Circuit Switching
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Digital Subscriber Line (DSL) Technologies
CHAPTER21 Chapter Goals • Identify and discuss different types of digital subscriber line (DSL) technologies. • Discuss the benefits of using xDSL technologies. • Explain how ASDL works. • Explain the basic concepts of signaling and modulation. • Discuss additional DSL technologies (SDSL, HDSL, HDSL-2, G.SHDSL, IDSL, and VDSL). Digital Subscriber Line Introduction Digital Subscriber Line (DSL) technology is a modem technology that uses existing twisted-pair telephone lines to transport high-bandwidth data, such as multimedia and video, to service subscribers. The term xDSL covers a number of similar yet competing forms of DSL technologies, including ADSL, SDSL, HDSL, HDSL-2, G.SHDL, IDSL, and VDSL. xDSL is drawing significant attention from implementers and service providers because it promises to deliver high-bandwidth data rates to dispersed locations with relatively small changes to the existing telco infrastructure. xDSL services are dedicated, point-to-point, public network access over twisted-pair copper wire on the local loop (last mile) between a network service provider’s (NSP) central office and the customer site, or on local loops created either intrabuilding or intracampus. Currently, most DSL deployments are ADSL, mainly delivered to residential customers. This chapter focus mainly on defining ADSL. Asymmetric Digital Subscriber Line Asymmetric Digital Subscriber Line (ADSL) technology is asymmetric. It allows more bandwidth downstream—from an NSP’s central office to the customer site—than upstream from the subscriber to the central office. This asymmetry, combined with always-on access (which eliminates call setup), makes ADSL ideal for Internet/intranet surfing, video-on-demand, and remote LAN access. Users of these applications typically download much more information than they send. -

A Technology Comparison Adopting Ultra-Wideband for Memsen’S File Sharing and Wireless Marketing Platform
A Technology Comparison Adopting Ultra-Wideband for Memsen’s file sharing and wireless marketing platform What is Ultra-Wideband Technology? Memsen Corporation 1 of 8 • Ultra-Wideband is a proposed standard for short-range wireless communications that aims to replace Bluetooth technology in near future. • It is an ideal solution for wireless connectivity in the range of 10 to 20 meters between consumer electronics (CE), mobile devices, and PC peripheral devices which provides very high data-rate while consuming very little battery power. It offers the best solution for bandwidth, cost, power consumption, and physical size requirements for next generation consumer electronic devices. • UWB radios can use frequencies from 3.1 GHz to 10.6 GHz, a band more than 7 GHz wide. Each radio channel can have a bandwidth of more than 500 MHz depending upon its center frequency. Due to such a large signal bandwidth, FCC has put severe broadcast power restrictions. By doing so UWB devices can make use of extremely wide frequency band while emitting very less amount of energy to get detected by other narrower band devices. Hence, a UWB device signal can not interfere with other narrower band device signals and because of this reason a UWB device can co-exist with other wireless devices. • UWB is considered as Wireless USB – replacement of standard USB and fire wire (IEEE 1394) solutions due to its higher data-rate compared to USB and fire wire. • UWB signals can co-exists with other short/large range wireless communications signals due to its own nature of being detected as noise to other signals. -
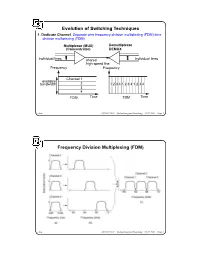
Evolution of Switching Techniques Frequency Division Multiplexing
Evolution of Switching Techniques 1. Dedicate Channel. Separate wire frequency division multiplexing (FDM) time division multiplexing (TDM) Multiplexor (MUX) Demultiplexor (Concentrator) DEMUX individual lines shared individual lines high speed line Frequency Frequency Channel 1 available bandwidth 2 1 2 3 4 1 2 3 4 1 2 3 4 3 4 FDM Time TDM Time chow CS522 F2001—Multiplexing and Switching—10/17/2001—Page 1 Frequency Division Multiplexing (FDM) chow CS522 F2001—Multiplexing and Switching—10/17/2001—Page 2 Wavelength Division Multiplexing chow CS522 F2001—Multiplexing and Switching—10/17/2001—Page 3 Impact of WDM z Many big organizations are starting projects to design WDM system or DWDN (Dense Wave Division Mutiplexing Network). We may see products appear in next three years.In Fujitsu and CCL/Taiwan, 128 different wavelengthes on the same strand of fiber was reported working in the lab. z We may have optical routers between end systems that can take one wavelenght signal, covert to different wavelenght, send it out on different links. Some are designing traditional routers that covert optical signal to electronical signal, and use time slot interchange based on high speed memory to do the switching, the convert the electronic signal back to optical signal. z With this type of optical networks, we will have a virtual circuit network, where each connection is assigned some wave length. Each connection can have 2.4 gbps tremedous bandwidth. z With inital 128 different wavelength, we can have about 10 end users. If each pair of end users needs to communicate simultaneously, it will use 10*10=100 different wavelength. -

D4.2 – Report on Technical and Quality of Service Viability
Ref. Ares(2019)1779406 - 18/03/2019 (H2020 730840) D4.2 – Report on Technical and Quality of Service Viability Version 1.2 Published by the MISTRAL Consortium Dissemination Level: Public This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 730840 H2020-S2RJU-2015-01/H2020-S2RJU-OC-2015-01-2 Topic S2R-OC-IP2-03-2015: Technical specifications for a new Adaptable Communication system for all Railways Final Version Document version: 1.2 Submission date: 2019-03-12 MISTRAL D4.2 – Report on Technical and Quality of Service Viability Document control page Document file: D4.2 Report on Technical and Quality of Service Viability Document version: 1.2 Document owner: Alexander Wolf (TUD) Work package: WP4 – Technical Viability Analysis Task: T4.3, T4.4 Deliverable type: R Document status: approved by the document owner for internal review approved for submission to the EC Document history: Version Author(s) Date Summary of changes made 0.1 Alexander Wolf (TUD) 2017-12-27 TOCs and content description 0.4 Alexander Wolf (TUD) 2018-01-31 First draft version 0.5 Carles Artigas (ARD) 2018-02-02 Contribution on LTE Security, Chapter 5 0.8 Alexander Wolf (TUD) 2018-03-31 Second draft version 0.9 Alexander Wolf (TUD) 2018-04-27 Release candidate 1.0 Alexander Wolf (TUD) 2018-04-30 Final version 1.0.1 Alexander Wolf (TUD) 2018-05-02 Formatting corrections 1.0.2 Alexander Wolf (TUD) 2018-05-08 Minor additions on chapter 6 1.1 Alexander Wolf (TUD) 2018-10-29 Minor additions after 3GPP comments 1.2 Alexander Wolf (TUD) 2019-03-12 Revision after Shift2Rail JU comments Internal review history: Reviewed by Date Summary of comments Edoardo Bonetto (ISMB) 2018-04-19 Review, comments and remarks Laura Masullo (SIRTI) 2018-04-19 Review, comments and remarks Laura Masullo (SIRTI) 2018-04-29 Review Document version : 1.2 Page 2 of 88 Submission date: 2019-03-12 MISTRAL D4.2 – Report on Technical and Quality of Service Viability Legal Notice The information in this document is subject to change without notice. -

(Qos) and Quality of Experience (Qoe) Issues in Video Service Provider Networks ––
Troubleshooting Quality of Service (QoS) and Quality of Experience (QoE) issues in Video Service Provider Networks –– APPLICATION NOTE Application Note 2 www.tek.com/mpeg-video-test-solution-series/mpeg-analyzer Troubleshooting Quality of Service (QoS) and Quality of Experience (QoE) issues in Broadcast and Cable Networks Video Service Providers deliver TV programs using a variety is critical to have access or test points throughout the facility. of different network architectures. Most of these networks The minimum set of test points in any network should be at include satellite for distribution (ingest), ASI or IP throughout the point of ingest where the signal comes into the facility, the the facility, and often RF to the home or customer premise ASI or IP switch, and finally egress where the signal leaves as (egress). The quality of today’s digital video and audio is IP or RF. With a minimum of these three access points, it is usually quite good, but when audio or video issues appear at now possible to isolate the issue to have originated at either: random, it is usually quite difficult to pinpoint the root cause ingest, facility, or egress. of the problem. The issue might be as simple as an encoder To begin testing a signal that may contain the suspected over-compressing a few pictures during a scene with high issue, two related methods are often used, Quality of Service motion. Or, the problem might be from a random weather (QoS), and Quality of Experience (QoE). Both methods are event (e.g., heavy wind, rain, snow, etc.). -

Spread Spectrum and Wi-Fi Basics Syed Masud Mahmud, Ph.D
Spread Spectrum and Wi-Fi Basics Syed Masud Mahmud, Ph.D. Electrical and Computer Engineering Dept. Wayne State University Detroit MI 48202 Spread Spectrum and Wi-Fi Basics by Syed M. Mahmud 1 Spread Spectrum Spread Spectrum techniques are used to deliberately spread the frequency domain of a signal from its narrow band domain. These techniques are used for a variety of reasons such as: establishment of secure communications, increasing resistance to natural interference and jamming Spread Spectrum and Wi-Fi Basics by Syed M. Mahmud 2 Spread Spectrum Techniques Frequency Hopping Spread Spectrum (FHSS) Direct -Sequence Spread Spectrum (DSSS) Orthogonal Frequency-Division Multiplexing (OFDM) Spread Spectrum and Wi-Fi Basics by Syed M. Mahmud 3 The FHSS Technology FHSS is a method of transmitting signals by rapidly switching channels, using a pseudorandom sequence known to both the transmitter and receiver. FHSS offers three main advantages over a fixed- frequency transmission: Resistant to narrowband interference. Difficult to intercept. An eavesdropper would only be able to intercept the transmission if they knew the pseudorandom sequence. Can share a frequency band with many types of conventional transmissions with minimal interference. Spread Spectrum and Wi-Fi Basics by Syed M. Mahmud 4 The FHSS Technology If the hop sequence of two transmitters are different and never transmit the same frequency at the same time, then there will be no interference among them. A hopping code determines the frequencies the radio will transmit and in which order. A set of hopping codes that never use the same frequencies at the same time are considered orthogonal . -

Lecture 8: Overview of Computer Networking Roadmap
Lecture 8: Overview of Computer Networking Slides adapted from those of Computer Networking: A Top Down Approach, 5th edition. Jim Kurose, Keith Ross, Addison-Wesley, April 2009. Roadmap ! what’s the Internet? ! network edge: hosts, access net ! network core: packet/circuit switching, Internet structure ! performance: loss, delay, throughput ! media distribution: UDP, TCP/IP 1 What’s the Internet: “nuts and bolts” view PC ! millions of connected Mobile network computing devices: server Global ISP hosts = end systems wireless laptop " running network apps cellular handheld Home network ! communication links Regional ISP " fiber, copper, radio, satellite access " points transmission rate = bandwidth Institutional network wired links ! routers: forward packets (chunks of router data) What’s the Internet: “nuts and bolts” view ! protocols control sending, receiving Mobile network of msgs Global ISP " e.g., TCP, IP, HTTP, Skype, Ethernet ! Internet: “network of networks” Home network " loosely hierarchical Regional ISP " public Internet versus private intranet Institutional network ! Internet standards " RFC: Request for comments " IETF: Internet Engineering Task Force 2 A closer look at network structure: ! network edge: applications and hosts ! access networks, physical media: wired, wireless communication links ! network core: " interconnected routers " network of networks The network edge: ! end systems (hosts): " run application programs " e.g. Web, email " at “edge of network” peer-peer ! client/server model " client host requests, receives -

Diffserv -- the Scalable End-To-End Qos Model
WHITE PAPER DIFFSERV—THE SCALABLE END-TO-END QUALITY OF SERVICE MODEL Last Updated: August 2005 The Internet is changing every aspect of our lives—business, entertainment, education, and more. Businesses use the Internet and Web-related technologies to establish Intranets and Extranets that help streamline business processes and develop new business models. Behind all this success is the underlying fabric of the Internet: the Internet Protocol (IP). IP was designed to provide best-effort service for delivery of data packets and to run across virtually any network transmission media and system platform. The increasing popularity of IP has shifted the paradigm from “IP over everything,” to “everything over IP.” In order to manage the multitude of applications such as streaming video, Voice over IP (VoIP), e-commerce, Enterprise Resource Planning (ERP), and others, a network requires Quality of Service (QoS) in addition to best-effort service. Different applications have varying needs for delay, delay variation (jitter), bandwidth, packet loss, and availability. These parameters form the basis of QoS. The IP network should be designed to provide the requisite QoS to applications. For example, VoIP requires very low jitter, a one-way delay in the order of 150 milliseconds and guaranteed bandwidth in the range of 8Kbps -> 64Kbps, dependent on the codec used. In another example, a file transfer application, based on ftp, does not suffer from jitter, while packet loss will be highly detrimental to the throughput. To facilitate true end-to-end QoS on an IP-network, the Internet Engineering Task Force (IETF) has defined two models: Integrated Services (IntServ) and Differentiated Services (DiffServ). -

Guidelines on Mobile Device Forensics
NIST Special Publication 800-101 Revision 1 Guidelines on Mobile Device Forensics Rick Ayers Sam Brothers Wayne Jansen http://dx.doi.org/10.6028/NIST.SP.800-101r1 NIST Special Publication 800-101 Revision 1 Guidelines on Mobile Device Forensics Rick Ayers Software and Systems Division Information Technology Laboratory Sam Brothers U.S. Customs and Border Protection Department of Homeland Security Springfield, VA Wayne Jansen Booz-Allen-Hamilton McLean, VA http://dx.doi.org/10.6028/NIST.SP. 800-101r1 May 2014 U.S. Department of Commerce Penny Pritzker, Secretary National Institute of Standards and Technology Patrick D. Gallagher, Under Secretary of Commerce for Standards and Technology and Director Authority This publication has been developed by NIST in accordance with its statutory responsibilities under the Federal Information Security Management Act of 2002 (FISMA), 44 U.S.C. § 3541 et seq., Public Law (P.L.) 107-347. NIST is responsible for developing information security standards and guidelines, including minimum requirements for Federal information systems, but such standards and guidelines shall not apply to national security systems without the express approval of appropriate Federal officials exercising policy authority over such systems. This guideline is consistent with the requirements of the Office of Management and Budget (OMB) Circular A-130, Section 8b(3), Securing Agency Information Systems, as analyzed in Circular A- 130, Appendix IV: Analysis of Key Sections. Supplemental information is provided in Circular A- 130, Appendix III, Security of Federal Automated Information Resources. Nothing in this publication should be taken to contradict the standards and guidelines made mandatory and binding on Federal agencies by the Secretary of Commerce under statutory authority. -

Autoqos for Voice Over IP (Voip)
WHITE PAPER AUTOQoS FOR VOICE OVER IP Last Updated: September 2008 Customer networks exist to service application requirements and end users efficiently. The tremendous growth of the Internet and corporate intranets, the wide variety of new bandwidth-hungry applications, and convergence of data, voice, and video traffic over consolidated IP infrastructures has had a major impact on the ability of networks to provide predictable, measurable, and guaranteed services to these applications. Achieving the required Quality of Service (QoS) through the proper management of network delays, bandwidth requirements, and packet loss parameters, while maintaining simplicity, scalability, and manageability of the network is the fundamental solution to running an infrastructure that serves business applications end-to-end. Cisco IOS ® Software offers a portfolio of QoS features that enable customer networks to address voice, video, and data application requirements, and are extensively deployed by numerous Enterprises and Service Provider networks today. Cisco AutoQoS dramatically simplifies QoS deployment by automating Cisco IOS QoS features for voice traffic in a consistent manner and leveraging the advanced functionality and intelligence of Cisco IOS Software. Figure 1 illustrates how Cisco AutoQoS provides the user a simple, intelligent Command Line Interface (CLI) for enabling campus LAN and WAN QoS for Voice over IP (VoIP) on Cisco switches and routers. The network administrator does not need to possess extensive knowledge of the underlying network -

Research on the System Structure of IPV9 Based on TCP/IP/M
International Journal of Advanced Network, Monitoring and Controls Volume 04, No.03, 2019 Research on the System Structure of IPV9 Based on TCP/IP/M Wang Jianguo Xie Jianping 1. State and Provincial Joint Engineering Lab. of 1. Chinese Decimal Network Working Group Advanced Network, Monitoring and Control Shanghai, China 2. Xi'an, China Shanghai Decimal System Network Information 2. School of Computer Science and Engineering Technology Ltd. Xi'an Technological University e-mail: [email protected] Xi'an, China e-mail: [email protected] Wang Zhongsheng Zhong Wei 1. School of Computer Science and Engineering 1. Chinese Decimal Network Working Group Xi'an Technological University Shanghai, China Xi'an, China 2. Shanghai Decimal System Network Information 2. State and Provincial Joint Engineering Lab. of Technology Ltd. Advanced Network, Monitoring and Control e-mail: [email protected] Xi'an, China e-mail: [email protected] Abstract—Network system structure is the basis of network theory, which requires the establishment of a link before data communication. The design of network model can change the transmission and the withdrawal of the link after the network structure from the root, solve the deficiency of the transmission is completed. It solves the problem of original network system, and meet the new demand of the high-quality real-time media communication caused by the future network. TCP/IP as the core network technology is integration of three networks (communication network, successful, it has shortcomings but is a reasonable existence, broadcasting network and Internet) from the underlying will continue to play a role. Considering the compatibility with structure of the network, realizes the long-distance and the original network, the new network model needs to be large-traffic data transmission of the future network, and lays compatible with the existing TCP/IP four-layer model, at the a solid foundation for the digital currency and virtual same time; it can provide a better technical system to currency of the Internet. -
Circuit-Switched Coherence
Circuit-Switched Coherence ‡Natalie Enright Jerger, ‡Mikko Lipasti, and ?Li-Shiuan Peh ‡Electrical and Computer Engineering Department, University of Wisconsin-Madison ?Department of Electrical Engineering, Princeton University Abstract—Circuit-switched networks can significantly lower contention, overall system performance can degrade by 20% the communication latency between processor cores, when or more. This latency sensitivity coupled with low link uti- compared to packet-switched networks, since once circuits are set up, communication latency approaches pure intercon- lization motivates our exploration of circuit-switched fabrics nect delay. However, if circuits are not frequently reused, the for CMPs. long set up time and poorer interconnect utilization can hurt Our investigations show that traditional circuit-switched overall performance. To combat this problem, we propose a hybrid router design which intermingles packet-switched networks do not perform well, as circuits are not reused suf- flits with circuit-switched flits. Additionally, we co-design a ficiently to amortize circuit setup delay. This observation prediction-based coherence protocol that leverages the exis- motivates a network with a hybrid router design that sup- tence of circuits to optimize pair-wise sharing between cores. The protocol allows pair-wise sharers to communicate di- ports both circuit and packet switching with very fast circuit rectly with each other via circuits and drives up circuit reuse. reconfiguration (setup/teardown). Our preliminary results Circuit-switched coherence provides overall system perfor- show this leading to up to 8% improvement in overall system mance improvements of up to 17% with an average improve- performance over a packet-switched fabric. ment of 10% and reduces network latency by up to 30%.