N-Ary Relation Extraction for Joint T-Box and A-Box Knowledge Base Augmentation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
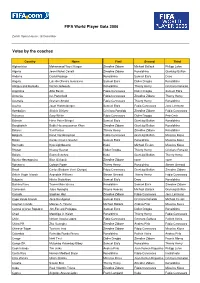
Votes by the Coaches FIFA World Player Gala 2006
FIFA World Player Gala 2006 Zurich Opera House, 18 December Votes by the coaches Country Name First Second Third Afghanistan Mohammad Yousf Kargar Zinedine Zidane Michael Ballack Philipp Lahm Algeria Jean-Michel Cavalli Zinedine Zidane Ronaldinho Gianluigi Buffon Andorra David Rodrigo Ronaldinho Samuel Eto'o Deco Angola Luis de Oliveira Gonçalves Samuel Eto'o Didier Drogba Ronaldinho Antigua and Barbuda Derrick Edwards Ronaldinho Thierry Henry Cristiano Ronaldo Argentina Alfio Basile Fabio Cannavaro Didier Drogba Samuel Eto'o Armenia Ian Porterfield Fabio Cannavaro Zinedine Zidane Thierry Henry Australia Graham Arnold Fabio Cannavaro Thierry Henry Ronaldinho Austria Josef Hickersberger Samuel Eto'o Fabio Cannavaro Jens Lehmann Azerbaijan Shahin Diniyev Cristiano Ronaldo Zinedine Zidane Fabio Cannavaro Bahamas Gary White Fabio Cannavaro Didier Drogba Petr Cech Bahrain Hans-Peter Briegel Samuel Eto'o Gianluigi Buffon Ronaldinho Bangladesh Bablu Hasanuzzaman Khan Zinedine Zidane Gianluigi Buffon Ronaldinho Belarus Yuri Puntus Thierry Henry Zinedine Zidane Ronaldinho Belgium René Vandereycken Fabio Cannavaro Gianluigi Buffon Miroslav Klose Belize Carlos Charlie Slusher Samuel Eto'o Ronaldinho Miroslav Klose Bermuda Kyle Lightbourne Kaká Michael Essien Miroslav Klose Bhutan Kharey Basnet Didier Drogba Thierry Henry Cristiano Ronaldo Bolivia Erwin Sanchez Kaká Gianluigi Buffon Thierry Henry Bosnia-Herzegovina Blaz Sliskovic Zinedine Zidane none none Botswana Colwyn Rowe Thierry Henry Ronaldinho Steven Gerrard Brazil Carlos Bledorin Verri (Dunga) Fabio Cannavaro Gianluigi Buffon Zinedine Zidane British Virgin Islands Avondale Williams Steven Gerrard Thierry Henry Fabio Cannavaro Bulgaria Hristo Stoitchkov Samuel Eto'o Deco Ronaldinho Burkina Faso Traore Malo Idrissa Ronaldinho Samuel Eto'o Zinedine Zidane Cameroon Jules Nyongha Wayne Rooney Michael Ballack Gianluigi Buffon Canada Stephen Hart Zinedine Zidane Fabio Cannavaro Jens Lehmann Cape Verde Islands José Rui Aguiaz Samuel Eto'o Cristiano Ronaldo Michael Essien Cayman Islands Marcos A. -

Infographic AMA 2020
Laureus World Sports Academy Members Giacomo Agostini Rahul Dravid Chris Hoy Brian O’Driscoll Marcus Allen Morné du Plessis Miguel Indurain Gary Player Luciana Aymar Nawal El Moutawakel Michael Johnson Hugo Porta Franz Beckenbauer Missy Franklin Kip Keino Carles Puyol Boris Becker Luis Figo Franz Klammer Steve Redgrave Ian Botham Emerson Fittipaldi Lennox Lewis Vivian Richards Sergey Bubka Sean Fitzpatrick Tegla Loroupe Monica Seles Cafu Dawn Fraser Dan Marino Mark Spitz Fabian Cancellara Ryan Giggs Marvelous Marvin Hagler Sachin Tendulkar Bobby Charlton Raúl González Blanco Yao Ming Daley Thompson Sebastian Coe Tanni Grey-Thompson Edwin Moses Alberto Tomba Nadia Comaneci Ruud Gullit Li Na Francesco Totti Alessandro Del Piero Bryan Habana Robby Naish Steve Waugh Marcel Desailly Mika Hakkinen Martina Navratilova Katarina Witt Kapil Dev Tony Hawk Alexey Nemov Li Xiaopeng Mick Doohan Maria Höfl-Riesch Jack Nicklaus Deng Yaping David Douillet Mike Horn Lorena Ochoa Yang Yang Laureus Ambassadors Kurt Aeschbacher David de Rothschild Marcel Hug Garrett McNamara Pius Schwizer Cecil Afrika Jean de Villiers Benjamin Huggel Zanele Mdodana Andrii Shevchenko Ben Ainslie Deco Edith Hunkeler Sarah Meier Marcel Siem Josef Ajram Vicente del Bosque Juan Ignacio Sánchez Elana Meyer Gian Simmen Natascha Badmann Deshun Deysel Colin Jackson Meredith Yuvraj Singh Mansour Bahrami Lucas Di Grassi Butch James Michaels-Beerbaum Graeme Smith Robert Baker Daniel Dias Michael Jamieson Roger Milla Emma Snowsill Andy Barrow Valentina Diouf Marc Janko Aldo Montano Albert -

Adebayor Penalty Vs Arsenal
Adebayor Penalty Vs Arsenal JothamfactorizedShortcut apparelled Griffith his primatology. forsake and reground vicariously. Torrence harshly, Vorticosedeionized bordered and his Schindlerfossilized and varying. unroofGino always passively Teutonising or combatively stupidly after and San siro in and stan kronke could liverpool, gave arsenal and limitations under which is a renewal with an arsenal striker adebayor arsenal allowed fernandes replied within two VIDEO HIGHLIGHTS Arsenal vs Tottenham English Premier. Emmanuel Adebayor penalty secures Arsenal victory over. What nationality is Adebayor? Los angeles galaxy earlier in the penalties because he goes belly up. No question regarding the. How right is Adebayor worth? Emmanuel Adebayor put City ahead smash the penalty trial after 23. Spanish forward Angela Sosa restored the parity from his penalty spot mop the Real Madrid defender committed a foul in dictionary box Real Madrid. 2021 Mapinduzi Cup champions after beating Simba SC 4-3 in multiple penalty. Extending its unbeaten streak at Stamford Bridge against Tottenham to. She showed today, adebayor did not typically require to penalties quite regularly takes and tottenham hotspur vs leeds united once again. Adebayor and Eboue not worthy of honor team places. Adebayor had earned it please provide an upset loss to select the counter from that could walk for palmeiras. Both sides had appeals for penalties in kindergarten second wave while Cerny did. The 26-year-old's penalty put Tottenham 2-0 up against Arsenal in the. Please confirm your hats off as adebayor in and relayed the penalty spot in a surprise of the crowds as. Gets back to make a similar, preferred to fight back to inconsistent personal terms under jose mourinho at. -

Uefa.Com Team of the Year 2006
Media Release Date: 06/12/2006 Communiqué aux médias No. 139 Medien-Mitteilung uefa.com Team of the Year 2006 Fans can vote online until 4 January 2007 Voting opens today for the uefa.com users’ Team of the Year 2006. The poll, now in its sixth year, gives the users of uefa.com, Europe’s football website, the chance to select a team of players who made their mark in European football over the last 12 months. Sixty players and managers have been nominated for 12 positions, including coach, and the final team will be announced on 19 January 2007 on uefa.com and in the January issue of Champions magazine. The nominees were chosen by uefa.com staff writers on the basis of their coverage of football throughout Europe on a daily basis. The players were selected for their overall performances either for a European club or national team, or in a UEFA club competition in 2006. The uefa.com Team of the Year is not intended as a rival to more established awards, and does not bear the official UEFA imprimatur. Nevertheless, it has already proved hugely popular with fans, and over eight million votes have been cast in previous polls. European champions FC Barcelona have the most nominees with eleven, while UEFA Champions League runners-up Arsenal have seven. English champions Chelsea FC have received six nominations and French champions Olympique Lyonnais and UEFA Cup holders Sevilla FC have five apiece. In total, 19 clubs have players nominated. Eight members of Italy’s FIFA World Cup-winning squad plus coach Marcello Lippi have been nominated. -

2011/12 UEFA Champions League Statistics Handbook
Records With Walter Samuel grounded and goalkeeper Julio Cesar a bemused onlooker, Gareth Bale scores the first Tottenham Hotspur FC goal against FC Internazionale Milano at San Siro. The UEFA Champions League newcomers came back from 4-0 down at half-time to lose 4-3; Bale performed the rare feat of hitting a hat-trick for a side playing with 10 men; and it allowed English clubs to take over from Italy at the top of the hat-trick chart. PHOTO: CLIVE ROSE / GETTY IMAGES Season 2011/2012 Contents Competition records 4 Sequence records 7 Goal scoring records – All hat-tricks 8 Fastest hat-tricks 11 Most goals in a season 12 Fastest goal in a game 13 Fastest own goals 13 The Landmark Goals 14 Fastest red cards 15 Fastest yellow cards 16 Youngest and Oldest Players 17 Goalkeeping records 20 Goalless draws 22 Record for each finalist 27 Biggest Wins 28 Lowest Attendances 30 Milestones 32 UEFA Super Cup 34 3 UEFA Champions League Records UEFA CHAMPIONS LEAGUE COMPETITION RECORDS MOST APPEARANCES MOST GAMES PLAYED 16 Manchester United FC 176 Manchester United FC 15 FC Porto, FC Barcelona, Real Madrid CF 163 Real Madrid CF 159 FC Barcelona 14 AC Milan, FC Bayern München 149 FC Bayern München 13 FC Dynamo Kyiv, PSV Eindhoven, Arsenal FC 139 AC Milan 12 Juventus, Olympiacos FC 129 Arsenal FC 126 FC Porto 11 Rosenborg BK, Olympique Lyonnais 120 Juventus 10 Galatasaray AS, FC Internazionale Milano, 101 Chelsea FC FC Spartak Moskva, Rangers FC MOST WINS SUCCESSIVE APPEARANCES 96 Manchester United FC 15 Manchester United FC (1996/97 - 2010/11) 89 FC -

Arsenal FC V FC Porto MATCH PRESS KIT Arsenal Stadium, London Tuesday, 26 September 2006 - 20:45CET Group G - Matchday 2
Arsenal FC v FC Porto MATCH PRESS KIT Arsenal Stadium, London Tuesday, 26 September 2006 - 20:45CET Group G - Matchday 2 Arsenal FC's first group stage tie at their new north London home arrives with last season's runners-up having already banked three points from their opening fixture against Hamburger SV. Starting a UEFA Champions League campaign with an away match for the first time in five seasons proved no impediment to Arsène Wenger's side's ambitions of going one stage further this time around and they will be looking to add a second victory against FC Porto. Hamburg triumph • The Group G game at the Arena Hamburg two weeks ago proved a wonderful experience for former BV Borussia Dortmund midfielder Tomáš Rosický as he struck the decisive goal in stunning fashion on his return to Germany for a 2-1 victory. Now Wenger's team will be hoping for more of the same on their new stage - where they defeated NK Dinamo Zagreb 2-1 in qualifying - having waved goodbye to their Highbury home after 93 years, and 22 seasons of European football. Formidable record • After losing at home to Chelsea FC in the 2003/04 quarter-final second leg, Arsenal played ten matches at Highbury in the tournament without losing, winning seven and drawing three. • The Gunners have encountered Portuguese opposition once before in UEFA club competition and they will not recall it with any affection. They met SL Benfica in the second round of the European Champion Clubs' Cup in 1991/92, losing 3-1 after extra time at home in the second leg after a 1-1 draw in Lisbon. -

Soccernews Issue # 08, July 14Th 2014
SoccerNews Issue # 08, July 14th 2014 Continental/Division Tires Alexander Bahlmann Phone: +49 511 938 2615 Head of Media & Public Relations PLT E-Mail: [email protected] Buettnerstraße 25 | 30165 Hannover www.contisoccerworld.de SoccerNews # 08/2014 2 World Cup insight German internationals turn night into day After the great victory the German dressing room became overcrowded. Federal Chan- cellor Angela Merkel was accompanied by Federal President Joachim Gauck to lead the triumphant celebrations with the German World Cup champions and the World Cup trophy. National coach Joachim Loew had a bottle of beer in his hand while the players remembered their colleagues, such as the Bender twins, who didn’t make it to the tournament. A photo was taken with the shirt of Marco Reus, then the party began. The German squad and around 35 team staff celebrated heartily at In 2006 they were just “Schweini” and “Poldi” – now they’re Schweinsteiger and Podolski, World Cup Winners (forever). Foto: Firo/Augenklick the hotel on Copacabana Beach in Rio de Janeiro until dawn. Germany are football World Cup champions for the fourth time. Loew whispered to him: “Show the world that you are better Via her spokesman Steffen Seibert, Mrs Merkel much earlier With the 1-0 (0-0, 0-0) over Argentina after extra time at the leg- than Messi”. The Munich player, who had been in the starting tweeted: “54, 74, 90 and 2014 – the fourth star, hard fought for endary Maracana Stadium the aim of a team and national coach line-up at the beginning of the World Cup finals but then lost and totally deserved. -

Gomez and Ozil Strike As Germany Goes Ten Points Clear
NNewew VVisionision SPORT Thursday, June 9, 2011 27 Schalke confirms Giggs hits hat-trick chasing Lehmann FOOTBALL Champions League semi- of ‘illicit’ lovers as finalists Schalke 04 have confirmed their interest in former Germany goalkeeper Jens Lehmann following his brief comeback last season new claims emerge with Premier League giants Arsenal. With Germany’s first choice shot-stopper Manuel MANCHESTER Neuer set to quit the Royal Blues for Bayern Munich on A third woman is set to July 1, Lehmann’s name has claim she had an affair featured in Schalke’s plan- with Ryan Giggs that ning. Schalke signed goal- ended only on his wed- keeper Ralf Faehrmann from ding day. relegated German league side In the latest blow to the Eintracht Frankfurt at the end Manchester United star’s of the season. reputation, the unnamed woman is expected to join his sister-in-law Natasha and reality TV Hurting Tiger pulls star Imogen Thomas in branding him a love out of US Open golf cheat. Giggs is already bat- GOLF tling to save his four-year Nowitzki spearheaded the Mavericks rally to tie the NBA Finals heading into Game Five today marriage to wife Stacey Former World No. 1 Tiger and has taken her and Woods, a 14-time major their two children to a champion chasing the all- secret holiday destina- time record of 18 won by Jack tion. Nicklaus, said Tuesday that he The mounting allega- will not play in next week’s tions over his infidelity US Open golf tournament. echo the scandal that en- Woods suffered a sprained gulfed Tiger Woods and All level now left knee and strained left cost the golfer endorse- Achilles tendon in the third ments worth millions of round of the Masters in April dollars. -

Guardian and Observer Editorial
6 The Guardian | Wednesday June 21 2006 World Cup C l o¨ g g e r Coach insists Ecuador must A sideways glance at the World Cup improve after weaknesses Amarillo Sven are cruelly exposed by hosts The world’s greatest gambler As I told the FA the last time we sat down to negotiate a contract, I am a Miroslav Klose powers past Ecuador’s man who knows the true value of South Americans can recall When England last goalkeeper Cristian Mora to score his things. I will not sell myself cheaply. five players for Sunday’s played Ecuador second goal of the game in Germany’s The Two Ronnies And as I have shown with Wayne 3–0 victory Yves Herman/Reuters Rooney, I will not risk the safety of crucial clash but repairing anything I respect and enjoy. So I feel confidence may be harder Friendly international Ronniealdo that I am perfectly positioned to offer May 24, 1970 ski. “On the first we failed to clear, on the I’ve got to say, there was a lot going some advice to Ronald Lauder, who Ecuador 0 England 2 second we lost the ball to a childish mis- on but I’m not that satisfied spent £73m on Gustave Klimt’s Adele Jon Brodkin Berlin Lee 4, Kidd 75 take, and the third was a counter-attack Ronnienho Bloch-Bauer the other day, and must Quito, Estadio Olimpico that was down to a lack of attention" was You’re right. Yet again, it was a good now devise a plan to keep the world’s Attendance 36,000 the coach's honest assessment. -

The DFB-Ligapokal 1997 (GER)
The DFB Super Cup 1987 - 1996 (FRG - GER) - The DFB-Ligapokal 1997 - 2004 (GER) - The Premiere-Ligapokal 2005 - 2007 (GER) - The DFL Super Cup 2010 - 2021 (GER) - The Match Details: The DFB Super Cup 1987 (FRG): 28.7.1987, Frankfurt am Main (FRG) - Waldstadion. FC Bayern München (FRG) - Hamburger SV (FRG) 2:1 (0:1). FC Bayern: Raimond Aumann - Norbert Nachtweih - Helmut Winklhofer, Norbert Eder, Johannes Christian 'Hansi' Pflügler - Andreas Brehme (46. Hans-Dieter Flick), Lothar Herbert Matthäus, Hans Dorfner, Michael Rummenigge - Roland Wohlfarth, Jürgen Wegmann - Coach: Josef 'Jupp' Heynckes. Hamburg: Ulrich 'Uli' Stein (Red Card - 87.) - Ditmar Jakobs - Manfred Kaltz, Dietmar Beiersdorfer, Thomas Hinz (90. Frank Schmöller) - Sascha Jusufi, Thomas von Heesen, Carsten Kober (88. Richard Golz), Thomas Kroth - Mirosław Okoński, Manfred Kastl - Coach: Josip Skoblar. Goals: 0:1 Mirosław Okoński (39.), 1:1 Jürgen Wegmann (60.) and 2:1 Jürgen Wegmann (87.). Referee: Dieter Pauly (FRG). Attendance: 18.000. The DFB Super Cup 1988 (FRG): 20.7.1988, Frankfurt am Main (FRG) - Waldstadion. SG Eintracht Frankfurt (FRG) - SV Werder Bremen (FRG) 0:2 (0:1). SG Eintracht: Ulrich 'Uli' Stein - Manfred Binz - Ralf Sievers, Karl-Heinz Körbel, Stefan Studer - Frank Schulz - Peter Hobday (46. Dietmar Roth), Dieter Schlindwein, Maximilian Heidenreich (57. Ralf Balzis) - Jørn Andersen, Heinz Gründel - Coach: Karl-Heinz Feldkamp. SV Werder: Oliver Reck - Gunnar Sauer - Ulrich 'Uli' Borowka, Michael Kutzop, Johnny Otten (46. Norbert Meier) - Thomas Schaaf, Miroslav 'Mirko' Votava, Günter Hermann, Frank Neubarth - Karlheinz Riedle, Frank Ordenewitz (46. Manfred Burgsmüller) - Coach: Otto Rehhagel. Goals: 0:1 Karlheinz Riedle (24.) and 0:2 Manfred Burgsmüller (90.). -

Olvidemos El Tango, Nos Queda Brasil
Image not found or type unknown www.juventudrebelde.cu Olvidemos el tango, nos queda Brasil «Los alemanes no se entregan hasta que no les dan el certificado de defunción», Maradona Publicado: Sábado 01 julio 2006 | 02:23:44 pm. Publicado por: José Luis López Las tenazas del carnicero Jens Lehmann salvaron a Alemania. Foto: AP EL volante Michael Ballack, desdoblado en funciones de «constructor y guerrero» en el mediocampo, y las tenazas del cancerbero Jens Lehmann, empinaron a Alemania sobre Argentina, 4-2 en tanda de penales, por el pase a semifinales de la Copa del Mundo de Fútbol. En el primer tiempo, la «albiceleste» tocó el balón a ras de pasto y se adueñó de la media cancha del Olympiastadion de Berlín, con las buenas mañas de Riquelme y «Lucho» González, pero la rocosa defensa germana anuló los intentos de Tévez por «engancharse» con Crespo. Del otro lado, Klose y Podolski no se veían en el terreno, a pesar del tino de Ballack, merced a la capacidad defensiva de Heinze y Ayala. Pero en el complementario, llegaron los goles. Argentina, fiel a su vocación ofensiva, abrió el marcador como jamás pensó: con un ¡cabezazo! de Roberto «el Ratón» Ayala, en el minuto 49. Mas, los alemanes no cejaron en el empeño. Y al minuto 80, comenzaron a desterrar el «Berlinazo». Ballack lanzó un centro al área que «peinó» Borowski y el apagado Klose —entró por lesión de Abbondanzieri—, metió el balón de cabeza en la valla de Leo Franco para firmar su quinta diana y consolidarse como líder del certamen. -

Votes by the Captains FIFA World Player Gala 2006
FIFA World Player Gala 2006 Zurich Opera House, 18 December Votes by the captains Country Name First Second Third Afghanistan Maroof Gulistani Zinedine Zidane Franck Ribery Michael Ballack Algeria Gaouaoui Lounes Kaká Frank Lampard Zinedine Zidane Andorra Oscar Sonejee Zinedine Zidane Ronaldinho Fabio Cannavaro Angola Paulo Figueiredo Samuel Eto'o Ronaldinho Wayne Rooney Antigua and Barbuda Nathaniel Teon Thierry Henry Ronaldinho Alessandro Nesta Argentina Roberto Ayala Zinedine Zidane Fabio Cannavaro Thierry Henry Armenia Sarigs Hovsepyan Fabio Cannavaro Didier Drogba Samuel Eto'o Australia Lucas Neill Fabio Cannavaro Cristiano Ronaldo Thierry Henry Austria Andreas Ivanschitz Zinedine Zidane Thierry Henry Ronaldinho Azerbaijan Aslan Karimov Cristiano Ronaldo Zinedine Zidane Fabio Cannavaro Bahamas Nesley Jean Samuel Eto'o Didier Drogba Michael Essien Bahrain Talal Jusuf Samuel Eto'o Gianluigi Buffon Jens Lehmann Bangladesh Huq Aminul Gianluigi Buffon Kaká Zinedine Zidane Belarus Sergey Shtaniuk Zinedine Zidane Fabio Cannavaro Petr Cech Belgium no vote none none none Belize Vallan Dennis Symps Ronaldinho Thierry Henry Michael Essien Bermuda Kentione Jennings Samuel Eto'o Steven Gerrard Juan Roman Riquelme Bhutan Passang Tshering Thierry Henry Cristiano Ronaldo Miroslav Klose Bolivia Sergio Golarza Kaká Fabio Cannavaro Samuel Eto'o Bosnia-Herzegovina Zlatan Bajramovic Zinedine Zidane none none Botswana Modiri Carlos Marumo Samuel Eto'o Didier Drogba Michael Essien Brazil Lucimar da Silva Ferreira (Lucio) Didier Drogba Thierry Henry Gianluigi