Obfuscating Gender in Social Media Writing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ice Cube, Westward Ho
Ice Cube, Westward Ho [Ice Cube:] Check it hoe shut your mouth and get naked I'm connected plus I'm makin' hit records So, if you wanna win hop in and take a spin That's W.C. and Mack 10 What's your name girlfriend You can have some fun wit us lay in the sun wit us Pack a gun wit us and make a run wit us To these illegal amigos who wanna buy bald eagles Out my regals we shoppin' at Spiegels So what you wanna do Decision, decisions And what you think about dick and pussy collisions You're a irrisistable bitch and all that Me I'm rich as fuck plus I smell like yack so come on [Chorus 2x:] Irristable bitch let's go Where we goin' Westward ho [Mack 10:] A nigga gots to get chose it's a house full of hoes I suppose at least one of those want Mister flossy with the kilos You know it's quick fast shit it's all about the cash Pauveted Rolex' and Benz' in the S class Don't get it twisted nigga you know the word Cube got the herb and I don't fuck with nothin' less than a bird I make yo whole crew scatter what ya say don't matter Cause nigga you's a punk so tell yo bitch I need to holler at her I take fo shows hop in my Benzo I stomp my Chuck to the flo as I head Westward with yo ho It's Mack 1-0 so fuck what she say I put it down the G way I'm gettin' head on the freeway. -
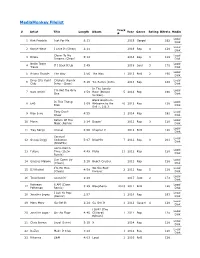
Mediamonkey Filelist
MediaMonkey Filelist Track # Artist Title Length Album Year Genre Rating Bitrate Media # Local 1 Kirk Franklin Just For Me 5:11 2019 Gospel 182 Disk Local 2 Kanye West I Love It (Clean) 2:11 2019 Rap 4 128 Disk Closer To My Local 3 Drake 5:14 2014 Rap 3 128 Dreams (Clean) Disk Nellie Tager Local 4 If I Back It Up 3:49 2018 Soul 3 172 Travis Disk Local 5 Ariana Grande The Way 3:56 The Way 1 2013 RnB 2 190 Disk Drop City Yacht Crickets (Remix Local 6 5:16 T.I. Remix (Intro 2013 Rap 128 Club Intro - Clean) Disk In The Lonely I'm Not the Only Local 7 Sam Smith 3:59 Hour (Deluxe 5 2014 Pop 190 One Disk Version) Block Brochure: In This Thang Local 8 E40 3:09 Welcome to the 16 2012 Rap 128 Breh Disk Soil 1, 2 & 3 They Don't Local 9 Rico Love 4:55 1 2014 Rap 182 Know Disk Return Of The Local 10 Mann 3:34 Buzzin' 2011 Rap 3 128 Macc (Remix) Disk Local 11 Trey Songz Unusal 4:00 Chapter V 2012 RnB 128 Disk Sensual Local 12 Snoop Dogg Seduction 5:07 BlissMix 7 2012 Rap 0 201 Disk (BlissMix) Same Damn Local 13 Future Time (Clean 4:49 Pluto 11 2012 Rap 128 Disk Remix) Sun Come Up Local 14 Glasses Malone 3:20 Beach Cruiser 2011 Rap 128 (Clean) Disk I'm On One We the Best Local 15 DJ Khaled 4:59 2 2011 Rap 5 128 (Clean) Forever Disk Local 16 Tessellated Searchin' 2:29 2017 Jazz 2 173 Disk Rahsaan 6 AM (Clean Local 17 3:29 Bleuphoria 2813 2011 RnB 128 Patterson Remix) Disk I Luh Ya Papi Local 18 Jennifer Lopez 2:57 1 2014 Rap 193 (Remix) Disk Local 19 Mary Mary Go Get It 2:24 Go Get It 1 2012 Gospel 4 128 Disk LOVE? [The Local 20 Jennifer Lopez On the -

Lil Wayne, Rich As Fuck (Ft. 2 Chainz)
Lil Wayne, Rich As Fuck (ft. 2 Chainz) [Lil Wayne:] AK on my night stand, right next to that bible But I swear with these 50 shots, I'll shoot it out with 5-0 Pockets gettin too fat, no weight watchers no lipo Money talks, bullshit walks on a motherfucking tight rope And I make that pussy tap out, I knock that pussy out cold Nigga you get beat the crap out but that's just how the dice roll These hoes want that hose pipe, so I give all these hoes pipe She get on that dick and stay on, all night like porch lights Lets do it, fuck talking, we out here we ballin And I'm spraying that on these rusty niggas like WD-40 We fucked up, we Truk'd up, no if ands or but fucks Bitch niggas go behind yo back like nun-chucks and that's fucked up But my hoes down, my cups up, my niggas down for whatever These bitches think they're too fly well tell em hoes I pluck feathers I'm Tunechi, Young Tunechi, I wear Trukfit fuck Gucci She's blowing kisses at me with her pussy lips, smooches And that's 2 Chainz... [2 Chainz & Lil Wayne:] Look at you, now look at us All my niggas look rich as fuck All my niggas live rich as fuck All my niggas look rich as fuck /2x [Lil Wayne:] Never talk to the cops, I dont speak pig latin I turn the penny to a motherfucking Janet Jackson Tell the bitches that be hatin I ain't got no worries I just wanna hit and run like I ain't got insurance Ho whats yo name whats yo sign, Zodiac Killer All rats gotta die, even Master Splinter, yeah Murder 187 I be killing them bitches I hope all dogs go to heaven And I got xanax, percocet, promethazine -

Songs by Artist
Songs by Artist Title Title (Hed) Planet Earth 2 Live Crew Bartender We Want Some Pussy Blackout 2 Pistols Other Side She Got It +44 You Know Me When Your Heart Stops Beating 20 Fingers 10 Years Short Dick Man Beautiful 21 Demands Through The Iris Give Me A Minute Wasteland 3 Doors Down 10,000 Maniacs Away From The Sun Because The Night Be Like That Candy Everybody Wants Behind Those Eyes More Than This Better Life, The These Are The Days Citizen Soldier Trouble Me Duck & Run 100 Proof Aged In Soul Every Time You Go Somebody's Been Sleeping Here By Me 10CC Here Without You I'm Not In Love It's Not My Time Things We Do For Love, The Kryptonite 112 Landing In London Come See Me Let Me Be Myself Cupid Let Me Go Dance With Me Live For Today Hot & Wet Loser It's Over Now Road I'm On, The Na Na Na So I Need You Peaches & Cream Train Right Here For You When I'm Gone U Already Know When You're Young 12 Gauge 3 Of Hearts Dunkie Butt Arizona Rain 12 Stones Love Is Enough Far Away 30 Seconds To Mars Way I Fell, The Closer To The Edge We Are One Kill, The 1910 Fruitgum Co. Kings And Queens 1, 2, 3 Red Light This Is War Simon Says Up In The Air (Explicit) 2 Chainz Yesterday Birthday Song (Explicit) 311 I'm Different (Explicit) All Mixed Up Spend It Amber 2 Live Crew Beyond The Grey Sky Doo Wah Diddy Creatures (For A While) Me So Horny Don't Tread On Me Song List Generator® Printed 5/12/2021 Page 1 of 334 Licensed to Chris Avis Songs by Artist Title Title 311 4Him First Straw Sacred Hideaway Hey You Where There Is Faith I'll Be Here Awhile Who You Are Love Song 5 Stairsteps, The You Wouldn't Believe O-O-H Child 38 Special 50 Cent Back Where You Belong 21 Questions Caught Up In You Baby By Me Hold On Loosely Best Friend If I'd Been The One Candy Shop Rockin' Into The Night Disco Inferno Second Chance Hustler's Ambition Teacher, Teacher If I Can't Wild-Eyed Southern Boys In Da Club 3LW Just A Lil' Bit I Do (Wanna Get Close To You) Outlaw No More (Baby I'ma Do Right) Outta Control Playas Gon' Play Outta Control (Remix Version) 3OH!3 P.I.M.P. -

They Have Something to Blame Everything On.'
VOLUME FOURTEEN ISSUE SEVEN 10 January 2000 'I envy people who drink . They have something to blame everything on.' - Oscar Levant World Still Crippled One Yea r After Devastating Y2K Bu g Humanity Still Searching For Resaon to Go On in Desolate Horrorscap e Wasteland Once Known as Earth (AP ) No recovery efforts have been successful tion to Pitt's wife's short appearance on the for dense human populance . The North round the globe, it is another deso - yet, mostly due to the great political insta - balcony before the Royal couple left th e West Coast of North America's greates t late, unbearable day for the few hud - bility of the entire planet. The constantly balcony and returned to their chambers to urban area, Abbotsford, invites all it's citi- led survivors of Judgement Day, changing parade of `World Dictators' hav e continue their state-sanctioned repopula- zens to take part in it's first annual raisin g the day that all computers turned on their made it difficult to direct any effor t tion of the earth. of a commemorative Pile of Suffering , human masters . towards recovery of any sort of livable con- But what of the common people? How are which will mark another year of horrid , ditions. But there is cause for celebration today . they spending Judgement Day's firs t dreary existence on a cold and barren plan- et. For today is the one year to the day sinc e At this point, there are 9 known `Worl d anniversary ? modern society as we knew it came to a Dictators' who claim to be the single, dom- Bill Gates, CEO of the former grea t `Yes my brothers,' the Grand General of screeching halt. -

Exploring the Use of African American Rhetorical Strategies in the Composition Classroom
Teachers Use of Own Languages (TUOOLS): Exploring the Use of African American Rhetorical Strategies in the Composition Classroom by Wonderful Faison April, 2014 Director of Thesis: William P. Banks, PhD Major Department: English This thesis explores how different African American Rhetorical Strategies are used by African American teachers in a first year college composition classroom. This thesis shows how these different strategies present in different public media, such as in public speeches, and then transitions into how these strategies are employed by teachers in the writing classroom. This thesis argues that African American Rhetorical Strategies are often used by African American teachers as a tools to help foster a student centered pedagogy. Teachers Use of Own Languages (TUOOLS): Exploring the Use of African American Rhetorical Strategies in the Composition Classroom A Thesis Presented To the Faculty of the Department of English East Carolina University In Partial Fulfillment of the Requirements for the Degree Master of Arts in English by Wonderful Faison April, 2014 © Wonderful Faison, 2014 TITLE by Your Name Here APPROVED BY: DIRECTOR OF DISSERTATION/THESIS: _______________________________________________________ (Name, Degree Here) COMMITTEE MEMBER: ________________________________________________________ (Name, Degree Here) COMMITTEE MEMBER: _______________________________________________________ (Name, Degree Here) CHAIR OF THE DEPARTMENT OF (Put Department Name Here): __________________________________________________ (Name, Degree Here) DEAN OF THE GRADUATE SCHOOL: _________________________________________________________ Paul J. Gemperline, PhD Dedication I dedicate this thesis to my father, who encouraged me to take my education as far as possible; my brothers and sister, who supported me through this process; and to my mother, who though far from my life, is never far from my heart. -

Journal of Hip Hop Studies
et al.: Journal of Hip Hop Studies Published by VCU Scholars Compass, 2017 1 Journal of Hip Hop Studies, Vol. 4 [2017], Iss. 1, Art. 1 Editor in Chief: Daniel White Hodge, North Park University Senior Editorial Advisory Board: Anthony Pinn, Rice University James Paterson, Lehigh University Book Review Editor: Gabriel B. Tait, Arkansas State University Associate Editors: Cassandra Chaney, Louisiana State University Jeffrey L. Coleman, St. Mary’s College of Maryland Monica Miller, Lehigh University Associate & Copy Editor: Travis Harris, Doctoral Candidate, College of William and Mary Editorial Board: Dr. Rachelle Ankney, North Park University Dr. Shanté Paradigm Smalls, St. John’s University (NYC) Dr. Jim Dekker, Cornerstone University Ms. Martha Diaz, New York University Mr. Earle Fisher, Rhodes College/Abyssinian Baptist Church, United States Mr. Jon Gill, Claremont University Dr. Daymond Glenn, Warner Pacific College Dr. Deshonna Collier-Goubil, Biola University Dr. Kamasi Hill, Interdenominational Theological Center Dr. Andre Johnson, Memphis Theological Seminary Dr. David Leonard, Washington State University Dr. Terry Lindsay, North Park University Ms. Velda Love, North Park University Dr. Anthony J. Nocella II, Hamline University Dr. Priya Parmar, SUNY Brooklyn, New York Dr. Soong-Chan Rah, North Park University Dr. Rupert Simms, North Park University Dr. Darron Smith, University of Tennessee Health Science Center Dr. Jules Thompson, University Minnesota, Twin Cities Dr. Mary Trujillo, North Park University Dr. Edgar Tyson, Fordham University Dr. Ebony A. Utley, California State University Long Beach, United States Dr. Don C. Sawyer III, Quinnipiac University https://scholarscompass.vcu.edu/jhhs/vol4/iss1/1 2 et al.: Journal of Hip Hop Studies Sponsored By: North Park Universities Center for Youth Ministry Studies (http://www.northpark.edu/Centers/Center-for-Youth-Ministry-Studies) Save The Kids Foundation (http://savethekidsgroup.org/) Published by VCU Scholars Compass, 2017 3 Journal of Hip Hop Studies, Vol. -

Download Bitclub.Indictment2.Pdf
,, RECEIVED FILED 2017R6}6~,(b{vF2.QM}/JLH VV UNITED STATES DISTRICTCOUR DEC O5 2019 AT 8:30 -=-=-~,,_,,..,...,_.___ M DISTRICT OF NEW JERSEY i WILLIAM T. WALSH, CLERK . w_~T 8:30 .. f _..c; i!J -f M WILLIAM T. WALSH CLERK UNITED STATES OF AMERICA Hon. V. Criminal Number: /'f- '177 Cc.cc~ ADIAH SINCLAIR WEEKS, 18 u.s.c. § 371 JOSEPH FRANK ABEL, and 18 u.s.c. § 1349 SILVIU CATALIN BALACI INDICTMENT The Grand Jury in and for the District of New J ersey, sitting at Newark, charges: COUNT ONE (Conspiracy to Commit Wire Fraud - 18 U.S.C. § 1349) 1. At times relevant to this Indictment: Individuals and Entities a. BitClub Network ("BCN") was a worldwide fraudulent scheme that solicited money from investors in exchange for shares of pooled investments in cryptocurrency mining and that rewarded existing investors for recruiting n ew investors. b. Defendant MATTHEW BRENT GOETTSCHE created and operated BCN. C. Defendant created, operated, and promoted BCN. d. Defendant JOBADIAH SINCLAIR WEEKS promoted BCN. e. Defendant SILVIU CATALINBAIACI created and operated BCN. BAIACI also served as programmer for BCN. Relevant Terminology f. "Cryptocurrency" was a digital representation of value that could be traded and functioned as a medium of exchange; a unit of account; and a store of value. Its value was decided by consensus within the community of users of the cryptocurrency. g. "Bitcoin" was a type of cryptocurrency. Bitcoin were generated and controlled through computer software operating via a decentralized, peer-to-peer network. Bitcoin could be used for purchases or exchanged for other currency on currency exchanges. -

On and Off the Stage at Atlanta Greek Picnic: Performances of Collective
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by DigitalCommons@Florida International University Florida International University FIU Digital Commons FIU Electronic Theses and Dissertations University Graduate School 3-20-2015 On and Off the tS age at Atlanta Greek Picnic: Performances of Collective Black Middle-Class Identities and the Politics of Belonging Synatra A. Smith Florida International University, [email protected] Follow this and additional works at: http://digitalcommons.fiu.edu/etd Part of the Social and Cultural Anthropology Commons Recommended Citation Smith, Synatra A., "On and Off the tS age at Atlanta Greek Picnic: Performances of Collective Black Middle-Class Identities and the Politics of Belonging" (2015). FIU Electronic Theses and Dissertations. Paper 1906. http://digitalcommons.fiu.edu/etd/1906 This work is brought to you for free and open access by the University Graduate School at FIU Digital Commons. It has been accepted for inclusion in FIU Electronic Theses and Dissertations by an authorized administrator of FIU Digital Commons. For more information, please contact [email protected]. FLORIDA INTERNATIONAL UNIVERSITY Miami, Florida ON AND OFF THE STAGE AT ATLANTA GREEK PICNIC: PERFORMANCES OF COLLECTIVE BLACK MIDDLE-CLASS IDENTITIES AND THE POLITICS OF BELONGING A dissertation submitted in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY in GLOBAL AND SOCIOCULTURAL STUDIES by Synatra A. Smith 2015 To: Dean Michael R. Heithaus College of Arts and Sciences This dissertation, written by Synatra A. Smith, and entitled On and Off the Stage at Atlanta Greek Picnic: Performances of Collective Black Middle-Class Identities and the Politics of Belonging, having been approved in respect to style and intellectual content, is referred to you for judgment. -

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
Case 3:18-cv-00124-MEJ Document 1 Filed 01/05/18 Page 1 of 81 1 Nathaniel Sterling, State Bar No. 215734 STERLING LAW FIRM 2 4790 Dewey Drive, Suite A Fair Oaks, California 95628 3 Phone: 916-801-4386 4 Attorney for Plaintiff, Erika Wong 5 6 UNITED STATES DISTRICT COURT 7 FOR THE NORTHERN DISTRICT OF CALIFORNIA 8 9 ERIKA WONG CASE NO.: 10 COMPLAINT FOR DAMAGES Plaintiff, BASED ON: 11 v. 1. Misclassification of 12 Employee as Independent ANTHONY LEVANDOWSKI, and DOES 1 Contractor 13 through 10, inclusive, 2. Violation of Bus. & Prof. Code Section 17200 et seq. 14 3. Fraud and Deceit (Civil Defendant. Code 1709-1710; 1534) 15 4. Failure to Pay Wages, Breaching Written, Oral 16 and/or Implied Contract 5. Breach of Written and/or 17 Oral and/or Implied Contract 18 6. Negligence causing employment damages and 19 mental and/or emotional distress 20 7. Intentional Infliction of Emotional Distress 21 8. Negligent and/or Intentional Interference with 22 Prospective Economic Advantage/Relations 23 9. Negligence Per se for Violating Statutes 24 10. Wrongful Demotion 11. Breach of Implied Covenant FIRM 25 of Good Faith and Fair 4386 RIVE 95628 - D Dealing CA LAW 801 , - EWEY 26 12. Retaliation against protected D AKS 916 O action of employee in 4790 AIR TEL F 27 Violation of FEHA Cal Gov Code 12940(h) 28 13. Discrimination and STERLING -1- COMPLAINT FOR DAMAGES Case 3:18-cv-00124-MEJ Document 1 Filed 01/05/18 Page 2 of 81 1 Harassment in violation of FEHA Cal. -

Downloading Music Via Various (Mostly Pirate) Services, Such As Limewire Helped to Push It Still Further
A University of Sussex PhD thesis Available online via Sussex Research Online: http://sro.sussex.ac.uk/ This thesis is protected by copyright which belongs to the author. This thesis cannot be reproduced or quoted extensively from without first obtaining permission in writing from the Author The content must not be changed in any way or sold commercially in any format or medium without the formal permission of the Author When referring to this work, full bibliographic details including the author, title, awarding institution and date of the thesis must be given Please visit Sussex Research Online for more information and further details LIFE ON ROAD: Symbolic Struggle & The Munpain Yusef Bakkali Thesis submitted for PhD Examination University of Sussex May 2017 2 Declaration I hereby declare that this thesis has not been and will not be, submitted in whole or in part to another University for the award of any other degree. Signed………………………………………. 3 Acknowledgements This thesis came together when, by necessity, I had to turn to my community for support. So for that reason, before anyone else; I would like to thank those who took part in this thesis. I owe a debt of gratitude to Susie Scott and Rachel Thomson for their supervision during my PhD process. Admittedly I might not have been the easiest student, but both of my supervisors stuck with me and supported me, helping me to believe it was possible. For the same reason I’d like to thank Luke Martell who supervised me as an undergraduate and helped me to apply for my PhD studentship; always a generous friend and mentor. -

Karaoke Cloud Song Book
Karaoke Cloud Songs by Artist Karaoke Shack Song Books Title DiscID Title DiscID 10CC Afrojack & Wrabel I'm Not In Love KCD1405-2-01 Ten Feet Tall KCD-79337 I'm Not In Love KCD-79404 Ten Feet Tall KCDPR1403-1- Things We Do For Love KCD1406-1-01 10 Things We Do For Love KCD-79474 Alabama 1975, The Backwoods Boogie KCD-81109 Chocolate KCD-79256 Wasn't Through Lovin' You Yet KCD-81254 Chocolate KCDPR1402-2- Alan Jackson 06 Jim And Jack And Hank KCD-80966 2 Chainz & Drake & Lil' Wayne You Go Your Way KCD-75102 I Do It KCDPR1310-3- You Go Your Way KCDC1305-09 04 Alesia Cara 2 Chainz & Drake & Lil' Wayne (Trio) Wild Things KCD-81304 I Do It KCD-78986 Alex Clare 2 Chainz & Wiz Khalifa Too Close KCDPR1304-10 We Own It (Fast & Furious) KCDPR1308-3- Too Close (Sunfly) KCD-75019 09 Alexis Spight 5 Seconds Of Summer Imagine Me KCD-75109 She Looks So Perfect KCD1408-2-02 Imagine Me KCDPR1305-06 She Looks So Perfect KCD-79638 Alice Cooper 50 Cent & Eminem & Adam Levine Elected KCD1405-2-03 My Life (Clean) KCDU1302-1- Elected KCD-79415 06 No More Mr. Nice Guy KCD1405-2-04 50 Cent & Eminem & Adam Levine (Duet) No More Mr. Nice Guy KCD-79406 My Life (Clean) (SBI) KCD-74976 Alicia Keys & Maxwell A$AP Rocky & Drake & 2 Chainz & Kendrick Lamar (Duet) Fire We Make KCDU1306-03 Fuckin' Problems (Clean) (SBI) KCD-74974 Alicia Keys & Maxwell (Duet) A$AP Rocky & Kendrick Lamar & Joey Bada$$ & Yelawolf, Danny Brown, Action Bronson & Big Krit (Duet) Fire We Make (SBI) KCD-75137 1 Train KCD-78139 Alicia Keys & Nicki Minaj Aaron Lewis Girl On Fire (Inferno Version)