Prediction of Vowel and Consonant Place of Articulation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

LINGUISTICS 221 LECTURE #3 the BASIC SOUNDS of ENGLISH 1. STOPS a Stop Consonant Is Produced with a Complete Closure of Airflow
LINGUISTICS 221 LECTURE #3 Introduction to Phonetics and Phonology THE BASIC SOUNDS OF ENGLISH 1. STOPS A stop consonant is produced with a complete closure of airflow in the vocal tract; the air pressure has built up behind the closure; the air rushes out with an explosive sound when released. The term plosive is also used for oral stops. ORAL STOPS: e.g., [b] [t] (= plosives) NASAL STOPS: e.g., [m] [n] (= nasals) There are three phases of stop articulation: i. CLOSING PHASE (approach or shutting phase) The articulators are moving from an open state to a closed state; ii. CLOSURE PHASE (= occlusion) Blockage of the airflow in the oral tract; iii. RELEASE PHASE Sudden reopening; it may be accompanied by a burst of air. ORAL STOPS IN ENGLISH a. BILABIAL STOPS: The blockage is made with the two lips. spot [p] voiceless baby [b] voiced 1 b. ALVEOLAR STOPS: The blade (or the tip) of the tongue makes a closure with the alveolar ridge; the sides of the tongue are along the upper teeth. lamino-alveolar stops or Check your apico-alveolar stops pronunciation! stake [t] voiceless deep [d] voiced c. VELAR STOPS: The closure is between the back of the tongue (= dorsum) and the velum. dorso-velar stops scar [k] voiceless goose [g] voiced 2. NASALS (= nasal stops) The air is stopped in the oral tract, but the velum is lowered so that the airflow can go through the nasal tract. All nasals are voiced. NASALS IN ENGLISH a. BILABIAL NASAL: made [m] b. ALVEOLAR NASAL: need [n] c. -

The Violability of Backness in Retroflex Consonants
The violability of backness in retroflex consonants Paul Boersma University of Amsterdam Silke Hamann ZAS Berlin February 11, 2005 Abstract This paper addresses remarks made by Flemming (2003) to the effect that his analysis of the interaction between retroflexion and vowel backness is superior to that of Hamann (2003b). While Hamann maintained that retroflex articulations are always back, Flemming adduces phonological as well as phonetic evidence to prove that retroflex consonants can be non-back and even front (i.e. palatalised). The present paper, however, shows that the phonetic evidence fails under closer scrutiny. A closer consideration of the phonological evidence shows, by making a principled distinction between articulatory and perceptual drives, that a reanalysis of Flemming’s data in terms of unviolated retroflex backness is not only possible but also simpler with respect to the number of language-specific stipulations. 1 Introduction This paper is a reply to Flemming’s article “The relationship between coronal place and vowel backness” in Phonology 20.3 (2003). In a footnote (p. 342), Flemming states that “a key difference from the present proposal is that Hamann (2003b) employs inviolable articulatory constraints, whereas it is a central thesis of this paper that the constraints relating coronal place to tongue-body backness are violable”. The only such constraint that is violable for Flemming but inviolable for Hamann is the constraint that requires retroflex coronals to be articulated with a back tongue body. Flemming expresses this as the violable constraint RETRO!BACK, or RETRO!BACKCLO if it only requires that the closing phase of a retroflex consonant be articulated with a back tongue body. -

English Phonetic Vowel Shortening and Lengthening As Perceptually Active for the Poles
View metadata, citation and similar papers at core.ac.uk brought to you by CORE Title: English phonetic vowel shortening and lengthening as perceptually active for the Poles Author: Arkadiusz Rojczyk Citation style: Rojczyk Arkadiusz. (2007). English phonetic vowel shortening and lengthening as perceptually active for the Poles. W: J. Arabski (red.), "On foreign language acquisition and effective learning" (S. 237-249). Katowice : Wydawnictwo Uniwersytetu Śląskiego Phonological subsystem English phonetic vowel shortening and lengthening as perceptually active for the Poles Arkadiusz Rojczyk University of Silesia, Katowice 1. Introduction Auditory perception is one of the most thriving and active domains of psy cholinguistics. Recent years have witnessed manifold attempts to investigate and understand how humans perceive linguistic sounds and what principles govern the process. The major assumption underlying the studies on auditory perception is a simple fact that linguistic sounds are means of conveying meaning, encoded by a speaker, to a hearer. The speaker, via articulatory gestures, transmits a message encoded in acoustic waves. This is the hearer, on the other hand, who, using his perceptual apparatus, reads acoustic signals and decodes them into the meaning. Therefore, in phonetic terms, the whole communicative act can be divided into three stages. Articulatory - the speaker encodes the message by sound production. Acoustic - the message is transmitted to the hearer as acous tic waves. Auditory - the hearer perceives sounds and decodes them into the meaning. Each of the three stages is indispensable for effective communication. Of the three aforementioned stages of communication, the auditory percep tion is the least amenable to precise depiction and understanding. -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

SSC: the Science of Talking
SSC: The Science of Talking (for year 1 students of medicine) Week 3: Sounds of the World’s Languages (vowels and consonants) Michael Ashby, Senior Lecturer in Phonetics, UCL PLIN1101 Introduction to Phonetics and Phonology A Lecture 4 page 1 Vowel Description Essential reading: Ashby & Maidment, Chapter 5 4.1 Aim: To introduce the basics of vowel description and the main characteristics of the vowels of RP English. 4.2 Definition of vowel: Vowels are produced without any major obstruction of the airflow; the intra-oral pressure stays low, and vowels are therefore sonorant sounds. Vowels are normally voiced. Vowels are articulated by raising some part of the tongue body (that is the front or the back of the tongue notnot the tip or blade) towards the roof of the oral cavity (see Figure 1). 4.3 Front vowels are produced by raising the front of the tongue towards the hard palate. Back vowels are produced by raising the back of the tongue towards the soft palate. Central vowels are produced by raising the centre part of the tongue towards the junction of the hard and soft palates. 4.4 The height of a vowel refers to the degree of raising of the relevant part of the tongue. If the tongue is raised so as to be close to the roof of the oral cavity then a close or high vowel is produced. If the tongue is only slightly raised, so that there is a wide gap between its highest point and the roof of the oral cavity, then an open or lowlowlow vowel results. -

Word Study Guide for Parents
Descriptions of Word Study Patterns/Concepts Purpose of Word Study • It teaches students to examine words to discover the regularities, patterns, and conventions of the English language in order to read and spell. • It increases specific knowledge of words – the spelling and meaning of individual words. 3 Layers of word study • Alphabet – learning the relationship between letters and sounds • Pattern – learning specific groupings of letters and their sounds • Meaning – learning the meaning of groups of letters such as prefixes, suffixes, and roots. Vocabulary increases at this layer. Sorting – organizing words into groups based on similarities in their patterns or meaning. Oddballs – words that cannot be grouped into any of the identified categories of a sort. Students should be taught that there are always words that “break the rules” and do not follow the general pattern. Sound marks / / - Sound marks around a letter or pattern tell the student to focus only on the sound rather than the actual letters. (example: the word gem could be grouped into the /j/ category because it sounds like j at the beginning). Vowel (represented by V) – one of 6 letters causing the mouth to open when vocalized (a, e, i, o, u, and usually y). A single vowel sound is heard in every syllable of a word. Consonants (represented by C) – all letters other than the vowels. Consonant sounds are blocked by the lips, tongue, or teeth during articulation. Concepts in Order of Instruction Initial and final consonants – students are instructed to look at pictures and identify the beginning sound. They then connect the beginning sound to the letter that makes that sound. -
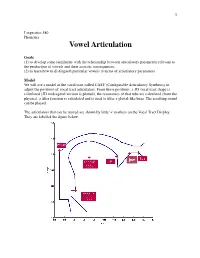
Vowel Articulation
1 Linguistics 580 Phonetics Vowel Articulation Goals (1) to develop some familiarity with the relationship between articulatory parameters relevant to the production of vowels and their acoustic consequences. (2) to learn how to distinguish particular vowels in terms of articulatory parameters. Model We will use a model of the vocal tract called CASY (Configurable Articulatory Synthesis) to adjust the positions of vocal tract articulators. From those positions, a 3D vocal tract shape is calculated (2D midsagittal version is plotted), the resonances of that tube are calculated (from the physics), a filter function is calculated and is used to filter a glottal-like buzz. The resulting sound can be played. The articulators that can be moved are shown by little '+' markers on the Vocal Tract Display. They are labelled the figure below. 2 The articulators can be moved by positioning the mouse pointer over one of these markers, then holding down the button and dragging it to a new position. As you are dragging, the articulator will move and the vocal tract shape will be updated appropriately. A new filter function and formants will also be displayed, and a new sound can be played. The articulator positions are defined relative to one another in a dependence hierarchy. The lower lip, tongue body, and tongue tip are dependent on the position of the jaw, so when the jaw moves, these articulators more along with it. The tongue tip is dependent on the position of the tongue body. The upper lip is dependent on the position of the lower lip. For this exercise with vowels, you should be able to produce decent approximations to English vowels by manipulating only the jaw, tongue body, and lips. -

Studies in African Linguistics Volume 21, Number 3, December 1990
Studies in African Linguistics Volume 21, Number 3, December 1990 CONTEXTUAL LABIALIZATION IN NA WURI* Roderic F. Casali Ghana Institute of Linguistics Literacy and Bible Translation and UCLA A spectrographic investigation into the non-contrastive labialization of consonants before round vowels in Nawuri (a Kwa language of Ghana) sup ports the notion that this labialization is the result of a phonological, feature spreading rule and not simply an automatic transitional process. This as sumption is further warranted in that it allows for a more natural treatment of some other phonological processes in the language. The fact that labial ization before round vowels is generally not very audible is explained in terms of a principle of speech perception. A final topic addressed is the question of why (both in Nawuri and apparently in a number of other Ghanaian languages as well) contextual labialization does tend to be more perceptible in certain restricted environments. o. Introduction This paper deals with the allophonic labialization of consonants before round vowels in Nawuri, a Kwa language of Ghana.! While such labialization is gener ally not very audible, spectrographic evidence suggests that it is strongly present, * The spectrograms in this study were produced at the phonetics lab of the University of Texas at Arlington using equipment provided through a grant of the Permanent University Fund of the University of Texas system. I would like to thank the following people for their valuable comments and suggestions: Joan Baart, Don Burquest, Mike Cahill, Jerry Edmondson, Norris McKinney, Bob Mugele, Tony Naden, and Keith Snider. I would also like to express my appreciation to Russell Schuh and an anonymous referee for this journal for their helpful criticism of an earlier version, and to Mary Steele for some helpful discussion concerning labialization in Konkomba. -

Bradley 2015 Labialization and Palatalization in Judeo-Spanish
LABIALIZATION AND PALATALIZATION IN JUDEO-SPANISH PHONOLOGY* TRAVIS G. BRADLEY University of California, Davis Judeo-Spanish (JS) presents a number of phonological processes involving secondary articulations. This paper establishes novel descriptive generalizations based on labialization and palatalization phenomena across different JS dialects. I show how these generalizations are part of a broader cross-linguistic typology of secondary articulation patterns, which would remain incomplete on the basis of non-Sephardic Spanish alone. I propose an analysis in Optimality Theory (OT) that accounts for this variation using the same universal constraints that are active in languages beyond Ibero-Romance. This paper demonstrates the utility of OT as an analytical framework for doing JS phonology and in turn highlights the importance of JS to phonological theory by bringing new generalizations and data to bear on the analysis of secondary articulations. 1. Introduction Judeo-Spanish (henceforth, JS) refers to those varieties of Spanish preserved by the Sephardic Jews who were expelled from Spain in 1492 and have emigrated throughout Europe, North Africa, the Middle East, and later, the United States. JS is intriguing to study from both diachronic and synchronic perspectives. The linguistic system retains many archaic features, which gives us a unique, albeit indirect, window into the structure of Old Spanish (henceforth, OS). Having evolved in relative isolation from the linguistic norms of the Iberian Peninsula and often in contact with other -
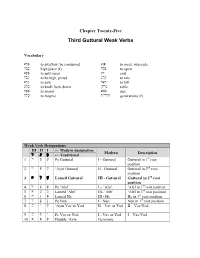
Third Guttural Weak Verbs
Chapter Twenty-Five Third Guttural Weak Verbs Vocabulary [:l'B to swallow, be consumed [:g'P to meet, intercede h'm'B high place (f) x:t'P to open [:q'B to split open #Eq end H:b'G to be high, proud [:r'q to tare [:r'z to sow x:c'r to kill [:r'K to knell, bow down !'x.lUv table x:v'm to anoint v,m,v sun x:l's to forgive tAd.lAT generations (f) Weak Verb Designations III II I ← Modern designation Modern Description l :[ 'P ← Traditional 1 d :m '[ Pe Guttural I - Guttural Guttural in 1st root position 2 l :a 'v ‘Ayin Guttural II - Guttural Guttural in 2nd root position 3 x :l 'v Lamed Guttural III - Guttural Guttural in 3rd root position 4 l :k 'a Pe ‘Alef I – ‘Alef ‘Alef in 1st root position 5 a 'c 'm Lamed ‘Alef III- ‘Alef ‘Alef in 3rd root position 6 h 'n 'B Lamed He III - He He in 3rd root position 7 l :p 'n Pe Nun I - Nun Nun in 1st root position 8 b W v ‘Ayin Vav or Yod II – Vav or Yod II – Vav/Yod 9 b :v 'y Pe Vav or Yod I - Vav or Yod I – Vav/Yod 10 b :b 's Double ‘Ayin Geminate Third Guttural Weak Verbs A Third Guttural verb designated as Lamed Guttural or III-Guttural is one whose third or final root consonant is one of the limited gutturals: H, x, or [. Final a, h , or r do not act as gutturals when placed in the final root consonant. -

The Effects of Post-Velar Consonants on Vowels in Ditidaht∗
The effects of post-velar consonants on vowels in Ditidaht∗ John Sylak-Glassman University of California, Berkeley Abstract: This article examines the effects of post-velar consonants on vowels in Ditidaht using acoustic data obtained using instrumental methods from four na- tive speakers. The results of this examination show that uvulars cause backing, pharyngeals cause centralization, and glottals cause peripheralization. A survey of phonological patterns involving post-velar consonants in Ditidaht reveals that high vowels cannot occur before coda pharyngeals. Additional phonetic investigation shows that in that same position, short /a/ and /o/ have merged, fully collapsing the vocalic height distinction among short vowels before coda /Q/. The results of the phonological survey show that no single pattern unifies all the post-velar con- sonants in Ditidaht, but that the phonological patterns that are present demonstrate phonetically-grounded phonological connections between subsets of the post-velar consonants. Keywords: Ditidaht, post-velar consonants, phonetics, phonology, acoustic mea- surement, merger 1 Introduction Ditidaht is a Southern Wakashan language spoken on Vancouver Island whose phonemic inventory includes consonants at all three post-velar places of articu- lation: Uvular, pharyngeal/epiglottal, and glottal. In the languages that contain similarly rich inventories of post-velar consonants (such as those in the Semitic, Cushitic, and Salish stocks), these consonants often pattern together phonolog- ically, for example by causing effects on vowels, by being avoided in certain prosodic positions, and by systematically failing to co-occur, especially in lexi- cal roots (Bessell 1992, 1998a,b; Hayward and Hayward 1989; McCarthy 1991, 1994). These phonological patterns have been used as evidence to support the ∗Thank you very much to the four speakers who kindly worked with me: Dorothy Shepherd, Michael Thompson, Christine Edgar, and Jimmy Chester. -

Arabic and English Consonants: a Phonetic and Phonological Investigation
Advances in Language and Literary Studies ISSN: 2203-4714 Vol. 6 No. 6; December 2015 Flourishing Creativity & Literacy Australian International Academic Centre, Australia Arabic and English Consonants: A Phonetic and Phonological Investigation Mohammed Shariq College of Science and Arts, Methnab, Qassim University, Saudi Arabia E-mail: [email protected] Doi:10.7575/aiac.alls.v.6n.6p.146 Received: 18/07/2015 URL: http://dx.doi.org/10.7575/aiac.alls.v.6n.6p.146 Accepted: 15/09/2015 Abstract This paper is an attempt to investigate the actual pronunciation of the consonants of Arabic and English with the help of phonetic and phonological tools like manner of the articulation, point of articulation, and their distribution at different positions in Arabic and English words. A phonetic and phonological analysis of the consonants of Arabic and English can be useful in overcoming the hindrances that confront the Arab EFL learners. The larger aim is to bring about pedagogical changes that can go a long way in improving pronunciation and ensuring the occurrence of desirable learning outcomes. Keywords: Phonetics, Phonology, Pronunciation, Arabic Consonants, English Consonants, Manner of articulation, Point of articulation 1. Introduction Cannorn (1967) and Ekundare (1993) define phonetics as sounds which is the basis of human speech as an acoustic phenomenon. It has a source of vibration somewhere in the vocal apparatus. According to Varshney (1995), Phonetics is the scientific study of the production, transmission and reception of speech sounds. It studies the medium of spoken language. On the other hand, Phonology concerns itself with the evolution, analysis, arrangement and description of the phonemes or meaningful sounds of a language (Ramamurthi, 2004).