running in zones, and fail these resources over to other zones running on the same host, or a zone running on a secondary host. Additionally, Solaris Cluster allows you to migrate zones between nodes, which can be quite handy when resources are tied to a zone and can’t be managed as a scalable services. Configuring zone failover is a piece of cake, and I will describe how to do it in this blog post. To get failover working, you will first need to download and install Solaris Cluster 3.2. You can grab the binaries from sun.com, and you can install them using the installer script that comes in the zip file: $ unzip suncluster_3_2u2-ga-solaris-x86.zip $ cd Solaris_x86 $ ./installer Once you run through the installer, the binaries should be placed in /usr/cluster, and you should be ready to configure the cluster. Prior to doing so, you should add something similar to the following to /etc/profile to make life easier for cluster administrators: PATH=/bin:/usr/bin:/sbin:/usr/sbin:/usr/sfw/bin:/usr/cluster/bin export PATH TERM=vt100 export TERM Also, if you selected the disabled remote services option during the Solaris install, you should reconfigure the rpc/bind service to allow connections from other cluster members (Solaris Cluster uses RPC extensively for cluster communications). -

High Availability for Business-Critical IT Services Using Oracle's SPARC
An Oracle White Paper April 2011 High Availability for Business-Critical IT Services Using Oracle’s SPARC Enterprise M-Series Servers Oracle White Paper— High Availability for Business-Critical IT Services Using Oracle’s SPARC Enterprise M-Series Servers Executive Overview ............................................................................ 1 Introduction ......................................................................................... 1 Oracle’s Comprehensive Approach to Availability .............................. 4 Systems with Mainframe-Class Reliability ...................................... 4 Training and Professional Services ................................................ 5 Process Automation ........................................................................ 5 Minimizing Planned Downtime ............................................................ 5 Dynamic Domains ........................................................................... 6 Online Reconfiguration, Maintenance, and Upgrades .................... 9 Reducing Unplanned Downtime ....................................................... 11 Built-in Hardware Redundancy ..................................................... 11 Configuring Additional System Redundancy................................. 16 Advanced Reliability Features ...................................................... 18 Additional Error Detection, Diagnosis, and Recovery Features .... 24 Maximizing IT Service Stability ......................................................... 26 Oracle -

Red Hat Enterprise Linux: Your Solaris Alternative
RED HAT ENTERPRISE LINUX: YOUR SOLARIS ALTERNATIVE 2 INTRODUCTION 3 FACTORS THAT INFLUENCE OPERATING SYSTEM CHOICE New projects Mandated migration 4 BUSINESS REQUIREMENTS TO CONSIDER Strength of ISV support Application migration considerations Performance Availability and scalability Security 11 TOTAL COST OF OWNERSHIP (TCO) Feature of comparison 13 DETAILED COMPARISON OF SELECTED FEATURES Filesystems and volume managers: Ext3, Ext4, XFS vs. UFS and ZFS DTrace vs SystemTap Software management 18 CONCLUSION Platform support Customer value www.redhat.com Red Hat Enterprise Linux: Your Solaris Alternative INTRODUCTION There were two primary reasons that IT professionals previously chose the Oracle Sun SPARC platform to power their IT infrastructures: the performance of the hardware and the robustness of the Solaris operating system. As the price, performance, and reliability of industry-standard x86_64 servers have increased to the point where they can meet and exceed these features, the reasons to continue buying SPARC hardware have become less and less compelling. This is particularly true with with large, multi-core x86 systems that are designed specifically for Linux©, such as the latest 128-core systems. Similarly, Linux, and in particular, Red Hat© Enterprise Linux, have emerged as the operating system of choice to leverage the benefits of open, industry-standard architectures. Selecting an operating system for your IT infrastructure has long-term consequences. The selection process must take into account not only the technical features of the current operating system, but the ability for the operating system to enable and support your future business requirements. While Oracle has quelled some worry over their commitment to Solaris, the move to Solaris 11 will likely be as painful as the move from Solaris 8/9 to Solaris 10, as Solaris 11 is significantly different from Solaris 10. -

Oracle® Solaris Cluster Data Service for Mysql Guide
® Oracle Solaris Cluster Data Service for MySQL Guide Part No: E69331 October 2019 Oracle Solaris Cluster Data Service for MySQL Guide Part No: E69331 Copyright © 2000, 2019, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. -

Hochverfügbarkeit Von Anwendungen Mit Oracle Solaris Cluster
<Insert Picture Here> Hochverfügbarkeit von Anwendungen mit Oracle Solaris Cluster Hartmut Streppel Principal Sales Consultant Oracle Deutschland SAFE HARBOR STATEMENT The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described for Oracle’s products remains at the sole discretion of Oracle. In addition, the following is intended to provide information for Oracle and Sun as we continue to combine the operations worldwide. Each country will complete its integration in accordance with local laws and requirements. In the EU and other non-EU countries with similar requirements, the combinations of local Oracle and Sun entities as well as other relevant changes during the transition phase will be conducted in accordance with and subject to the information and consultation requirements of applicable local laws, EU Directives and their implementation in the individual members states. Sun customers and partners should continue to engage with their Sun contacts for assistance for Sun products and their Oracle contacts for Oracle products. 3 Agenda • Oracle Solaris Cluster • Cluster-Agenten • Generic Data Service (GDS) • Zusammenfassung Oracle Solaris Cluster Keeps Data Centers Running 24x7 • Höchste Verfügbarkeit durch Hardware-Redundanz -
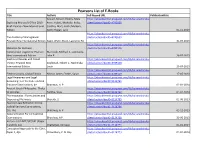
Pearsons List of E-Books
Pearsons List of E-Books Title Authors Full Record URL PublicationDate Grauer, Robert; Poatsy, Mary https://ebookcentral.proquest.com/lib/banarashinduu Exploring Microsoft Office 2010 Anne; Hulett, Michelle; Krebs, /detail.action?docID=4742025 Brief: Pearson New International Cynthia; Mast, Keith; Mulbery, Edition Keith; Hogan, Lynn 01-11-2013 https://ebookcentral.proquest.com/lib/banarashinduu The Anatomy Coloring Book: /detail.action?docID=4742630 Pearson New International Edition Kapit, Wynn; Elson, Lawrence M. 31-07-2013 https://ebookcentral.proquest.com/lib/banarashinduu Materials for Civil and /detail.action?docID=4789156 Construction Engineers: Pearson Mamlouk, Michael S.; Zaniewski, New International Edition John P. 26-07-2013 Electronic Devices and Circuit https://ebookcentral.proquest.com/lib/banarashinduu Theory: Pearson New Boylestad, Robert L.; Nashelsky, /detail.action?docID=4789158 International Edition Louis 23-07-2013 https://ebookcentral.proquest.com/lib/banarashinduu Electric Circuits, Global Edition Nilsson James; Riedel, Susan /detail.action?docID=4789159 17-05-2013 Legal Awareness and Legal https://ebookcentral.proquest.com/lib/banarashinduu Reasoning : For the CLAT and LLB /detail.action?docID=5124761 Entrance Examinations, 4e Bhardwaj, A. P. 01-01-2014 Ancient Greek Philosophy : Thales https://ebookcentral.proquest.com/lib/banarashinduu to Socrates Tankha, Vijay /detail.action?docID=5124762 01-01-2014 Pharmaceutics : Formulations and https://ebookcentral.proquest.com/lib/banarashinduu Dispensing Pharmacy Bharath, S. /detail.action?docID=5124765 01-06-2013 Pearson Legal Refresher for the https://ebookcentral.proquest.com/lib/banarashinduu Judicial Services Examinations, /detail.action?docID=5124766 2/e, The Bhardwaj, A. P. 01-12-2013 General English For Competitive https://ebookcentral.proquest.com/lib/banarashinduu Examinations Bhardwaj, A.P. -

Managing ZFS File Systems in Oracle® Solaris 11.4
® Managing ZFS File Systems in Oracle Solaris 11.4 Part No: E61017 February 2021 Managing ZFS File Systems in Oracle Solaris 11.4 Part No: E61017 Copyright © 2006, 2021, Oracle and/or its affiliates. License Restrictions Warranty/Consequential Damages Disclaimer This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. Warranty Disclaimer The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. Restricted Rights Notice If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or