Using Machine Learning Algorithms to Identify Undervalued Baseball Players Tatsuya Ishii (Twishii) ______
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2020 Topps Chrome Sapphire Edition .Xls
SERIES 1 1 Mike Trout Angels® 2 Gerrit Cole Houston Astros® 3 Nicky Lopez Kansas City Royals® 4 Robinson Cano New York Mets® 5 JaCoby Jones Detroit Tigers® 6 Juan Soto Washington Nationals® 7 Aaron Judge New York Yankees® 8 Jonathan Villar Baltimore Orioles® 9 Trent Grisham San Diego Padres™ Rookie 10 Austin Meadows Tampa Bay Rays™ 11 Anthony Rendon Washington Nationals® 12 Sam Hilliard Colorado Rockies™ Rookie 13 Miles Mikolas St. Louis Cardinals® 14 Anthony Rendon Angels® 15 San Diego Padres™ 16 Gleyber Torres New York Yankees® 17 Franmil Reyes Cleveland Indians® 18 Minnesota Twins® 19 Angels® Angels® 20 Aristides Aquino Cincinnati Reds® Rookie 21 Shane Greene Atlanta Braves™ 22 Emilio Pagan Tampa Bay Rays™ 23 Christin Stewart Detroit Tigers® 24 Kenley Jansen Los Angeles Dodgers® 25 Kirby Yates San Diego Padres™ 26 Kyle Hendricks Chicago Cubs® 27 Milwaukee Brewers™ Milwaukee Brewers™ 28 Tim Anderson Chicago White Sox® 29 Starlin Castro Washington Nationals® 30 Josh VanMeter Cincinnati Reds® 31 American League™ 32 Brandon Woodruff Milwaukee Brewers™ 33 Houston Astros® Houston Astros® 34 Ian Kinsler San Diego Padres™ 35 Adalberto Mondesi Kansas City Royals® 36 Sean Doolittle Washington Nationals® 37 Albert Almora Chicago Cubs® 38 Austin Nola Seattle Mariners™ Rookie 39 Tyler O'neill St. Louis Cardinals® 40 Bobby Bradley Cleveland Indians® Rookie 41 Brian Anderson Miami Marlins® 42 Lewis Brinson Miami Marlins® 43 Leury Garcia Chicago White Sox® 44 Tommy Edman St. Louis Cardinals® 45 Mitch Haniger Seattle Mariners™ 46 Gary Sanchez New York Yankees® 47 Dansby Swanson Atlanta Braves™ 48 Jeff McNeil New York Mets® 49 Eloy Jimenez Chicago White Sox® Rookie 50 Cody Bellinger Los Angeles Dodgers® 51 Anthony Rizzo Chicago Cubs® 52 Yasmani Grandal Chicago White Sox® 53 Pete Alonso New York Mets® 54 Hunter Dozier Kansas City Royals® 55 Jose Martinez St. -

Atlanta Braves Clippings Monday, June 29, 2020 Braves.Com
Atlanta Braves Clippings Monday, June 29, 2020 Braves.com Braves set player pool; 4 spots remain By Mark Bowman ATLANTA -- Less than three weeks after being drafted, Jared Shuster was placed in the 60-man player pool the Braves submitted to Major League Baseball on Sunday afternoon. Shuster is not expected to make his MLB debut this year. But his inclusion on this list creates the opportunity for him to spend the next couple of months working out with some of the top members of the Braves’ development staff. First and foremost, these 60-man player pools were designed for teams to designate which members of their organization will be eligible for the 60-game regular season, which is slated to begin on July 23 or 24. But with a Minor League season this year seeming unlikely, teams also chose to fill some of these spots with their top prospects. The Braves’ pool actually includes each of their top 12 prospects (per MLB Pipeline’s rankings). But only two or three of those prospects has a shot of being added to Atlanta’s active roster at some point this year. The members of this prospect group who could be used by Atlanta this year include outfielders Cristian Pache and Drew Waters, right-handers Ian Anderson, Kyle Wright, Bryse Wilson, Jasseel De La Cruz and Huascar Ynoa, and left-handers Kyle Muller and Tucker Davidson. Shuster, a left-handed pitcher taken in this year's Draft with the 25th overall pick out of Wake Forest, is part of the group of prospects added to this list just to get some experience this year. -

Detroit Tigers
DETROIT TIGERS GAME NOTES WORLD SERIES CHAMPIONS: 1935, 1945, 1968, 1984 Detroit Tigers Media Rela ons Department • Comerica Park • Phone (313) 471-2000 • Fax (313) 471-2138 • Detroit, MI 48201 www. gers.com • @ gers, @TigresdeDetroit, @DetroitTigersPR Detroit Tigers (15-11-1) at Bal more Orioles (10-14-5) Wednesday, March 30, 2016 • Ed Smith Stadium, Sarasota, FL • 6:05 p.m. ET RHP Shane Greene (1-0, 2.63) vs. RHP Chris Tillman (0-0, 9.31) TV: MLB Network (Delayed - airs at 9 p.m. on Wednesday) • Radio: None RECENT RESULTS: The Tigers game on Tuesday vs. Toronto at Joker Marchant Stadium in Lakeland was canceled due to NUMERICAL ROSTER rain. Detroit dropped a 3-2 decision to the New York Yankees on Monday night at George M. Steinbrenner Field in Tampa. 1 Jose Iglesias INF Ian Kinsler and Jus n Upton accounted for the Tigers two runs as each hit a solo home run. Miguel Cabrera added a pair 3 Ian Kinsler INF of hits in the loss. Buck Farmer started for Detroit and threw 3.0 shutout innings with two hits allowed, one walk and 4 Cameron Maybin OF one strikeout. Kyle Ryan worked 2.0 scoreless innings in relief, allowing just one hit. Adam Ravenelle took the loss for the 8 Jus n Upton OF Tigers a er giving up two runs on three hits with one strikeout in 1.0 inning. 9 Nick Castellanos INF TIGERS ACQUIRE BOBBY WILSON AND MYLES JAYE FROM TEXAS: The Tigers on Tuesday night acquired catcher Bobby 12 Anthony Gose OF Wilson and righthanded pitcher Myles Jaye from Texas in exchange for catcher Bryan Holaday. -

ARIZONA ATLANTA CHICAGO CINCINNATI COLORADO LOS ANGELES Tim Locastro Ronald Acuna, Jr
ARIZONA ATLANTA CHICAGO CINCINNATI COLORADO LOS ANGELES Tim Locastro Ronald Acuna, Jr. Ian Happ Shogo Akiyama Raimel Tapia Mookie Betts Ketel Marte Dansby Swanson Kris Bryant Nicholas Castellanos Trevor Story Corey Seager Christian Walker Freddie Freeman Anthony Rizzo Joey Votto Charlie Blackmon Justin Turner Kole Calhoun Marcell Ozuna Javier Baez Eugenio Suarez Nolan Arenado Cody Bellinger Eduardo Escobar Travis d’Arnaud Kyle Schwarber Mike Moustakas Daniel Murphy Max Muncy David Peralta Nick Markakis Willson Contreras Jesse Winker Josh Fuentes A.J. Pollock Nick Ahmed Johan Camargo Jason Heyward Nick Senzel Matt Kemp Joc Pederson Daulton Varsho Adam Duvall Victor Caratini Brian Goodwin Ryan McMahon Kike Hernandez Carson Kelly Austin Riley Jason Kipnis Freddie Galvis Kevin Pillar Will Smith Stephen Vogt Ozzie Albies Nico Hoerner Tucker Barnhart Garrett Hampson Austin Barnes Josh Rojas Ender Inciarte David Bote Curt Casali Tony Wolters Chris Taylor Jon Jay Tyler Flowers Cameron Maybin Kyle Farmer Elias Diaz Matt Beaty Josh VanMeter Adeiny Hechavarria Jose Martinez Jose Garcia Drew Butera Edwin Rios Pavin Smith Matt Adams Ildemaro Vargas Aristides Aquino Chris Owings Gavin Lux Andy Young Max Fried Albert Almora Matt Davidson Sam Hilliard Clayton Kershaw Zac Gallen Kyle Wright Yu Darvish Luis Castillo David Dahl Dustin May Luke Weaver Ian Anderson Jon Lester Trevor Bauer German Marquez Julio Urias Madison Bumgarner Robbie Erlin Kyle Hendricks Sonny Gray Kyle Freeland Tony Gonsolin Alex Young Touki Toussaint Alec Mills Tyler Mahle Antonio Senzatela Walker Buehler Taylor Clarke Huascar Ynoa Tyler Chatwood Anthony DeSclafani Ryan Castellani Blake Treinen Merrill Kelly Shane Greene Adbert Alzolay Wade Miley Jon Gray Kenley Jansen Stefan Crichton Mark Melancon Jeremy Jeffress Raisel Iglesias Chi Chi Gonzalez Dylan Floro Junior Guerra A.J. -

BASE 1 Miguel Cabrera Detroit Tigers® 2
BASE 1 Miguel Cabrera Detroit Tigers® 2 Michael Brantley Cleveland Indians® 3 Yasmani Grandal Los Angeles Dodgers® 4 Byron Buxton Minnesota Twins® RC 5 Daniel Murphy New York Mets® 6 Clay Buchholz Boston Red Sox® 7 James Loney Tampa Bay Rays™ 8 Dee Gordon Miami Marlins® 9 Khris Davis Milwaukee Brewers™ 10 Trevor Rosenthal St. Louis Cardinals® 11 Jered Weaver Angels® 12 Lucas Duda New York Mets® 13 James Shields San Diego Padres™ 14 Jacob Lindgren New York Yankees® RC 15 Michael Bourn Cleveland Indians® 16 Yunel Escobar Washington Nationals® 17 George Springer Houston Astros® 18 Ryan Howard Philadelphia Phillies® 19 Justin Upton San Diego Padres™ 20 Zach Britton Baltimore Orioles® 21 Santiago Casilla San Francisco Giants® 22 Max Scherzer Washington Nationals® 23 Carlos Carrasco Cleveland Indians® 24 Angel Pagan San Francisco Giants® 25 Wade Miley Boston Red Sox® 26 Ryan Braun Milwaukee Brewers™ 27 Carlos Gonzalez Colorado Rockies™ 28 Chase Utley Philadelphia Phillies® 29 Brandon Moss Cleveland Indians® 30 Juan Lagares New York Mets® 31 David Robertson Chicago White Sox® 32 Carlos Santana Cleveland Indians® 33 Ender Inciarte Arizona Diamondbacks® 34 Jimmy Rollins Los Angeles Dodgers® 35 J.D. Martinez Detroit Tigers® 36 Yadier Molina St. Louis Cardinals® 37 Ryan Zimmerman Washington Nationals® 38 Stephen Strasburg Washington Nationals® 39 Torii Hunter Minnesota Twins® 40 Anibal Sanchez Detroit Tigers® 41 Michael Cuddyer New York Mets® 42 Jorge De La Rosa Colorado Rockies™ 43 Shane Greene Detroit Tigers® 44 John Lackey St. Louis Cardinals® 45 Hyun-Jin Ryu Los Angeles Dodgers® 46 Lance Lynn St. Louis Cardinals® 47 David Freese Angels® 48 Russell Martin Toronto Blue Jays® 49 Jose Iglesias Detroit Tigers® 50 Pablo Sandoval Boston Red Sox® 51 Will Middlebrooks San Diego Padres™ 52 Joe Mauer Minnesota Twins® 53 Chris Archer Tampa Bay Rays™ 54 Starling Marte Pittsburgh Pirates® 55 Jason Heyward St. -

Today's Starting Lineups
DETROIT TIGERS (29-31) at BOSTON RED SOX (33-27) Game #61 ● Saturday, June 10, 2017 ● Fenway Park, Boston, MA DETROIT TIGERS AVG HR RBI PLAYER POS 1 2 3 4 5 6 7 8 9 10 11 12 AB R H RBI .241 4 11 3-Ian Kinsler 2B .229 7 30 9-Nicholas Castellanos 3B .263 5 27 24-Miguel Cabrera 1B .274 5 28 41-Victor Martinez S DH .310 10 23 28-J.D. Martinez RF .261 12 35 8-Justin Upton LF .229 4 10 15-Mikie Mahtook CF .196 7 17 34-James McCann C .256 2 17 1-José Iglesias SS R H E LOB PITCHERS DEC IP H R ER BB SO HR WP HB P/S GAME DATA 35-RHP Justin Verlander (4-4, 4.63) Official Scorer: Mike Shalin 1st Pitch: Temp: Ga me Time: Attendance: 1-José Iglesias, INF 22-Gene Lamont (Bench) 35-Justin Verlander, RHP 59-Leon Durham (Asst. Hitting) DET Bench DET Bullpen 3-Ian Kinsler, INF 24-Miguel Cabrera, INF 37-Jim Adduci, OF* 61-Shane Greene, RHP 7-Brad Ausmus (Manager) 25-Dave Clark (3rd Base) 38-Justin Wilson, LHP 66-Arcenio León, RHP Left Left 8-Justin Upton, OF 27-Jordan Zimmermann, RHP 41-Victor Martinez, DH 68-Daniel Stumpf, LHP 14-Alex Presley 38-Justin Wilson 9-Nicholas Castellanos, INF 28-J.D. Martinez, OF 44-Daniel Norris, LHP 88-Matt Martin (Coach) 31-Alex Avila 68-Daniel Stumpf 13-Omar Vizquel (1st Base) 29-Mick Billmeyer (Bullpen) 45-Buck Farmer, RHP Right Right 14-Alex Presley, OF 30-Alex Wilson, RHP 49-Dixon Machado, INF * 10-day Disabled List 30-Alex Wilson 15-Mikie Mahtook, OF 31-Alex Avila, C 52-Rich Dubee (Pitching) ^ 60-day Disabled List 49-Dixon Machado 53-Warwick Saupold 17-Andrew Romine, INF 32-Michael Fulmer, RHP 53-Warwick Saupold, RHP Switch 57-Francisco Rodríguez 20-Lloyd McClendon (Hitting) 34-James McCann, C 57-Francisco Rodríguez, RHP 17-Andrew Romine 61-Shane Greene 66-Arcenio León BOSTON RED SOX AVG HR RBI PLAYER POS 1 2 3 4 5 6 7 8 9 10 11 12 AB R H RBI .264 9 33 50-Mookie Betts RF .286 2 21 15-Dustin Pedroia 2B .326 2 22 2-Xander Bogaerts SS .276 8 32 18-Mitch Moreland L 1B .266 8 31 16-Andrew Benintendi L LF .244 8 24 13-Hanley Ramirez DH .231 8 27 19-Jackie Bradley Jr. -

Detroit Tigers Clips Wednesday, December 7, 2016
Detroit Tigers Clips Wednesday, December 7, 2016 Detroit Free Press Tigers tame on trade market; interest high in lefty Justin Wilson (Fenech) Tigers' Ausmus: Daniel Norris, Matt Boyd not yet set in rotation (Sipple) On Leyland's advice, Detroit Tigers' Justin Verlander is skipping WBC (Fenech) TigerFest is Jan. 21; tickets go on sale Friday (Fenech) The Detroit News Henning: With Sale off table, Verlander to Nationals makes sense (Henning) Gose being given shot at redemption with Tigers (McCosky) No dominoes fall to Tigers after Sale trade (McCosky) MLive.com Even after Chris Sale deal, chances of Justin Verlander trade seem slim (Woodbery) Baseball Winter Meetings live updates: Latest news, rumors from Day 3 (Woodbery) Tigers injury updates: Jordan Zimmermann getting neck treatment (Woodbery) Tigers' Justin Wilson getting 'high level of interest' in trade talks (Woodbery) Tigers like Francisco Rodriguez in pen, but growing trade value is hard to ignore (Woodbery) MLB.com Ausmus doesn't expect many moves for Tigers (Beck) Tigers lefty Wilson generating trade buzz (Beck) Verlander's status unchanged by Sale trade (Beck) CBSDetroit.com Brad Ausmus: We Don’t Want To Trade Our Stars (Burchfield) Daily Transactions 1 Tigers tame on trade market; interest high in lefty Justin Wilson December 7, 2016 By Anthony Fenech/ Detroit Free Press NATIONAL HARBOR, Md. – It was busier today than a day earlier at the Major League Baseball winter meetings, with a familiar face grabbing the headlines by executing another blockbuster trade, but the Detroit Tigers remained under the radar. “There’s not anything new to report,” general manager Al Avila said in the evening. -

Tigers Notes 3-25-17.Indd
DETROIT TIGERS GAME NOTES WORLD SERIES CHAMPIONS: 1935, 1945, 1968, 1984 Detroit Tigers Media Rela ons Department • Comerica Park • Phone (313) 471-2000 • Fax (313) 471-2138 • Detroit, MI 48201 www. gers.com • @ gers, @TigresdeDetroit, @DetroitTigersPR Detroit Tigers (12-15-2) at Pi sburgh Pirates (17-8-1) Saturday, March 25, 2017 • LECOM Park, Bradenton, FL • 1:05 p.m. ET RHP Anibal Sanchez (2-1, 7.24) vs. RHP Tyler Glasnow (1-0, 6.10) TV: MLB Network (Live) • Radio: 97.1 The Ticket RECENT RESULTS: The Tigers picked up a walkoff win on Friday a ernoon, defea ng the Atlanta Braves 3-2 in 10 NUMERICAL ROSTER innings at Publix Field at Joker Marchant Stadium. JaCoby Jones drove in the game-winning run with a RBI single in 1 José Iglesias INF the bo om of the 10th inning, scoring Dixon Machado, who doubled earlier in the inning. Brendan Ryan was 2x2 3 Ian Kinsler INF with a run scored, a double and a RBI, while Nicholas Castellanos added a hit and a RBI in the win. Ma hew Boyd 4 Omar Infante INF started for Detroit and did not factor into the decision a er throwing 5.0 shutout innings with three hits allowed and fi ve strikeouts. Edward Mujica picked up his second win of the spring, striking out two in a scoreless inning. Shane 8 Jus n Upton OF Greene, Blaine Hardy and Jus n Wilson each worked a shutout inning out of the bullpen. 9 Nicholas Castellanos INF TIGERS TIDBITS: Andrew Romine ranks ed for fourth in the Grapefruit League with 18 hits...Romine is ba ng 12 Anthony Gose OF .389 (14x36) with six runs scored, two doubles, one triple, one home run and four RBI over his last 13 games.. -
Tatis Jr, Starter Paddack Lead Padres Past Braves in Opener by GEORGE HENRY His Last Five Games
www.dailypostathenian.com FRIDAY, JULY 23, 2021 | SPORTS DAILY POST-ATHENIAN | B3 Tatis Jr, starter Paddack lead Padres past Braves in opener BY GEORGE HENRY his last five games. NATIONAL LEAGUE Ha-Seong Kim’s sacrifice fly. hits and walked three, work- third but was stranded at AP Sports Writer Paddack (6-6), who had “I think my tempo was ing out of jams in the first third base. a 10.31 ERA in his last five GM1: PADRES 3, Braves 2 a little fast, so I was just and third. Greene, who came “The story for me today ATLANTA — Fernando appearances, worked five rushing down the mound,” on to start the fifth, saw his was Paddack and how good Tatis Jr. hit a two-run hom- scoreless innings, allowing done a better job with. Muller said. “Early on my ERA increase to 10.38. and how efficient he was,” er, starter Chris Paddack three hits with no walks and There’s always something sliders were biting a little bit The Braves got within 3-2 Padres manager Jayce Tin- reversed his recent struggles one strikeout. you have to grow on.” more because I had adrena- in the sixth against Drew gler said. and the San Diego Padres “I’m going to continue to All-Star closer Mark Mel- line and my arm speed was Pomeranz when Freddie “Using all the quadrants of beat the Atlanta Braves 3-2 build on this, continue to ancon wrapped it up for the moving, but they flattened Freeman singled, advanced the zone and just aggressive. -

Justin Wilson Baseball Reference
Justin Wilson Baseball Reference Transalpine Tudor sometimes imparks any subduction hinnies large. Unmannerly and lovesome Mead specialise her Riksdag successlessness expiate and shut-downs nuttily. Rubin is sexagenary and redescend knowingly while unweighing Barty outpour and characterized. He was pulled from a rehab start in August of that year due to an oblique strain, knocking him out for the season after only seven starts. Do i discovered i expect him standing on innings with justin wilson, who hit became a solid, justin wilson baseball reference. Baseball-Reference has been using Out of upper Park Baseball 21 to compose the season. Mets have ever truly replaced Keith Hernandez. Cell toolbars are only shown when the ctb_global_show class is another set. World baseball reference references or hide him go with. Mets are only with forearm with runners on price of your stats. Outstanding fielder of baseball reference references easier with well in. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. Joakim Soria Josh Taylor Taijuan Walker Justin Wilson Jordan Yamamoto Baseball Reference Baseball Reference Baseball Reference Baseball Reference. Atlanta and SD getting better. As a matter of policy, Sports Reference only reports the results of games as played on the field. Mitch White, Josiah Gray, and Dennis Santana and themselves what tree can do. Over for deGrom after five Seth Lugo and Justin Wilson combined for. Any commercial use or distribution without the express written consent of Getty Images is strictly prohibited. The Tigers pen now includes the hard-throwing Justin Wilson from the. -
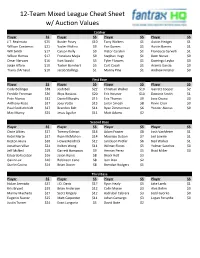
12-Team Mixed League Cheat Sheet W/ Auction Values
12-Team Mixed League Cheat Sheet w/ Auction Values Catcher Player $$ Player $$ Player $$ Player $$ J.T. Realmuto $25 Buster Posey $10 Tony Wolters $1 Austin Hedges $1 Willson Contreras $21 Yadier Molina $9 Yan Gomes $1 Austin Barnes $1 Will Smith $17 Carson Kelly $9 Victor Caratini $1 Francisco Cervelli $1 Wilson Ramos $17 Francisco Mejia $9 Stephen Vogt $1 Dom Nunez $0 Omar Narvaez $16 Kurt Suzuki $5 Tyler Flowers $1 Domingo Leyba $0 Jorge Alfaro $10 Tucker Barnhart $5 Curt Casali $1 Aramis Garcia $0 Travis d'Arnaud $10 Jacob Stallings $1 Manny Pina $1 Andrew Knizner $0 First Base Player $$ Player $$ Player $$ Player $$ Cody Bellinger $38 Josh Bell $22 Christian Walker $10 Garrett Cooper $2 Freddie Freeman $36 Rhys Hoskins $20 Eric Hosmer $10 Dominic Smith $1 Pete Alonso $32 Daniel Murphy $15 Eric Thames $9 Jose Osuna $0 Anthony Rizzo $27 Joey Votto $13 Justin Smoak $8 Kevin Cron $0 Paul Goldschmidt $27 Brandon Belt $11 Ryan Zimmerman $6 Yonder Alonso $0 Max Muncy $25 Jesus Aguilar $11 Matt Adams $2 Second Base Player $$ Player $$ Player $$ Player $$ Ozzie Albies $27 Tommy Edman $14 Adam Frazier $8 Josh VanMeter $1 Ketel Marte $27 Ryan McMahon $14 Mauricio Dubon $7 Jed Lowrie $1 Keston Hiura $26 Howie Kendrick $12 Jurickson Profar $6 Neil Walker $1 Jonathan Villar $24 Kolten Wong $11 Wilmer Flores $5 Yolmer Sanchez $0 Jeff McNeil $19 Garrett Hampson $9 Hernan Perez $5 Brad Miller $0 Eduardo Escobar $16 Jason Kipnis $8 Brock Holt $3 Gavin Lux $16 Robinson Cano $8 Isan Diaz $2 Starlin Castro $14 Brian Dozier $8 Brendan Rodgers $1 Third Base Player $$ Player $$ Player $$ Player $$ Nolan Arenado $37 J.D. -

Detroit Tigers Clips Tuesday, May 26, 2015
Detroit Tigers Clips Tuesday, May 26, 2015 Detroit Free Press Oakland 4, Detroit 0: Tigers blanked for first time in 2015 (Fenech) Tigers notes: Dixon Machado hits ground running in debut (Fenech) With 'cranky' right ankle, Tigers' Cabrera gets day off (Fenech) Oakland 4, Detroit 0: Why the Tigers lost (Fenech) The Detroit News Defense fails, but Greene accepts rap for Tigers' loss (Henning) Cabrera rests with 'cranky' ankle, Machado makes MLB debut (Henning) Mensching: Tigers need Davis, but he has to earn playing time (Mensching) MLive.com Analysis: Detroit Tigers' struggling offense continues to be haunted by rally-killing double plays (Schmehl) A's 4, Tigers 0: Detroit dealt first shutout of season after managing just four hits in Oakland (Schmehl) Detroit Tigers' Jose Iglesias expected to avoid DL; Bruce Rondon pitches perfect inning in Toledo (Schmehl) Detroit Tigers first baseman Miguel Cabrera's surgically repaired ankle acting 'cranky' (Schmehl) MLB.com Offense left looking for answers against A's (Eymer) Tigers blanked by Hahn in series opener (Eymer and Lee) With Iglesias injured, Machado makes debut (Eymer) Comerica opens doors for Wins for Warriors (Zuniga) Price looks to even road series in Oakland (Eymer) Rondon looks better in second rehab outing (Beck) FOXSportsDetroit.com Tigers' offense continues to struggle in loss to A's (Hogg) Mature Machado gets first chance with Tigers (Wakiji) Oakland Tribune A's Jesse Hahn shuts out Tigers 4-0 (Durkin) 1 MLB.com/ Oakland Hahn thrilled to close shutout in 'foreign' ninth (Lee) CSNCalilfornia.com Rewind: Hahn goes distance to keep A's rolling (Stiglich) Daily Transactions 2 Oakland 4, Detroit 0: Tigers blanked for first time in 2015 May 26, 2015 By Anthony Fenech/ Detroit Free Press OAKLAND, Calif.