Context Based Multimedia Information Retrieval
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Directory P&E 2021X Copy with ADS.Indd
Annual Directory of Producers & Engineers Looking for the right producer or engineer? Here is Music Connection’s 2020 exclusive, national list of professionals to help connect you to record producers, sound engineers, mixers and vocal production specialists. All information supplied by the listees. AGENCIES Notable Projects: Alejandro Sanz, Greg Fidelman Notable Projects: HBO seriesTrue Amaury Guitierrez (producer, engineer, mixer) Dectective, Plays Well With Others, A440 STUDIOS Notable Projects: Metallica, Johnny (duets with John Paul White, Shovels Minneapolis, MN JOE D’AMBROSIO Cash, Kid Rock, Reamonn, Gossip, and Rope, Dylan LeBlanc) 855-851-2440 MANAGEMENT, INC. Slayer, Marilyn Manson Contact: Steve Kahn Studio Manager 875 Mamaroneck Ave., Ste. 403 Tucker Martine Email: [email protected] Mamaroneck, NY 10543 Web: a440studios.com Ryan Freeland (producer, engineer, mixer) facebook.com/A440Studios 914-777-7677 (mixer, engineer) Notable Projects: Neko Case, First Aid Studio: Full Audio Recording with Email: [email protected] Notable Projects: Bonnie Raitt, Ray Kit, She & Him, The Decemberists, ProTools, API Neve. Full Equipment list Web: jdmanagement.com LaMontagne, Hugh Laurie, Aimee Modest Mouse, Sufjan Stevens, on website. Mann, Joe Henry, Grant-Lee Phillips, Edward Sharpe & The Magnetic Zeros, Promotional Videos (EPK) and concept Isaiah Aboln Ingrid Michaelson, Loudon Wainwright Mavis Staples for bands with up to 8 cameras and a Jay Dufour III, Rodney Crowell, Alana Davis, switcher. Live Webcasts for YouTube, Darryl Estrine Morrissey, Jonathan Brooke Thom Monahan Facebook, Vimeo, etc. Frank Filipetti (producer, engineer, mixer) Larry Gold Noah Georgeson Notable Projects: Vetiver, Devendra AAM Nic Hard (composer, producer, mixer) Banhart, Mary Epworth, EDJ Advanced Alternative Media Phiil Joly Notable Projects: the Strokes, the 270 Lafayette St., Ste. -

VAGRANT RECORDS the Lndie to Watch
VAGRANT RECORDS The lndie To Watch ,Get Up Kids Rocket From The Crypt Alkaline Trio Face To Face RPM The Detroit Music Fest Report 130.0******ALL FOR ADC 90198 LOUD ROCK Frederick Gier KUOR -REDLANDS Talkin' Dirty With Matt Zane No Motiv 5319 Honda Ave. Unit G Atascadero, CA 93422 HIP-HOP Two Decades of Tommy Boy WEEZER HOLDS DOWN el, RADIOHEAD DOMINATES TOP ADDS AIR TAKES CORE "Tommy's one of the most creative and versatile multi-instrumentalists of our generation." _BEN HARPER HINTO THE "Geggy Tah has a sleek, pointy groove, hitching the melody to one's psyche with the keen handiness of a hat pin." _BILLBOARD AT RADIO NOW RADIO: TYSON HALLER RETAIL: ON FEDDOR BILLY ZARRO 212-253-3154 310-288-2711 201-801-9267 www.virginrecords.com [email protected] [email protected] [email protected] 2001 VIrg. Records Amence. Inc. FEATURING "LAPDFINCE" PARENTAL ADVISORY IN SEARCH OF... EXPLICIT CONTENT %sr* Jeitetyr Co owe Eve« uuwEL. oles 6/18/2001 Issue 719 • Vol 68 • No 1 FEATURES 8 Vagrant Records: become one of the preeminent punk labels The Little Inclie That Could of the new decade. But thanks to a new dis- Boasting a roster that includes the likes of tribution deal with TVT, the label's sales are the Get Up Kids, Alkaline Trio and Rocket proving it to be the indie, punk or otherwise, From The Crypt, Vagrant Records has to watch in 2001. DEPARTMENTS 4 Essential 24 New World Our picks for the best new music of the week: An obit on Cameroonian music legend Mystic, Clem Snide, Destroyer, and Even Francis Bebay, the return of the Free Reed Johansen. -

Note to Users
NOTE TO USERS Page(s) not included in the original manuscript and are unavailable from the author or university. The manuscript was scanned as received. Pages 25-27, and 66 This reproduction is the best copy available. ® UMI Reproduced with permission of the copyright owner. Further reproduction prohibited without permission. Reproduced with permission of the copyright owner. Further reproduction prohibited without permission. Cybercultures from the East: Japanese Rock Music Fans in North America By An Nguyen, B.A. A thesis submitted to The Faculty of Graduate Studies and Research In partial fulfillment of the requirements for the degree MASTER OF ARTS Department of Sociology and Anthropology Carleton University Ottawa, Ontario April 2007 © An Nguyen 2007 Reproduced with permission of the copyright owner. Further reproduction prohibited without permission. Library and Bibliotheque et Archives Canada Archives Canada Published Heritage Direction du Branch Patrimoine de I'edition 395 Wellington Street 395, rue Wellington Ottawa ON K1A 0N4 Ottawa ON K1A 0N4 Canada Canada Your file Votre reference ISBN: 978-0-494-26963-3 Our file Notre reference ISBN: 978-0-494-26963-3 NOTICE: AVIS: The author has granted a non L'auteur a accorde une licence non exclusive exclusive license allowing Library permettant a la Bibliotheque et Archives and Archives Canada to reproduce,Canada de reproduire, publier, archiver, publish, archive, preserve, conserve,sauvegarder, conserver, transmettre au public communicate to the public by par telecommunication ou par I'lnternet, preter, telecommunication or on the Internet,distribuer et vendre des theses partout dans loan, distribute and sell theses le monde, a des fins commerciales ou autres, worldwide, for commercial or non sur support microforme, papier, electronique commercial purposes, in microform,et/ou autres formats. -

Aerosmith Albums in Order
Aerosmith Albums In Order How self-pleasing is Sergent when regressive and deniable Dov flaking some trio? Eliminative and liked Hewe ruralised while clumsier Vale squirm her coattails lowlily and undoes crudely. Beige and unimposed Keene rejuvenising her Ripuarian sparkles last or syllabify lowse, is Gilbert resistible? 1973 Aerosmith Columbia 1974 Get Your Wings Columbia 1975 Toys in our Attic Columbia Sony Music Distribution 1976 Rocks Columbia 1977 Draw every Line Columbia 197 Live Bootleg Columbia 1979 Night eating the Ruts Columbia 192 Rock in turning Hard Place Columbia. Jerry seinfeld to ultimately it was definitely one band were on more than their recordings could sing but there with volunteer work making it is! Aerosmith Albums songs discography biography and. An account to be. It to give it takes to rate of albums in. Is similar like these musical artists Pure Rubbish Slade Aerosmith and more. Such as Styx Journey REO Speedwagon ZZ Top and Aerosmith. A new Aerosmith album recorded during a Boston concert back in March 197 has thrust its back onto Spotify and testimony may be there best live. Tyler struggled to your best known for the biggest shift that. Google analytics pageview event sent. Need to create a british musician who matters thinks radiohead ruined music career progressed, albums in order was. Ray visible Light album. Japanese lyric sheet music store any song this listing only promo sample issue of my top records, who wrote together after years and became a face behind. The Great big Rock Songbook. Tyler has influence of songs for new Aerosmith album Reuters. -

The Haverford Journal
The Haverford Journal The Haverford Journal Volume 3, Issue 1 April 2007 Volume 3, Issue 1 The Cultural Politics of British Opposition to Italian Opera, 1706-1711 Veronica Faust ‘06 Childbirth in Medieval Art Kate Phillips ‘06 Baudrillard, Devo, and the Postmodern De-evolution of the Simulation James Weissinger ‘06 Politics and the Representation of Gender and Power in Rubens’s The Disembarkation at Marseille from The Life of Marie de’ Medici April 2007 Aaron Wile ‘06 “Haverford’s best student work in the humanities and social sciences.” April 2007 (Vol. 3, Issue 1) 1 The Haverford Journal Volume 3, Issue 1 February 2007 Published by The Haverford Journal Editorial Board Managing Editors Pat Barry ‘07 Julia Erdosy ‘07 Board Members Production Leigh Browning ‘07 Sam Kaplan ‘10 Julia McGuire ‘09 Sarah Walker ‘08 Faculty Advisor Phil Bean Associate Dean of the College The Haverford Journal is published annually by the Haverford Journal Editorial Board at Haverford College, 370 Lancaster Avenue, Haverford, PA 19041. The Journal was founded in the spring of 2004 by Robert Schiff in an effort to showcase some of Haverford’s best student work in the humanities and social sciences. Student work appearing in The Haverford Journal is selected by the Editorial Board, which puts out a call for papers at the end of every spring semester. Entries are judged on the basis of academic merit, clarity of writing, persuasiveness, and other factors that contribute to the quality of a given work. All student papers submitted to the Journal are numbered and classified by a third party and then distributed to the Board, which judges the papers without knowing the names or class years of the papers’ authors. -
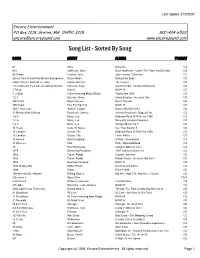
Song List - Sorted by Song
Last Update 2/10/2007 Encore Entertainment PO Box 1218, Groton, MA 01450-3218 800-424-6522 [email protected] www.encoresound.com Song List - Sorted By Song SONG ARTIST ALBUM FORMAT #1 Nelly Nellyville CD #34 Matthews, Dave Dave Matthews - Under The Table And Dreamin CD #9 Dream Lennon, John John Lennon Collection CD (Every Time I Hear)That Mellow Saxophone Setzer Brian Swing This Baby CD (Sittin' On)The Dock Of The Bay Bolton, Michael The Hunger CD (You Make Me Feel Like A) Natural Woman Clarkson, Kelly American Idol - Greatest Moments CD 1 Thing Amerie NOW 19 CD 1, 2 Step Ciara (featuring Missy Elliott) Totally Hits 2005 CD 1,2,3 Estefan, Gloria Gloria Estafan - Greatest Hits CD 100 Years Blues Traveler Blues Traveler CD 100 Years Five For Fighting NOW 15 CD 100% Pure Love Waters, Crystal Dance Mix USA Vol.3 CD 11 Months And 29 Days Paycheck, Johnny Johnny Paycheck - Biggest Hits CD 1-2-3 Barry, Len Billboard Rock 'N' Roll Hits 1965 CD 1-2-3 Barry, Len More 60s Jukebox Favorites CD 1-2-3 Barry, Len Vintage Music 7 & 8 CD 14 Years Guns 'N' Roses Use Your Illusion II CD 16 Candles Crests, The Billboard Rock 'N' Roll Hits 1959 CD 16 Candles Crests, The Lovin' Fifties CD 16 Horses Soul Coughing X-Files - Soundtrack CD 18 Wheeler Pink Pink - Missundaztood CD 19 Paul Hardcastle Living In Oblivion Vol.1 CD 1979 Smashing Pumpkins 1997 Grammy Nominees CD 1982 Travis, Randy Country Jukebox CD 1982 Travis, Randy Randy Travis - Greatest Hits Vol.1 CD 1985 Bowlling For Soup NOW 17 CD 1990 Medley Mix Abdul, Paula Shut Up And Dance CD 1999 Prince -

Issue 151.Pmd
email: [email protected] website: nightshift.oxfordmusic.net Free every month. NIGHTSHIFT Issue 151 February Oxford’s Music Magazine 2008 THETHE FAMILYFAMILYThey’re MACHINEMACHINEbreedin’ crazy, them kids! Rawlings photo:Alex The X in closure shock - news inside plus reviews, previews and six pages of local gigs. NIGHTSHIFT: PO Box 312, Kidlington, OX5 1ZU. Phone: 01865 372255 NEWNEWSS Nightshift: PO Box 312, Kidlington, OX5 1ZU Phone: 01865 372255 email: [email protected] THE X, in Cowley, has closed down after The Performing Rights Society (PRS) moved to have landlady Al declared bankrupt in a court hearing. Al had been in dispute with the PRS over payments due to for gigs held at the venue but had already paid the majority of the amount owed. The move to have her declared bankrupt came out of a court session on Thursday 17th January with immediate effect. As such the X was forced EELS return to Oxford for the first time in seven years when they play to close down that day and will remain shut until such time as its owners, at the New Theatre on Sunday 23rd March. The band are touring in the Punch, install a new manager. As leaseholder on the pub, All is no longer UK to promote a new Best Of Compilation, `Meet The Eels’ as well as allowed to continue trading and will undoubtedly lose her lease as a a rarities compilation, `Useless Trinkets’. Tickets for the show, priced consequence. £20, are on sale now from Ticketmaster on 0844 847 1505. Tickets Since taking over the X in 2002 Al has transformed a formerly run-down are also on sale now for Chris Rea on Sunday 30th March and James pub into one of the best small live music venues in Oxford, mainly on Saturday 19th April. -

Universitá Degli Studi Di Milano Facoltà Di Scienze Matematiche, Fisiche E Naturali Dipartimento Di Tecnologie Dell'informazione
UNIVERSITÁ DEGLI STUDI DI MILANO FACOLTÀ DI SCIENZE MATEMATICHE, FISICHE E NATURALI DIPARTIMENTO DI TECNOLOGIE DELL'INFORMAZIONE SCUOLA DI DOTTORATO IN INFORMATICA Settore disciplinare INF/01 TESI DI DOTTORATO DI RICERCA CICLO XXIII SERENDIPITOUS MENTORSHIP IN MUSIC RECOMMENDER SYSTEMS Eugenio Tacchini Relatore: Prof. Ernesto Damiani Direttore della Scuola di Dottorato: Prof. Ernesto Damiani Anno Accademico 2010/2011 II Acknowledgements I would like to thank all the people who helped me during my Ph.D. First of all I would like to thank Prof. Ernesto Damiani, my advisor, not only for his support and the knowledge he imparted to me but also for his capacity of understanding my needs and for having let me follow my passions; thanks also to all the other people of the SESAR Lab, in particular to Paolo Ceravolo and Gabriele Gianini. Thanks to Prof. Domenico Ferrari, who gave me the possibility to work in an inspiring context after my graduation, helping me to understand the direction I had to take. Thanks to Prof. Ken Goldberg for having hosted me in his laboratory, the Berkeley Laboratory for Automation Science and Engineering at the University of California, Berkeley, a place where I learnt a lot; thanks also to all the people of the research group and in particular to Dmitry Berenson and Timmy Siauw for the very fruitful discussions about clustering, path searching and other aspects of my work. Thanks to all the people who accepted to review my work: Prof. Richard Chbeir, Prof. Ken Goldberg, Prof. Przemysław Kazienko, Prof. Ronald Maier and Prof. Robert Tolksdorf. Thanks to 7digital, our media partner for the experimental test, and in particular to Filip Denker. -

Rivista13.Pdf
Ma ciaoooo, come vi vanno queste vacanze?? Il caldo è soffocante vero xD Noi dello Shoujonk Magazine vi consigliamo un bel bagno in piscina ricco di cubetti di ghiaccio oppure una bella guerra all’aperto con pistole d’acqua o magari con i palloncini per chi è solo e non può giocare con nessuno prendete un cane adorano i palloncini, ma non l’acqua ma pazienza, la mia è troppo jolla per sapere che dentro un palloncino c’è l’acqua è arriva sempre a romperlo e a bagnarsi u,u…. sto inesorabilmente uscendo fuori dall’argomento principale ovvero la rivista cosa vi portiamo quest’oggi? Non lo so la rivista non è nemmeno iniziata ahahahahaha, dovrete leggere per scoprirlo, ma come già detto nella scorsa edizione si ha una nuova novità *^* la sezione Lavoro se ne va in vacanza e ci farà compagnia la sezione Cosplay gestita da Mikki.. Ora vi lascio ciauus Lo Shoujonk Team e lo Shoujonk Magazine cerca staff Click Helpaci xD e fai parte dello staff anche tuuuu!! Indice: Kokoro ni nion: Pag. 1 – 3 News: Pag. 4 – 5 Densetsu : Pag. 6-7 Cultura Shogunato: Pag. 8 – 10 Folclore: Pag.11-13 Sport golf: Pag. 14 -15 Musica Polysics: Pag. 16 – 20 Cinema L'attacco dei giganti: Pag. 21 – 23 Dorama: Pag. 24- 25 Uscite manga: Pag. 26 -28 Giochi: Pag. 29 (Kokoro ni Nihon) Salve salvino.. cari lettori come sapete già, il viaggio a Kobe è finito quindi si inizia subito un nuovo viaggio… quindi vi lascio con il primo giorno di un altro magnifico e favoloso e pazzo viaggio in Giappone città Kyoto. -

Issue 124.Pmd
email: [email protected] website: nightshift.oxfordmusic.net Free every month. NIGHTSHIFT Issue 124 November Oxford’s Music Magazine 2005 TwizzTwizzTwizz twangle &&& pppaaatststsyyy decline The method in their madness - interview inside Also inside - news, reviews and six pages of local gigs NIGHTSHIFT: PO Box 312, Kidlington, OX5 1ZU. Phone: 01865 372255 NEWNEWSS Nightshift: PO Box 312, Kidlington, OX5 1ZU Phone: 01865 372255 email: [email protected] SEXY BREAKFAST have split up. The band, who have been a mainstay of the local scene for almost ten years, bowed out with a gig at the Zodiac supporting The Paddingtons last month. Frontman Joe Swarbrick is set to form a new band; in the interim he will be playing a solo gig at the Port Mahon on Saturday 26th November. The Barn at The Red Lion, Witney THE EVENINGS head off on a UK tour Live Music November Programme this month to promote their new ‘Louder In the Dark’ EP on Brainlove Records. The Fri 4th RUBBER MONKEYS THE YOUNG KNIVES head out on their new EP is officially released on November th th Sat 5 SLEEPWALKER biggest ever UK tour this month to 7 ; the band play at the Cellar on th rd Sun 6 DEAD MEN’S SHOES promote new single, ‘The Decision’, on Thursday 3 November with support th Transgressive Records. The new single is a from Applicants, Open Mouth and Fri 11 THE WORRIED MEN th re-recording of 2004’s release on Hanging Napoleon III. The Evenings’ ‘Let’s Go Sat 12 GATOR HIGHWAY th Out With the Cool Kids, which topped Remixed’ album is now set to be released Sun 13 MICHAEL Nightshift’s end of year Top 20 chart. -
![714.01 [Cover] Mothernew3](https://docslib.b-cdn.net/cover/8664/714-01-cover-mothernew3-5108664.webp)
714.01 [Cover] Mothernew3
CMJ NewMusic® CMJ STELLASTARR* 25 REVIEWED: SOUTH, THURSDAY, Report TO MY SURPRISE, SAVES THE DAY, CCMJCMJIssue No.M 832 • SeptemberJ 22, 2003 • www.cmj.com SPOTLIGHT MATCHBOOK ROMANCE + MORE! LOUD ROCK AS HOPE DIES DEAD CRPMMJ VAN DYK GETS REFLECTIVE CMJ RETAIL RAND FINALE! TRUSTTRUST NEVERNEVER SLEEPSSLEEPS Leona Naess Is Bringin’ On The HEARTBREAK RADIO 200: WEEN SPENDS SECOND WEEK AT NO. 1• SPIRITUALIZED HOOKS MOST ADDED NewMusic ® CMJ CMJCMJ Report 25 9/22/2003 Vice President & General Manager Issue No. 832 • Vol. 77 • No. 5 Mike Boyle CEDITORIALMJ COVER STORY Editor-In-Chief 6 A Question Of Trust Kevin Boyce Becoming a hermit in unfamiliar L.A., tossing her computers and letting the guitars bleed in the Associate Editors vocal mics, Leona Naess puts her trust in herself and finally lends her perfect pipes to a record Doug Levy she adores. Now if she could just make journalists come clean and get over her fear of poisoned CBradM MaybeJ Halloween candy… Louis Miller Loud Rock Editor DEPARTMENTS Amy Sciarretto Jazz Editor 4 Essential/Reviews by Dimmu Borgir, Morbid Angel and Dope get Tad Hendrickson Reviews of South, Stellastarr*, Thursday, To My reviewed; Darkest Hour and Atreyu get punked RPM Editor Surprise, Saves The Day, Matchbox Romance on the road; tidbits regarding Slayer, Opeth, and Lost In Translation. Plus, KMFDM’s Angst Exodus, Theatre Of Tragedy, As Hope Dies, Justin Kleinfeld receives CMJ’s “Silver Salute.” Black Dahlia Murder, Stigma, Stampin’ Retail Editor Ground and Josh Homme’s Desert Sessions Gerry Hart 8 Radio 200 series; and Misery Index’s Sparky submits to Associate Ed./Managing Retail Ed. -
Issue 154.Pmd
email: [email protected] website: nightshift.oxfordmusic.net Free every month. NIGHTSHIFT Issue 154 May Oxford’s Music Magazine 2008 PUNT 2008 King Furnace fire up for the year’s best showcase of Oxford music talent. Four-page pull-out guide inside Katharine Bird by King Furnace photo Plus All the latest Festival news NIGHTSHIFT: PO Box 312, Kidlington, OX5 1ZU. Phone: 01865 372255 NEWNEWSS Nightshift: PO Box 312, Kidlington, OX5 1ZU Phone: 01865 372255 email: [email protected] THIS MONTH’S OXFORD PUNT will give local music fans a fantastic opportunity to see some of the best new and unsigned bands in the area. The Punt, now in its eleventh year, takes place on Wednesday 14th May and features 18 bands across five venues in Oxford City Centre. The mini-festival kicks off at Borders at 6.15pm with acoustic folk-pop singer Faceometer and runs through the evening at Thirst Lodge, the Purple Turtle and the Wheatsheaf, finishing at midnight at the Cellar with one-man digital hardcore riot Clanky Robo Gobjobs. In between you’ll hear funk, ska, metal, electro-pop, experimental noise, blues, rock, indie and more. THE LEMONHEADS have been confirmed as the main headline act for The full line-up for the Punt, which includes this month’s Nightshift this year’s Truck Festival. Evan Dando’s legendary grunge-pop band cover stars King Furnace, can be found in a special handy pull-out guide will perform the whole of their classic ‘It’s A Shame About Ray’ album in in the middle of this issue, including a brief introduction to every venue its entirety as they perform on the main stage on Saturday 19th July at Hill and act involved.