Coding of Still Pictures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ITU-T Rec. T.800 (08/2002) Information Technology
INTERNATIONAL TELECOMMUNICATION UNION ITU-T T.800 TELECOMMUNICATION (08/2002) STANDARDIZATION SECTOR OF ITU SERIES T: TERMINALS FOR TELEMATIC SERVICES Information technology – JPEG 2000 image coding system: Core coding system ITU-T Recommendation T.800 INTERNATIONAL STANDARD ISO/IEC 15444-1 ITU-T RECOMMENDATION T.800 Information technology – JPEG 2000 image coding system: Core coding system Summary This Recommendation | International Standard defines a set of lossless (bit-preserving) and lossy compression methods for coding bi-level, continuous-tone grey-scale, palletized color, or continuous-tone colour digital still images. This Recommendation | International Standard: – specifies decoding processes for converting compressed image data to reconstructed image data; – specifies a codestream syntax containing information for interpreting the compressed image data; – specifies a file format; – provides guidance on encoding processes for converting source image data to compressed image data; – provides guidance on how to implement these processes in practice. Source ITU-T Recommendation T.800 was prepared by ITU-T Study Group 16 (2001-2004) and approved on 29 August 2002. An identical text is also published as ISO/IEC 15444-1. ITU-T Rec. T.800 (08/2002 E) i FOREWORD The International Telecommunication Union (ITU) is the United Nations specialized agency in the field of telecommunications. The ITU Telecommunication Standardization Sector (ITU-T) is a permanent organ of ITU. ITU-T is responsible for studying technical, operating and tariff questions and issuing Recommendations on them with a view to standardizing telecommunications on a worldwide basis. The World Telecommunication Standardization Assembly (WTSA), which meets every four years, establishes the topics for study by the ITU-T study groups which, in turn, produce Recommendations on these topics. -

Free Lossless Image Format
FREE LOSSLESS IMAGE FORMAT Jon Sneyers and Pieter Wuille [email protected] [email protected] Cloudinary Blockstream ICIP 2016, September 26th DON’T WE HAVE ENOUGH IMAGE FORMATS ALREADY? • JPEG, PNG, GIF, WebP, JPEG 2000, JPEG XR, JPEG-LS, JBIG(2), APNG, MNG, BPG, TIFF, BMP, TGA, PCX, PBM/PGM/PPM, PAM, … • Obligatory XKCD comic: YES, BUT… • There are many kinds of images: photographs, medical images, diagrams, plots, maps, line art, paintings, comics, logos, game graphics, textures, rendered scenes, scanned documents, screenshots, … EVERYTHING SUCKS AT SOMETHING • None of the existing formats works well on all kinds of images. • JPEG / JP2 / JXR is great for photographs, but… • PNG / GIF is great for line art, but… • WebP: basically two totally different formats • Lossy WebP: somewhat better than (moz)JPEG • Lossless WebP: somewhat better than PNG • They are both .webp, but you still have to pick the format GOAL: ONE FORMAT THAT COMPRESSES ALL IMAGES WELL EXPERIMENTAL RESULTS Corpus Lossless formats JPEG* (bit depth) FLIF FLIF* WebP BPG PNG PNG* JP2* JXR JLS 100% 90% interlaced PNGs, we used OptiPNG [21]. For BPG we used [4] 8 1.002 1.000 1.234 1.318 1.480 2.108 1.253 1.676 1.242 1.054 0.302 the options -m 9 -e jctvc; for WebP we used -m 6 -q [4] 16 1.017 1.000 / / 1.414 1.502 1.012 2.011 1.111 / / 100. For the other formats we used default lossless options. [5] 8 1.032 1.000 1.099 1.163 1.429 1.664 1.097 1.248 1.500 1.017 0.302� [6] 8 1.003 1.000 1.040 1.081 1.282 1.441 1.074 1.168 1.225 0.980 0.263 Figure 4 shows the results; see [22] for more details. -

Quadtree Based JBIG Compression
Quadtree Based JBIG Compression B. Fowler R. Arps A. El Gamal D. Yang ISL, Stanford University, Stanford, CA 94305-4055 ffowler,arps,abbas,[email protected] Abstract A JBIG compliant, quadtree based, lossless image compression algorithm is describ ed. In terms of the numb er of arithmetic co ding op erations required to co de an image, this algorithm is signi cantly faster than previous JBIG algorithm variations. Based on this criterion, our algorithm achieves an average sp eed increase of more than 9 times with only a 5 decrease in compression when tested on the eight CCITT bi-level test images and compared against the basic non-progressive JBIG algorithm. The fastest JBIG variation that we know of, using \PRES" resolution reduction and progressive buildup, achieved an average sp eed increase of less than 6 times with a 7 decrease in compression, under the same conditions. 1 Intro duction In facsimile applications it is desirable to integrate a bilevel image sensor with loss- less compression on the same chip. Suchintegration would lower p ower consumption, improve reliability, and reduce system cost. To reap these b ene ts, however, the se- lection of the compression algorithm must takeinto consideration the implementation tradeo s intro duced byintegration. On the one hand, integration enhances the p os- sibility of parallelism which, if prop erly exploited, can sp eed up compression. On the other hand, the compression circuitry cannot b e to o complex b ecause of limitations on the available chip area. Moreover, most of the chip area on a bilevel image sensor must b e o ccupied by photo detectors, leaving only the edges for digital logic. -

JPEG and JPEG 2000
JPEG and JPEG 2000 Past, present, and future Richard Clark Elysium Ltd, Crowborough, UK [email protected] Planned presentation Brief introduction JPEG – 25 years of standards… Shortfalls and issues Why JPEG 2000? JPEG 2000 – imaging architecture JPEG 2000 – what it is (should be!) Current activities New and continuing work… +44 1892 667411 - [email protected] Introductions Richard Clark – Working in technical standardisation since early 70’s – Fax, email, character coding (8859-1 is basis of HTML), image coding, multimedia – Elysium, set up in ’91 as SME innovator on the Web – Currently looks after JPEG web site, historical archive, some PR, some standards as editor (extensions to JPEG, JPEG-LS, MIME type RFC and software reference for JPEG 2000), HD Photo in JPEG, and the UK MPEG and JPEG committees – Plus some work that is actually funded……. +44 1892 667411 - [email protected] Elysium in Europe ACTS project – SPEAR – advanced JPEG tools ESPRIT project – Eurostill – consensus building on JPEG 2000 IST – Migrator 2000 – tool migration and feature exploitation of JPEG 2000 – 2KAN – JPEG 2000 advanced networking Plus some other involvement through CEN in cultural heritage and medical imaging, Interreg and others +44 1892 667411 - [email protected] 25 years of standards JPEG – Joint Photographic Experts Group, joint venture between ISO and CCITT (now ITU-T) Evolved from photo-videotex, character coding First meeting March 83 – JPEG proper started in July 86. 42nd meeting in Lausanne, next week… Attendance through national -

MPEG Compression Is Based on Processing 8 X 8 Pixel Blocks
MPEG-1 & MPEG-2 Compression 6th of March, 2002, Mauri Kangas Contents: • MPEG Background • MPEG-1 Standard (shortly) • MPEG-2 Standard (shortly) • MPEG-1 and MPEG-2 Differencies • MPEG Encoding and Decoding • Colour sub-sampling • Motion Compensation • Slices, macroblocks, blocks, etc. • DCT • MPEG-2 bit stream syntax • MPEG-2 • Supported Features • Levels • Profiles • DVB Systems 1 © Mauri Kangas 2002 MPEG-1,2.PPT/ 24.02.2002 / Mauri Kangas MPEG Background • MPEG = Motion Picture Expert Group • ISO/IEC JTC1/SC29 • WG11 Motion Picture Experts Group (MPEG) • WG10 Joint Photographic Experts Group (JPEG) • WG7 Computer Graphics Experts Group (CGEG) • WG9 Joint Bi-level Image coding experts Group (JBIG) • WG12 Multimedia and Hypermedia information coding Experts Group (MHEG) • MPEG-1,2 Standardization 1988- • Requirement • System • Video • Audio • Implementation • Testing • Latest MPEG Standardization: MPEG-4, MPEG-7, MPEG-21 2 © Mauri Kangas 2002 MPEG-1,2.PPT/ 24.02.2002 / Mauri Kangas MPEG-1 Standard ISO/IEC 11172-2 (1991) "Coding of moving pictures and associated audio for digital storage media" Video • optimized for bitrates around 1.5 Mbit/s • originally optimized for SIF picture format, but not limited to it: • 352x240 pixels a 30 frames/sec [ NTSC based ] • 352x288 pixels at 25 frames/sec [ PAL based ] • progressive frames only - no direct provision for interlaced video applications, such as broadcast television Audio • joint stereo audio coding at 192 kbit/s (layer 2) System • mainly designed for error-free digital storage media • -
![CISC 3635 [36] Multimedia Coding and Compression](https://docslib.b-cdn.net/cover/4741/cisc-3635-36-multimedia-coding-and-compression-814741.webp)
CISC 3635 [36] Multimedia Coding and Compression
Brooklyn College Department of Computer and Information Sciences CISC 3635 [36] Multimedia Coding and Compression 3 hours lecture; 3 credits Media types and their representation. Multimedia coding and compression. Lossless data compression. Lossy data compression. Compression standards: text, audio, image, fax, and video. Course Outline: 1. Media Types and Their Representations (Week 1-2) a. Text b. Analog and Digital Audio c. Digitization of Sound d. Musical Instrument Digital Interface (MIDI) e. Audio Coding: Pulse Code Modulation (PCM) f. Graphics and Images Data Representation g. Image File Formats: GIF, JPEG, PNG, TIFF, BMP, etc. h. Color Science and Models i. Fax j. Video Concepts k. Video Signals: Component, Composite, S-Video l. Analog and Digital Video: NTSC, PAL, SECAM, HDTV 2. Lossless Compression Algorithms (Week 3-4) a. Basics of Information Theory b. Run-Length Coding c. Variable Length Coding: Huffman Coding d. Basic Fax Compression e. Dictionary Based Coding: LZW Compression f. Arithmetic Coding g. Lossless Image Compression 3. Lossy Compression Algorithms (Week 5-6) a. Distortion Measures b. Quantization c. Transform Coding d. Wavelet Based Coding e. Embedded Zerotree of Wavelet (EZW) Coefficients 4. Basic Audio Compression (Week 7-8) a. Differential Coders: DPCM, ADPCM, DM b. Vocoders c. Linear Predictive Coding (LPC) d. CELP e. Audio Standards: G.711, G.726, G.723, G.728. G.729, etc. 5. Image Compression Standards (Week 9) a. The JPEG Standard b. JPEG 2000 c. JPEG-LS d. Bilevel Image Compression Standards: JBIG, JBIG2 6. Basic Video Compression (Week 10) a. Video Compression Based on Motion Compensation b. Search for Motion Vectors c. -
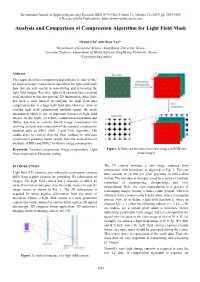
Analysis and Comparison of Compression Algorithm for Light Field Mask
International Journal of Applied Engineering Research ISSN 0973-4562 Volume 12, Number 12 (2017) pp. 3553-3556 © Research India Publications. http://www.ripublication.com Analysis and Comparison of Compression Algorithm for Light Field Mask Hyunji Cho1 and Hoon Yoo2* 1Department of Computer Science, SangMyung University, Korea. 2Associate Professor, Department of Media Software SangMyung University, Korea. *Corresponding author Abstract This paper describes comparison and analysis of state-of-the- art lossless image compression algorithms for light field mask data that are very useful in transmitting and refocusing the light field images. Recently, light field cameras have received wide attention in that they provide 3D information. Also, there has been a wide interest in studying the light field data compression due to a huge light field data. However, most of existing light field compression methods ignore the mask information which is one of important features of light field images. In this paper, we reports compression algorithms and further use this to achieve binary image compression by realizing analysis and comparison of the standard compression methods such as JBIG, JBIG 2 and PNG algorithm. The results seem to confirm that the PNG method for text data compression provides better results than the state-of-the-art methods of JBIG and JBIG2 for binary image compression. Keywords: Lossless compression, Image compression, Light Figure. 2. Basic architecture from raw images to RGB and filed compression, Plenoptic coding mask images INTRODUCTION The LF camera provides a raw image captured from photosensor with microlens, as depicted in Fig. 1. The raw Light field (LF) cameras, also referred to as plenoptic cameras, data consists of 10 bits per pixel precision in little-endian differ from regular cameras by providing 3D information of format. -

File Format Guidelines for Management and Long-Term Retention of Electronic Records
FILE FORMAT GUIDELINES FOR MANAGEMENT AND LONG-TERM RETENTION OF ELECTRONIC RECORDS 9/10/2012 State Archives of North Carolina File Format Guidelines for Management and Long-Term Retention of Electronic records Table of Contents 1. GUIDELINES AND RECOMMENDATIONS .................................................................................. 3 2. DESCRIPTION OF FORMATS RECOMMENDED FOR LONG-TERM RETENTION ......................... 7 2.1 Word Processing Documents ...................................................................................................................... 7 2.1.1 PDF/A-1a (.pdf) (ISO 19005-1 compliant PDF/A) ........................................................................ 7 2.1.2 OpenDocument Text (.odt) ................................................................................................................... 3 2.1.3 Special Note on Google Docs™ .......................................................................................................... 4 2.2 Plain Text Documents ................................................................................................................................... 5 2.2.1 Plain Text (.txt) US-ASCII or UTF-8 encoding ................................................................................... 6 2.2.2 Comma-separated file (.csv) US-ASCII or UTF-8 encoding ........................................................... 7 2.2.3 Tab-delimited file (.txt) US-ASCII or UTF-8 encoding .................................................................... 8 2.3 -

DICOM PS3.5 2021C
PS3.5 DICOM PS3.5 2021d - Data Structures and Encoding Page 2 PS3.5: DICOM PS3.5 2021d - Data Structures and Encoding Copyright © 2021 NEMA A DICOM® publication - Standard - DICOM PS3.5 2021d - Data Structures and Encoding Page 3 Table of Contents Notice and Disclaimer ........................................................................................................................................... 13 Foreword ............................................................................................................................................................ 15 1. Scope and Field of Application ............................................................................................................................. 17 2. Normative References ....................................................................................................................................... 19 3. Definitions ....................................................................................................................................................... 23 4. Symbols and Abbreviations ................................................................................................................................. 27 5. Conventions ..................................................................................................................................................... 29 6. Value Encoding ............................................................................................................................................... -
Lossless Image Compression
Lossless Image Compression C.M. Liu Perceptual Signal Processing Lab College of Computer Science National Chiao-Tung University http://www.csie.nctu.edu.tw/~cmliu/Courses/Compression/ Office: EC538 (03)5731877 [email protected] Lossless JPEG (1992) 2 ITU Recommendation T.81 (09/92) Compression based on 8 predictive modes ( “selection values): 0 P(x) = x (no prediction) 1 P(x) = W 2 P(x) = N 3 P(x) = NW NW N 4 P(x) = W + N - NW 5 P(x) = W + ⎣(N-NW)/2⎦ W x 6 P(x) = N + ⎣(W-NW)/2⎦ 7 P(x) = ⎣(W + N)/2⎦ Sequence is then entropy-coded (Huffman/AC) Lossless JPEG (2) 3 Value 0 used for differential coding only in hierarchical mode Values 1, 2, 3 One-dimensional predictors Values 4, 5, 6, 7 Two-dimensional Value 1 (W) Used in the first line of samples At the beginning of each restart Selected predictor used for the other lines Value 2 (N) Used at the start of each line, except first P-1 Default predictor value: 2 At the start of first line Beginning of each restart Lossless JPEG Performance 4 JPEG prediction mode comparisons JPEG vs. GIF vs. PNG Context-Adaptive Lossless Image Compression [Wu 95/96] 5 Two modes: gray-scale & bi-level We are skipping the lossy scheme for now Basic ideas find the best context from the info available to encoder/decoder estimate the presence/lack of horizontal/vertical features CALIC: Initial Prediction 6 if dh−dv > 80 // sharp horizontal edge X* = N else if dv−dh > 80 // sharp vertical edge X* = W else { // assume smoothness first X* = (N+W)/2 +(NE−NW)/4 if dh−dv > 32 // horizontal edge X* = (X*+N)/2 -

JBIG-Like Coding of Bi-Level Image Data in JPEG-2000
ISO/IEC JTC 1/SC 29/WG1 N1014 Date: 1998-10- 20 ISO/IEC JTC 1/SC 29/WG 1 (ITU-T SG8) Coding of Still Pictures JBIG JPEG Joint Bi-level Image Joint Photographic Experts Group Experts Group TITLE: Report on Core Experiment CodEff26: JBIG-Like Coding of Bi-Level Image Data in JPEG-2000 SOURCE: Faouzi Kossentini ([email protected]) and Dave Tompkins Department of ECE, University of BC, Vancouver, BC, Canada V6T 1Z4 Soeren Forchhammer ([email protected]), Bo Martins and Ole Jensen Department of Telecommunication, TDU, Lyngby, Denmark, DK-2800 Ian Caven, Image Power Inc., Vancouver, BC, Canada V6E 4B1 Paul Howard, AT&T Labs, NJ, USA PROJECT: JPEG-2000 STATUS: Core Experiment Results REQUESTED ACTION: Discussion DISTRIBUTION: 14th Meeting of ISO/IEC JTC1/SC 29/WG1 Contact: ISO/IEC JTC 1/SC 29/WG 1 Convener - Dr. Daniel T. Lee Hewlett-Packard Company, 11000 Wolfe Road, MS42U0, Cupertion, California 95014, USA Tel: +1 408 447 4160, Fax: +1 408 447 2842, E-mail: [email protected] 2 1. Update This document updates results previously reported in WG1N863. Specifically, the upcoming JBIG-2 Verification Model (VM) was used to generate the compression rates in Table 1. These results more accurately reflect the expected bit rates, and include the overhead required for the proper JBIG-2 bitstream formatting. Results may be better in the final implementation, but these results are guaranteed to be attainable with the current VM. The JBIG-2 VM will be available in December 1998. 2. Summary This document presents experimental results that compare the compression performance several JBIG-like coders to the VM0 baseline coder. -

Eb-2013-00233 INCITS International Committee for Information
eb-2013-00233 INCITS International Committee for Information Technology Standards INCITS Secretariat, Information Technology Industry Council (ITI) 1101 K Street, NW, Suite 610, Washington, DC 20005 Date: February 6, 2013 Ref. Doc.: eb-2012-01071 Reply to: Deborah J. Spittle, Associate Manager, Standards Operations Phone: 202-626-5746 Email: [email protected] Notification of Public Review and Comments Register for the Reaffirmations of National Standards in INCITS/L3. The public review period is from February 15, 2013 April 1, 2013. INCITS/ISO/IEC 9281-2:1990[R2008] Information technology - Picture Coding Methods - Part 2: Procedure for Registration INCITS/ISO/IEC 9281-1:1990[R2008] Information technology - Picture Coding Methods - Part 1: Identification INCITS/ISO/IEC 9282-1:1988[R2008] Information technology - Coded Representation of Computer Graphics Images - Part 1: Encoding principles for picture representation in a 7-bit or 8-bit environment INCITS/ISO/IEC 14496-5:2001/AM Information technology - Coding of audio-visual objects - Part 5: 2:2003[R2008] Reference software AMENDMENT 2: MPEG-4 Reference software extensions for XMT and media modes INCITS/ISO/IEC 21000-2:2005[2008] Information technology - Multimedia Framework (MPEG-21) - Part 2: Digital Item Declaration INCITS/ISO/IEC 14496- Information technology - Coding of audio-visual objects - Part 5: 5:2001/AM1:2002[R2008] Reference software - Amendment 1: Reference software for MPEG-4 INCITS/ISO/IEC 13818-2:2000/AM Information technology - Generic coding of moving pictures and 1:2001[R2008]