A Cache Line Fill Circuit for a Micropipelined, Asynchronous Microprocessor
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Memory Hierarchy Memory Hierarchy
Memory Key challenge in modern computer architecture Lecture 2: different memory no point in blindingly fast computation if data can’t be and variable types moved in and out fast enough need lots of memory for big applications Prof. Mike Giles very fast memory is also very expensive [email protected] end up being pushed towards a hierarchical design Oxford University Mathematical Institute Oxford e-Research Centre Lecture 2 – p. 1 Lecture 2 – p. 2 CPU Memory Hierarchy Memory Hierarchy Execution speed relies on exploiting data locality 2 – 8 GB Main memory 1GHz DDR3 temporal locality: a data item just accessed is likely to be used again in the near future, so keep it in the cache ? 200+ cycle access, 20-30GB/s spatial locality: neighbouring data is also likely to be 6 used soon, so load them into the cache at the same 2–6MB time using a ‘wide’ bus (like a multi-lane motorway) L3 Cache 2GHz SRAM ??25-35 cycle access 66 This wide bus is only way to get high bandwidth to slow 32KB + 256KB main memory ? L1/L2 Cache faster 3GHz SRAM more expensive ??? 6665-12 cycle access smaller registers Lecture 2 – p. 3 Lecture 2 – p. 4 Caches Importance of Locality The cache line is the basic unit of data transfer; Typical workstation: typical size is 64 bytes 8 8-byte items. ≡ × 10 Gflops CPU 20 GB/s memory L2 cache bandwidth With a single cache, when the CPU loads data into a ←→ 64 bytes/line register: it looks for line in cache 20GB/s 300M line/s 2.4G double/s ≡ ≡ if there (hit), it gets data At worst, each flop requires 2 inputs and has 1 output, if not (miss), it gets entire line from main memory, forcing loading of 3 lines = 100 Mflops displacing an existing line in cache (usually least ⇒ recently used) If all 8 variables/line are used, then this increases to 800 Mflops. -

Make the Most out of Last Level Cache in Intel Processors In: Proceedings of the Fourteenth Eurosys Conference (Eurosys'19), Dresden, Germany, 25-28 March 2019
http://www.diva-portal.org Postprint This is the accepted version of a paper presented at EuroSys'19. Citation for the original published paper: Farshin, A., Roozbeh, A., Maguire Jr., G Q., Kostic, D. (2019) Make the Most out of Last Level Cache in Intel Processors In: Proceedings of the Fourteenth EuroSys Conference (EuroSys'19), Dresden, Germany, 25-28 March 2019. ACM Digital Library N.B. When citing this work, cite the original published paper. Permanent link to this version: http://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-244750 Make the Most out of Last Level Cache in Intel Processors Alireza Farshin∗† Amir Roozbeh∗ KTH Royal Institute of Technology KTH Royal Institute of Technology [email protected] Ericsson Research [email protected] Gerald Q. Maguire Jr. Dejan Kostić KTH Royal Institute of Technology KTH Royal Institute of Technology [email protected] [email protected] Abstract between Central Processing Unit (CPU) and Direct Random In modern (Intel) processors, Last Level Cache (LLC) is Access Memory (DRAM) speeds has been increasing. One divided into multiple slices and an undocumented hashing means to mitigate this problem is better utilization of cache algorithm (aka Complex Addressing) maps different parts memory (a faster, but smaller memory closer to the CPU) in of memory address space among these slices to increase order to reduce the number of DRAM accesses. the effective memory bandwidth. After a careful study This cache memory becomes even more valuable due to of Intel’s Complex Addressing, we introduce a slice- the explosion of data and the advent of hundred gigabit per aware memory management scheme, wherein frequently second networks (100/200/400 Gbps) [9]. -

Migration from IBM 750FX to MPC7447A by Douglas Hamilton European Applications Engineering Networking and Computing Systems Group Freescale Semiconductor, Inc
Freescale Semiconductor AN2808 Application Note Rev. 1, 06/2005 Migration from IBM 750FX to MPC7447A by Douglas Hamilton European Applications Engineering Networking and Computing Systems Group Freescale Semiconductor, Inc. Contents 1 Scope and Definitions 1. Scope and Definitions . 1 2. Feature Overview . 2 The purpose of this application note is to facilitate migration 3. 7447A Specific Features . 12 from IBM’s 750FX-based systems to Freescale’s 4. Programming Model . 16 MPC7447A. It addresses the differences between the 5. Hardware Considerations . 27 systems, explaining which features have changed and why, 6. Revision History . 30 before discussing the impact on migration in terms of hardware and software. Throughout this document the following references are used: • 750FX—which applies to Freescale’s MPC750, MPC740, MPC755, and MPC745 devices, as well as to IBM’s 750FX devices. Any features specific to IBM’s 750FX will be explicitly stated as such. • MPC7447A—which applies to Freescale’s MPC7450 family of products (MPC7450, MPC7451, MPC7441, MPC7455, MPC7445, MPC7457, MPC7447, and MPC7447A) except where otherwise stated. Because this document is to aid the migration from 750FX, which does not support L3 cache, the L3 cache features of the MPC745x devices are not mentioned. © Freescale Semiconductor, Inc., 2005. All rights reserved. Feature Overview 2 Feature Overview There are many differences between the 750FX and the MPC7447A devices, beyond the clear differences of the core complex. This section covers the differences between the cores and then other areas of interest including the cache configuration and system interfaces. 2.1 Cores The key processing elements of the G3 core complex used in the 750FX are shown below in Figure 1, and the G4 complex used in the 7447A is shown in Figure 2. -

Caches & Memory
Caches & Memory Hakim Weatherspoon CS 3410 Computer Science Cornell University [Weatherspoon, Bala, Bracy, McKee, and Sirer] Programs 101 C Code RISC-V Assembly int main (int argc, char* argv[ ]) { main: addi sp,sp,-48 int i; sw x1,44(sp) int m = n; sw fp,40(sp) int sum = 0; move fp,sp sw x10,-36(fp) for (i = 1; i <= m; i++) { sw x11,-40(fp) sum += i; la x15,n } lw x15,0(x15) printf (“...”, n, sum); sw x15,-28(fp) } sw x0,-24(fp) li x15,1 sw x15,-20(fp) Load/Store Architectures: L2: lw x14,-20(fp) lw x15,-28(fp) • Read data from memory blt x15,x14,L3 (put in registers) . • Manipulate it .Instructions that read from • Store it back to memory or write to memory… 2 Programs 101 C Code RISC-V Assembly int main (int argc, char* argv[ ]) { main: addi sp,sp,-48 int i; sw ra,44(sp) int m = n; sw fp,40(sp) int sum = 0; move fp,sp sw a0,-36(fp) for (i = 1; i <= m; i++) { sw a1,-40(fp) sum += i; la a5,n } lw a5,0(x15) printf (“...”, n, sum); sw a5,-28(fp) } sw x0,-24(fp) li a5,1 sw a5,-20(fp) Load/Store Architectures: L2: lw a4,-20(fp) lw a5,-28(fp) • Read data from memory blt a5,a4,L3 (put in registers) . • Manipulate it .Instructions that read from • Store it back to memory or write to memory… 3 1 Cycle Per Stage: the Biggest Lie (So Far) Code Stored in Memory (also, data and stack) compute jump/branch targets A memory register ALU D D file B +4 addr PC B control din dout M inst memory extend new imm forward pc Stack, Data, Code detect unit hazard Stored in Memory Instruction Instruction Write- ctrl ctrl ctrl Fetch Decode Execute Memory Back IF/ID -

Stealing the Shared Cache for Fun and Profit
IT 13 048 Examensarbete 30 hp Juli 2013 Stealing the shared cache for fun and profit Moncef Mechri Institutionen för informationsteknologi Department of Information Technology Abstract Stealing the shared cache for fun and profit Moncef Mechri Teknisk- naturvetenskaplig fakultet UTH-enheten Cache pirating is a low-overhead method created by the Uppsala Architecture Besöksadress: Research Team (UART) to analyze the Ångströmlaboratoriet Lägerhyddsvägen 1 effect of sharing a CPU cache Hus 4, Plan 0 among several cores. The cache pirate is a program that will actively and Postadress: carefully steal a part of the shared Box 536 751 21 Uppsala cache by keeping its working set in it. The target application can then be Telefon: benchmarked to see its dependency on 018 – 471 30 03 the available shared cache capacity. The Telefax: topic of this Master Thesis project 018 – 471 30 00 is to implement a cache pirate and use it on Ericsson’s systems. Hemsida: http://www.teknat.uu.se/student Handledare: Erik Berg Ämnesgranskare: David Black-Schaffer Examinator: Ivan Christoff IT 13 048 Sponsor: Ericsson Tryckt av: Reprocentralen ITC Contents Acronyms 2 1 Introduction 3 2 Background information 5 2.1 A dive into modern processors . 5 2.1.1 Memory hierarchy . 5 2.1.2 Virtual memory . 6 2.1.3 CPU caches . 8 2.1.4 Benchmarking the memory hierarchy . 13 3 The Cache Pirate 17 3.1 Monitoring the Pirate . 18 3.1.1 The original approach . 19 3.1.2 Defeating prefetching . 19 3.1.3 Timing . 20 3.2 Stealing evenly from every set . -

IBM Power Systems Performance Report Apr 13, 2021
IBM Power Performance Report Power7 to Power10 September 8, 2021 Table of Contents 3 Introduction to Performance of IBM UNIX, IBM i, and Linux Operating System Servers 4 Section 1 – SPEC® CPU Benchmark Performance 4 Section 1a – Linux Multi-user SPEC® CPU2017 Performance (Power10) 4 Section 1b – Linux Multi-user SPEC® CPU2017 Performance (Power9) 4 Section 1c – AIX Multi-user SPEC® CPU2006 Performance (Power7, Power7+, Power8) 5 Section 1d – Linux Multi-user SPEC® CPU2006 Performance (Power7, Power7+, Power8) 6 Section 2 – AIX Multi-user Performance (rPerf) 6 Section 2a – AIX Multi-user Performance (Power8, Power9 and Power10) 9 Section 2b – AIX Multi-user Performance (Power9) in Non-default Processor Power Mode Setting 9 Section 2c – AIX Multi-user Performance (Power7 and Power7+) 13 Section 2d – AIX Capacity Upgrade on Demand Relative Performance Guidelines (Power8) 15 Section 2e – AIX Capacity Upgrade on Demand Relative Performance Guidelines (Power7 and Power7+) 20 Section 3 – CPW Benchmark Performance 19 Section 3a – CPW Benchmark Performance (Power8, Power9 and Power10) 22 Section 3b – CPW Benchmark Performance (Power7 and Power7+) 25 Section 4 – SPECjbb®2015 Benchmark Performance 25 Section 4a – SPECjbb®2015 Benchmark Performance (Power9) 25 Section 4b – SPECjbb®2015 Benchmark Performance (Power8) 25 Section 5 – AIX SAP® Standard Application Benchmark Performance 25 Section 5a – SAP® Sales and Distribution (SD) 2-Tier – AIX (Power7 to Power8) 26 Section 5b – SAP® Sales and Distribution (SD) 2-Tier – Linux on Power (Power7 to Power7+) -

Cache & Memory System
COMP 212 Computer Organization & Architecture Re-Cap of Lecture #2 • The text book is required for the class – COMP 212 Fall 2008 You will need it for homework, project, review…etc. – To get it at a good price: Lecture 3 » Check with senior student for used book » Check with university book store Cache & Memory System » Try this website: addall.com » Anyone got the book ? Care to share experience ? Comp 212 Computer Org & Arch 1 Z. Li, 2008 Comp 212 Computer Org & Arch 2 Z. Li, 2008 Components & Connections Instruction – CPU: processing data • Instruction word has 2 parts – Mem: store data – Opcode: eg, 4 bit, will have total 24=16 different instructions – I/O & Network: exchange data with – Operand: address or immediate number an outside world instruction can operate on – Connection: Bus, a – In von Neumann computer, instruction and data broadcasting medium share the same memory space: – Address space: 2W for address width W. • eg, 8 bit has 28=256 addressable space, • 216=65536 addressable space (room number) Comp 212 Computer Org & Arch 3 Z. Li, 2008 Comp 212 Computer Org & Arch 4 Z. Li, 2008 Instruction Cycle Register & Memory Operations During Instruction Cycle • Instruction Cycle has 3 phases • Pay attention to the – Instruction fetch: following registers’ • pull instruction from mem to IR, according to PC change over cycles: • CPU can’t process memory data directly ! – Instruction execution: – PC, IR • Operate on the operand, either load or save data to – AC memory, or move data among registers, or ALU – Mem at [940], [941] operations – Interruption Handling: to achieve parallel operation with slower IO device • Sequential • Nested Comp 212 Computer Org & Arch 5 Z. -

Cache-Fair Thread Scheduling for Multicore Processors
Cache-Fair Thread Scheduling for Multicore Processors The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Fedorova, Alexandra, Margo Seltzer, and Michael D. Smith. 2006. Cache-Fair Thread Scheduling for Multicore Processors. Harvard Computer Science Group Technical Report TR-17-06. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:25686821 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Cache-Fair Thread Scheduling for Multicore Processors Alexandra Fedorova, Margo Seltzer and Michael D. Smith TR-17-06 Computer Science Group Harvard University Cambridge, Massachusetts Cache-Fair Thread Scheduling for Multicore Processors Alexandra Fedorova†‡, Margo Seltzer† and Michael D. Smith† †Harvard University, ‡Sun Microsystems ABSTRACT ensure that equal-priority threads get equal shares of We present a new operating system scheduling the CPU. On multicore processors a thread’s share of algorithm for multicore processors. Our algorithm the CPU, and thus its forward progress, is dependent reduces the effects of unequal CPU cache sharing that both upon its time slice and the cache behavior of its occur on these processors and cause unfair CPU co-runners. Kim et al showed that a SPEC CPU2000 sharing, priority inversion, and inadequate CPU [12] benchmark gzip runs 42% slower with a co-runner accounting. We describe the implementation of our art, than with apsi, even though gzip executes the same algorithm in the Solaris operating system and number of cycles in both cases [7]. -
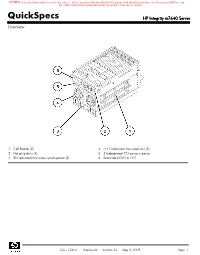
Quickspecs HP Integrity Rx7640 Server Overview
RETIRED: Retired products sold prior to the November 1, 2015 separation of Hewlett-Packard Company into Hewlett Packard Enterprise Company and HP Inc. may have older product names and model numbers that differ from current models. QuickSpecs HP Integrity rx7640 Server Overview 1. Cell Boards (2) 4. N+1 redundant hot-swap fans (2) 2. Hot-plug disks (4) 5. 2 Independent PCI power supplies 3. 2N redundant hot-swap system power (2) 6. Removable DVD or DAT DA - 12470 Worldwide — Version 25 — May 8, 2009 Page 1 RETIRED: Retired products sold prior to the November 1, 2015 separation of Hewlett-Packard Company into Hewlett Packard Enterprise Company and HP Inc. may have older product names and model numbers that differ from current models. QuickSpecs HP Integrity rx7640 Server Overview 1. N+1 PCI cooling fans 5. Dual-grid 2N redundant power inputs 2. System backplane (right side) 6. Hot-swap redundant fans 3. Core I/O 7. 15 Hot-plug PCI-X slots 4. Power cord retention bracket At A Glance HP Integrity rx7640 Server Product Number (base system) AB312A Standard System Features HP UX 11i v3 and HP UX 11i v2 operating system Microsoft Windows Server 2008 for Itanium-based systems Linux RHEL AS 5 and AS 4 and SLES 10 SP 1. Mad9M rx7640 configuration not supported. OpenVMS V8.3 1H1 or higher (for Montvale). Mad9M rx7640 configurations not supported. One External Ultra320 LVD SCSI channel (a second Ultra320 SCSI port is available if a Smart Array card is used to access internal disk drives) Four internal SCSI controllers Two GbE LAN ports (with auto -

Exploiting Cache Side Channels on CPU-FPGA Cloud Platforms
Exploiting Cache Side-Channels on CPU-FPGA Cloud Platforms Cache-basierte Seitenkanalangriffe auf CPU-FPGA Cloud Plattformen Masterarbeit im Rahmen des Studiengangs Informatik der Universität zu Lübeck vorgelegt von Thore Tiemann ausgegeben und betreut von Prof. Dr. Thomas Eisenbarth Lübeck, den 09. Januar 2020 Abstract Cloud service providers invest more and more in FPGA infrastructure to offer it to their customers (IaaS). FPGA use cases include the acceleration of artificial intelligence applica- tions. While physical attacks on FPGAs got a lot of attention by researchers just recently, nobody focused on micro-architectural attacks in the context of FPGA yet. We take the first step into this direction and investigate the timing behavior of memory reads on two Intel FPGA platforms that were designed to be used in a cloud environment: a Programmable Acceleration Card (PAC) and a Xeon CPU with an integrated FPGA that has an additional coherent local cache. By using the Open Programmable Acceleration Engine (OPAE) and the Core Cache Interface (CCI-P), our setup represents a realistic cloud scenario. We show that an Acceleration Functional Unit (AFU) on either platform can, with the help of a self-designed hardware timer, distinguish which of the different parts of the memory hierarchy serves the response for memory reads. On the integrated platform, the same is true for the CPU, as it can differentiate between answers from the FPGA cache, the CPU cache, and the main memory. Next, we analyze the effect of the caching hints offered by the CCI-P on the location of written cache lines in the memory hierarchy and show that most cache lines get cached in the LLC of the CPU. -

The Tradeoffs of Fused Memory Hierarchies in Heterogeneous Computing Architectures
The Tradeoffs of Fused Memory Hierarchies in Heterogeneous Computing Architectures Kyle Spafford Jeremy S. Meredith Seyong Lee Oak Ridge National Oak Ridge National Oak Ridge National Laboratory Laboratory Laboratory 1 Bethel Valley Road 1 Bethel Valley Road 1 Bethel Valley Road Oak Ridge, TN 37831 Oak Ridge, TN 37831 Oak Ridge, TN 37831 [email protected] [email protected] [email protected] Dong Li Philip C. Roth Jeffrey S. Vetter Oak Ridge National Oak Ridge National Oak Ridge National Laboratory Laboratory Laboratory 1 Bethel Valley Road 1 Bethel Valley Road 1 Bethel Valley Road Oak Ridge, TN 37831 Oak Ridge, TN 37831 Oak Ridge, TN 37831 [email protected] [email protected] [email protected] ABSTRACT 1. INTRODUCTION With the rise of general purpose computing on graphics pro- cessing units (GPGPU), the influence from consumer mar- 1.1 GPUs and Heterogeneity kets can now be seen across the spectrum of computer ar- chitectures. In fact, many of the high-ranking Top500 HPC The demand for flexibility in advanced computer graph- systems now include these accelerators. Traditionally, GPUs ics has caused the GPU to evolve from a highly specialized, have connected to the CPU via the PCIe bus, which has fixed-function pipeline to a more general processor. How- proved to be a significant bottleneck for scalable scientific ever, in its current form, there are still substantial differ- applications. Now, a trend toward tighter integration be- ences between the GPU and a traditional multi-core CPU. tween CPU and GPU has removed this bottleneck and uni- Perhaps the most salient difference is in the memory hier- fied the memory hierarchy for both CPU and GPU cores. -

Architectural Trade-Offs in a Latency Tolerant Gallium Arsenide Microprocessor
Architectural Trade-offs in a Latency Tolerant Gallium Arsenide Microprocessor by Michael D. Upton A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Electrical Engineering) in The University of Michigan 1996 Doctoral Committee: Associate Professor Richard B. Brown, CoChairperson Professor Trevor N. Mudge, CoChairperson Associate Professor Myron Campbell Professor Edward S. Davidson Professor Yale N. Patt © Michael D. Upton 1996 All Rights Reserved DEDICATION To Kelly, Without whose support this work may not have been started, would not have been enjoyed, and could not have been completed. Thank you for your continual support and encouragement. ii ACKNOWLEDGEMENTS Many people, both at Michigan and elsewhere, were instrumental in the completion of this work. I would like to thank my co-chairs, Richard Brown and Trevor Mudge, first for attracting me to Michigan, and then for allowing our group the freedom to explore many different ideas in architecture and circuit design. Their guidance and motivation combined to make this a truly memorable experience. I am also grateful to each of my other dissertation committee members: Ed Davidson, Yale Patt, and Myron Campbell. The support and encouragement of the other faculty on the project, Karem Sakallah and Ron Lomax, is also gratefully acknowledged. My friends and former colleagues Mark Rossman, Steve Sugiyama, Ray Farbarik, Tom Rossman and Kendall Russell were always willing to lend their assistance. Richard Oettel continually reminded me of the valuable support of friends and family, and the importance of having fun in your work. Our corporate sponsors: Cascade Design Automation, Chronologic, Cadence, and Metasoft, provided software and support that made this work possible.