Real-Time Detection for Cache Side Channel Attack Using Performance Counter Monitor
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Memory Hierarchy Memory Hierarchy
Memory Key challenge in modern computer architecture Lecture 2: different memory no point in blindingly fast computation if data can’t be and variable types moved in and out fast enough need lots of memory for big applications Prof. Mike Giles very fast memory is also very expensive [email protected] end up being pushed towards a hierarchical design Oxford University Mathematical Institute Oxford e-Research Centre Lecture 2 – p. 1 Lecture 2 – p. 2 CPU Memory Hierarchy Memory Hierarchy Execution speed relies on exploiting data locality 2 – 8 GB Main memory 1GHz DDR3 temporal locality: a data item just accessed is likely to be used again in the near future, so keep it in the cache ? 200+ cycle access, 20-30GB/s spatial locality: neighbouring data is also likely to be 6 used soon, so load them into the cache at the same 2–6MB time using a ‘wide’ bus (like a multi-lane motorway) L3 Cache 2GHz SRAM ??25-35 cycle access 66 This wide bus is only way to get high bandwidth to slow 32KB + 256KB main memory ? L1/L2 Cache faster 3GHz SRAM more expensive ??? 6665-12 cycle access smaller registers Lecture 2 – p. 3 Lecture 2 – p. 4 Caches Importance of Locality The cache line is the basic unit of data transfer; Typical workstation: typical size is 64 bytes 8 8-byte items. ≡ × 10 Gflops CPU 20 GB/s memory L2 cache bandwidth With a single cache, when the CPU loads data into a ←→ 64 bytes/line register: it looks for line in cache 20GB/s 300M line/s 2.4G double/s ≡ ≡ if there (hit), it gets data At worst, each flop requires 2 inputs and has 1 output, if not (miss), it gets entire line from main memory, forcing loading of 3 lines = 100 Mflops displacing an existing line in cache (usually least ⇒ recently used) If all 8 variables/line are used, then this increases to 800 Mflops. -

Nina Koennemann Bann They Come from Behind the Wall: the So-Called Smokers. Nina Koennemann Observes Them As If They Were the La
Films & Windows I-IV 07.06. - 25.08. 2012 Films & Windows (IV) Nina Koennemann & Flame Opening Reception: 09.08.2012 / 19.00 - 22.00 CET Nina Koennemann Bann They come from behind the wall: the so-called smokers. Nina Koennemann observes them as if they were the last - or newly discovered - specimens of their kind. Their shoes, their lair, the way in which they separate ash from ember and how they dispose of waste. The traces that they leave behind in the cityscape; a cityscape in which they them- selves appear only in traces. A granite block and a film frame, in which visible and invisible dividing lines of the various quadrants, zones and outskirts overlap each other, forming the city as a semi-transparent area. The era of the cigarette, which began with the rise of industrial production and mass consumption, their ordering of time into brief intervals-the length of a smoke-is shown here entering its last phase. The semi-worldliness of smoking, last bound to bars and juke joints, finds the reverberation of a waking dream in the reflections of people, their body parts and passenger cars in the granite surface. This can mean the bisection of the world in the exact doubling of the material factors, or it's interpreted as a means of escape, an extension of space. -Katha Schulte Flame In May 2012 over a thousand computers in countries in the Middle East were infected by Flame malware. The virus is the latest in a series of cyberweapons (following Stuxnet in 2010, Duqu in 2011 and Mahdi in February 2012) and, because of its large and expensive scale, is speculated to be designed by governments for espionage purposes rather than hacker or cybercriminal activity. -

Binary Counter
Systems I: Computer Organization and Architecture Lecture 8: Registers and Counters Registers • A register is a group of flip-flops. – Each flip-flop stores one bit of data; n flip-flops are required to store n bits of data. – There are several different types of registers available commercially. – The simplest design is a register consisting only of flip- flops, with no other gates in the circuit. • Loading the register – transfer of new data into the register. • The flip-flops share a common clock pulse (frequently using a buffer to reduce power requirements). • Output could be sampled at any time. • Clearing the flip-flop (placing zeroes in all its bit) can be done through a special terminal on the flip-flop. 1 4-bit Register I0 D Q A0 Clock C I1 D Q A1 C I D Q 2 A2 C D Q A I3 3 C Clear Registers With Parallel Load • The clock usually provides a steady stream of pulses which are applied to all flip-flops in the system. • A separate control system is needed to determine when to load a particular register. • The Register with Parallel Load has a separate load input. – When it is cleared, the register receives it output as input. – When it is set, it received the load input. 2 4-bit Register With Parallel Load Load D Q A0 I0 C D Q A1 C I1 D Q A2 I2 C D Q A3 I3 C Clock Shift Registers • A shift register is a register which can shift its data in one or both directions. -

Make the Most out of Last Level Cache in Intel Processors In: Proceedings of the Fourteenth Eurosys Conference (Eurosys'19), Dresden, Germany, 25-28 March 2019
http://www.diva-portal.org Postprint This is the accepted version of a paper presented at EuroSys'19. Citation for the original published paper: Farshin, A., Roozbeh, A., Maguire Jr., G Q., Kostic, D. (2019) Make the Most out of Last Level Cache in Intel Processors In: Proceedings of the Fourteenth EuroSys Conference (EuroSys'19), Dresden, Germany, 25-28 March 2019. ACM Digital Library N.B. When citing this work, cite the original published paper. Permanent link to this version: http://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-244750 Make the Most out of Last Level Cache in Intel Processors Alireza Farshin∗† Amir Roozbeh∗ KTH Royal Institute of Technology KTH Royal Institute of Technology [email protected] Ericsson Research [email protected] Gerald Q. Maguire Jr. Dejan Kostić KTH Royal Institute of Technology KTH Royal Institute of Technology [email protected] [email protected] Abstract between Central Processing Unit (CPU) and Direct Random In modern (Intel) processors, Last Level Cache (LLC) is Access Memory (DRAM) speeds has been increasing. One divided into multiple slices and an undocumented hashing means to mitigate this problem is better utilization of cache algorithm (aka Complex Addressing) maps different parts memory (a faster, but smaller memory closer to the CPU) in of memory address space among these slices to increase order to reduce the number of DRAM accesses. the effective memory bandwidth. After a careful study This cache memory becomes even more valuable due to of Intel’s Complex Addressing, we introduce a slice- the explosion of data and the advent of hundred gigabit per aware memory management scheme, wherein frequently second networks (100/200/400 Gbps) [9]. -

Migration from IBM 750FX to MPC7447A by Douglas Hamilton European Applications Engineering Networking and Computing Systems Group Freescale Semiconductor, Inc
Freescale Semiconductor AN2808 Application Note Rev. 1, 06/2005 Migration from IBM 750FX to MPC7447A by Douglas Hamilton European Applications Engineering Networking and Computing Systems Group Freescale Semiconductor, Inc. Contents 1 Scope and Definitions 1. Scope and Definitions . 1 2. Feature Overview . 2 The purpose of this application note is to facilitate migration 3. 7447A Specific Features . 12 from IBM’s 750FX-based systems to Freescale’s 4. Programming Model . 16 MPC7447A. It addresses the differences between the 5. Hardware Considerations . 27 systems, explaining which features have changed and why, 6. Revision History . 30 before discussing the impact on migration in terms of hardware and software. Throughout this document the following references are used: • 750FX—which applies to Freescale’s MPC750, MPC740, MPC755, and MPC745 devices, as well as to IBM’s 750FX devices. Any features specific to IBM’s 750FX will be explicitly stated as such. • MPC7447A—which applies to Freescale’s MPC7450 family of products (MPC7450, MPC7451, MPC7441, MPC7455, MPC7445, MPC7457, MPC7447, and MPC7447A) except where otherwise stated. Because this document is to aid the migration from 750FX, which does not support L3 cache, the L3 cache features of the MPC745x devices are not mentioned. © Freescale Semiconductor, Inc., 2005. All rights reserved. Feature Overview 2 Feature Overview There are many differences between the 750FX and the MPC7447A devices, beyond the clear differences of the core complex. This section covers the differences between the cores and then other areas of interest including the cache configuration and system interfaces. 2.1 Cores The key processing elements of the G3 core complex used in the 750FX are shown below in Figure 1, and the G4 complex used in the 7447A is shown in Figure 2. -

Cross Architectural Power Modelling
Cross Architectural Power Modelling Kai Chen1, Peter Kilpatrick1, Dimitrios S. Nikolopoulos2, and Blesson Varghese1 1Queen’s University Belfast, UK; 2Virginia Tech, USA E-mail: [email protected]; [email protected]; [email protected]; [email protected] Abstract—Existing power modelling research focuses on the processor are extensively explored using a cumbersome trial model rather than the process for developing models. An auto- and error approach after which a suitable few are selected [7]. mated power modelling process that can be deployed on different Such an approach does not easily scale for various processor processors for developing power models with high accuracy is developed. For this, (i) an automated hardware performance architectures since a different set of hardware counters will be counter selection method that selects counters best correlated to required to model power for each processor. power on both ARM and Intel processors, (ii) a noise filter based Currently, there is little research that develops automated on clustering that can reduce the mean error in power models, and (iii) a two stage power model that surmounts challenges in methods for selecting hardware counters to capture proces- using existing power models across multiple architectures are sor power over multiple processor architectures. Automated proposed and developed. The key results are: (i) the automated methods are required for easily building power models for a hardware performance counter selection method achieves compa- collection of heterogeneous processors as seen in traditional rable selection to the manual method reported in the literature, data centers that host multiple generations of server proces- (ii) the noise filter reduces the mean error in power models by up to 55%, and (iii) the two stage power model can predict sors, or in emerging distributed computing environments like dynamic power with less than 8% error on both ARM and Intel fog/edge computing [8] and mobile cloud computing (in these processors, which is an improvement over classic models. -

Caches & Memory
Caches & Memory Hakim Weatherspoon CS 3410 Computer Science Cornell University [Weatherspoon, Bala, Bracy, McKee, and Sirer] Programs 101 C Code RISC-V Assembly int main (int argc, char* argv[ ]) { main: addi sp,sp,-48 int i; sw x1,44(sp) int m = n; sw fp,40(sp) int sum = 0; move fp,sp sw x10,-36(fp) for (i = 1; i <= m; i++) { sw x11,-40(fp) sum += i; la x15,n } lw x15,0(x15) printf (“...”, n, sum); sw x15,-28(fp) } sw x0,-24(fp) li x15,1 sw x15,-20(fp) Load/Store Architectures: L2: lw x14,-20(fp) lw x15,-28(fp) • Read data from memory blt x15,x14,L3 (put in registers) . • Manipulate it .Instructions that read from • Store it back to memory or write to memory… 2 Programs 101 C Code RISC-V Assembly int main (int argc, char* argv[ ]) { main: addi sp,sp,-48 int i; sw ra,44(sp) int m = n; sw fp,40(sp) int sum = 0; move fp,sp sw a0,-36(fp) for (i = 1; i <= m; i++) { sw a1,-40(fp) sum += i; la a5,n } lw a5,0(x15) printf (“...”, n, sum); sw a5,-28(fp) } sw x0,-24(fp) li a5,1 sw a5,-20(fp) Load/Store Architectures: L2: lw a4,-20(fp) lw a5,-28(fp) • Read data from memory blt a5,a4,L3 (put in registers) . • Manipulate it .Instructions that read from • Store it back to memory or write to memory… 3 1 Cycle Per Stage: the Biggest Lie (So Far) Code Stored in Memory (also, data and stack) compute jump/branch targets A memory register ALU D D file B +4 addr PC B control din dout M inst memory extend new imm forward pc Stack, Data, Code detect unit hazard Stored in Memory Instruction Instruction Write- ctrl ctrl ctrl Fetch Decode Execute Memory Back IF/ID -

Experiment No
1 LIST OF EXPERIMENTS 1. Study of logic gates. 2. Design and implementation of adders and subtractors using logic gates. 3. Design and implementation of code converters using logic gates. 4. Design and implementation of 4-bit binary adder/subtractor and BCD adder using IC 7483. 5. Design and implementation of 2-bit magnitude comparator using logic gates, 8- bit magnitude comparator using IC 7485. 6. Design and implementation of 16-bit odd/even parity checker/ generator using IC 74180. 7. Design and implementation of multiplexer and demultiplexer using logic gates and study of IC 74150 and IC 74154. 8. Design and implementation of encoder and decoder using logic gates and study of IC 7445 and IC 74147. 9. Construction and verification of 4-bit ripple counter and Mod-10/Mod-12 ripple counter. 10. Design and implementation of 3-bit synchronous up/down counter. 11. Implementation of SISO, SIPO, PISO and PIPO shift registers using flip-flops. KCTCET/2016-17/Odd/3rd/ETE/CSE/LM 2 EXPERIMENT NO. 01 STUDY OF LOGIC GATES AIM: To study about logic gates and verify their truth tables. APPARATUS REQUIRED: SL No. COMPONENT SPECIFICATION QTY 1. AND GATE IC 7408 1 2. OR GATE IC 7432 1 3. NOT GATE IC 7404 1 4. NAND GATE 2 I/P IC 7400 1 5. NOR GATE IC 7402 1 6. X-OR GATE IC 7486 1 7. NAND GATE 3 I/P IC 7410 1 8. IC TRAINER KIT - 1 9. PATCH CORD - 14 THEORY: Circuit that takes the logical decision and the process are called logic gates. -

Stealing the Shared Cache for Fun and Profit
IT 13 048 Examensarbete 30 hp Juli 2013 Stealing the shared cache for fun and profit Moncef Mechri Institutionen för informationsteknologi Department of Information Technology Abstract Stealing the shared cache for fun and profit Moncef Mechri Teknisk- naturvetenskaplig fakultet UTH-enheten Cache pirating is a low-overhead method created by the Uppsala Architecture Besöksadress: Research Team (UART) to analyze the Ångströmlaboratoriet Lägerhyddsvägen 1 effect of sharing a CPU cache Hus 4, Plan 0 among several cores. The cache pirate is a program that will actively and Postadress: carefully steal a part of the shared Box 536 751 21 Uppsala cache by keeping its working set in it. The target application can then be Telefon: benchmarked to see its dependency on 018 – 471 30 03 the available shared cache capacity. The Telefax: topic of this Master Thesis project 018 – 471 30 00 is to implement a cache pirate and use it on Ericsson’s systems. Hemsida: http://www.teknat.uu.se/student Handledare: Erik Berg Ämnesgranskare: David Black-Schaffer Examinator: Ivan Christoff IT 13 048 Sponsor: Ericsson Tryckt av: Reprocentralen ITC Contents Acronyms 2 1 Introduction 3 2 Background information 5 2.1 A dive into modern processors . 5 2.1.1 Memory hierarchy . 5 2.1.2 Virtual memory . 6 2.1.3 CPU caches . 8 2.1.4 Benchmarking the memory hierarchy . 13 3 The Cache Pirate 17 3.1 Monitoring the Pirate . 18 3.1.1 The original approach . 19 3.1.2 Defeating prefetching . 19 3.1.3 Timing . 20 3.2 Stealing evenly from every set . -
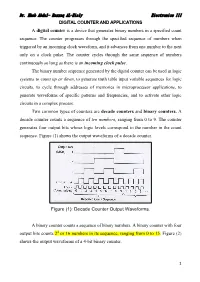
1 DIGITAL COUNTER and APPLICATIONS a Digital Counter Is
Dr. Ehab Abdul- Razzaq AL-Hialy Electronics III DIGITAL COUNTER AND APPLICATIONS A digital counter is a device that generates binary numbers in a specified count sequence. The counter progresses through the specified sequence of numbers when triggered by an incoming clock waveform, and it advances from one number to the next only on a clock pulse. The counter cycles through the same sequence of numbers continuously so long as there is an incoming clock pulse. The binary number sequence generated by the digital counter can be used in logic systems to count up or down, to generate truth table input variable sequences for logic circuits, to cycle through addresses of memories in microprocessor applications, to generate waveforms of specific patterns and frequencies, and to activate other logic circuits in a complex process. Two common types of counters are decade counters and binary counters. A decade counter counts a sequence of ten numbers, ranging from 0 to 9. The counter generates four output bits whose logic levels correspond to the number in the count sequence. Figure (1) shows the output waveforms of a decade counter. Figure (1): Decade Counter Output Waveforms. A binary counter counts a sequence of binary numbers. A binary counter with four output bits counts 24 or 16 numbers in its sequence, ranging from 0 to 15. Figure (2) shows-the output waveforms of a 4-bit binary counter. 1 Dr. Ehab Abdul- Razzaq AL-Hialy Electronics III Figure (2): Binary Counter Output Waveforms. EXAMPLE (1): Decade Counter. Problem: Determine the 4-bit decade counter output that corresponds to the waveforms shown in Figure (1). -

IBM Power Systems Performance Report Apr 13, 2021
IBM Power Performance Report Power7 to Power10 September 8, 2021 Table of Contents 3 Introduction to Performance of IBM UNIX, IBM i, and Linux Operating System Servers 4 Section 1 – SPEC® CPU Benchmark Performance 4 Section 1a – Linux Multi-user SPEC® CPU2017 Performance (Power10) 4 Section 1b – Linux Multi-user SPEC® CPU2017 Performance (Power9) 4 Section 1c – AIX Multi-user SPEC® CPU2006 Performance (Power7, Power7+, Power8) 5 Section 1d – Linux Multi-user SPEC® CPU2006 Performance (Power7, Power7+, Power8) 6 Section 2 – AIX Multi-user Performance (rPerf) 6 Section 2a – AIX Multi-user Performance (Power8, Power9 and Power10) 9 Section 2b – AIX Multi-user Performance (Power9) in Non-default Processor Power Mode Setting 9 Section 2c – AIX Multi-user Performance (Power7 and Power7+) 13 Section 2d – AIX Capacity Upgrade on Demand Relative Performance Guidelines (Power8) 15 Section 2e – AIX Capacity Upgrade on Demand Relative Performance Guidelines (Power7 and Power7+) 20 Section 3 – CPW Benchmark Performance 19 Section 3a – CPW Benchmark Performance (Power8, Power9 and Power10) 22 Section 3b – CPW Benchmark Performance (Power7 and Power7+) 25 Section 4 – SPECjbb®2015 Benchmark Performance 25 Section 4a – SPECjbb®2015 Benchmark Performance (Power9) 25 Section 4b – SPECjbb®2015 Benchmark Performance (Power8) 25 Section 5 – AIX SAP® Standard Application Benchmark Performance 25 Section 5a – SAP® Sales and Distribution (SD) 2-Tier – AIX (Power7 to Power8) 26 Section 5b – SAP® Sales and Distribution (SD) 2-Tier – Linux on Power (Power7 to Power7+) -

A Survey on Smartphones Security: Software Vulnerabilities, Malware, and Attacks
(IJACSA) International Journal of Advanced Computer Science and Applications Vol. 8, No. 10, 2017 A Survey on Smartphones Security: Software Vulnerabilities, Malware, and Attacks Milad Taleby Ahvanooey*, Prof. Qianmu Li*, Mahdi Rabbani, Ahmed Raza Rajput School of Computer Science and Engineering, Nanjing University of Science and Technology, Nanjing, P.O. Box 210094 P.R. China. Abstract—Nowadays, the usage of smartphones and their desktop usage (desktop usage, web usage, overall is down to applications have become rapidly popular in people’s daily life. 44.9% in the first quarter of 2017). Further, based on the latest Over the last decade, availability of mobile money services such report released by Kaspersky on December 2016 [3], 36% of as mobile-payment systems and app markets have significantly online banking attacks have targeted Android devices and increased due to the different forms of apps and connectivity increased 8% compared to the year 2015. In all online banking provided by mobile devices, such as 3G, 4G, GPRS, and Wi-Fi, attacks in 2016, have been stolen more than $100 million etc. In the same trend, the number of vulnerabilities targeting around the world. Although Android OS becomes very popular these services and communication networks has raised as well. today, it is exposing more and more vulnerable encounter Therefore, smartphones have become ideal target devices for attacks due to having open-source software, thus everybody malicious programmers. With increasing the number of can develop apps freely. A malware writer (or developer) can vulnerabilities and attacks, there has been a corresponding ascent of the security countermeasures presented by the take advantage of these features to develop malicious apps.