Sorting and Asymptotic Complexity
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Batcher's Algorithm
18.310 lecture notes Fall 2010 Batcher’s Algorithm Prof. Michel Goemans Perhaps the most restrictive version of the sorting problem requires not only no motion of the keys beyond compare-and-switches, but also that the plan of comparison-and-switches be fixed in advance. In each of the methods mentioned so far, the comparison to be made at any time often depends upon the result of previous comparisons. For example, in HeapSort, it appears at first glance that we are making only compare-and-switches between pairs of keys, but the comparisons we perform are not fixed in advance. Indeed when fixing a headless heap, we move either to the left child or to the right child depending on which child had the largest element; this is not fixed in advance. A sorting network is a fixed collection of comparison-switches, so that all comparisons and switches are between keys at locations that have been specified from the beginning. These comparisons are not dependent on what has happened before. The corresponding sorting algorithm is said to be non-adaptive. We will describe a simple recursive non-adaptive sorting procedure, named Batcher’s Algorithm after its discoverer. It is simple and elegant but has the disadvantage that it requires on the order of n(log n)2 comparisons. which is larger by a factor of the order of log n than the theoretical lower bound for comparison sorting. For a long time (ten years is a long time in this subject!) nobody knew if one could find a sorting network better than this one. -

Sorting Algorithms Correcness, Complexity and Other Properties
Sorting Algorithms Correcness, Complexity and other Properties Joshua Knowles School of Computer Science The University of Manchester COMP26912 - Week 9 LF17, April 1 2011 The Importance of Sorting Important because • Fundamental to organizing data • Principles of good algorithm design (correctness and efficiency) can be appreciated in the methods developed for this simple (to state) task. Sorting Algorithms 2 LF17, April 1 2011 Every algorithms book has a large section on Sorting... Sorting Algorithms 3 LF17, April 1 2011 ...On the Other Hand • Progress in computer speed and memory has reduced the practical importance of (further developments in) sorting • quicksort() is often an adequate answer in many applications However, you still need to know your way (a little) around the the key sorting algorithms Sorting Algorithms 4 LF17, April 1 2011 Overview What you should learn about sorting (what is examinable) • Definition of sorting. Correctness of sorting algorithms • How the following work: Bubble sort, Insertion sort, Selection sort, Quicksort, Merge sort, Heap sort, Bucket sort, Radix sort • Main properties of those algorithms • How to reason about complexity — worst case and special cases Covered in: the course book; labs; this lecture; wikipedia; wider reading Sorting Algorithms 5 LF17, April 1 2011 Relevant Pages of the Course Book Selection sort: 97 (very short description only) Insertion sort: 98 (very short) Merge sort: 219–224 (pages on multi-way merge not needed) Heap sort: 100–106 and 107–111 Quicksort: 234–238 Bucket sort: 241–242 Radix sort: 242–243 Lower bound on sorting 239–240 Practical issues, 244 Some of the exercise on pp. -

Advanced Topics in Sorting
Advanced Topics in Sorting complexity system sorts duplicate keys comparators 1 complexity system sorts duplicate keys comparators 2 Complexity of sorting Computational complexity. Framework to study efficiency of algorithms for solving a particular problem X. Machine model. Focus on fundamental operations. Upper bound. Cost guarantee provided by some algorithm for X. Lower bound. Proven limit on cost guarantee of any algorithm for X. Optimal algorithm. Algorithm with best cost guarantee for X. lower bound ~ upper bound Example: sorting. • Machine model = # comparisons access information only through compares • Upper bound = N lg N from mergesort. • Lower bound ? 3 Decision Tree a < b yes no code between comparisons (e.g., sequence of exchanges) b < c a < c yes no yes no a b c b a c a < c b < c yes no yes no a c b c a b b c a c b a 4 Comparison-based lower bound for sorting Theorem. Any comparison based sorting algorithm must use more than N lg N - 1.44 N comparisons in the worst-case. Pf. Assume input consists of N distinct values a through a . • 1 N • Worst case dictated by tree height h. N ! different orderings. • • (At least) one leaf corresponds to each ordering. Binary tree with N ! leaves cannot have height less than lg (N!) • h lg N! lg (N / e) N Stirling's formula = N lg N - N lg e N lg N - 1.44 N 5 Complexity of sorting Upper bound. Cost guarantee provided by some algorithm for X. Lower bound. Proven limit on cost guarantee of any algorithm for X. -

Sorting Algorithm 1 Sorting Algorithm
Sorting algorithm 1 Sorting algorithm In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order. Efficient sorting is important for optimizing the use of other algorithms (such as search and merge algorithms) that require sorted lists to work correctly; it is also often useful for canonicalizing data and for producing human-readable output. More formally, the output must satisfy two conditions: 1. The output is in nondecreasing order (each element is no smaller than the previous element according to the desired total order); 2. The output is a permutation, or reordering, of the input. Since the dawn of computing, the sorting problem has attracted a great deal of research, perhaps due to the complexity of solving it efficiently despite its simple, familiar statement. For example, bubble sort was analyzed as early as 1956.[1] Although many consider it a solved problem, useful new sorting algorithms are still being invented (for example, library sort was first published in 2004). Sorting algorithms are prevalent in introductory computer science classes, where the abundance of algorithms for the problem provides a gentle introduction to a variety of core algorithm concepts, such as big O notation, divide and conquer algorithms, data structures, randomized algorithms, best, worst and average case analysis, time-space tradeoffs, and lower bounds. Classification Sorting algorithms used in computer science are often classified by: • Computational complexity (worst, average and best behaviour) of element comparisons in terms of the size of the list . For typical sorting algorithms good behavior is and bad behavior is . -

How to Sort out Your Life in O(N) Time
How to sort out your life in O(n) time arel Číže @kaja47K funkcionaklne.cz I said, "Kiss me, you're beautiful - These are truly the last days" Godspeed You! Black Emperor, The Dead Flag Blues Everyone, deep in their hearts, is waiting for the end of the world to come. Haruki Murakami, 1Q84 ... Free lunch 1965 – 2022 Cramming More Components onto Integrated Circuits http://www.cs.utexas.edu/~fussell/courses/cs352h/papers/moore.pdf He pays his staff in junk. William S. Burroughs, Naked Lunch Sorting? quicksort and chill HS 1964 QS 1959 MS 1945 RS 1887 quicksort, mergesort, heapsort, radix sort, multi- way merge sort, samplesort, insertion sort, selection sort, library sort, counting sort, bucketsort, bitonic merge sort, Batcher odd-even sort, odd–even transposition sort, radix quick sort, radix merge sort*, burst sort binary search tree, B-tree, R-tree, VP tree, trie, log-structured merge tree, skip list, YOLO tree* vs. hashing Robin Hood hashing https://cs.uwaterloo.ca/research/tr/1986/CS-86-14.pdf xs.sorted.take(k) (take (sort xs) k) qsort(lotOfIntegers) It may be the wrong decision, but fuck it, it's mine. (Mark Z. Danielewski, House of Leaves) I tell you, my man, this is the American Dream in action! We’d be fools not to ride this strange torpedo all the way out to the end. (HST, FALILV) Linear time sorting? I owe the discovery of Uqbar to the conjunction of a mirror and an Encyclopedia. (Jorge Luis Borges, Tlön, Uqbar, Orbis Tertius) Sorting out graph processing https://github.com/frankmcsherry/blog/blob/master/posts/2015-08-15.md Radix Sort Revisited http://www.codercorner.com/RadixSortRevisited.htm Sketchy radix sort https://github.com/kaja47/sketches (thinking|drinking|WTF)* I know they accuse me of arrogance, and perhaps misanthropy, and perhaps of madness. -

Sorting Algorithm 1 Sorting Algorithm
Sorting algorithm 1 Sorting algorithm A sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order. Efficient sorting is important for optimizing the use of other algorithms (such as search and merge algorithms) which require input data to be in sorted lists; it is also often useful for canonicalizing data and for producing human-readable output. More formally, the output must satisfy two conditions: 1. The output is in nondecreasing order (each element is no smaller than the previous element according to the desired total order); 2. The output is a permutation (reordering) of the input. Since the dawn of computing, the sorting problem has attracted a great deal of research, perhaps due to the complexity of solving it efficiently despite its simple, familiar statement. For example, bubble sort was analyzed as early as 1956.[1] Although many consider it a solved problem, useful new sorting algorithms are still being invented (for example, library sort was first published in 2006). Sorting algorithms are prevalent in introductory computer science classes, where the abundance of algorithms for the problem provides a gentle introduction to a variety of core algorithm concepts, such as big O notation, divide and conquer algorithms, data structures, randomized algorithms, best, worst and average case analysis, time-space tradeoffs, and upper and lower bounds. Classification Sorting algorithms are often classified by: • Computational complexity (worst, average and best behavior) of element comparisons in terms of the size of the list (n). For typical serial sorting algorithms good behavior is O(n log n), with parallel sort in O(log2 n), and bad behavior is O(n2). -

BOTTOM-UP-HEAPSORT, a New Variant of HEAPSORT Beating, on an Average, QUICKSORT (If N Is Not Very Small)
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Theoretical Computer Science 118 (1993) 81-98 81 Elsevier BOTTOM-UP-HEAPSORT, a new variant of HEAPSORT beating, on an average, QUICKSORT (if n is not very small) Ingo Wegener* FB Informatik. LS II. Universitiit Dortmund, Postfach 500500, 4600 Dortmund 50, Germany Abstract Wegener, I., BOTTOM-UP-HEAPSORT, a new variant of HEAPSORT beating, on an average, QUICKSORT (if n is not very small), Theoretical Computer Science 118 (1993) 81-98. A variant of HEAPSORT, called BOTTOM-UP-HEAPSORT, is presented. It is based on a new reheap procedure. This sequential sorting algorithm is easy to implement and beats, on an average, QUICKSORT if n 2400 and a clever version of QUICKSORT (where the split object is the median of 3 randomly chosen objects) if n> 16000. The worst-case number of comparisons is bounded by 1.5n log n + O(n). Moreover, the new reheap procedure improves the delete procedure for the heap data structure for all n. 1. Introduction Sorting is one of the most fundamental problems in computer science. In this paper, only general (excluding BUCKETSORT) sequential sorting algorithms are studied. In Section 2 a short review of the long history of efficient sequential sorting algorithms is given. The QUICKSORT variant where the split object is the median of three random objects is, on an average, the most efficient known algorithm for internal sorting. The new algorithm will be compared with this strong competi- tor, called CLEVER QUICKSORT. -

A Comparative Study of Sorting Algorithms with FPGA Acceleration by High Level Synthesis
A Comparative Study of Sorting Algorithms with FPGA Acceleration by High Level Synthesis Yomna Ben Jmaa1,2, Rabie Ben Atitallah2, David Duvivier2, Maher Ben Jemaa1 1 NIS University of Sfax, ReDCAD, Tunisia 2 Polytechnical University Hauts-de-France, France [email protected], fRabie.BenAtitallah, [email protected], [email protected] Abstract. Nowadays, sorting is an important operation the risk of accidents, the traffic jams and pollution. for several real-time embedded applications. It is one Also, ITS improve the transport efficiency, safety of the most commonly studied problems in computer and security of passengers. They are used in science. It can be considered as an advantage for various domains such as railways, avionics and some applications such as avionic systems and decision automotive technology. At different steps, several support systems because these applications need a applications need to use sorting algorithms such sorting algorithm for their implementation. However, as decision support systems, path planning [6], sorting a big number of elements and/or real-time de- cision making need high processing speed. Therefore, scheduling and so on. accelerating sorting algorithms using FPGA can be an attractive solution. In this paper, we propose an efficient However, the complexity and the targeted hardware implementation for different sorting algorithms execution platform(s) are the main performance (BubbleSort, InsertionSort, SelectionSort, QuickSort, criteria for sorting algorithms. Different platforms HeapSort, ShellSort, MergeSort and TimSort) from such as CPU (single or multi-core), GPU (Graphics high-level descriptions in the zynq-7000 platform. In Processing Unit), FPGA (Field Programmable addition, we compare the performance of different Gate Array) [14] and heterogeneous architectures algorithms in terms of execution time, standard deviation can be used. -

Comparison Sorts Name Best Average Worst Memory Stable Method Other Notes Quicksort Is Usually Done in Place with O(Log N) Stack Space
Comparison sorts Name Best Average Worst Memory Stable Method Other notes Quicksort is usually done in place with O(log n) stack space. Most implementations on typical in- are unstable, as stable average, worst place sort in-place partitioning is case is ; is not more complex. Naïve Quicksort Sedgewick stable; Partitioning variants use an O(n) variation is stable space array to store the worst versions partition. Quicksort case exist variant using three-way (fat) partitioning takes O(n) comparisons when sorting an array of equal keys. Highly parallelizable (up to O(log n) using the Three Hungarian's Algorithmor, more Merge sort worst case Yes Merging practically, Cole's parallel merge sort) for processing large amounts of data. Can be implemented as In-place merge sort — — Yes Merging a stable sort based on stable in-place merging. Heapsort No Selection O(n + d) where d is the Insertion sort Yes Insertion number of inversions. Introsort No Partitioning Used in several STL Comparison sorts Name Best Average Worst Memory Stable Method Other notes & Selection implementations. Stable with O(n) extra Selection sort No Selection space, for example using lists. Makes n comparisons Insertion & Timsort Yes when the data is already Merging sorted or reverse sorted. Makes n comparisons Cubesort Yes Insertion when the data is already sorted or reverse sorted. Small code size, no use Depends on gap of call stack, reasonably sequence; fast, useful where Shell sort or best known is No Insertion memory is at a premium such as embedded and older mainframe applications. Bubble sort Yes Exchanging Tiny code size. -

Discussion 10 Solution Fall 2015 1 Sorting I Show the Steps Taken by Each Sort on the Following Unordered List
CS 61B Discussion 10 Solution Fall 2015 1 Sorting I Show the steps taken by each sort on the following unordered list: 106, 351, 214, 873, 615, 172, 333, 564 (a) Quicksort (assume the pivot is always the first item in the sublist being sorted and the array is sorted in place). At every step circle everything that will be a pivot on the next step and box all previous pivots. 106 351 214 873 615 172 333 564 £ 106 351 214 873 615 172 333 564 ¢ ¡ £ 106 214 172 333 351 873 615 564 £¢ ¡ £ 106 172 214 333 351 615 564 873 ¢ ¡ £¢ ¡ 106 172 214 333 351 564 615 873 ¢ ¡ (b) Merge sort. Show the intermediate merging steps. 106 351 214 873 615 172 333 564 106 351 214 873 172 615 333 564 106 214 351 873 172 333 564 615 106 214 351 873 172 333 564 615 106 172 214 333 351 564 615 873 (c) LSD radix sort. 106 351 214 873 615 172 333 564 351 172 873 333 214 564 615 106 106 214 615 333 351 564 172 873 106 172 214 333 351 564 615 873 2 Sorting II Match the sorting algorithms to the sequences, each of which represents several intermediate steps in the sorting of an array of integers. Algorithms: Quicksort, merge sort, heapsort, MSD radix sort, insertion sort. CS 61B, Fall 2015, Discussion 10 Solution 1 (a) 12, 7, 8, 4, 10, 2, 5, 34, 14 7, 8, 4, 10, 2, 5, 12, 34, 14 4, 2, 5, 7, 8, 10, 12, 14, 34 Quicksort (b) 23, 45, 12, 4, 65, 34, 20, 43 12, 23, 45, 4, 65, 34, 20, 43 Insertion sort (c) 12, 32, 14, 11, 17, 38, 23, 34 12, 14, 11, 17, 23, 32, 38, 34 MSD radix sort (d) 45, 23, 5, 65, 34, 3, 76, 25 23, 45, 5, 65, 3, 34, 25, 76 5, 23, 45, 65, 3, 25, 34, 76 Merge sort (e) 23, 44, 12, 11, 54, 33, 1, 41 54, 44, 33, 41, 23, 12, 1, 11 44, 41, 33, 11, 23, 12, 1, 54 Heap sort 3 Runtimes Fill in the best and worst case runtimes of the following sorting algorithms with respect to n, the length of the list being sorted, along with when that runtime would occur. -

Smoothsort's Behavior on Presorted Sequences by Stefan Hertel
Smoothsort's Behavior on Presorted Sequences by Stefan Hertel Fachbereich 10 Universitat des Saarlandes 6600 Saarbrlicken West Germany A 82/11 July 1982 Abstract: In [5], Mehlhorn presented an algorithm for sorting nearly sorted sequences of length n in time 0(n(1+log(F/n») where F is the number of initial inver sions. More recently, Dijkstra[3] presented a new algorithm for sorting in situ. Without giving much evidence of it, he claims that his algorithm works well on nearly sorted sequences. In this note we show that smoothsort compares unfavorably to Mehlhorn's algorithm. We present a sequence of length n with O(nlogn) inversions which forces smooth sort to use time Q(nlogn), contrasting to the time o (nloglogn) Mehlhorn's algorithm would need. - 1 O. Introduction Sorting is a task in the very heart of computer science, and efficient algorithms for it were developed early. Several of them achieve the O(nlogn) lower bound for sor ting n elements by comparison that can be found in Knuth[4]. In many applications, however, the lists to be sorted do not consist of randomly distributed elements, they are already partially sorted. Most classic O(nlogn) algorithms - most notably mergesort and heapsort (see [4]) - do not take the presortedness of their inputs into account (cmp. [2]). Therefore, in recent years, the interest in sorting focused on algorithms that exploit the degree of sortedness of the respective input. No generally accepted measure of sortedness of a list has evolved so far. Cook and Kim[2] use the minimum number of elements after the removal of which the remaining portion of the list is sorted - on this basis, they compared five well-known sorting algorithms experimentally. -
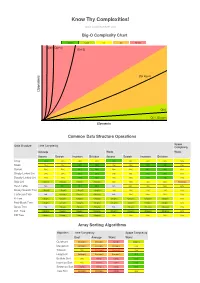
Big-O Algorithm Complexity Cheat Sheet
Know Thy Complexities! www.bigocheatsheet.com Big-O Complexity Chart Excellent Good Fair Bad Horrible O(n!) O(2^n) O(n^2) s O(n log n) n o i t a r e p O O(n) O(1), O(log n) Elements Common Data Structure Operations Space Data Structure Time Complexity Complexity Average Worst Worst Access Search Insertion Deletion Access Search Insertion Deletion Array O(1) O(n) O(n) O(n) O(1) O(n) O(n) O(n) O(n) Stack O(n) O(n) O(1) O(1) O(n) O(n) O(1) O(1) O(n) Queue O(n) O(n) O(1) O(1) O(n) O(n) O(1) O(1) O(n) Singly-Linked List O(n) O(n) O(1) O(1) O(n) O(n) O(1) O(1) O(n) Doubly-Linked List O(n) O(n) O(1) O(1) O(n) O(n) O(1) O(1) O(n) Skip List O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) O(n) O(n) O(n) O(n log(n)) Hash Table N/A O(1) O(1) O(1) N/A O(n) O(n) O(n) O(n) Binary Search Tree O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) O(n) O(n) O(n) O(n) Cartesian Tree N/A O(log(n)) O(log(n)) O(log(n)) N/A O(n) O(n) O(n) O(n) B-Tree O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) Red-Black Tree O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) Splay Tree N/A O(log(n)) O(log(n)) O(log(n)) N/A O(log(n)) O(log(n)) O(log(n)) O(n) AVL Tree O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) KD Tree O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) O(n) O(n) O(n) O(n) Array Sorting Algorithms Algorithm Time Complexity Space Complexity Best Average Worst Worst Quicksort O(n log(n)) O(n log(n)) O(n^2) O(log(n)) Mergesort O(n log(n)) O(n log(n)) O(n log(n)) O(n)