Introduction to Text Mining
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Infovox Ivox – User Manual
Infovox iVox – User Manual version 4 Published the 22nd of April 2014 Copyright © 2006-2014 Acapela Group. All rights reserved http://www.acapela-group.com Table of Contents INTRODUCTION .......................................................................................................... 1. WHAT IS INFOVOX IVOX? .................................................................................................. 1. HOW TO USE INFOVOX IVOX ............................................................................................. 1. TRIAL LICENSE AND PURCHASE INFORMATION ........................................................................ 2. SYSTEM REQUIREMENTS ................................................................................................... 2. LIMITATIONS OF INFOVOX IVOX .......................................................................................... 2. INSTALLATION/UNINSTALLATION ................................................................................ 3. HOW TO INSTALL INFOVOX IVOX ......................................................................................... 3. HOW TO UNINSTALL INFOVOX IVOX .................................................................................... 3. INFOVOX IVOX VOICE MANAGER ................................................................................. 4. THE VOICE MANAGER WINDOW ......................................................................................... 4. INSTALLING VOICES ........................................................................................................ -

Fontfont Opentype® User Guide
version 02 | September 2007 fontfont opentype® user guide sections a | Introduction to OpenType® b | Layout Features c | Language Support section a INTRODUCTION TO OPENTYPE® what is OpenType is a font file format developed jointly by Adobe and Microsoft. opentype? The two main benefits of the OpenType format are its cross-platform compatibility – you can work with the same font file on Mac, Windows or other computers – and its ability to support widely expanded charac- ter sets and layout features which provide rich linguistic support and advanced typographic control. OpenType fonts can be installed and used alongside PostScript Type 1 and TrueType fonts. Since these fonts rely on OpenType-specific tables, non-savvy applications on computers running operating systems prior to OS X and Windows 2000 will not be able to use them without intermedia- tion by system services like atm. There are now many FontFont typefaces available in OpenType format with many more to follow step by step. They are OpenType fonts with PostScript outlines, i. e. CFF (Compact Font Format) fonts. Each Open- Type FontFont is accompanied by a font-specific Info Guide listing all the layout features supported by this font. The font and Info Guide will be delivered as a .zip file which can be decompressed on any computer by OS built-in support or a recent version of StuffIt Expander or WinZip. This document covers the basics of the OpenType format. In Section two you will find a glossary of all OpenType layout features that may be sup- ported by FontFonts. Section C explains the language support and lists all code pages that may be available. -

RFC 9030: an Architecture for Ipv6 Over the Time-Slotted Channel
Stream: Internet Engineering Task Force (IETF) RFC: 9030 Category: Informational Published: May 2021 ISSN: 2070-1721 Author: P. Thubert, Ed. Cisco Systems RFC 9030 An Architecture for IPv6 over the Time-Slotted Channel Hopping Mode of IEEE 802.15.4 (6TiSCH) Abstract This document describes a network architecture that provides low-latency, low-jitter, and high- reliability packet delivery. It combines a high-speed powered backbone and subnetworks using IEEE 802.15.4 time-slotted channel hopping (TSCH) to meet the requirements of low-power wireless deterministic applications. Status of This Memo This document is not an Internet Standards Track specification; it is published for informational purposes. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Not all documents approved by the IESG are candidates for any level of Internet Standard; see Section 2 of RFC 7841. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at https://www.rfc-editor.org/info/rfc9030. Copyright Notice Copyright (c) 2021 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (https://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. -

Technical Report Belbo Oblique
Technical Report [629 Glyphs] Belbo Belbo Two Oblique Belbo Hair Oblique Belbo Thin Oblique Belbo ExtraLight Oblique Belbo Light Oblique Belbo SemiLight Oblique Belbo Oblique Belbo Book Oblique Belbo Medium Oblique Belbo SemiBold Oblique Belbo Bold Oblique Belbo ExtraBold Oblique Belbo Black Oblique Belbo - Designed by Ralph du Carrois © bBox Type GmbH [PDF generated 2019-02-11] OT-Features, Scripts & Languages Supported Script(s): Latin 51 languages and many more: All Case-Sensitive Contextual Denominator Discretionary Alternates Forms Alternates Ligatures Afrikaans, Albanian, Basque, Bosnian, Breton, Corsican, Croatian, Czech, Danish, Dutch, English, Estonian, Faroese, Finnish, French, Gaelic, Galician, German, Hungarian, Icelandic, Indonesian, Irish, Italian, Kurdish, Fractions Localized Numerator Ordinals Proportional Latvian, Leonese, Lithuanian, Luxembourgish, Malay, Malaysian, Manx, Forms Figures Norwegian, Occitan, Polish, Portuguese, Rhaeto-Romanic, Romanian, Scottish Gaelic, Serbian Latin, Slovak, Slovakian, Slovene, Slovenian, Sorbian (Lower), Sorbian (Upper), Spanish, Swahili, Swedish, Turkish, Turkmen, Scientific Standard Stylistic Stylistic Stylistic Inferiors Ligatures Alternates Set 1 Set 2 Walloon Stylistic Subscript Superscript Tabular Sets Figures Belbo - Designed by Ralph du Carrois © bBox Type GmbH [PDF generated 2019-02-11] Code Pages (this overview can happen to be incomplete) ## Mac OS ## ## MS Windows ## ## ISO 8859 ## Mac OS Roman MS Windows 1250 Central European ISO 8859-1 Latin 1 (Western) Mac OS Central European -

Mac OS 8 Revealed
•••••••••••••••••••••••••••••••••••••••••••• Mac OS 8 Revealed Tony Francis Addison-Wesley Developers Press Reading, Massachusetts • Menlo Park, California • New York Don Mills, Ontario • Harlow, England • Amsterdam Bonn • Sydney • Singapore • Tokyo • Madrid • San Juan Seoul • Milan • Mexico City • Taipei Apple, AppleScript, AppleTalk, Color LaserWriter, ColorSync, FireWire, LocalTalk, Macintosh, Mac, MacTCP, OpenDoc, Performa, PowerBook, PowerTalk, QuickTime, TrueType, and World- Script are trademarks of Apple Computer, Inc., registered in the United States and other countries. Apple Press, the Apple Press Signature, AOCE, Balloon Help, Cyberdog, Finder, Power Mac, and QuickDraw are trademarks of Apple Computer, Inc. Adobe™, Acrobat™, and PostScript™ are trademarks of Adobe Systems Incorporated or its sub- sidiaries and may be registered in certain jurisdictions. AIX® is a registered trademark of IBM Corp. and is being used under license. NuBus™ is a trademark of Texas Instruments. PowerPC™ is a trademark of International Business Machines Corporation, used under license therefrom. SOM, SOMobjects, and System Object Model are licensed trademarks of IBM Corporation. UNIX® is a registered trademark of Novell, Inc. in the United States and other countries, licensed exclusively through X/Open Company, Ltd. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters or all capital letters. The author and publisher have taken care in the preparation of this book, but make no express or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. -

IDOL Keyview Viewing SDK 12.7 Programming Guide
KeyView Software Version 12.7 Viewing SDK Programming Guide Document Release Date: October 2020 Software Release Date: October 2020 Viewing SDK Programming Guide Legal notices Copyright notice © Copyright 2016-2020 Micro Focus or one of its affiliates. The only warranties for products and services of Micro Focus and its affiliates and licensors (“Micro Focus”) are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. Micro Focus shall not be liable for technical or editorial errors or omissions contained herein. The information contained herein is subject to change without notice. Documentation updates The title page of this document contains the following identifying information: l Software Version number, which indicates the software version. l Document Release Date, which changes each time the document is updated. l Software Release Date, which indicates the release date of this version of the software. To check for updated documentation, visit https://www.microfocus.com/support-and-services/documentation/. Support Visit the MySupport portal to access contact information and details about the products, services, and support that Micro Focus offers. This portal also provides customer self-solve capabilities. It gives you a fast and efficient way to access interactive technical support tools needed to manage your business. As a valued support customer, you can benefit by using the MySupport portal to: l Search for knowledge documents of interest l Access product documentation l View software vulnerability alerts l Enter into discussions with other software customers l Download software patches l Manage software licenses, downloads, and support contracts l Submit and track service requests l Contact customer support l View information about all services that Support offers Many areas of the portal require you to sign in. -

The Confproc Package∗
The confproc package∗ Vincent Verfaille† Printed on August 1, 2011 Abstract The confproc package provided a LATEX 2e document-class together with various tools (Perl and Unix/bash scripts) for building conference proceedings, or concatenating any set of PDFs with a table of contents, index and bookmarks. The LaTeX2e class derives from LATEX 2e scripts written for the DAFx-06 conference proceedings. It is mainly based on the ’pdfpages’ package for PDF papers including, and the ’hyperref’ package for creating proper links, bookmarks and general bibliography back references. It also uses many other packages for fine tuning of table of contents, bibliography and index of authors. Current version 0.8 is the previous 0.7 major update with key-value option management, that has now been tested with TeXLive 2011. The added value of this class is in the time it saves for you to quickly design conference proceedings. See readme.txt for a short overview and additional (legal) information, and exampleN.tex and corresponding files and scripts for an example of use. Contents 1 Introduction4 1.1 Short history.......................................4 1.2 Other packages or softwares..............................4 1.3 A solution: the confproc package...........................5 1.4 Version history.....................................8 1.5 To do / bugs....................................... 10 1.6 Thanks.......................................... 10 2 Installation 12 2.1 Steps summary..................................... 12 2.2 Packages and compiler................................. 12 2.3 Installation steps.................................... 14 3 Example 1 (example1empty.tex): A short introduction to confproc 16 3.1 Preamble........................................ 16 3.2 Front matter: cover page, index and table of contents................. 17 3.3 Main matter: the papers................................ -

Typetool 3 for Windows User Manual
TypeTool 3 basic font editor for fast and easy font creation, conversion and modification User’s manual for windows Copyright © 1992–2013 by Fontlab Ltd. All rights reserved. Editors: Sasha Petrov, Adam Twardoch, Ted Harrison, Yuri Yarmola Cover illustration: Paweł Jońca, pejot.com No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written consent of the publisher. Any software referred to herein is furnished under license and may only be used or copied in accordance with the terms of such license. Fontographer, FontLab, FontLab logo, ScanFont, TypeTool, SigMaker, AsiaFont Studio, FontAudit and VectorPaint are either registered trademarks or trademarks of Fontlab, Ltd. in the United States and/or other countries. Apple, the Apple Logo, Mac, Mac OS, Macintosh and TrueType are trademarks of Apple Computer, Inc., registered in the United States and other countries. Adobe, PostScript, PostScript 3, Type Manager, FreeHand, Illustrator and OpenType logo are trademarks of Adobe Systems Incorporated that may be registered in certain jurisdictions. Windows, Windows 95, Windows 98, Windows XP, Windows NT, Windows Vista and OpenType are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. IBM is a registered trademark of International Business Machines Corporation. Other brand or product names are the trademarks or registered trademarks of their respective holders. THIS PUBLICATION AND THE INFORMATION HEREIN IS FURNISHED AS IS, IS SUBJECT TO CHANGE WITHOUT NOTICE, AND SHOULD NOT BE CONSTRUED AS A COMMITMENT BY FONTLAB LTD. -

Text Encoding
CS101 – Fundamentals of Computer and Information Sciences – LIU 1 of 8 Figure 1: @pigworker on Twitter Text encoding We have covered how to represent numbers in binary; in this section we’ll explore representations of text as bits. By ‘text’,we mean alphabets and other writing systems — used everywhere from status updates and text messages to email and digital books. Beginnings To start with, we can propose a way of mapping letters and other characters (punc- tuation, space, etc.) to numbers. For example, let A be represented as the number 0, B as 1, C as 2, and so on. There are 26 letters in the English alphabet, so Z is 25, and we’d need a total of 5 bits. (2⁵ is 32, so we’d even have a few numbers left over for punctuation.) Exercise: using the scheme outlined above, decode the word represented by the bits 00010 00000 10011 If our text messages need to distinguish between upper- and lower-case letters, we’ll need more than 5 bits. Upper-case A–Z is 26 characters, lower-case a–z is another 26, so that’s a total of 52. 2⁶ is 64, so 6 bits would cover it and again have a few available for punctuation. But what about including numbers in our text? If we want to send the text message “amazon has a 20% discount on textbooks,”we can’t really represent that ‘20’ as 10100 in binary, because that would conflict with the representation of the letter ‘U’. Instead, we need to add space for the standard ten numerals as characters. -
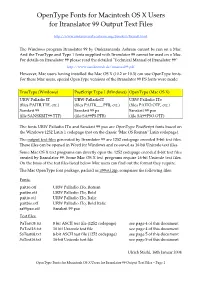
Opentype Fonts for Macintosh OS X Users for Itranslator 99 Output Text Files
OpenType Fonts for Macintosh OS X Users for Itranslator 99 Output Text Files http://www.omkarananda-ashram.org/Sanskrit/Itranslt.html The Windows program Itranslator 99 by Omkarananda Ashram cannot be run on a Mac. And the TrueType and Type 1 fonts supplied with Itranslator 99 cannot be used on a Mac. For details on Itranslator 99 please read the detailed "Technical Manual of Itranslator 99": http://www.sanskritweb.de/itmanual99.pdf However, Mac users having installed the Mac OS X (10.2 or 10.3) can use OpenType fonts. For these Mac users, special OpenType versions of the Itranslator 99 PS fonts were made: TrueType (Windows) PostScript Type 1 (Windows) OpenType (Mac OS X) URW Palladio IT URW-PalladioIT URW Palladio ITo (files PAITR.TTF, etc.) (files PAITR___.PFB, etc.) (files PAITO.OTF, etc.) Sanskrit 99 Sanskrit 99 ps Sanskrit 99 pso (file SANSKRIT99.TTF) (file SA99PS.PFB) (file SA99PSO.OTF) The fonts URW Palladio ITo and Sanskrit 99 pso are OpenType PostScript fonts based on the Windows 1252 Latin 1 codepage (not on the classic "Mac OS Roman" Latin codepage). The output text files generated by Itranslator 99 are 1252 codepage encoded 8-bit text files. These files can be opened in Word for Windows and re-saved as 16-bit Unicode text files. Some Mac OS X text programs can directly open the 1252 codepage encoded 8-bit text files created by Itranslator 99. Some Mac OS X text programs require 16-bit Unicode text files. On the basis of the test files listed below Mac users can find out the format they require. -

Survey on RPL Enhancements: a Focus on Topology, Security and Mobility Patrick Olivier Kamgueu, Emmanuel Nataf, Thomas Djotio Ndie
Survey on RPL enhancements: a focus on topology, security and mobility Patrick Olivier Kamgueu, Emmanuel Nataf, Thomas Djotio Ndie To cite this version: Patrick Olivier Kamgueu, Emmanuel Nataf, Thomas Djotio Ndie. Survey on RPL enhancements: a focus on topology, security and mobility. Computer Communications, Elsevier, 2018, pp.1-17. 10.1016/j.comcom.2018.02.011. hal-01713247 HAL Id: hal-01713247 https://hal.inria.fr/hal-01713247 Submitted on 20 Feb 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Survey on RPL enhancements: a focus on topology, security and mobility Patrick Olivier Kamgueua,b,∗, Emmanuel Natafa, Thomas Djotio Ndieb aUniversity of Lorraine, UMR 7503, Nancy { France INRIA Grand Est { MADYNES Team bUniversity of Yaounde 1, Cameroon LIRIMA, IoT4D Team Abstract A few years ago, the IPv6 Routing Protocol for Low-power and Lossy Networks (RPL) was proposed by IETF as the routing standard designed for classes of networks in which both nodes and their interconnects are constrained. Since then, great attention has been paid by the scientific and industrial communities for the protocol evaluation and improvement. Indeed, depending on applications scenarios, constraints related to the target environments or other requirements, many adaptations and improvements can be made.