The Probability of Winning in the Federer-Nadal Wimbledon 2007 Final
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Rafael Nadal: the Humble Champion AUG212017
Rafael Nadal: The Humble Champion AUG212017 James Buddell Chief Writer ATPWorldTour.com pays tribute to Nadal on his return to No. 1 A tennis champion is one who doesn’t just win matches, collects trophies or plays in an aesthetically pleasing way, but in the eyes of fans globally embodies professionalism, commitment and sportsmanship on and off the court. In an era when superlatives are thrown around, when players are categorised and all-time lists are compiled, there are those gilded few, in living memory, from Ken Rosewall and Rod Laverto Roger Federer and Rafael Nadal, who are lionised. Not just for who they are, but what they represent. Nadal has sat on a pedestal, living in the spotlight for much of the past 17 years – from the tennis prodigy who practised three times a week from the age of 14 with fellow Mallorcan Carlos Moya, to the winner of 73 tour-level crowns on all surfaces today. His every move, match (and injury) is scrutinised. Read more stories in our Rafa Returns To No. 1 tribute... Coach Roig: 'Rafa Has Been Through A Lot' The Day Nadal Won His First Emirates ATP Rankings Point Peers Pay Tribute To Rafa Today, in privacy, surrounded by his family and friends, Nadal could be forgiven to shed a tear upon his return to No. 1 in the Emirates ATP Rankings, but the hard-working, humble and passionate Spanish champion won’t allow time for such emotion. He’ll be found on a practice court, wearing down his training partner with match-quality focus, under the gaze of Toni Nadal, Francisco Roig or Moya. -

THE ROGER FEDERER STORY Quest for Perfection
THE ROGER FEDERER STORY Quest For Perfection RENÉ STAUFFER THE ROGER FEDERER STORY Quest For Perfection RENÉ STAUFFER New Chapter Press Cover and interior design: Emily Brackett, Visible Logic Originally published in Germany under the title “Das Tennis-Genie” by Pendo Verlag. © Pendo Verlag GmbH & Co. KG, Munich and Zurich, 2006 Published across the world in English by New Chapter Press, www.newchapterpressonline.com ISBN 094-2257-391 978-094-2257-397 Printed in the United States of America Contents From The Author . v Prologue: Encounter with a 15-year-old...................ix Introduction: No One Expected Him....................xiv PART I From Kempton Park to Basel . .3 A Boy Discovers Tennis . .8 Homesickness in Ecublens ............................14 The Best of All Juniors . .21 A Newcomer Climbs to the Top ........................30 New Coach, New Ways . 35 Olympic Experiences . 40 No Pain, No Gain . 44 Uproar at the Davis Cup . .49 The Man Who Beat Sampras . 53 The Taxi Driver of Biel . 57 Visit to the Top Ten . .60 Drama in South Africa...............................65 Red Dawn in China .................................70 The Grand Slam Block ...............................74 A Magic Sunday ....................................79 A Cow for the Victor . 86 Reaching for the Stars . .91 Duels in Texas . .95 An Abrupt End ....................................100 The Glittering Crowning . 104 No. 1 . .109 Samson’s Return . 116 New York, New York . .122 Setting Records Around the World.....................125 The Other Australian ...............................130 A True Champion..................................137 Fresh Tracks on Clay . .142 Three Men at the Champions Dinner . 146 An Evening in Flushing Meadows . .150 The Savior of Shanghai..............................155 Chasing Ghosts . .160 A Rivalry Is Born . -

Rafael Nadal Press Conference
Rolex Monte-Carlo Masters Principality of Monaco Friday, 16 April 2021 Rafael Nadal Press Conference A. RUBLEV/R. Nadal RAFAEL NADAL: Yeah, of course, have been such an important tournament for me during all my tennis career. 6-4, 4-6, 6-2 Always sad to lose here, of course, because it's an important one for me. I missed an opportunity to start the THE MODERATOR: Questions, please. clay court season in the right way. Q. Can you talk us through the match, what you think But that's it. I can't complain. It's not the moment to made the difference, how you feel you played. complain. When you are not able to do the things you had to do on the court, then is not the moment to complain RAFAEL NADAL: Well, have been an easy match to after, no? explain, no? When you face great player like him and you don't play well, you should lose, no? That's easy to The only thing that I can do is go to Barcelona and keep analyze. practicing, keep practicing, try to fix the things that didn't work well. I think my backhand today was not enough well. For some reason I had problems with my serve. I don't Lots of mistakes. I was not able to open the court with my know understand why because I was not having problems backhand then. on the practices at all. But today was one of these days that my serve was a disaster. Yeah, is small things that I know, and difficult to explain. -

Tennis MEDIA Guide 2012 2012 TULSA Tennis Media Guide
The Official Tulsa Golden Hurricane TENNIS MEDIA Guide 2012 www.tulsahurricane.com 2012 TULSA TENNIS Media Guide Table of Contents TULSA QUICK FACTS Introduction 1 Individual/Team Honors ................................. 20-21 Location: Tulsa, Oklahoma Year-By-Year Conference Results .......................22 Founded: 1894 Table of Contents .................................................1 Hall of Fame .........................................................22 Enrollment: 4,187 Tulsa Quick Facts .................................................1 Region Champions ...............................................22 Nickname: Golden Hurricane The University of Tulsa ........................................2 All-Americans................................................. 23-24 Colors: Old Gold, Royal Blue and Crimson The City of Tulsa ..................................................3 National Champions ............................................24 Conference: Conference USA Michael D. Case Tennis Center ...........................4 All-Time Letterwinners ........................................25 Affiliation: NCAA Division I President ..............................................................5 President: Dr. Steadman Upham Director of Athletics .............................................5 Women’s Team 26 Faculty Representative: Chris Anderson Director of Athletics: Ross Parmley Staff 6 Team Photo/Roster ..............................................26 Associate Athletic Director/SWA: Crista Troester Player Profiles ............................................... -

Federer Reaches Semis at ATP Finals
SUNDAY, NOVEMBER 10, 2013 SPORTS Ruthless Aussies thrash Italy 50-20 TURIN: Wing Nick Cummins scored two nisingly close to victory over the and worked hard through the game to Australia a line-out on Italy’s 22-metre Italy were given brief hope of a fight- of seven Australian tries as the Wallabies Wallabies in a 19-22 reverse last year. score those points. So there was consis- line and led to the Wallabies’ fourth try back when replacement Lorenzo made up for defeat to England with a “After the first half, or at least the first tency there, and we had to work hard in on 50 minutes. Cittadini bundled the ball over shortly commanding 50-20 victory over hapless 30 minutes, I saw some quality play defence at different times.” Italy’s posi- Adam Ashley-Cooper played a piv- after to add five points, but Di Italy at the Olympic Stadium yesterday. from Italy. But we gave away errors tive start was soon brought to heel. otal role, holding off several players and Bernardo’s disappointing afternoon Italy had been looking to capitalise cheaply and at the end of the day our Captain Ben Mowen touched down causing confusion metres from the try- with the boot continued when he on Australia’s morale-sapping 20-13 defence certainly wasn’t up to the job.” for Australia on 15 minutes, with Quade line before offloading to Cummins who missed the conversion. reverse at Twickenham last week to Australia’s dominance was never under Cooper making up for an earlier penalty sneaked aroud him to run in behind the There was no stopping Australia, and score a first, historic win over Australia threat but their defence was given a miss with the conversion before adding posts for his second. -

Tennis Edition
Commemorative Books Coverage List Wimbledon Tennis 2017 Date of Pages Event Covered (Daily Mirror unless stated) Paper 5 July 1913 Page 11 Anthony Wilding (N.Z) defeats Maurice McLoughlin to win his fourth singles title Dorothea Lambert Chambers wins her seventh singles title. 6 July 1914 Page 4 Norman Brookes beats Anthony Wilding in the men’s final 6 July 1919 Back Suzanne Lenglen (Fr) beats Dorothea Lambert Chambers in the ladies’ final Bill Tilden (US) wins the men’s singles. Suzanne Lenglen wins Triple Crown 4 July 1920 Back 4 July 1925 Page 2 Suzanne Lenglen wins the ladies singles for the sixth time 3 July 1926 Page 8 Jean Borotra (Fr) defeats Howard Kinsey to win his second singles title Henri Cochet (Fr) and Helen Wills (USA) win the singles titles for the first time 3 July 1927 Page 3 7 July 1928 Page 26 Rene Lacoste (Fr) defeats Henri Cochet to win his second singles title 7 July 1929 Pages 3 and back Henri Cochet (Fr) defeats Jean Borotra to win the men’s singles title for the second time Bill Tilden defeats Wilmer Allison to win the men’s title for a third time 6 July 1930 Back 7 July 1934 Pages 1 and 26 Fred Perry (GB) defeats Jack Crawford in the men’s singles final 9 July 1934 Page 27 Dorothy Round (GB) defeats Helen Jacobs in the ladies’ singles final 6 July 1935 Page 26 Fred Perry retains his singles title after defeating Gottfried von Cramm 4 Jul 1936 Pages 14 and 26 Fred Perry defeats Gottfried von Cramm to win his third successive singles title Don Budge (USA) wins Triple Crown, and Dorothy Round wins her second title -
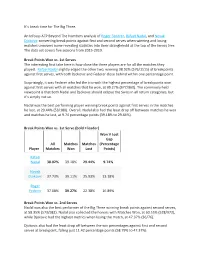
It's Break Time for the Big Three. an Infosys ATP Beyond the Numbers
It’s break time for The Big Three. An Infosys ATP Beyond The Numbers analysis of Roger Federer, Rafael Nadal, and Novak Djokovic converting break points against first and second serves when winning and losing matches uncovers some revealing statistics into their stranglehold at the top of the tennis tree. The data set covers five seasons from 2015-2019. Break Points Won vs. 1st Serves The interesting first take here is how close the three players are for all the matches they played. Rafael Nadal slightly edged the other two, winning 38.02% (576/1515) of breakpoints against first serves, with both Djokovic and Federer close behind within one percentage point. Surprisingly, it was Federer who led the trio with the highest percentage of breakpoints won against first serves with all matches that he won, at 39.27% (377/960). The commonly held viewpoint is that both Nadal and Djokovic should eclipse the Swiss in all return categories, but it’s simply not so. Nadal was the best performing player winning break points against first serves in the matches he lost, at 29.44% (53/180). Overall, Nadal also had the least drop off between matches he won and matches he lost, at 9.74 percentage points (39.18% to 29.44%). Break Points Won vs. 1st Serve (bold = leader) Won V Lost Gap All Matches Matches (Percentage Player Matches Won Lost Points) Rafael Nadal 38.02% 39.18% 29.44% 9.74% Novak Djokovic 37.73% 39.11% 25.93% 13.18% Roger Federer 37.08% 39.27% 22.38% 16.89% Break Points Won vs. -

Legalnotice Djokovic Raises His Game to a New Level
8C z MONDAY, JANUARY 28, 2019 z THE ENQUIRER OHIO Tennis Djokovic raises his game to a new level Howard Fendrich and stretched and occasionally even Australian dominance ASSOCIATED PRESS did the splits, contorting his body to get wherever and whenever he need- Novak Djokovic, Roger Federer and MELBOURNE, Australia – Novak ed. Rafael Nadal have won 14 of the past Djokovic was so good, so relentless, so Djokovic grabbed 13 of the first 14 16 Australian Opens: flawless, that Rafael Nadal never stood points, including all four that lasted 10 2019 — Novak Djokovic a chance. strokes or more. A trend was estab- Djokovic reduced one of the greats lished. 2018 — Roger Federer of the game to merely another out- Of most significance, Nadal was 2017 — Roger Federer classed opponent – just a guy, really – broken the very first time he served and one so out of sorts that Nadal even Sunday. That gave Djokovic one more 2016 — Novak Djokovic whiffed on one of his famous fore- Novak Djokovic dominated Rafael break of Nadal than the zero that the 2015 — Novak Djokovic hands entirely. Nadal 6-3, 6-2, 6-3 to win a record Spaniard’s five preceding opponents In a breathtakingly mistake-free seventh Australian Open title and a had managed. 2014 — Stan Wawrinka performance that yielded a remark- third consecutive Grand Slam Nadal could make no headway on 2013 — Novak Djokovic ably lopsided result, the No. 1-ranked championship. GETTY IMAGES this day. Djokovic won each of the ini- Djokovic overwhelmed Nadal 6-3, 6-2, tial 16 points he served and 25 of the 2012 — Novak Djokovic 6-3 on Sunday night to win a record first 26. -

August—September 2017
August—September 2017 President Des Shaw [email protected] January Morning Tea Notice Council AGM Hon Treasurer Paul Thomson [email protected] SEED ...Jade Lewis News from Ron Dutton Hon Sec. Angela Hart [email protected] Peter Doohan & Mervyn Rose Editor Cecilie McIntyre [email protected] Blast From the Past Fed Cup Link to IC Council website www.ictennis.net Wimbledon Snippets Drop Shots Our Annual Morning Tea Notice. Last week all members on email were sent details of how to reserve your FREE ticket and gate passes to the morning teas held on both Mondays of the International Tournaments in Auckland in early January. (Women to the ASB Classic Women’s week on Monday 1st January, and Men to the ASB Classic Men’s week on Monday 8th January.. We must stress that although there is no charge, and you can ask for a ground pass for a partner to come with you to both the morning teas, if they want to sit in the stand with you, you must pay for those tickets. The cut off date for requests is 29th September and forms, with or without extra ticket payments MUST be returned to Angela before then. Every year since we have been doing this there have been last minute requests….but no late applications will be accepted this year. In the past the return forms have gone to Tennis Auckland but now, although payment is still made out to Tennis Auckland they need to be sent to Angela. DON’T leave it till the last days. -
![[Click Here and Type in Recipient's Full Name]](https://docslib.b-cdn.net/cover/7514/click-here-and-type-in-recipients-full-name-2847514.webp)
[Click Here and Type in Recipient's Full Name]
News Release 11 November 2018 DJOKOVIC PRESENTED YEAR-END ATP WORLD TOUR NO. 1 TROPHY AT 2018 NITTO ATP FINALS LONDON — Novak Djokovic was today presented with the 2018 year-end ATP World Tour No. 1 trophy during an on-court presentation at the Nitto ATP Finals, the season finale at The O2 in London. The Serbian is one of only four players in ATP Rankings history (since 1973) to have clinched the year-end top spot on five (or more) occasions, joining Pete Sampras (six), Jimmy Connors and Roger Federer (both five times). Djokovic, who replaced Spain’s Rafael Nadal at No. 1 on 5 November, has completed a remarkable comeback to top form in 2018, capturing four titles—including two Grand Slams and two ATP World Tour Masters 1000s – from six tour-level finals. Aged 31 and six months, Djokovic is the oldest player to finish year-end No. 1 in ATP Rankings history. Having previously finished at the top in 2011-12, 2014-15, he is the second player — after Nadal (2008, 2010, 2013 and 2017) — with three stints as year-end No. 1. He is also the first player to be ranked outside the Top 20 and finish the same season at No. 1 in the history of the ATP Rankings. Russia’s Marat Safin was as low at No. 38 on 28 February 2000 before becoming No. 1 on 20 November that year, but he did not finish the season at No. 1. When Djokovic fell to No. 22 on 21 May 2018, it was his lowest ranking since he was No. -

2016 Us Open Preview
2016 US OPEN Flushing Meadows, New York, USA | August 29 – September 11, 2016 Draw Size: S-128, D-64 | $46.3 million | Hard TOURNAMENT PREVIEW www.usopen.org 2016 US OPEN PREVIEW CITY: Flushing Meadows, New York, USA SITE: USTA Billie Jean King National Tennis Center DATE: August 29 – September 11, 2016 PRIZE MONEY: $46.3 million (combined men & women) DRAW: 128 singles/64 doubles SURFACE: Hard Welcome to the 2016 US Open, the last Grand Slam tournament of the year, to be held at the Billie Jean King National Tennis Center. The US National Championships (now US Open) is one of the oldest major sporting events in the country: Event First held Kentucky Derby (horse racing) 1875 US National Championships/US Open (tennis) 1881 Stanley Cup (hockey) 1893 US Open (golf) 1895 World Series (baseball) 1903 Indianapolis 500 (auto racing) 1911 NFL Championship/Super Bowl (American football) 1920 The Masters (golf) 1934 NBA Finals (basketball) 1947 The US National Championships, known since 1968 as the US Open Tennis Championships, is the second-oldest of the four Grand Slam tennis tournaments after Wimbledon, and the only one to have been played each year since its inception in 1881. This is the 136th staging of the event. This is the 49th US Open and the 195th Grand Slam tournament of the Open Era. The tournament has been held on hard court at Flushing Meadows since moving from Forest Hills in 1978. For the second year in a row, this year’s championship match will be played on a Sunday after seven straight years on a Monday. -

Featured Men's Singles Semi-Finals
2017 US OPEN Flushing, New York, USA | August 28-September 10, 2017 Draw Size: S-128, D-64 | $50.4 million | Hard www.usopen.org DAY 12 MEDIA NOTES | Friday, September 8, 2017 FEATURED MEN’S SINGLES SEMI-FINALS ARTHUR ASHE STADIUM [1] Rafael Nadal (ESP) vs [24] Juan Martin del Potro (ARG) Nadal Leads 8-5 [28] Kevin Anderson (RSA) vs [12] Pablo Carreno Busta (ESP) Anderson Leads 2-0 DAY 12 HIGHLIGHTS • The semi-finals on Friday feature two former US Open champions and two Grand Slam semi-final debutants. The 2017 US Open is the first Grand Slam event to feature three double-digit seeds or unseeded players in the semi- finals since 2002 Roland Garros: [11] Juan Carlos Ferrero, [18] Alex Corretja and [20] Albert Costa. All three were Spaniards, and the 2017 US Open has been another breakout tournament for Spain. Two Spaniards are in the semi-finals for the first time in US Open history: Rafael Nadal and Pablo Carreno Busta. On Monday, Nadal and Garbine Muguruza will be No. 1 on the ATP World Tour and WTA respectively, marking the first time since August 10, 2003 that two players from the same country will top the rankings (Andre Agassi and Serena Williams of USA). • No. 1 Nadal and No. 24 seed Juan Martin del Potro resume their rivalry with the Spaniard holding an 8-5 head- to-head lead. However, the Argentine leads 5-4 on hard courts, winning the last two meetings (2013 Shanghai, 2016 Rio Olympics). Nadal is 3-2 in US Open semi-finals and 22-3 in Grand Slam semi-finals overall, winning the last 14 since falling to del Potro at the 2009 US Open.