Efficient Supersampling Antialiasing for High-Performance Architectures
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Mathematical Basics of Bandlimited Sampling and Aliasing
Signal Processing Mathematical basics of bandlimited sampling and aliasing Modern applications often require that we sample analog signals, convert them to digital form, perform operations on them, and reconstruct them as analog signals. The important question is how to sample and reconstruct an analog signal while preserving the full information of the original. By Vladimir Vitchev o begin, we are concerned exclusively The limits of integration for Equation 5 T about bandlimited signals. The reasons are specified only for one period. That isn’t a are both mathematical and physical, as we problem when dealing with the delta func- discuss later. A signal is said to be band- Furthermore, note that the asterisk in Equa- tion, but to give rigor to the above expres- limited if the amplitude of its spectrum goes tion 3 denotes convolution, not multiplica- sions, note that substitutions can be made: to zero for all frequencies beyond some thresh- tion. Since we know the spectrum of the The integral can be replaced with a Fourier old called the cutoff frequency. For one such original signal G(f), we need find only the integral from minus infinity to infinity, and signal (g(t) in Figure 1), the spectrum is zero Fourier transform of the train of impulses. To the periodic train of delta functions can be for frequencies above a. In that case, the do so we recognize that the train of impulses replaced with a single delta function, which is value a is also the bandwidth (BW) for this is a periodic function and can, therefore, be the basis for the periodic signal. -

NVIDIA Opengl in 2012 Mark Kilgard
NVIDIA OpenGL in 2012 Mark Kilgard • Principal System Software Engineer – OpenGL driver and API evolution – Cg (“C for graphics”) shading language – GPU-accelerated path rendering • OpenGL Utility Toolkit (GLUT) implementer • Author of OpenGL for the X Window System • Co-author of Cg Tutorial Outline • OpenGL’s importance to NVIDIA • OpenGL API improvements & new features – OpenGL 4.2 – Direct3D interoperability – GPU-accelerated path rendering – Kepler Improvements • Bindless Textures • Linux improvements & new features • Cg 3.1 update NVIDIA’s OpenGL Leverage Cg GeForce Parallel Nsight Tegra Quadro OptiX Example of Hybrid Rendering with OptiX OpenGL (Rasterization) OptiX (Ray tracing) Parallel Nsight Provides OpenGL Profiling Configure Application Trace Settings Parallel Nsight Provides OpenGL Profiling Magnified trace options shows specific OpenGL (and Cg) tracing options Parallel Nsight Provides OpenGL Profiling Parallel Nsight Provides OpenGL Profiling Trace of mix of OpenGL and CUDA shows glFinish & OpenGL draw calls Only Cross Platform 3D API OpenGL 3D Graphics API • cross-platform • most functional • peak performance • open standard • inter-operable • well specified & documented • 20 years of compatibility OpenGL Spawns Closely Related Standards Congratulations: WebGL officially approved, February 2012 “The web is now 3D enabled” Buffer and OpenGL 4 – DirectX 11 Superset Event Interop • Interop with a complete compute solution – OpenGL is for graphics – CUDA / OpenCL is for compute • Shaders can be saved to and loaded from binary -

Msalvi Temporal Supersampling.Pdf
1 2 3 4 5 6 7 8 We know for certain that the last sample, shaded in the current frame, is valid. 9 We cannot say whether the color of the remaining 3 samples would be the same if computed in the current frame due to motion, (dis)occlusion, change in lighting, etc.. 10 Re-using stale/invalid samples results in quite interesting image artifacts. In this case the fairy model is moving from the left to the right side of the screen and if we re-use every past sample we will observe a characteristic ghosting artifact. 11 There are many possible strategies to reject samples. Most involve checking whether plurality of pre and post shading attributes from past frames is consistent with information acquired in the current frame. In practice it is really hard to come up with a robust strategy that works in the general case. For these reasons “old” approaches have seen limited success/applicability. 12 More recent temporal supersampling methods are based on the general idea of re- using resolved color (i.e. the color associated to a “small” image region after applying a reconstruction filter), while older methods re-use individual samples. What might appear as a small difference is actually extremely important and makes possible to build much more robust temporal techniques. First of all re-using resolved color makes possible to throw away most of the past information and to only keep around the last frame. This helps reducing the cost of temporal methods. Since we don’t have access to individual samples anymore the pixel color is computed by continuous integration using a moving exponential average (EMA). -

ESE 531: Digital Signal Processing
ESE 531: Digital Signal Processing Lec 12: February 21st, 2017 Data Converters, Noise Shaping (con’t) Penn ESE 531 Spring 2017 - Khanna Lecture Outline ! Data Converters " Anti-aliasing " ADC " Quantization " Practical DAC ! Noise Shaping Penn ESE 531 Spring 2017 - Khanna 2 ADC Penn ESE 531 Spring 2017 - Khanna 3 Anti-Aliasing Filter with ADC Penn ESE 531 Spring 2017 - Khanna 4 Oversampled ADC Penn ESE 531 Spring 2017 - Khanna 5 Oversampled ADC Penn ESE 531 Spring 2017 - Khanna 6 Oversampled ADC Penn ESE 531 Spring 2017 - Khanna 7 Oversampled ADC Penn ESE 531 Spring 2017 - Khanna 8 Sampling and Quantization Penn ESE 531 Spring 2017 - Khanna 9 Sampling and Quantization Penn ESE 531 Spring 2017 - Khanna 10 Effect of Quantization Error on Signal ! Quantization error is a deterministic function of the signal " Consequently, the effect of quantization strongly depends on the signal itself ! Unless, we consider fairly trivial signals, a deterministic analysis is usually impractical " More common to look at errors from a statistical perspective " "Quantization noise” ! Two aspects " How much noise power (variance) does quantization add to our samples? " How is this noise distributed in frequency? Penn ESE 531 Spring 2017 - Khanna 11 Quantization Error ! Model quantization error as noise ! In that case: Penn ESE 531 Spring 2017 - Khanna 12 Ideal Quantizer ! Quantization step Δ ! Quantization error has sawtooth shape, ! Bounded by –Δ/2, +Δ/2 ! Ideally infinite input range and infinite number of quantization levels Penn ESE 568 Fall 2016 - Khanna adapted from Murmann EE315B, Stanford 13 Ideal B-bit Quantizer ! Practical quantizers have a limited input range and a finite set of output codes ! E.g. -

Discontinuity Edge Overdraw Pedro V
Discontinuity Edge Overdraw Pedro V. Sander Hugues Hoppe John Snyder Steven J. Gortler Harvard University Microsoft Research Microsoft Research Harvard University http://cs.harvard.edu/~pvs http://research.microsoft.com/~hoppe [email protected] http://cs.harvard.edu/~sjg Abstract Aliasing is an important problem when rendering triangle meshes. Efficient antialiasing techniques such as mipmapping greatly improve the filtering of textures defined over a mesh. A major component of the remaining aliasing occurs along discontinuity edges such as silhouettes, creases, and material boundaries. Framebuffer supersampling is a simple remedy, but 2×2 super- sampling leaves behind significant temporal artifacts, while greater supersampling demands even more fill-rate and memory. We present an alternative that focuses effort on discontinuity edges by overdrawing such edges as antialiased lines. Although the idea is simple, several subtleties arise. Visible silhouette edges must be detected efficiently. Discontinuity edges need consistent orientations. They must be blended as they approach (a) aliased original (b) overdrawn edges (c) final result the silhouette to avoid popping. Unfortunately, edge blending Figure 1: Reducing aliasing artifacts using edge overdraw. results in blurriness. Our technique balances these two competing objectives of temporal smoothness and spatial sharpness. Finally, With current graphics hardware, a simple technique for reducing the best results are obtained when discontinuity edges are sorted aliasing is to supersample and filter the output image. On current by depth. Our approach proves surprisingly effective at reducing displays (desktop screens of ~1K×1K resolution), 2×2 supersam- temporal artifacts commonly referred to as "crawling jaggies", pling reduces but does not eliminate aliasing. Of course, a finer with little added cost. -

Comparing Oversampling Techniques to Handle the Class Imbalance Problem: a Customer Churn Prediction Case Study
Received September 14, 2016, accepted October 1, 2016, date of publication October 26, 2016, date of current version November 28, 2016. Digital Object Identifier 10.1109/ACCESS.2016.2619719 Comparing Oversampling Techniques to Handle the Class Imbalance Problem: A Customer Churn Prediction Case Study ADNAN AMIN1, SAJID ANWAR1, AWAIS ADNAN1, MUHAMMAD NAWAZ1, NEWTON HOWARD2, JUNAID QADIR3, (Senior Member, IEEE), AHMAD HAWALAH4, AND AMIR HUSSAIN5, (Senior Member, IEEE) 1Center for Excellence in Information Technology, Institute of Management Sciences, Peshawar 25000, Pakistan 2Nuffield Department of Surgical Sciences, University of Oxford, Oxford, OX3 9DU, U.K. 3Information Technology University, Arfa Software Technology Park, Lahore 54000, Pakistan 4College of Computer Science and Engineering, Taibah University, Medina 344, Saudi Arabia 5Division of Computing Science and Maths, University of Stirling, Stirling, FK9 4LA, U.K. Corresponding author: A. Amin ([email protected]) The work of A. Hussain was supported by the U.K. Engineering and Physical Sciences Research Council under Grant EP/M026981/1. ABSTRACT Customer retention is a major issue for various service-based organizations particularly telecom industry, wherein predictive models for observing the behavior of customers are one of the great instruments in customer retention process and inferring the future behavior of the customers. However, the performances of predictive models are greatly affected when the real-world data set is highly imbalanced. A data set is called imbalanced if the samples size from one class is very much smaller or larger than the other classes. The most commonly used technique is over/under sampling for handling the class-imbalance problem (CIP) in various domains. -

Super-Sampling Anti-Aliasing Analyzed
Super-sampling Anti-aliasing Analyzed Kristof Beets Dave Barron Beyond3D [email protected] Abstract - This paper examines two varieties of super-sample anti-aliasing: Rotated Grid Super- Sampling (RGSS) and Ordered Grid Super-Sampling (OGSS). RGSS employs a sub-sampling grid that is rotated around the standard horizontal and vertical offset axes used in OGSS by (typically) 20 to 30°. RGSS is seen to have one basic advantage over OGSS: More effective anti-aliasing near the horizontal and vertical axes, where the human eye can most easily detect screen aliasing (jaggies). This advantage also permits the use of fewer sub-samples to achieve approximately the same visual effect as OGSS. In addition, this paper examines the fill-rate, memory, and bandwidth usage of both anti-aliasing techniques. Super-sampling anti-aliasing is found to be a costly process that inevitably reduces graphics processing performance, typically by a substantial margin. However, anti-aliasing’s posi- tive impact on image quality is significant and is seen to be very important to an improved gaming experience and worth the performance cost. What is Aliasing? digital medium like a CD. This translates to graphics in that a sample represents a specific moment as well as a Computers have always strived to achieve a higher-level specific area. A pixel represents each area and a frame of quality in graphics, with the goal in mind of eventu- represents each moment. ally being able to create an accurate representation of reality. Of course, to achieve reality itself is impossible, At our current level of consumer technology, it simply as reality is infinitely detailed. -

CSMOUTE: Combined Synthetic Oversampling and Undersampling Technique for Imbalanced Data Classification
CSMOUTE: Combined Synthetic Oversampling and Undersampling Technique for Imbalanced Data Classification Michał Koziarski Department of Electronics AGH University of Science and Technology Al. Mickiewicza 30, 30-059 Kraków, Poland Email: [email protected] Abstract—In this paper we propose a novel data-level algo- ity observations (oversampling). Secondly, the algorithm-level rithm for handling data imbalance in the classification task, Syn- methods, which adjust the training procedure of the learning thetic Majority Undersampling Technique (SMUTE). SMUTE algorithms to better accommodate for the data imbalance. In leverages the concept of interpolation of nearby instances, previ- ously introduced in the oversampling setting in SMOTE. Further- this paper we focus on the former. Specifically, we propose more, we combine both in the Combined Synthetic Oversampling a novel undersampling algorithm, Synthetic Majority Under- and Undersampling Technique (CSMOUTE), which integrates sampling Technique (SMUTE), which leverages the concept of SMOTE oversampling with SMUTE undersampling. The results interpolation of nearby instances, previously introduced in the of the conducted experimental study demonstrate the usefulness oversampling setting in SMOTE [5]. Secondly, we propose a of both the SMUTE and the CSMOUTE algorithms, especially when combined with more complex classifiers, namely MLP and Combined Synthetic Oversampling and Undersampling Tech- SVM, and when applied on datasets consisting of a large number nique (CSMOUTE), which integrates SMOTE oversampling of outliers. This leads us to a conclusion that the proposed with SMUTE undersampling. The aim of this paper is to approach shows promise for further extensions accommodating serve as a preliminary study of the potential usefulness of local data characteristics, a direction discussed in more detail in the proposed approach, with the final goal of extending it to the paper. -

Efficient Multidimensional Sampling
EUROGRAPHICS 2002 / G. Drettakis and H.-P. Seidel Volume 21 (2002 ), Number 3 (Guest Editors) Efficient Multidimensional Sampling Thomas Kollig and Alexander Keller Department of Computer Science, Kaiserslautern University, Germany Abstract Image synthesis often requires the Monte Carlo estimation of integrals. Based on a generalized con- cept of stratification we present an efficient sampling scheme that consistently outperforms previous techniques. This is achieved by assembling sampling patterns that are stratified in the sense of jittered sampling and N-rooks sampling at the same time. The faster convergence and improved anti-aliasing are demonstrated by numerical experiments. Categories and Subject Descriptors (according to ACM CCS): G.3 [Probability and Statistics]: Prob- abilistic Algorithms (including Monte Carlo); I.3.2 [Computer Graphics]: Picture/Image Generation; I.3.7 [Computer Graphics]: Three-Dimensional Graphics and Realism. 1. Introduction general concept of stratification than just joining jit- tered and Latin hypercube sampling. Since our sam- Many rendering tasks are given in integral form and ples are highly correlated and satisfy a minimum dis- usually the integrands are discontinuous and of high tance property, noise artifacts are attenuated much 22 dimension, too. Since the Monte Carlo method is in- more efficiently and anti-aliasing is improved. dependent of dimension and applicable to all square- integrable functions, it has proven to be a practical tool for numerical integration. It relies on the point 2. Monte Carlo Integration sampling paradigm and such on sample placement. In- The Monte Carlo method of integration estimates the creasing the uniformity of the samples is crucial for integral of a square-integrable function f over the s- the efficiency of the stochastic method and the level dimensional unit cube by of noise contained in the rendered images. -

Signal Sampling
FYS3240 PC-based instrumentation and microcontrollers Signal sampling Spring 2017 – Lecture #5 Bekkeng, 30.01.2017 Content – Aliasing – Sampling – Analog to Digital Conversion (ADC) – Filtering – Oversampling – Triggering Analog Signal Information Three types of information: • Level • Shape • Frequency Sampling Considerations – An analog signal is continuous – A sampled signal is a series of discrete samples acquired at a specified sampling rate – The faster we sample the more our sampled signal will look like our actual signal Actual Signal – If not sampled fast enough a problem known as aliasing will occur Sampled Signal Aliasing Adequately Sampled SignalSignal Aliased Signal Bandwidth of a filter • The bandwidth B of a filter is defined to be between the -3 dB points Sampling & Nyquist’s Theorem • Nyquist’s sampling theorem: – The sample frequency should be at least twice the highest frequency contained in the signal Δf • Or, more correctly: The sample frequency fs should be at least twice the bandwidth Δf of your signal 0 f • In mathematical terms: fs ≥ 2 *Δf, where Δf = fhigh – flow • However, to accurately represent the shape of the ECG signal signal, or to determine peak maximum and peak locations, a higher sampling rate is required – Typically a sample rate of 10 times the bandwidth of the signal is required. Illustration from wikipedia Sampling Example Aliased Signal 100Hz Sine Wave Sampled at 100Hz Adequately Sampled for Frequency Only (Same # of cycles) 100Hz Sine Wave Sampled at 200Hz Adequately Sampled for Frequency and Shape 100Hz Sine Wave Sampled at 1kHz Hardware Filtering • Filtering – To remove unwanted signals from the signal that you are trying to measure • Analog anti-aliasing low-pass filtering before the A/D converter – To remove all signal frequencies that are higher than the input bandwidth of the device. -
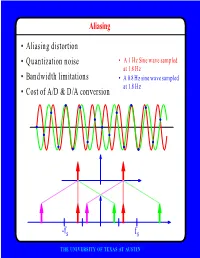
F • Aliasing Distortion • Quantization Noise • Bandwidth Limitations • Cost of A/D & D/A Conversion
Aliasing • Aliasing distortion • Quantization noise • A 1 Hz Sine wave sampled at 1.8 Hz • Bandwidth limitations • A 0.8 Hz sine wave sampled at 1.8 Hz • Cost of A/D & D/A conversion -fs fs THE UNIVERSITY OF TEXAS AT AUSTIN Advantages of Digital Systems Perfect reconstruction of a Better trade-off between signal is possible even after bandwidth and noise severe distortion immunity performance digital analog bandwidth Increase signal-to-noise ratio simply by adding more bits SNR = -7.2 + 6 dB/bit THE UNIVERSITY OF TEXAS AT AUSTIN Advantages of Digital Systems Programmability • Modifiable in the field • Implement multiple standards • Better user interfaces • Tolerance for changes in specifications • Get better use of hardware for low-speed operations • Debugging • User programmability THE UNIVERSITY OF TEXAS AT AUSTIN Disadvantages of Digital Systems Programmability • Speed is too slow for some applications • High average power and peak power consumption RISC (2 Watts) vs. DSP (50 mW) DATA PROG MEMORY MEMORY HARVARD ARCHITECTURE • Aliasing from undersampling • Clipping from quantization Q[v] v v THE UNIVERSITY OF TEXAS AT AUSTIN Analog-to-Digital Conversion 1 --- T h(t) Q[.] xt() yt() ynT() yˆ()nT Anti-Aliasing Sampler Quantizer Filter xt() y(nT) t n y(t) ^y(nT) t n THE UNIVERSITY OF TEXAS AT AUSTIN Resampling Changing the Sampling Rate • Conversion between audio formats Compact 48.0 Digital Disc ---------- Audio Tape 44.1 KHz44.1 48 KHz • Speech compression Speech 1 Speech for on DAT --- Telephone 48 KHz 6 8 KHz • Video format conversion -

Enhancing ADC Resolution by Oversampling
AVR121: Enhancing ADC resolution by oversampling 8-bit Features Microcontrollers • Increasing the resolution by oversampling • Averaging and decimation • Noise reduction by averaging samples Application Note 1 Introduction Atmel’s AVR controller offers an Analog to Digital Converter with 10-bit resolution. In most cases 10-bit resolution is sufficient, but in some cases higher accuracy is desired. Special signal processing techniques can be used to improve the resolution of the measurement. By using a method called ‘Oversampling and Decimation’ higher resolution might be achieved, without using an external ADC. This Application Note explains the method, and which conditions need to be fulfilled to make this method work properly. Figure 1-1. Enhancing the resolution. A/D A/D A/D 10-bit 11-bit 12-bit t t t Rev. 8003A-AVR-09/05 2 Theory of operation Before reading the rest of this Application Note, the reader is encouraged to read Application Note AVR120 - ‘Calibration of the ADC’, and the ADC section in the AVR datasheet. The following examples and numbers are calculated for Single Ended Input in a Free Running Mode. ADC Noise Reduction Mode is not used. This method is also valid in the other modes, though the numbers in the following examples will be different. The ADCs reference voltage and the ADCs resolution define the ADC step size. The ADC’s reference voltage, VREF, may be selected to AVCC, an internal 2.56V / 1.1V reference, or a reference voltage at the AREF pin. A lower VREF provides a higher voltage precision but minimizes the dynamic range of the input signal.