International Journal of Software Engineering (Ijse)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Xp Project Management
University of Montana ScholarWorks at University of Montana Graduate Student Theses, Dissertations, & Professional Papers Graduate School 2007 XP PROJECT MANAGEMENT Craig William Macholz The University of Montana Follow this and additional works at: https://scholarworks.umt.edu/etd Let us know how access to this document benefits ou.y Recommended Citation Macholz, Craig William, "XP PROJECT MANAGEMENT" (2007). Graduate Student Theses, Dissertations, & Professional Papers. 1201. https://scholarworks.umt.edu/etd/1201 This Thesis is brought to you for free and open access by the Graduate School at ScholarWorks at University of Montana. It has been accepted for inclusion in Graduate Student Theses, Dissertations, & Professional Papers by an authorized administrator of ScholarWorks at University of Montana. For more information, please contact [email protected]. XP PROJECT MANAGEMENT By Craig William Macholz BS in Business Administration, The University of Montana, Missoula, MT, 1997 Thesis presented in partial fulfillment of the requirements for the degree of Master of Science in Computer Science The University of Montana Missoula, MT Autumn 2007 Approved by: Dr. David A. Strobel, Dean Graduate School Dr. Joel Henry Computer Science Dr. Yolanda Reimer Computer Science Dr. Shawn Clouse Business Administration i Macholz, Craig, M.S., December 2007 Computer Science Extreme Programming Project Management Chairperson: Dr. Joel Henry Extreme programming project management examines software development theory, the extreme programming process, and the essentials of standard project management as applied to software projects. The goal of this thesis is to integrate standard software project management practices, where possible, into the extreme programming process. Thus creating a management framework for extreme programming project management that gives the extreme programming managers the management activities and tools to utilize the extreme programming process within a wider range of commercial computing organizations, relationships, and development projects. -

Information Technology and Software Development
Course Title: Information Technology and Software Development NATIONAL OPEN UNIVERSITY OF NIGERIA SCHOOL OF SCIENCE AND TECHNOLOGY COURSE CODE: CIT 703 COURSE TITLE: Information Technology and Software Development National Open University of Nigeria, Victoria Island, Lagos Page 1 Course Title: Information Technology and Software Development Course Code Course Title Information Technology and Software Development Course Developer/Writer Eze, Festus Chux Department of Computer Science Ebonyi State University Abakaliki Course Editor Programme Leader Course Coordinator National Open University of Nigeria, Victoria Island, Lagos Page 2 Course Title: Information Technology and Software Development Introduction Information Technology and Software Development is a three credit load course for all the students offering Post Graduate Diploma (PGD) in Computer Science, Information Technology and other allied courses. Software Development is a major branch in computing and information Technology. A software development professional oversees the processes of software development, the management of software development project, the maintenance of the installed software in an organisation. For sometime the field has been dominated with what is the definitive process of software development. Furthermore there has been the running battle between professionals and managers on who should control a software development project. There is an attempt to classify it as any other project that an organisation handles hence anybody could manage it. Whereas others see it as a highly professional issue that requires high precision in design, management and implementation. However, software development is all involving. It involves the user (client) whose interest is paramount. The developing organisation and her professionals ( team)are of great importance. Therefore a successful exercise can only take place when all these variegated interests are harmonised. -

Empirical Studies of Agile Software Development: a Systematic Review
Available online at www.sciencedirect.com Information and Software Technology 50 (2008) 833–859 www.elsevier.com/locate/infsof Empirical studies of agile software development: A systematic review Tore Dyba˚ *, Torgeir Dingsøyr SINTEF ICT, S.P. Andersensv. 15B, NO-7465 Trondheim, Norway Received 22 October 2007; received in revised form 22 January 2008; accepted 24 January 2008 Available online 2 February 2008 Abstract Agile software development represents a major departure from traditional, plan-based approaches to software engineering. A system- atic review of empirical studies of agile software development up to and including 2005 was conducted. The search strategy identified 1996 studies, of which 36 were identified as empirical studies. The studies were grouped into four themes: introduction and adoption, human and social factors, perceptions on agile methods, and comparative studies. The review investigates what is currently known about the benefits and limitations of, and the strength of evidence for, agile methods. Implications for research and practice are presented. The main implication for research is a need for more and better empirical studies of agile software development within a common research agenda. For the industrial readership, the review provides a map of findings, according to topic, that can be compared for relevance to their own settings and situations. Ó 2008 Elsevier B.V. All rights reserved. Keywords: Empirical software engineering; Evidence-based software engineering; Systematic review; Research synthesis; Agile software development; XP; Extreme programming; Scrum Contents 1. Introduction . 834 2. Background – agile software development . 834 2.1. The field of agile software development. 834 2.2. Summary of previous reviews . -

Evaluating Effectiveness of Pair Programming As a Teaching Tool in Programming Courses
Information Systems Education Journal (ISEDJ) 12 (6) ISSN: 1545-679X November 2014 Evaluating Effectiveness of Pair Programming as a Teaching Tool in Programming Courses Silvana Faja [email protected] School of Accountancy and Computer Information Systems, University of Central Missouri, Warrensburg, Missouri, 64093, USA Abstract This study investigates the effectiveness of pair programming on student learning and satisfaction in introductory programming courses. Pair programming, used in the industry as a practice of an agile development method, can be adopted in classroom settings to encourage peer learning, increase students’ social skills, and enhance student achievement. This study explored students’ perceptions on effectiveness of pair programming and the influence of student’s level of experience with this activity and perceived partner involvement on effectiveness outcomes. Findings suggest that the more students are involved in this activity, the more they enjoy it and the more they learn by collaborating with their partners. When comparing different effectiveness measures, their perceived learning, quality of work, and enjoyment during pair programming was found to be at a higher level than increased productivity outcome. Keywords: Pair Programming, Teamwork, Collaborative Learning, Programming Course. 1. INTRODUCTION information systems courses. It discusses what was learned about the impact of this type of Software development is typically a process that collaborative activity on students’ attitudes and requires the coordinated efforts of the members learning. The following section provides a of one or more teams. As such, it is important review of existing research on pair that computer programming courses provide programming, collaborative learning and students not only with technical knowledge, but research questions and hypotheses. -

The Role of Customers in Extreme Programming Projects
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by ResearchArchive at Victoria University of Wellington THE ROLE OF CUSTOMERS IN EXTREME PROGRAMMING PROJECTS By Angela Michelle Martin A thesis submitted to the Victoria University of Wellington in fulfilment of the requirements for the degree of Doctor of Philosophy In Computer Science Victoria University of Wellington 2009i The Role of Customers in Extreme Programming Projects ABSTRACT eXtreme programming (XP) is one of a new breed of methods, collectively known as the agile methods, that are challenging conventional wisdom regarding systems development processes and practices. Practitioners specifically designed the agile methods to meet the business problems and challenges we face building software today. As such, these methods are receiving significant attention in practitioner literature. In order to operate effectively in the world of vague and changing requirements, XP moves the emphasis away from document-centric processes into practices that enable people. The Customer is the primary organisational facing role in eXtreme Programming (XP). The Customer's explicit responsibilities are to drive the project, providing project requirements (user stories) and quality control (acceptance testing). Unfortunately the customer must also shoulder a number of implicit responsibilities including liaison with external project stakeholders, especially project funders, clients, and end users, while maintaining the trust of both the development team and the wider business. This thesis presents a grounded theory of XP software development requirements elicitation, communication, and acceptance, which was guided by three major research questions. What is the experience of being an XP Customer? We found that teams agree that the on-site customer practice is a drastic improvement to the traditional document-centric approaches. -

Software Testing: a Changing Career
Software Testing: A Changing Career Sean Cunningham1, Jemil Gambo1, Aidan Lawless1, Declan Moore1, Murat Yilmaz2, Paul M. Clarke 1,3 [0000-0002-4487-627X], Rory V. O’Connor1,3 [0000-0001-9253-0313] 1 School of Computing, Dublin City University, Ireland {sean.cunningham29,jemil.gambo2,aidan.lawless8, declan.moore39}@mail.dcu.ie 2 Department of Computer Engineering, Cankaya University, Turkey [email protected] 3 Lero, the Irish Software Engineering Research Center {rory.oconnor,paul.m.clarke}@dcu.ie The software tester is an imperative component to quality software development. Their role has transformed over the last half a century and volumes of work have documented various approaches, methods, and skillsets to be used in that time. Software projects have gone from using monolithic architectures and heavy- weight methodologies, to service-oriented and lightweight. Testing has trans- formed from a sequential step performed by dedicated testers to a continuous activity carried out by various development professionals. Technological ad- vancements have pushed automation into routine test tasks permitting a change of focus for the tester. Management styles and methodologies have pushed de- velopment to be agile and lean, towards continuous integration and frequent re- lease. Regardless of these many important changes, the software tester’s role re- mains the verification and validation of software code. Keywords: software quality improvement, test drive development, continuous development, software development lifecycle 1 Introduction It is well documented that software development is a complex socio-technical activity [42], the process for which needs to be vigilantly maintained and evolved [43]. We furthermore find that roles within software development can have varying names [44], and that the very terminology adopted is perhaps the source of some fusion [45] [46]. -

Incorporating Aspects Into the Software Development Process in Context of Aspect- Oriented Programming Mark Alan Basch University of North Florida
UNF Digital Commons UNF Graduate Theses and Dissertations Student Scholarship 2002 Incorporating Aspects into the Software Development Process in Context of Aspect- Oriented Programming Mark Alan Basch University of North Florida Suggested Citation Basch, Mark Alan, "Incorporating Aspects into the Software Development Process in Context of Aspect-Oriented Programming" (2002). UNF Graduate Theses and Dissertations. 112. https://digitalcommons.unf.edu/etd/112 This Master's Thesis is brought to you for free and open access by the Student Scholarship at UNF Digital Commons. It has been accepted for inclusion in UNF Graduate Theses and Dissertations by an authorized administrator of UNF Digital Commons. For more information, please contact Digital Projects. © 2002 All Rights Reserved INCORPORATING ASPECTS INTO THE SOFTWARE DEVELOPMENT PROCESS IN THE CONTEXT OF ASPECT -ORIENTED PROGRAMMING by Mark Alan Basch A thesis submitted to the Department of Computer and Information Sciences in partial fulfillment of the requirements for the degree of Master of Science in Computer and Information Sciences UNIVERSITY OF NORTH FLORIDA DEPARTMENT OF COMPUTER AND INFORMATION SCIENCES December 2002 ACKNOWLEDGEMENT I wish to thank my thesis adviser, Dr. Arturo 1. Sanchez, for his assistance and patience in guiding me through the thesis process. 11 The thesis "Incorporating Aspects into the Software Development Process in the Context of Aspect-Oriented Programming" submitted by Mark Alan Basch in partial fulfillment of the requirements for the degree of Master of Science in Computer and Information Science has been Appro d b the ¥eSiS mmittee Date Signature Deleted c ez Thesis Adviser and Committee Chairperson Signature Deleted Robert F. Roggio Signature Deleted Neal S. -

On-Demand Collaboration in Programming
On-Demand Collaboration in Programming YAN CHEN, University of Michigan, Ann Arbor JASMINE JONES, Berea College, Berea STEVE ONEY, University of Michigan, Ann Arbor Many teams have shifted to online remote collaboration as a result of COVID-19, from professional development teams to programming classes to computing-related workspaces (e.g., makerspaces). This paper explores on-demand remote help seeking in programming, a type of collaboration that occurs when developers seek online support for their tasks as needed, and argues that a key challenge in scaling remote on-demand collaboration in programming is to facilitate effective context capturing and workforce coordination. Traditionally, this collaboration happens within teams and organizations where people are familiar with the context of the tasks. Recently, this collaboration has become ubiquitous due to the success of paid online crowdsourcing marketplaces (e.g., Upwork) and Q&A sites (e.g., Stack Overflow). We discuss prior work on on-demand collaboration in programming, analyze how the ideacanbe tested in physical computing as well, and examine existing and new challenges that should be further explored. CCS Concepts: • Computer systems organization ! Embedded systems; Redundancy; Robotics; • Networks ! Network relia- bility. Additional Key Words and Phrases: on-demand support; programming collaboration; crowdsourcing ACM Reference Format: Yan Chen, Jasmine Jones, and Steve Oney. 2018. On-Demand Collaboration in Programming. In New Future of Work ’20: ACM Symposium on Neural Gaze Detection, June 03–05, 2018, Woodstock, NY. ACM, New York, NY, USA,4 pages. https://doi.org/10.1145/1122445.1122456 1 INTRODUCTION Technology companies, schools, bootcamps, and makerspaces have shifted to prolonged online work as a result of COVID-19. -
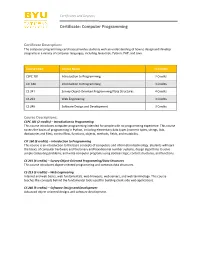
Certificate: Computer Programming
Certificates and Degrees Certificate: Computer Programming Certificate Description: The computer programming certificate provides students with an understanding of how to design and develop programs in a variety of computer languages, including Javascript, Python, PHP, and Java. Course Code Course Name 15 Credits CSPC 101 Introduction to Programming 2 Credits CIT 160 Introduction to Programming 3 Credits CS 241 Survey Object-Oriented Programming/Data Structures 4 Credits CS 213 Web Engineering 3 Credits CS 246 Software Design and Development 3 Credits Course Descriptions: CSPC 101 (2 credits) – Introduction to Programming This course introduces computer programming intended for people with no programming experience. This course covers the basics of programming in Python, including elementary data types (numeric types, strings, lists, dictionaries and files), control flow, functions, objects, methods, fields, and mutability. CIT 160 (3 credits) – Introduction to Programming This course is an introduction to the basic concepts of computers and information technology. Students will learn the basics of computer hardware and the binary and hexadecimal number systems, design algorithms to solve simple computing problems, and write computer programs using Boolean logic, control structures, and functions. CS 241 (4 credits) – Survey Object-Oriented Programming/Data Structures This course introduces object-oriented programming and common data structures. CS 213 (3 credits) – Web Engineering Internet and web basics, web fundamentals, web browsers, -

Architecting the Cloud, Part of the on Cloud Podcast
Architecting the Cloud May 2020 Architecting the Cloud, part of the On Cloud Podcast Mike Kavis, Managing Director, Deloitte Consulting LLP Title: Software testing in the age of cloud—new ideas and opportunities Description: Testing has always been a critical component of good software development practice. However, it’s often short-shrifted or siloed. As a result, app performance can suffer. In this episode of the podcast, Mike Kavis and guest, mabl’s Lisa Crispin, discuss the evolution of testing and how new development ideologies like DevOps have shed light on the importance of testing. Lisa also talks about how the cloud has transformed software testing by making it faster and automating much of the process, so that testers can focus on crucial human-centric testing such as security and accessibility testing. Lisa also touches on how cloud-native apps changes the testing process and gives her advice on how companies can learn more about testing and use that knowledge to improve their software delivery process. Duration: 00:23:48 Operator: This podcast is produced by Deloitte. The views and opinions expressed by podcast speakers and guests are solely their own and do not reflect the opinions of Deloitte. This podcast provides general information only and is not intended to constitute advice or services of any kind. For additional information about Deloitte, go to Deloitte.com/About. Welcome to Architecting the Cloud, part of the On Cloud Podcast, where we get real about Cloud Technology what works, what doesn't and why. Now here is your host Mike Kavis. Mike Kavis: Hey, everyone. -

Chapter 10 Team Structure
From "Succeeding with Agile: Software Development Using Scrum" by Mike Cohn Chapter 10 Team Structure It is perhaps a myth, but an enduring one, that people and their pets resemble one another. The same has been said of products and the teams that build them. The system being produced will tend to have a structure that mirrors the structure of the group that is producing it, whether or not this was intended. One should take advantage of this fact and then deliberately design the group structure so as to achieve the desired system structure. (Conway 1968; commonly referred to as “Conway’s Law”) If it is true that a product reflects the structure of the team that built it, then an important decision for any Scrum project is how to organize those individuals into teams. Factoring into this decision are considerations of team size, familiarity with the domain, the channels of communication, the technical design of the sys- tem, individual experience levels, the technologies involved, the newness of those technologies, where team members are located, competitive and market pressures, expectations about project schedule, and much more. In this chapter we look at the importance of two critical factors to be con- sidered when deciding how to structure Scrum teams: keeping teams small and orienting each team around the delivery of end-to-end user-visible functional- ity. We also look at the importance of having the right people on each team and not overloading those individuals by forcing them to split time among too many teams. We conclude the chapter with nine questions to ask when starting a multi- team project. -

A Literature Review on Agile Model Methodology in Software Development
Vol-3 Issue-6 2017 IJARIIE-ISSN(O)-2395-4396 A Literature Review on Agile Model Methodology in software Development Riya Shah* *Lecturer in Computer Engineering Department, S.B. Polytechnic, Savli, Gujarat, India. ABSTRACT “Change is necessary, growth is optional” said by a John C. Maxwell. And this Sentence exists very truly in software engineering. Agile process is an iterative approach in which customer satisfaction is at highest priority as the customer has direct involvement in evaluating the Agile Software Development is the result of that changing environmental demand and struggle of researchers to overcome traditional model of software development. Agile development is modern approach which deals with fast delivery of quality software and full association customers, so the requirement of customer can be satisfied and achieve the goals. This review paper includes different approaches of agile. Keywords: Agile software development; Extreme Programming; Scrum; Feature Driven Development; limitation; agile manifesto I.INTRODUCTION Agile is greater extent becoming the dictate developing method in the software industry. A lot of companies are opportunity close to agility in one way or another because of the need for fast delivery while at the same time dealing with fast changing requirements. Agile methodologies try to find an equilibrium point between no process and too much process, allowing it to survive in dynamic environments where requirements frequently change while Striving high quality software product [1] Agile encompasses different methodologies, including: Agile Software Development (ASD) [2], extreme Programming (XP)[3], Scrum, Feature Driven Development (FDD). II.AGILE METHODS The agile methods claim to place more emphasis on people, interaction, working software, customer collaboration, and change, rather than on processes, tools, contracts and plans [8].Many studies have been conducted on agile methods.