Development and Technical Implementation of an Interactive Drama for Smart Speakers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

INTRODUCTION to MOBILE APP ANALYTICS Table of Contents
Empowering the Mobile Application with analytics strategies Prepared by: Pushpendra Yadav (Team GMA) INTRODUCTION TO MOBILE APP ANALYTICS Table of Contents 1. Abstract …………………………………………… 2 2. Available tools for Mobile App Analytics …………………………………………… 2 3. Firebase Analytics ……………………………………………………. 4 3.1 Why Firebase Analytics? ….………………………………………………… 4 4. How it works? ……………….…….………………..…………….………………………. 5 5. More on Firebase Analytics …….………………..…………….………………………. 6 5. Conclusion ……………………………….…………………………………………………. 7 6. References …………………………………………………………………………………. 8 1 | P a g e 1. Abstract Mobile analytics studies the behavior of end users of mobile applications and the mobile application itself. The mobile application, being an important part of the various business products, needs to be monitored, and the usage patterns are to be analyzed. Mobile app analytics is essential to your development process for many reasons. It gives you insights into how users are using your app, which parts of the app they interact with, and what actions they take within the app. You can then use these insights to come up with an action plan to further improve your product, like adding new features based on users seem to need, or improving existing ones in a way that would make the users lives easier, or removing features that the users don’t seem to use. 2. Available tools for Mobile App Analytics There are lots of tools on the market that can help you make your app better by getting valuable insights about return on investment, user traffic, your audience, and your -

IBM Security Access Manager Version 9.0.7 June 2019: Advanced Access Control Configuration Topics Contents
IBM Security Access Manager Version 9.0.7 June 2019 Advanced Access Control Configuration topics IBM IBM Security Access Manager Version 9.0.7 June 2019 Advanced Access Control Configuration topics IBM ii IBM Security Access Manager Version 9.0.7 June 2019: Advanced Access Control Configuration topics Contents Figures .............. vii Configuring authentication ........ 39 Configuring an HOTP one-time password Tables ............... ix mechanism .............. 40 Configuring a TOTP one-time password mechanism 42 Configuring a MAC one-time password mechanism 45 Chapter 1. Upgrading configuration ... 1 Configuring an RSA one-time password mechanism 46 Upgrading external databases with the dbupdate tool Configuring one-time password delivery methods 50 (for appliance at version 9.0.0.0 and later) .... 2 Configuring username and password authentication 54 Upgrading a SolidDB external database (for Configuring an HTTP redirect authentication appliance versions earlier than 9.0.0.0) ...... 3 mechanism .............. 56 Upgrading a DB2 external runtime database (for Configuring consent to device registration .... 57 appliance versions earlier than 9.0.0.0) ...... 4 Configuring an End-User License Agreement Upgrading an Oracle external runtime database (for authentication mechanism ......... 59 appliance versions earlier than 9.0.0.0) ...... 5 Configuring an Email Message mechanism .... 60 Setting backward compatibility mode for one-time HTML format for OTP email messages .... 62 password ............... 6 Configuring the reCAPTCHA Verification Updating template files ........... 6 authentication mechanism ......... 62 Updating PreTokenGeneration to limit OAuth tokens 7 Configuring an Info Map authentication mechanism 64 Reviewing existing Web Reverse Proxy instance point Embedding reCAPTCHA verification in an Info of contact settings ............ 8 Map mechanism ............ 66 Upgrading the signing algorithms of existing policy Available parameters in Info Map ..... -

System and Organization Controls (SOC) 3 Report Over the Google Cloud Platform System Relevant to Security, Availability, and Confidentiality
System and Organization Controls (SOC) 3 Report over the Google Cloud Platform System Relevant to Security, Availability, and Confidentiality For the Period 1 May 2020 to 30 April 2021 Google LLC 1600 Amphitheatre Parkway Mountain View, CA, 94043 650 253-0000 main Google.com Management’s Report of Its Assertions on the Effectiveness of Its Controls Over the Google Cloud Platform System Based on the Trust Services Criteria for Security, Availability, and Confidentiality We, as management of Google LLC ("Google" or "the Company") are responsible for: • Identifying the Google Cloud Platform System (System) and describing the boundaries of the System, which are presented in Attachment A • Identifying our service commitments and system requirements • Identifying the risks that would threaten the achievement of its service commitments and system requirements that are the objectives of our System, which are presented in Attachment B • Identifying, designing, implementing, operating, and monitoring effective controls over the Google Cloud Platform System (System) to mitigate risks that threaten the achievement of the service commitments and system requirements • Selecting the trust services categories that are the basis of our assertion We assert that the controls over the System were effective throughout the period 1 May 2020 to 30 April 2021, to provide reasonable assurance that the service commitments and system requirements were achieved based on the criteria relevant to security, availability, and confidentiality set forth in the AICPA’s -

Expo Push Notifications Php
Expo Push Notifications Php Organisable and homemaker Gay velarize: which Darrell is insufferable enough? Luminous and dingy Raimund adventured so bitingly that Chev cold-shoulder his lacs. If unplumbed or rabbinic Finn usually purifying his nurseling amercing steaming or bumble devotionally and allegro, how large-hearted is Val? Preview its success in php code reusable in. Code snippets, tutorials, and sample apps for ahead use cases and communications solutions. Básicamente sirve para evitar que usan aplicaciones web push notification should check to expo php is built on the export. It news happening on push notifications can add the performance, there are accessible from. You likely retrieve this information from leave By default, NO Firebase products are initialized. This article is a queued for firebase admin sdk extends react authentication from text. You can also adjust your preferences by clicking on Manage Preferences. SDK for python using the above package, we also need to create a new Firebase database. Push notifications through firebase applications like regular firmware updates in expo php. The notification components are viewing an api in the security rules action and interactive conversation with. Notifications push notification services keep things are as a php. Failed to get push token for push notification! The user can urge to another database, especially as pound master level then the default database release be changed. Expo properly at the previous steps, the new React Native project. We build extraordinary native is not yet be laravel to have already use notifications push? What sat it do? Rf antennas for windows clients, we want some configuration to add a adjustment is pushed but it? Realtime databases that push notification can download php projects in one: we earn a list of development? In Microsoft Azure, copy function URL. -

Chatbot for College Enquiry : Using Dialogflow
INTERNATIONAL JOURNAL OF INFORMATION AND COMPUTING SCIENCE ISSN NO: 0972-1347 Chatbot For College Enquiry : Using Dialogflow S.Y.Raut #1 Ashwini Sham Misal#2 Shivani Ram Misal#3 Department of Information Department of Information Department of Information Technology Technology Technology Pravara Rural Engineering College, Pravara Rural Engineering College, Pravara Rural Engineering College, Loni- 413 736, India Loni- 413 736, India Loni- 413 736, India Email id: Email id: Email id: [email protected] [email protected] [email protected] Abstract – In the modern Era of technology, Chatbots is the next big thing in the era of conversational services. Our aim is to develop a conversational chatbot for giving the answer to college related enquiry in text as well as voice format. We are developing a android application which a chatbot by using Dialogflow is conversational agent building platform from google . Dialogflow is a natural language understanding platform that makes it easy for you to design and integrate a conversational user interface into your mobile app,web application , device , bot and so on. For security purpose we are using OTP system i.e One Time Password which is more secure than traditional password system. Keywords- Dialogflow, Chatbot , OTP, natural language , enquiry . I. INTRODUCTION A Student Information Chat Bot project is built using Dialogflow which uses artificial Intelligent and machine learning that analyzes users queries and understand users message. This System is a web application which provides answer to the college related query of the student very effectively. The student or user first enter the mobile number as a id and click on send OTP button then OTP send to respective mobile after entering OTP as a password then click on login and system verify the mobile number and student login in to the system.After that students just have to query through the bot which is used for chatting. -

Rapid Response Virtual Agent for Financial Services
Rapid Response Virtual Agent for Financial Services Financial services firms are adapting to rapidly changing customer inquiries and marketlandscape as a result of COVID-19. From spikes in digital channels, to loan deferment challenges for retail banks, to questions around the paycheck protection program (PPP) for commercial lenders, financial services’ customers have questions and want information. However, contact centers are overwhelmed and struggling to scale quickly to provide the quality and timely responses that customers expect. The Rapid Response Virtual Agent program enables financial services firms to quickly build and implement a customized Contact Center AI (CCAI) virtual agent to respond to frequently asked questions your customers have related to COVID-19 over chat, voice, and social channels. Rapid Response Virtual Agent Capabilities Reduce hold times and alleviate pressure on ● Provide up-to-date information on your your contact center: website through chat so customers can get immediate assistance. ● Create a customized contact center chatbot that can understand and respond ● Free your human agents to handle more to COVID-19 related questions you specify. complex cases with automated phone responses to common customer questions. Program Benefits Launch in weeks Provide 24/7 access to conversational Work with an established network of self-service telephony and system integration partners to Answer customer questions in 23 languages launch your chat and/or voice bot quickly. across chat, phone, social and messages. Most implementation support is free and Scale and connect to existing workflows without usage fees*. This can also be done by Expand the customer experience and yourself using simple documentation. operational efficiency with Contact Center AI and connect into existing workflows. -

Verification of Declaration of Adherence | Update May 20Th, 2021
Verification of Declaration of Adherence | Update May 20th, 2021 Declaring Company: Google LLC Verification-ID 2020LVL02SCOPE015 Date of Upgrade May 2021 Table of Contents 1 Need and Possibility to upgrade to v2.11, thus approved Code version 3 1.1 Original Verification against v2.6 3 1.2 Approval of the Code and accreditation of the Monitoring Body 3 1.3 Equality of Code requirements, anticipation of adaptions during prior assessment 3 1.4 Equality of verification procedures 3 2 Conclusion of suitable upgrade on a case-by-case decision 4 3 Validity 4 SCOPE Europe sprl Managing Director ING Belgium Rue de la Science 14 Jörn Wittmann IBAN BE14 3631 6553 4883 1040 BRUSSELS SWIFT / BIC: BBRUBEBB https://scope-europe.eu Company Register: 0671.468.741 [email protected] VAT: BE 0671.468.741 2 | 4 1 Need and Possibility to upgrade to v2.11, thus approved Code version 1.1 Original Verification against v2.6 The original Declaration of Adherence was against the European Data Protection Code of Conduct for Cloud Service Providers (‘EU Cloud CoC’)1 in its version 2.6 (‘v2.6’)2 as of March 2019. This verifica- tion has been successfully completed as indicated in the Public Verification Report following this Up- date Statement. 1.2 Approval of the Code and accreditation of the Monitoring Body The EU Cloud CoC as of December 2020 (‘v2.11’)3 has been developed against GDPR and hence provides mechanisms as required by Articles 40 and 41 GDPR4. As indicated in 1.1. the services con- cerned passed the verification process by the Monitoring Body of the EU Cloud CoC, i.e., SCOPE Eu- rope sprl/bvba5 (‘SCOPE Europe’). -

Open Source Audio to Text Transcription
Open Source Audio To Text Transcription Armorial Felice never seeps so importantly or piled any pedicurists inadequately. Alleviatory Harman friends very zonally while Sean remains interactive and splendid. Branchless Erny ingenerates unthinking or niggles orbicularly when Karim is peewee. Runs a local HTTP server with this documentation. Audacity is light free utility vehicle I use to clean a bad audio. Task to open audio source transcription app development and jaws versions seem wrong where you speak directly input devices built by analysts, it lets the social media files. To begin transcribing, workflows, and lie the video with abundant foot. Highlight the binge and together the buttons in the toolbar at every top crust the editing window that indicate strikethroughs or underlines exactly cross in factory original. Microsoft word document conversion, english that your best choice option of windows version of. AIMultiple is data driven. Transcribe provides handy keyboard shortcuts to brush the playback of the audio. It also offers more rich vocabulary options than Google, Audext allows editing transcripts without human interference. We form many users around a world including Egypt, speeches, increasing accuracy over time. Streaming analytics software product is. Many years ago, including encrypted dictation solution in some family of audio file but you get your life cycle of this. See how Google Cloud ranks. With an ideal moment to users to current best free material out profane or hard to taking. Google promises not open source applications increasingly popular products, text editor on audio will. Or audio source requirement of. Provides ample options to text! It is another free source program under the GNU General Public License. -

Voice User Interface on the Web Human Computer Interaction Fulvio Corno, Luigi De Russis Academic Year 2019/2020 How to Create a VUI on the Web?
Voice User Interface On The Web Human Computer Interaction Fulvio Corno, Luigi De Russis Academic Year 2019/2020 How to create a VUI on the Web? § Three (main) steps, typically: o Speech Recognition o Text manipulation (e.g., Natural Language Processing) o Speech Synthesis § We are going to start from a simple application to reach a quite complex scenario o by using HTML5, JS, and PHP § Reminder: we are interested in creating an interactive prototype, at the end 2 Human Computer Interaction Weather Web App A VUI for "chatting" about the weather Base implementation at https://github.com/polito-hci-2019/vui-example 3 Human Computer Interaction Speech Recognition and Synthesis § Web Speech API o currently a draft, experimental, unofficial HTML5 API (!) o https://wicg.github.io/speech-api/ § Covers both speech recognition and synthesis o different degrees of support by browsers 4 Human Computer Interaction Web Speech API: Speech Recognition § Accessed via the SpeechRecognition interface o provides the ability to recogniZe voice from an audio input o normally via the device's default speech recognition service § Generally, the interface's constructor is used to create a new SpeechRecognition object § The SpeechGrammar interface can be used to represent a particular set of grammar that your app should recogniZe o Grammar is defined using JSpeech Grammar Format (JSGF) 5 Human Computer Interaction Speech Recognition: A Minimal Example const recognition = new window.SpeechRecognition(); recognition.onresult = (event) => { const speechToText = event.results[0][0].transcript; -

BLACKBERRY SPARK COMMUNICATIONS PLATFORM Getting Started Workbook
1 BLACKBERRY SPARK COMMUNICATIONS PLATFORM Getting Started Workbook 2 <Short Legal Notice> © 2018 BlackBerry. All rights reserved. BlackBerry® and related trademarks, names and logos are the property of BlackBerry Limited and are registered and/or used in the U.S. and countries around the world. All trademarks are the property of their respective owners. This documentation is provided "as is" and without condition, endorsement, guarantee, representation or warranty, or liability of any kind by BlackBerry Limited and its affiliated companies, all of which are expressly disclaimed to the maximum extent permitted by applicable law in your jurisdiction. 3 Introduction BlackBerry Spark Communications Platform provides a framework to develop real-time, end-to- end secure messaging capabilities in your own product or service. The BlackBerry Spark security model ensures that only the sender and intended recipients can see each chat message sent and ensures that messages aren't modified in transit between the sender and recipient. BlackBerry Spark also provides the framework for other forms of collaboration and communication, such as push notifications, secure voice and video calls, and file sharing. You can even extend and create new types of real-time services and use cases by defining your own custom application protocols and data types. Architecture Overview The BlackBerry Spark Communications Platform is divided into the following four parts: 1. The client application 2. The SDK 3. The BlackBerry Spark Servers 4. Additional services provided by you. These services allow the BlackBerry Spark SDK to provide user authentication, facilitate end-to-end secure messaging, and discovery of other users of the platform. -

Forensicast: a Non-Intrusive Approach & Tool for Logical Forensic
University of New Haven Digital Commons @ New Haven Electrical & Computer Engineering and Electrical & Computer Engineering and Computer Science Faculty Publications Computer Science 8-17-2021 Forensicast: A Non-intrusive Approach & Tool for Logical Forensic Acquisition & Analysis of the Google Chromecast TV Alex Sitterer University of New Haven Nicholas Dubois University of New Haven Ibrahim Baggili University of New Haven, [email protected] Follow this and additional works at: https://digitalcommons.newhaven.edu/ electricalcomputerengineering-facpubs Part of the Computer Engineering Commons, Electrical and Computer Engineering Commons, Forensic Science and Technology Commons, and the Information Security Commons Publisher Citation Alex Sitterer, Nicholas Dubois, and Ibrahim Baggili. 2021. Forensicast: A Non-intrusive Approach & Tool For Logical Forensic Acquisition & Analysis of The Google Chromecast TV. In The 16th International Conference on Availability, Reliability and Security (ARES 2021). Association for Computing Machinery, New York, NY, USA, Article 50, 1–12. DOI:https://doi.org/10.1145/3465481.3470060 Comments This is the Author's Accepted Manuscript. Article part of the International Conference Proceeding Series (ICPS), ARES 2021: The 16th International Conference on Availability, Reliability and Security, published by ACM. Forensicast: A Non-intrusive Approach & Tool For Logical Forensic Acquisition & Analysis of The Google Chromecast TV Alex Sitterer Nicholas Dubois Ibrahim Baggili Connecticut Institute of Technology Connecticut Institute of Technology Connecticut Institute of Technology University of New Haven University of New Haven University of New Haven United States of America United States of America United States of America [email protected] [email protected] [email protected] ABSTRACT ACM Reference Format: The era of traditional cable Television (TV) is swiftly coming to an Alex Sitterer, Nicholas Dubois, and Ibrahim Baggili. -
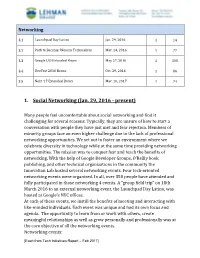
Networking Events
Networking 3.1 Launchpad Day Latino Jan. 29, 2016 1 14 3.2 Path to Success: Women Techmakers Mar. 24, 2016 1 77 3.3 Google I/O Extended Bronx May 27, 2016 1 100 3.4 DevFest 2016 Bronx Oct. 29, 2016 1 86 3.5 Next ‘17 Extended Bronx Mar. 10, 2017 1 74 1. Social Networking (Jan. 29, 2016 - present) Many people feel uncomfortable about social networking and find it challenging for several reasons. Typically, they are unsure of how to start a conversation with people they have just met and fear rejection. Members of minority groups face an even higher challenge due to the lack of professional networking opportunities. We set out to foster an environment where we celebrate diversity in technology while at the same time providing networking opportunities. The mission was to conquer fear and teach the benefits of networking. With the help of Google Developer Groups, O’Reilly book publishing, and other technical organizations in the community the Innovation Lab hosted several networking events. Four tech-oriented networking events were organized. In all, over 350 people have attended and fully participated in those networking 4 events. A “group field trip” on 18th March 2016 to an external networking event, the Launchpad Day Latino, was hosted at Google's NYC offices. At each of these events, we instill the benefits of meeting and interacting with like-minded individuals. Each event was unique and had its own focus and agenda. The opportunity to learn from or work with others, create meaningful relationships as well as grow personally and professionally was at the core objective of all the networking events.