Implementing Database Operations Using SIMD Instructions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

High Performance Computing Through Parallel and Distributed Processing
Yadav S. et al., J. Harmoniz. Res. Eng., 2013, 1(2), 54-64 Journal Of Harmonized Research (JOHR) Journal Of Harmonized Research in Engineering 1(2), 2013, 54-64 ISSN 2347 – 7393 Original Research Article High Performance Computing through Parallel and Distributed Processing Shikha Yadav, Preeti Dhanda, Nisha Yadav Department of Computer Science and Engineering, Dronacharya College of Engineering, Khentawas, Farukhnagar, Gurgaon, India Abstract : There is a very high need of High Performance Computing (HPC) in many applications like space science to Artificial Intelligence. HPC shall be attained through Parallel and Distributed Computing. In this paper, Parallel and Distributed algorithms are discussed based on Parallel and Distributed Processors to achieve HPC. The Programming concepts like threads, fork and sockets are discussed with some simple examples for HPC. Keywords: High Performance Computing, Parallel and Distributed processing, Computer Architecture Introduction time to solve large problems like weather Computer Architecture and Programming play forecasting, Tsunami, Remote Sensing, a significant role for High Performance National calamities, Defence, Mineral computing (HPC) in large applications Space exploration, Finite-element, Cloud science to Artificial Intelligence. The Computing, and Expert Systems etc. The Algorithms are problem solving procedures Algorithms are Non-Recursive Algorithms, and later these algorithms transform in to Recursive Algorithms, Parallel Algorithms particular Programming language for HPC. and Distributed Algorithms. There is need to study algorithms for High The Algorithms must be supported the Performance Computing. These Algorithms Computer Architecture. The Computer are to be designed to computer in reasonable Architecture is characterized with Flynn’s Classification SISD, SIMD, MIMD, and For Correspondence: MISD. Most of the Computer Architectures preeti.dhanda01ATgmail.com are supported with SIMD (Single Instruction Received on: October 2013 Multiple Data Streams). -

2.5 Classification of Parallel Computers
52 // Architectures 2.5 Classification of Parallel Computers 2.5 Classification of Parallel Computers 2.5.1 Granularity In parallel computing, granularity means the amount of computation in relation to communication or synchronisation Periods of computation are typically separated from periods of communication by synchronization events. • fine level (same operations with different data) ◦ vector processors ◦ instruction level parallelism ◦ fine-grain parallelism: – Relatively small amounts of computational work are done between communication events – Low computation to communication ratio – Facilitates load balancing 53 // Architectures 2.5 Classification of Parallel Computers – Implies high communication overhead and less opportunity for per- formance enhancement – If granularity is too fine it is possible that the overhead required for communications and synchronization between tasks takes longer than the computation. • operation level (different operations simultaneously) • problem level (independent subtasks) ◦ coarse-grain parallelism: – Relatively large amounts of computational work are done between communication/synchronization events – High computation to communication ratio – Implies more opportunity for performance increase – Harder to load balance efficiently 54 // Architectures 2.5 Classification of Parallel Computers 2.5.2 Hardware: Pipelining (was used in supercomputers, e.g. Cray-1) In N elements in pipeline and for 8 element L clock cycles =) for calculation it would take L + N cycles; without pipeline L ∗ N cycles Example of good code for pipelineing: §doi =1 ,k ¤ z ( i ) =x ( i ) +y ( i ) end do ¦ 55 // Architectures 2.5 Classification of Parallel Computers Vector processors, fast vector operations (operations on arrays). Previous example good also for vector processor (vector addition) , but, e.g. recursion – hard to optimise for vector processors Example: IntelMMX – simple vector processor. -

Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and Power
Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and power ITSC 3181 Introduction to Computer Architecture https://passlaB.githuB.io/ITSC3181/ Department of Computer Science Yonghong Yan [email protected] https://passlab.github.io/yanyh/ Lectures for Chapter 1 and C Basics Computer Abstractions and Technology • Lecture 01: Chapter 1 – 1.1 – 1.4: Introduction, great ideas, Moore’s law, aBstraction, computer components, and program execution • Lecture 02: C Basics; Memory and Binary Systems • Lecture 03: Number System, Compilation, Assembly, Linking and Program Execution ☛• Lecture 04: Chapter 1 – 1.6 – 1.7: Performance, power and technology trends • Lecture 05: – 1.8 - 1.9: Multiprocessing and Benchmarking 2 § 1.6 Performance 1.6 Defining Performance • Which airplane has the best performance? Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 100 200 300 400 500 0 2000 4000 6000 8000 10000 Passenger Capacity Cruising Range (miles) Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 500 1000 1500 0 100000 200000 300000 400000 Cruising Speed (mph) Passengers x mph 3 Response Time and Throughput • Response time çè Latency – How long it takes to do a task • Throughput çè Bandwidth – Total work done per unit time • e.g., tasks/transactions/… per hour • How are response time and throughput affected by – Replacing the processor with a faster version? – Adding more processors? • We’ll focus on response time for now… 4 Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y”, i.e. -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

Parallel Programming
Parallel Programming Parallel Programming Parallel Computing Hardware Shared memory: multiple cpus are attached to the BUS all processors share the same primary memory the same memory address on different CPU’s refer to the same memory location CPU-to-memory connection becomes a bottleneck: shared memory computers cannot scale very well Parallel Programming Parallel Computing Hardware Distributed memory: each processor has its own private memory computational tasks can only operate on local data infinite available memory through adding nodes requires more difficult programming Parallel Programming OpenMP versus MPI OpenMP (Open Multi-Processing): easy to use; loop-level parallelism non-loop-level parallelism is more difficult limited to shared memory computers cannot handle very large problems MPI(Message Passing Interface): require low-level programming; more difficult programming scalable cost/size can handle very large problems Parallel Programming MPI Distributed memory: Each processor can access only the instructions/data stored in its own memory. The machine has an interconnection network that supports passing messages between processors. A user specifies a number of concurrent processes when program begins. Every process executes the same program, though theflow of execution may depend on the processors unique ID number (e.g. “if (my id == 0) then ”). ··· Each process performs computations on its local variables, then communicates with other processes (repeat), to eventually achieve the computed result. In this model, processors pass messages both to send/receive information, and to synchronize with one another. Parallel Programming Introduction to MPI Communicators and Groups: MPI uses objects called communicators and groups to define which collection of processes may communicate with each other. -

Threads Chapter 4
Threads Chapter 4 Reading: 4.1,4.4, 4.5 1 Process Characteristics ● Unit of resource ownership - process is allocated: ■ a virtual address space to hold the process image ■ control of some resources (files, I/O devices...) ● Unit of dispatching - process is an execution path through one or more programs ■ execution may be interleaved with other process ■ the process has an execution state and a dispatching priority 2 Process Characteristics ● These two characteristics are treated independently by some recent OS ● The unit of dispatching is usually referred to a thread or a lightweight process ● The unit of resource ownership is usually referred to as a process or task 3 Multithreading vs. Single threading ● Multithreading: when the OS supports multiple threads of execution within a single process ● Single threading: when the OS does not recognize the concept of thread ● MS-DOS support a single user process and a single thread ● UNIX supports multiple user processes but only supports one thread per process ● Solaris /NT supports multiple threads 4 Threads and Processes 5 Processes Vs Threads ● Have a virtual address space which holds the process image ■ Process: an address space, an execution context ■ Protected access to processors, other processes, files, and I/O Class threadex{ resources Public static void main(String arg[]){ ■ Context switch between Int x=0; processes expensive My_thread t1= new my_thread(x); t1.start(); ● Threads of a process execute in Thr_wait(); a single address space System.out.println(x) ■ Global variables are -

Lecture 10: Introduction to Openmp (Part 2)
Lecture 10: Introduction to OpenMP (Part 2) 1 Performance Issues I • C/C++ stores matrices in row-major fashion. • Loop interchanges may increase cache locality { … #pragma omp parallel for for(i=0;i< N; i++) { for(j=0;j< M; j++) { A[i][j] =B[i][j] + C[i][j]; } } } • Parallelize outer-most loop 2 Performance Issues II • Move synchronization points outwards. The inner loop is parallelized. • In each iteration step of the outer loop, a parallel region is created. This causes parallelization overhead. { … for(i=0;i< N; i++) { #pragma omp parallel for for(j=0;j< M; j++) { A[i][j] =B[i][j] + C[i][j]; } } } 3 Performance Issues III • Avoid parallel overhead at low iteration counts { … #pragma omp parallel for if(M > 800) for(j=0;j< M; j++) { aa[j] =alpha*bb[j] + cc[j]; } } 4 C++: Random Access Iterators Loops • Parallelization of random access iterator loops is supported void iterator_example(){ std::vector vec(23); std::vector::iterator it; #pragma omp parallel for default(none) shared(vec) for(it=vec.begin(); it< vec.end(); it++) { // do work with it // } } 5 Conditional Compilation • Keep sequential and parallel programs as a single source code #if def _OPENMP #include “omp.h” #endif Main() { #ifdef _OPENMP omp_set_num_threads(3); #endif for(i=0;i< N; i++) { #pragma omp parallel for for(j=0;j< M; j++) { A[i][j] =B[i][j] + C[i][j]; } } } 6 Be Careful with Data Dependences • Whenever a statement in a program reads or writes a memory location and another statement reads or writes the same memory location, and at least one of the two statements writes the location, then there is a data dependence on that memory location between the two statements. -

The Problem with Threads
The Problem with Threads Edward A. Lee Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2006-1 http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-1.html January 10, 2006 Copyright © 2006, by the author(s). All rights reserved. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission. Acknowledgement This work was supported in part by the Center for Hybrid and Embedded Software Systems (CHESS) at UC Berkeley, which receives support from the National Science Foundation (NSF award No. CCR-0225610), the State of California Micro Program, and the following companies: Agilent, DGIST, General Motors, Hewlett Packard, Infineon, Microsoft, and Toyota. The Problem with Threads Edward A. Lee Professor, Chair of EE, Associate Chair of EECS EECS Department University of California at Berkeley Berkeley, CA 94720, U.S.A. [email protected] January 10, 2006 Abstract Threads are a seemingly straightforward adaptation of the dominant sequential model of computation to concurrent systems. Languages require little or no syntactic changes to sup- port threads, and operating systems and architectures have evolved to efficiently support them. Many technologists are pushing for increased use of multithreading in software in order to take advantage of the predicted increases in parallelism in computer architectures. -
Clock Rate Improves Roughly Proportional to Improvement in L • Number of Transistors Improves Proportional to L2 (Or Faster)
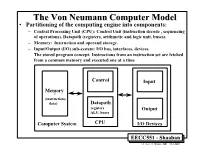
TheThe VonVon NeumannNeumann ComputerComputer ModelModel • Partitioning of the computing engine into components: – Central Processing Unit (CPU): Control Unit (instruction decode , sequencing of operations), Datapath (registers, arithmetic and logic unit, buses). – Memory: Instruction and operand storage. – Input/Output (I/O) sub-system: I/O bus, interfaces, devices. – The stored program concept: Instructions from an instruction set are fetched from a common memory and executed one at a time Control Input Memory - (instructions, data) Datapath registers Output ALU, buses Computer System CPU I/O Devices EECC551 - Shaaban #1 Lec # 1 Winter 2001 12-3-2001 Generic CPU Machine Instruction Execution Steps Instruction Obtain instruction from program storage Fetch Instruction Determine required actions and instruction size Decode Operand Locate and obtain operand data Fetch Execute Compute result value or status Result Deposit results in storage for later use Store Next Determine successor or next instruction Instruction EECC551 - Shaaban #2 Lec # 1 Winter 2001 12-3-2001 HardwareHardware ComponentsComponents ofof AnyAny ComputerComputer Five classic components of all computers: 1. Control Unit; 2. Datapath; 3. Memory; 4. Input; 5. Output } Processor Computer Keyboard, Mouse, etc. Processor Memory Devices (active) (passive) Control Input (where Unit programs, data Disk Datapath live when Output running) Display, Printer, etc. EECC551 - Shaaban #3 Lec # 1 Winter 2001 12-3-2001 CPUCPU OrganizationOrganization • Datapath Design: – Capabilities & performance characteristics of principal Functional Units (FUs): • (e.g., Registers, ALU, Shifters, Logic Units, ...) – Ways in which these components are interconnected (buses connections, multiplexors, etc.). – How information flows between components. • Control Unit Design: – Logic and means by which such information flow is controlled. – Control and coordination of FUs operation to realize the targeted Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram). -

Real-Time Performance During CUDA™ a Demonstration and Analysis of Redhawk™ CUDA RT Optimizations
A Concurrent Real-Time White Paper 2881 Gateway Drive Pompano Beach, FL 33069 (954) 974-1700 www.concurrent-rt.com Real-Time Performance During CUDA™ A Demonstration and Analysis of RedHawk™ CUDA RT Optimizations By: Concurrent Real-Time Linux® Development Team November 2010 Overview There are many challenges to creating a real-time Linux distribution that provides guaranteed low process-dispatch latencies and minimal process run-time jitter. Concurrent Real Time’s RedHawk Linux distribution meets and exceeds these challenges, providing a hard real-time environment on many qualified hardware configurations, even in the presence of a heavy system load. However, there are additional challenges faced when guaranteeing real-time performance of processes while CUDA applications are simultaneously running on the system. The proprietary CUDA driver supplied by NVIDIA® frequently makes demands upon kernel resources that can dramatically impact real-time performance. This paper discusses a demonstration application developed by Concurrent to illustrate that RedHawk Linux kernel optimizations allow hard real-time performance guarantees to be preserved even while demanding CUDA applications are running. The test results will show how RedHawk performance compares to CentOS performance running the same application. The design and implementation details of the demonstration application are also discussed in this paper. Demonstration This demonstration features two selectable real-time test modes: 1. Jitter Mode: measure and graph the run-time jitter of a real-time process 2. PDL Mode: measure and graph the process-dispatch latency of a real-time process While the demonstration is running, it is possible to switch between these different modes at any time. -

An Introduction to Gpus, CUDA and Opencl
An Introduction to GPUs, CUDA and OpenCL Bryan Catanzaro, NVIDIA Research Overview ¡ Heterogeneous parallel computing ¡ The CUDA and OpenCL programming models ¡ Writing efficient CUDA code ¡ Thrust: making CUDA C++ productive 2/54 Heterogeneous Parallel Computing Latency-Optimized Throughput- CPU Optimized GPU Fast Serial Scalable Parallel Processing Processing 3/54 Why do we need heterogeneity? ¡ Why not just use latency optimized processors? § Once you decide to go parallel, why not go all the way § And reap more benefits ¡ For many applications, throughput optimized processors are more efficient: faster and use less power § Advantages can be fairly significant 4/54 Why Heterogeneity? ¡ Different goals produce different designs § Throughput optimized: assume work load is highly parallel § Latency optimized: assume work load is mostly sequential ¡ To minimize latency eXperienced by 1 thread: § lots of big on-chip caches § sophisticated control ¡ To maXimize throughput of all threads: § multithreading can hide latency … so skip the big caches § simpler control, cost amortized over ALUs via SIMD 5/54 Latency vs. Throughput Specificaons Westmere-EP Fermi (Tesla C2050) 6 cores, 2 issue, 14 SMs, 2 issue, 16 Processing Elements 4 way SIMD way SIMD @3.46 GHz @1.15 GHz 6 cores, 2 threads, 4 14 SMs, 48 SIMD Resident Strands/ way SIMD: vectors, 32 way Westmere-EP (32nm) Threads (max) SIMD: 48 strands 21504 threads SP GFLOP/s 166 1030 Memory Bandwidth 32 GB/s 144 GB/s Register File ~6 kB 1.75 MB Local Store/L1 Cache 192 kB 896 kB L2 Cache 1.5 MB 0.75 MB -

Atmega165p Datasheet
Features • High Performance, Low Power Atmel® AVR® 8-Bit Microcontroller • Advanced RISC Architecture – 130 Powerful Instructions – Most Single Clock Cycle Execution – 32 × 8 General Purpose Working Registers – Fully Static Operation – Up to 16 MIPS Throughput at 16 MHz – On-Chip 2-cycle Multiplier • High Endurance Non-volatile Memory segments – 16 Kbytes of In-System Self-programmable Flash program memory – 512 Bytes EEPROM – 1 Kbytes Internal SRAM 8-bit – Write/Erase cyles: 10,000 Flash/100,000 EEPROM(1)(3) – Data retention: 20 years at 85°C/100 years at 25°C(2)(3) Microcontroller – Optional Boot Code Section with Independent Lock Bits In-System Programming by On-chip Boot Program with 16K Bytes True Read-While-Write Operation – Programming Lock for Software Security In-System • JTAG (IEEE std. 1149.1 compliant) Interface – Boundary-scan Capabilities According to the JTAG Standard Programmable – Extensive On-chip Debug Support – Programming of Flash, EEPROM, Fuses, and Lock Bits through the JTAG Interface Flash • Peripheral Features – Two 8-bit Timer/Counters with Separate Prescaler and Compare Mode – One 16-bit Timer/Counter with Separate Prescaler, Compare Mode, and Capture Mode – Real Time Counter with Separate Oscillator –Four PWM Channels ATmega165P – 8-channel, 10-bit ADC – Programmable Serial USART ATmega165PV – Master/Slave SPI Serial Interface – Universal Serial Interface with Start Condition Detector – Programmable Watchdog Timer with Separate On-chip Oscillator – On-chip Analog Comparator Preliminary – Interrupt and Wake-up