Towards High-Order Methods for Stochastic Differential Equations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Regularity of Solutions and Parameter Estimation for Spde’S with Space-Time White Noise
REGULARITY OF SOLUTIONS AND PARAMETER ESTIMATION FOR SPDE’S WITH SPACE-TIME WHITE NOISE by Igor Cialenco A Dissertation Presented to the FACULTY OF THE GRADUATE SCHOOL UNIVERSITY OF SOUTHERN CALIFORNIA In Partial Fulfillment of the Requirements for the Degree DOCTOR OF PHILOSOPHY (APPLIED MATHEMATICS) May 2007 Copyright 2007 Igor Cialenco Dedication To my wife Angela, and my parents. ii Acknowledgements I would like to acknowledge my academic adviser Prof. Sergey V. Lototsky who introduced me into the Theory of Stochastic Partial Differential Equations, suggested the interesting topics of research and guided me through it. I also wish to thank the members of my committee - Prof. Remigijus Mikulevicius and Prof. Aris Protopapadakis, for their help and support. Last but certainly not least, I want to thank my wife Angela, and my family for their support both during the thesis and before it. iii Table of Contents Dedication ii Acknowledgements iii List of Tables v List of Figures vi Abstract vii Chapter 1: Introduction 1 1.1 Sobolev spaces . 1 1.2 Diffusion processes and absolute continuity of their measures . 4 1.3 Stochastic partial differential equations and their applications . 7 1.4 Ito’sˆ formula in Hilbert space . 14 1.5 Existence and uniqueness of solution . 18 Chapter 2: Regularity of solution 23 2.1 Introduction . 23 2.2 Equations with additive noise . 29 2.2.1 Existence and uniqueness . 29 2.2.2 Regularity in space . 33 2.2.3 Regularity in time . 38 2.3 Equations with multiplicative noise . 41 2.3.1 Existence and uniqueness . 41 2.3.2 Regularity in space and time . -

Stochastic Pdes and Markov Random Fields with Ecological Applications
Intro SPDE GMRF Examples Boundaries Excursions References Stochastic PDEs and Markov random fields with ecological applications Finn Lindgren Spatially-varying Stochastic Differential Equations with Applications to the Biological Sciences OSU, Columbus, Ohio, 2015 Finn Lindgren - [email protected] Stochastic PDEs and Markov random fields with ecological applications Intro SPDE GMRF Examples Boundaries Excursions References “Big” data Z(Dtrn) 20 15 10 5 Illustration: Synthetic data mimicking satellite based CO2 measurements. Iregular data locations, uneven coverage, features on different scales. Finn Lindgren - [email protected] Stochastic PDEs and Markov random fields with ecological applications Intro SPDE GMRF Examples Boundaries Excursions References Sparse spatial coverage of temperature measurements raw data (y) 200409 kriged (eta+zed) etazed field 20 15 15 10 10 10 5 5 lat lat lat 0 0 0 −10 −5 −5 44 46 48 50 52 44 46 48 50 52 44 46 48 50 52 −20 2 4 6 8 10 14 2 4 6 8 10 14 2 4 6 8 10 14 lon lon lon residual (y − (eta+zed)) climate (eta) eta field 20 2 15 18 10 16 1 14 5 lat 0 lat lat 12 0 10 −1 8 −5 44 46 48 50 52 6 −2 44 46 48 50 52 44 46 48 50 52 2 4 6 8 10 14 2 4 6 8 10 14 2 4 6 8 10 14 lon lon lon Regional observations: ≈ 20,000,000 from daily timeseries over 160 years Finn Lindgren - [email protected] Stochastic PDEs and Markov random fields with ecological applications Intro SPDE GMRF Examples Boundaries Excursions References Spatio-temporal modelling framework Spatial statistics framework ◮ Spatial domain D, or space-time domain D × T, T ⊂ R. -

Subband Particle Filtering for Speech Enhancement
14th European Signal Processing Conference (EUSIPCO 2006), Florence, Italy, September 4-8, 2006, copyright by EURASIP SUBBAND PARTICLE FILTERING FOR SPEECH ENHANCEMENT Ying Deng and V. John Mathews Dept. of Electrical and Computer Eng., University of Utah 50 S. Central Campus Dr., Rm. 3280 MEB, Salt Lake City, UT 84112, USA phone: + (1)(801) 581-6941, fax: + (1)(801) 581-5281, email: [email protected], [email protected] ABSTRACT as those discussed in [16, 17] and also in this paper, the integrations Particle filters have recently been applied to speech enhancement used to compute the filtering distribution and the integrations em- when the input speech signal is modeled as a time-varying autore- ployed to estimate the clean speech signal and model parameters do gressive process with stochastically evolving parameters. This type not have closed-form analytical solutions. Approximation methods of modeling results in a nonlinear and conditionally Gaussian state- have to be employed for these computations. The approximation space system that is not amenable to analytical solutions. Prior work methods developed so far can be grouped into three classes: (1) an- in this area involved signal processing in the fullband domain and alytic approximations such as the Gaussian sum filter [19] and the assumed white Gaussian noise with known variance. This paper extended Kalman filter [20], (2) numerical approximations which extends such ideas to subband domain particle filters and colored make the continuous integration variable discrete and then replace noise. Experimental results indicate that the subband particle filter each integral by a summation [21], and (3) sampling approaches achieves higher segmental SNR than the fullband algorithm and is such as the unscented Kalman filter [22] which uses a small num- effective in dealing with colored noise without increasing the com- ber of deterministically chosen samples and the particle filter [23] putational complexity. -

Lecture 6: Particle Filtering, Other Approximations, and Continuous-Time Models
Lecture 6: Particle Filtering, Other Approximations, and Continuous-Time Models Simo Särkkä Department of Biomedical Engineering and Computational Science Aalto University March 10, 2011 Simo Särkkä Lecture 6: Particle Filtering and Other Approximations Contents 1 Particle Filtering 2 Particle Filtering Properties 3 Further Filtering Algorithms 4 Continuous-Discrete-Time EKF 5 General Continuous-Discrete-Time Filtering 6 Continuous-Time Filtering 7 Linear Stochastic Differential Equations 8 What is Beyond This? 9 Summary Simo Särkkä Lecture 6: Particle Filtering and Other Approximations Particle Filtering: Overview [1/3] Demo: Kalman vs. Particle Filtering: Kalman filter animation Particle filter animation Simo Särkkä Lecture 6: Particle Filtering and Other Approximations Particle Filtering: Overview [2/3] =⇒ The idea is to form a weighted particle presentation (x(i), w (i)) of the posterior distribution: p(x) ≈ w (i) δ(x − x(i)). Xi Particle filtering = Sequential importance sampling, with additional resampling step. Bootstrap filter (also called Condensation) is the simplest particle filter. Simo Särkkä Lecture 6: Particle Filtering and Other Approximations Particle Filtering: Overview [3/3] The efficiency of particle filter is determined by the selection of the importance distribution. The importance distribution can be formed by using e.g. EKF or UKF. Sometimes the optimal importance distribution can be used, and it minimizes the variance of the weights. Rao-Blackwellization: Some components of the model are marginalized in closed form ⇒ hybrid particle/Kalman filter. Simo Särkkä Lecture 6: Particle Filtering and Other Approximations Bootstrap Filter: Principle State density representation is set of samples (i) {xk : i = 1,..., N}. Bootstrap filter performs optimal filtering update and prediction steps using Monte Carlo. -

Fundamental Concepts of Time-Series Econometrics
CHAPTER 1 Fundamental Concepts of Time-Series Econometrics Many of the principles and properties that we studied in cross-section econometrics carry over when our data are collected over time. However, time-series data present important challenges that are not present with cross sections and that warrant detailed attention. Random variables that are measured over time are often called “time series.” We define the simplest kind of time series, “white noise,” then we discuss how variables with more complex properties can be derived from an underlying white-noise variable. After studying basic kinds of time-series variables and the rules, or “time-series processes,” that relate them to a white-noise variable, we then make the critical distinction between stationary and non- stationary time-series processes. 1.1 Time Series and White Noise 1.1.1 Time-series processes A time series is a sequence of observations on a variable taken at discrete intervals in 1 time. We index the time periods as 1, 2, …, T and denote the set of observations as ( yy12, , ..., yT ) . We often think of these observations as being a finite sample from a time-series stochastic pro- cess that began infinitely far back in time and will continue into the indefinite future: pre-sample sample post-sample ...,y−−−3 , y 2 , y 1 , yyy 0 , 12 , , ..., yT− 1 , y TT , y + 1 , y T + 2 , ... Each element of the time series is treated as a random variable with a probability distri- bution. As with the cross-section variables of our earlier analysis, we assume that the distri- butions of the individual elements of the series have parameters in common. -

Markov Random Fields and Stochastic Image Models
Markov Random Fields and Stochastic Image Models Charles A. Bouman School of Electrical and Computer Engineering Purdue University Phone: (317) 494-0340 Fax: (317) 494-3358 email [email protected] Available from: http://dynamo.ecn.purdue.edu/»bouman/ Tutorial Presented at: 1995 IEEE International Conference on Image Processing 23-26 October 1995 Washington, D.C. Special thanks to: Ken Sauer Suhail Saquib Department of Electrical School of Electrical and Computer Engineering Engineering University of Notre Dame Purdue University 1 Overview of Topics 1. Introduction (b) Non-Gaussian MRF's 2. The Bayesian Approach i. Quadratic functions ii. Non-Convex functions 3. Discrete Models iii. Continuous MAP estimation (a) Markov Chains iv. Convex functions (b) Markov Random Fields (MRF) (c) Parameter Estimation (c) Simulation i. Estimation of σ (d) Parameter estimation ii. Estimation of T and p parameters 4. Application of MRF's to Segmentation 6. Application to Tomography (a) The Model (a) Tomographic system and data models (b) Bayesian Estimation (b) MAP Optimization (c) MAP Optimization (c) Parameter estimation (d) Parameter Estimation 7. Multiscale Stochastic Models (e) Other Approaches (a) Continuous models 5. Continuous Models (b) Discrete models (a) Gaussian Random Process Models 8. High Level Image Models i. Autoregressive (AR) models ii. Simultaneous AR (SAR) models iii. Gaussian MRF's iv. Generalization to 2-D 2 References in Statistical Image Modeling 1. Overview references [100, 89, 50, 54, 162, 4, 44] 4. Simulation and Stochastic Optimization Methods [118, 80, 129, 100, 68, 141, 61, 76, 62, 63] 2. Type of Random Field Model 5. Computational Methods used with MRF Models (a) Discrete Models i. -

Lecture 1: Stationary Time Series∗
Lecture 1: Stationary Time Series∗ 1 Introduction If a random variable X is indexed to time, usually denoted by t, the observations {Xt, t ∈ T} is called a time series, where T is a time index set (for example, T = Z, the integer set). Time series data are very common in empirical economic studies. Figure 1 plots some frequently used variables. The upper left figure plots the quarterly GDP from 1947 to 2001; the upper right figure plots the the residuals after linear-detrending the logarithm of GDP; the lower left figure plots the monthly S&P 500 index data from 1990 to 2001; and the lower right figure plots the log difference of the monthly S&P. As you could see, these four series display quite different patterns over time. Investigating and modeling these different patterns is an important part of this course. In this course, you will find that many of the techniques (estimation methods, inference proce- dures, etc) you have learned in your general econometrics course are still applicable in time series analysis. However, there are something special of time series data compared to cross sectional data. For example, when working with cross-sectional data, it usually makes sense to assume that the observations are independent from each other, however, time series data are very likely to display some degree of dependence over time. More importantly, for time series data, we could observe only one history of the realizations of this variable. For example, suppose you obtain a series of US weekly stock index data for the last 50 years. -

White Noise Analysis of Neural Networks
Published as a conference paper at ICLR 2020 WHITE NOISE ANALYSIS OF NEURAL NETWORKS Ali Borji & Sikun Liny∗ yUniversity of California, Santa Barbara, CA [email protected], [email protected] ABSTRACT A white noise analysis of modern deep neural networks is presented to unveil their biases at the whole network level or the single neuron level. Our analysis is based on two popular and related methods in psychophysics and neurophysiology namely classification images and spike triggered analysis. These methods have been widely used to understand the underlying mechanisms of sensory systems in humans and monkeys. We leverage them to investigate the inherent biases of deep neural networks and to obtain a first-order approximation of their function- ality. We emphasize on CNNs since they are currently the state of the art meth- ods in computer vision and are a decent model of human visual processing. In addition, we study multi-layer perceptrons, logistic regression, and recurrent neu- ral networks. Experiments over four classic datasets, MNIST, Fashion-MNIST, CIFAR-10, and ImageNet, show that the computed bias maps resemble the target classes and when used for classification lead to an over two-fold performance than the chance level. Further, we show that classification images can be used to attack a black-box classifier and to detect adversarial patch attacks. Finally, we utilize spike triggered averaging to derive the filters of CNNs and explore how the be- havior of a network changes when neurons in different layers are modulated. Our effort illustrates a successful example of borrowing from neurosciences to study ANNs and highlights the importance of cross-fertilization and synergy across ma- chine learning, deep learning, and computational neuroscience1. -

Normalizing Flow Based Hidden Markov Models for Classification Of
1 Normalizing Flow based Hidden Markov Models for Classification of Speech Phones with Explainability Anubhab Ghosh, Antoine Honore,´ Dong Liu, Gustav Eje Henter, Saikat Chatterjee Digital Futures, and School of Electrical Engg. and Computer Sc., KTH Royal Institute of Technology, Sweden [email protected], [email protected], [email protected], [email protected], [email protected] Abstract—In pursuit of explainability, we develop genera- data point then they are suitable for ML classification. For tive models for sequential data. The proposed models provide example, a Gaussian mixture model (GMM) is a suitable state-of-the-art classification results and robust performance for generative model widely used for ML classification. Param- speech phone classification. We combine modern neural networks (normalizing flows) and traditional generative models (hidden eters of a GMM are learned from data using time-tested Markov models - HMMs). Normalizing flow-based mixture learning principles, such as expectation-maximization (EM). models (NMMs) are used to model the conditional probability GMMs have been used in numerous applications with robust distribution given the hidden state in the HMMs. Model param- performance where data is corrupted. Our opinion is that eters are learned through judicious combinations of time-tested generative models with explainable data generation process, Bayesian learning methods and contemporary neural network learning methods. We mainly combine expectation-maximization use of time-tested learning principles, and scope of robust (EM) and mini-batch gradient descent. The proposed generative performance for many potential applications provide a path models can compute likelihood of a data and hence directly suit- towards explainable machine learning and trust. -

Minimax Particle Filtering for Tracking a Highly Maneuvering Target
Received: 26 June 2018 Revised: 31 August 2019 Accepted: 20 September 2019 DOI: 10.1002/rnc.4785 RESEARCH ARTICLE Minimax particle filtering for tracking a highly maneuvering target Jaechan Lim1,2 Hun-Seok Kim1 Hyung-Min Park2 1Department of Electrical Engineering and Computer Science, University of Summary Michigan, Ann Arbor, Michigan In this paper, we propose a new framework of particle filtering that adopts 2 Department of Electronic Engineering, the minimax strategy. In the approach, we minimize a maximized risk, and Sogang University, Seoul, South Korea the process of the risk maximization is reflected when computing the weights Correspondence of particles. This scheme results in the significantly reduced variance of the Hyung-Min Park, Department of Electronic Engineering, Sogang weights of particles that enables the robustness against the degeneracy problem, University, Seoul 04107, South Korea. and we can obtain improved quality of particles. The proposed approach is Email: [email protected] robust against environmentally adverse scenarios, particularly when the state of Funding information a target is highly maneuvering. Furthermore, we can reduce the computational Basic Science Research Program, complexity by avoiding the computation of a complex joint probability density Grant/Award Number: NRF-2016R1D1A1A09918304 and function. We investigate the new method by comparing its performance to that NRF-2019R1I1A1A01058976 of standard particle filtering and verify its effectiveness through experiments. The employed strategy can be adopted for any other variants of particle filtering to enhance tracking performance. KEYWORDS bearing, minimax, particle filtering, range, risk, target tracking 1 INTRODUCTION Conventional adaptive filters such as the adaptive Kalman filter can be applied to maneuvering target tracking.1 In this adaptive filter, two additional schemes exist beyond the standard Kalman filtering, ie, maneuvering detection and adjust- ing the state noise variance. -

Means • Recall: We Model a Time Series As a Collection of Random Variables: X1,X2,X3,..., Or More Generally {Xt,T ∈T}
Means • Recall: We model a time series as a collection of random variables: x1; x2; x3;::: , or more generally fxt; t 2 T g. • The mean function is Z 1 µx;t = E(xt) = xft(x)dx 1 where the expectation is for the given t, across all the possible values of xt. Here ft(·) is the pdf of xt. 1 Example: Moving Average • wt is white noise, with E (wt) = 0 for all t • the moving average is 1 v = w + w + w t 3 t−1 t t+1 • so 1 h i µ = E (v ) = E w + E (w ) + E w = 0: v;t t 3 t−1 t t+1 2 Moving Average Model with Mean Function 1 0 v −1 −2 0 100 200 300 400 500 Time 3 Example: Random Walk with Drift • The random walk with drift δ is t X xt = δt + wj j=1 • so t X µx;t = E (xt) = δt + E wj = δt; j=1 a straight line with slope δ. 4 Random Walk Model with Mean Function 80 60 x 40 20 0 0 100 200 300 400 500 Time 5 Example: Signal Plus Noise • The \signal plus noise" model is xt = 2 cos(2πt=50 + 0:6π) + wt • so µx;t = E (xt) = 2 cos(2πt=50 + 0:6π) + E (wt) = 2 cos(2πt=50 + 0:6π); the (cosine wave) signal. 6 Signal-Plus-Noise Model with Mean Function 4 2 x 0 −2 −4 0 100 200 300 400 500 Time 7 Covariances • The autocovariance function is, for all s and t, h i γx(s; t) = E (xs − µx;s) xt − µx;t : • Symmetry: γx(s; t) = γx(t; s). -
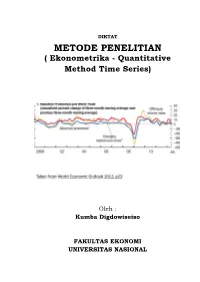
METODE PENELITIAN ( Ekonometrika - Quantitative Method Time Series)
DIKTAT METODE PENELITIAN ( Ekonometrika - Quantitative Method Time Series) Oleh : Kumba Digdowiseiso FAKULTAS EKONOMI UNIVERSITAS NASIONAL Quantitative Method Analysis: Time Series (1) Kumba Digdowiseiso Quantitative Method Analysis: Time Series (2) Kumba Digdowiseiso Stationarity • OLS estimates for time series models will only be BLUE if, in addition to the usual OLS assumptions, the time series are stationary. • A stochastic time-series is said to be weakly stationary if its mean and variance are constant over time and the value of the covariance between the two time periods depends only on the lag between the two time periods. • i.e. if Yt is a stochastic time series, it is weakly stationary if it has the following statistical properties: Mean: E(Yt )= µ Variance: 2 2 var(Yt )= E(Y t − µ) =σ Covariance: γ k = E[(Yt − µ)(Yt+k − µ)] Where γk , the covariance between 2 variables k time periods apart, only depends on k and not t. • A stationary time series exhibits mean reversion • Do economic time series usually exhibit these properties? Recall the examples of time series that were discussed in the last session 250 200 index 150 price 100 50 IMF commodity commodity IMF 0 Data source: IMF IFS 2011 Monthly interest rates in South Africa 14 12 10 8 % 6 4 2 0 Money market interest rate Government bond yield Data source: IMF IFS 2011 Consumer and producer price indices and broad money suuply in South Africa 160 3,E+06 140 2,E+06 120 100 2,E+06 80 (millions) 60 1,E+06 40 SA Rand 5,E+05 20 0 0,E+00 PPI CPI Broad money supply (right axis) Data source: IMF IFS 2011 ut ~ NIID(0,σ ) Gaussian White Noise 2 4 2 1 2 0 wn1 wn3 0 -1 -2 -2 -3 0 20 40 60 80 100 0 20 40 60 80 100 time time White Noise Process – A stochastic stationary time series • The white noise process can be seen as the basic building block for more complex stochastic DGPs (more next session) – The residuals from all time series regressions should be white noise • This is a purely random stochastic process since it has zero mean.