Watchdog for Intellij: an IDE Plugin to Analyze Software Testing Practices
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Said GUERRAB
Said GUERRAB CONTACT 404-5100 Boulevard Pie IX E-mail: [email protected] H1X 2B6 Website: www.sguerrab-developper.com Montreal (QC) Phone: 438-935-8707 SUMMARY 05 years of experience designing and developing websites. Bilingual French-English. Implementation of numerous IT projects within the school. Design and implementation of websites in PHP, MySQL, JSP, HTML5, CSS3, Sass, Less, Stylus, and JavaScript, Bootstrap, D3.js, MVC framworks (PHP Laravel), Photoshop... Web project management (specifications, deadlines, risks management...). Audio editing, video editing, and graphic design. SEO for websites Autonomous, organized, have a team spirit, available, highly motivated, adaptable to new situations, can work under pressure. TECHNICAL Operating Systems: Windows, Linux , Mac OS X SKILLS Programming Languages: Java, JSP, Ruby, Cobol, VB.NET, C++, PHP, HTML/CSS, JavaScript Markup Languages:JSON, YAML, XML CSS Preprocessors: Sass CSS, Stylus CSS, Less CSS Editors & IDEs: Eclipse, PHPStorm, NetBeans, RubyMine, Sublime Text… Version Control Systems: GIT, Github, Bitbucket, SVN Frameworks & libraries: Laravel, JQuery, Bootstrap, D3.js... CMS: Drupal, Joomla, WordPress Server management: Apache, Tomcat, Glassfish, CPanel, DNS Database: Oracle SQL, PL/SQL, SQL Server, MySQL, Access. Office Applications:Excel, Word, Powerpoint and LibreOffice suite Other software: Microsoft Project, Microsoft Visio, Oracle Forms, Oracle Reports Graphism: Photoshop, The Gimp, Illustrator, Inkscape et InDesign. Maintening:Software (installation and updating). PROFESSIONAL Identify the needs of clients. SKILLS Analyze specifications of the website. Establish a site plan with the design of each page. Choosing tools for the development of the site . Coordinate the collection and the organization of information to include on the site. Collaborate in the definition of the architecture of the site and the choice of navigation scenarios. -

Single-Window Integrated Development Environment
Московский государственный университет имени М.В. Ломоносова Факультет вычислительной математики и кибернетики Кафедра автоматизации систем вычислительных комплексов Лаборатория вычислительных комплексов Курсовая работа на тему: «Однооконный интерфейс среды разработки программ» Студент 422 группы Ручкин И.Д. Научный руководитель Прус В.В. Москва 2010 Аннотация В данной работе описывается подход к решению проблем сложности графического интерфейса пользователя для интегрированных сред разработки программ, заключающийся в создании однооконного интерфейса. Этот подход предполагает удаление инструментальных окон – дополнительных окон среды разработки – и перенесение их функциональности в окно текстового редактора. Создание однооконного интерфейса включает обзор существующих интегрированных сред разработки программ, построение проекта однооконного интерфейса и частичную реализацию построенного проекта. Обзор сред разработки описывает организацию инструментальных окон и сами инструментальные окна популярных сред разработки программ. Результатом обзора является модель инструментальных окон, описывающая классы инструментальных окон, обобщенные инструментальные окна и их функциональность. За счет этой модели дальнейшие рассуждения абстрагируются от конкретных сред разработки программ. Далее в рамках полученной модели инструментальных окон создается проект однооконного интерфейса. Для этого рассматривается каждое обобщенное инструментальное окно и предлагается способ замены его функциональности. Предложенный проект однооконного интерфейса частично -

Overall Features Performance Price
Scan this code for more info. To download a barcode app, SMS <f2k> to 56677 from a mobile phone with Internet access and camera. SMARTPHONE JOLLA Experience a different way of operating a smartphone without any home or back button — Ashok Pandey to operate, but those who are upgrading to taste the new flavor may struggle a little. At the start, it asks to setup your account and then, it guides you how to use the phone. The first screen reminded us of BB 10 OS. Since there is no Home button, you’ll have to learn a lot of gestures, shortcuts and cues. Sailfish OS sup- ports Android apps and games, and most apps run smoothly. Although there is no issue with Android apps and games on Jolla, but with third party apps like facebook you will find some functionality and notification differences, as Price: `15,490 they are not integrated with the system. Feels good and runs smooth: Jolla has 4.5-inch qHD (960x450p) display, though we were expecting a 720p display, yet screen has good viewing angles. The display is average to use in direct sunlight. It is backed by a 1.4GHz dual-core processor, 1GB RAM and 16 GB internal memory (13.7 GB available to the user) expandable via microSD card. Navigating the phone was quite easy, and launching and switching between apps was smooth. It is equipped with 8 MP rear camera with LED flash that captures quality images in day- light with decent color reproduction. The cam- here are many smartphone manufacturers era comes with several settings for the flash, and OS platforms available in the market. -
Fira Code: Monospaced Font with Programming Ligatures
Personal Open source Business Explore Pricing Blog Support This repository Sign in Sign up tonsky / FiraCode Watch 282 Star 9,014 Fork 255 Code Issues 74 Pull requests 1 Projects 0 Wiki Pulse Graphs Monospaced font with programming ligatures 145 commits 1 branch 15 releases 32 contributors OFL-1.1 master New pull request Find file Clone or download lf- committed with tonsky Add mintty to the ligatures-unsupported list (#284) Latest commit d7dbc2d 16 days ago distr Version 1.203 (added `__`, closes #120) a month ago showcases Version 1.203 (added `__`, closes #120) a month ago .gitignore - Removed `!!!` `???` `;;;` `&&&` `|||` `=~` (closes #167) `~~~` `%%%` 3 months ago FiraCode.glyphs Version 1.203 (added `__`, closes #120) a month ago LICENSE version 0.6 a year ago README.md Add mintty to the ligatures-unsupported list (#284) 16 days ago gen_calt.clj Removed `/**` `**/` and disabled ligatures for `/*/` `*/*` sequences … 2 months ago release.sh removed Retina weight from webfonts 3 months ago README.md Fira Code: monospaced font with programming ligatures Problem Programmers use a lot of symbols, often encoded with several characters. For the human brain, sequences like -> , <= or := are single logical tokens, even if they take two or three characters on the screen. Your eye spends a non-zero amount of energy to scan, parse and join multiple characters into a single logical one. Ideally, all programming languages should be designed with full-fledged Unicode symbols for operators, but that’s not the case yet. Solution Download v1.203 · How to install · News & updates Fira Code is an extension of the Fira Mono font containing a set of ligatures for common programming multi-character combinations. -
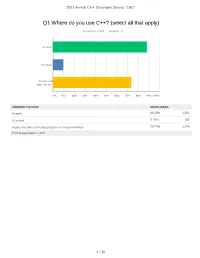
Q1 Where Do You Use C++? (Select All That Apply)
2021 Annual C++ Developer Survey "Lite" Q1 Where do you use C++? (select all that apply) Answered: 1,870 Skipped: 3 At work At school In personal time, for ho... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES At work 88.29% 1,651 At school 9.79% 183 In personal time, for hobby projects or to try new things 73.74% 1,379 Total Respondents: 1,870 1 / 35 2021 Annual C++ Developer Survey "Lite" Q2 How many years of programming experience do you have in C++ specifically? Answered: 1,869 Skipped: 4 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 7.60% 142 3-5 years 20.60% 385 6-10 years 20.71% 387 10-20 years 30.02% 561 >20 years 21.08% 394 TOTAL 1,869 2 / 35 2021 Annual C++ Developer Survey "Lite" Q3 How many years of programming experience do you have overall (all languages)? Answered: 1,865 Skipped: 8 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 1.02% 19 3-5 years 12.17% 227 6-10 years 22.68% 423 10-20 years 29.71% 554 >20 years 34.42% 642 TOTAL 1,865 3 / 35 2021 Annual C++ Developer Survey "Lite" Q4 What types of projects do you work on? (select all that apply) Answered: 1,861 Skipped: 12 Gaming (e.g., console and.. -

License Agreement for Intellij Idea
LICENSE AGREEMENT FOR APPCODE (Classroom License) Version 11, Effective as of 16 May 2013 IMPORTANT! READ CAREFULLY: THIS IS A LEGAL AGREEMENT. BY DOWNLOADING, INSTALLING, COPYING, SAVING ON YOUR COMPUTER, OR OTHERWISE USING THIS SOFTWARE, YOU (LICENSEE, AS DEFINED BELOW) ARE BECOMING A PARTY TO THIS AGREEMENT AND YOU ARE CONSENTING TO BE BOUND BY ALL THE TERMS AND CONDITIONS OF THIS AGREEMENT. IF YOU DO NOT AGREE TO THE TERMS AND CONDITIONS OF THIS AGREEMENT, YOU SHOULD NOT DOWNLOAD, INSTALL AND USE THE SOFTWARE. 1. PARTIES (a) "Licensor" means JetBrains s.r.o., having its principal place of business at Na hřebenech II 1718/10, Prague, 14700, Czech Republic, registered with Commercial Register kept by the Municipal Court of Prague, Section C, file 86211, ID.Nr.: 265 02 275. (b) "Licensee" means a public or private school, college, training courses, university and other post secondary educational establishment specified in the License Certificate, exercising rights under, and complying with the terms of this Agreement. 2. DEFINITIONS (a) "Authorized User" means any student, faculty or staff member authorized by Licensee to use the Software while performing duties within the scope of their employment or assignment. (b) "Software" means software program known as JetBrains AppCode in binary form, including its documentation, upgrades provided pursuant to Section 7 of this Agreement, and any third party software programs that are owned and licensed pursuant to Section 6 of this Agreement by parties other than Licensor and that either integrated with or made part of JetBrains AppCode (collectively, "Third Party Software"). (c) "License Certificate" means evidence of a license provided by Licensor to Licensee in electronic or printed form. -
Xdebug Tutorial
Welcome! Xdebug tutorial PHP Konferenca - Ljubljana, Slovenia Derick Rethans - [email protected] - twitter: @derickr http://derickrethans.nl/talks.html About Me Derick Rethans ● Dutchman living in London ● PHP development ● Author of the mcrypt, input_filter, dbus, translit and date/time extensions ● Author of Xdebug ● Contributor to the Apache Zeta Components Incubator project (formerly eZ Components) ● Freelancer doing PHP (internals) development I Do Not Need a Debugger ● printf(), var_dump() and echo are good enough I Do Not Need a Debugger I Do Need a Debugger ● Xdebug: An Open Source debugging tool ● About 8 years old ● Works on "every" operating system ● Version 2.1 released about three months ago This Tutorial ● Installation overview ● Downloading, compiling and configuring Xdebug ● Basic function overview ● Playing with settings, stack traces and function traces break ● Profiling ● Profiling your own code ● Code coverage ● (Setting up code-coverage with PHP Unit) break ● Debugging ● Setting up your IDE for debugging Installation The Xdebug extension ● Zend extension, and not a PHP extension ● Xdebug is very PHP-version sensitive ● Different compilers under Windows ● Debug/non-debug ● Threadsafe or not In PHP 5.1 and 5.2: zend_extension=/local/php/lib/php/extensions/no-debug-non-zts- 20090626/xdebug.so zend_extension_ts=/local/php/lib/php/extensions/debug-zts- 20090626/xdebug.so zend_extension_debug=/local/php/lib/php/extensions/debug-non-zts- 20090626/xdebug.so In PHP 5.3: zend_extension=/local/php/lib/php/extensions/no-debug-non-zts- -

How to Communicate with Developers
How to Communicate with Developers Employer branding, job listings, and emails that resonate with a tech audience Developers are one of the most in-demand groups of employees these days. And guess what, they noticed this as well: Countless approaches by potential employers, sometimes several messages a day through Linkedin, and a few desperate recruiters even cold calling. So those with technical talents are by no means oblivious to the talent shortage. The good news is that they don’t just use this bargaining power to simply negotiate the highest salaries and most outrageous benefits. Instead, developers are intrinsically motivated. They are looking for the right place to work. Your challenge in this noisy jobs market is to clearly communicate what defines your employer brand, what work needs doing, and, ultimately, who might be the right fit for the role. All of this is easier said than done. Because tech recruiting is a complex business, it is easy to not see the forest for the trees. This guide will help you decide where to start or what to fix next. In the first and more general part, we would like you to take a step back. Before we even think about how to package our job opening and approach a candidate with our offer, we look at what information and knowledge you should gather about your tech team and the company at large. Following that, we will take a practical look at how to write and talk about your company and the role, with a special focus on the job listings and a recruiting emails as a first introduction. -

Ratan Sunder Parai
Ratan Sunder Parai SOFTWARE ENGINEER Kallyanpur, Dhaka, Bangladesh (+880) 1771-998817 | [email protected] | ratanparai.wordpress.com | ratanparai | ratan-parai | ratanparai “Never memorize something that you can look up.” ― Albert Einstein Objective Super nerd who loves Vim and customize all of the development environment. Love to take challenge for devising a better problem-solving method while learning new technologies and tools as needed. Skills PHP, Node.JS, JavaScript, Python, JAVA, Android, C# .NET, C/C++, iOS (Objective-C), HTML5, Programming Typescript, Pug, CSS3, SASS, LESS, Regex, Swift 2 Database MySQL, MariaDB, MongoDB, SQLite, Redis Development Architecture MVC, MVW, REST API, Publish-Subscribe Express.JS, Socket.IO, AngularJS, Angular4, Gulp, Grunt, Codeigniter, Laravel, Slim Framework, Framework and Platform ASP.NET MVC, Entity Framework, Bootstrap, Foundation, SemanticUI, 960 Grid, Mocha, Chai, CMAKE, Bower, Composer, OAuth 1.0a, oAuth 2.0 VIM, Emacs, Xcode, Eclipse, WebStorm, Visual Studio, Visual Studio Code, Android Studio, Sublime Development Tool Text, IntelliJ IDEA, Code::Blocks, Geany, PyCharm, QT Creator Operating System Windows 98 – Windows 10, MacOS 10.4.4(Tiger) – 10.11(El Capitan), Ubuntu (8.04 – 15.10), Fedora Web Server Apache, Nginx, Lighttpd, Tor Hidden Service Languages Bengali, English Experience Leads Corporation Ltd. Dhaka, Bangladesh SOFTWARE ENGINEER INTERN May. 2017 - PRESENT • Developed Anti-skimming software (Terminal + Client) for Prime Bank in JAVA • Develop Customize Message Format -

How Intellij IDEA Helps Your Business
How IntelliJ IDEA Helps Your Business JetBrains IntelliJ IDEA is a capable and er- their overall productivity), IntelliJ IDEA can Remarkable Return on Investment (ROI) gonomic IDE for web, enterprise and mobile be an equally valuable asset for your busi- Java development. In addition to the bene- ness. It can save you money and resources Designed for productivity fits it provides to developers (such as saving by reducing software development and main- their time by automating routine tasks, locat- tenance costs, help you keep release sched- Code quality matters ing and fixing errors, taking advantage of in- ules, and even boost revenues by improving telligent support from the IDE, and increasing the quality of your software products. The power of IntelliJ Platform Facilitating workflow for the entire team Comprehensive and fast customer support Flexible licensing policy and bulk discounts Industry recognition Contact us Remarkable Return on Investment (ROI) At least 30% of the time, developers work According to our internal research, IntelliJ Compared to the labor cost, a price on fixing code issues that could be avoided IDEA users report a 23% to 35% increase of IntelliJ IDEA is only $ 1.9 per business altogether if the right development tools in their productivity when using IntelliJ IDEA, day (calculated based on 260 business were used. Newly hired developers spend in comparison with other IDEs or text edi- days per year). Not to mention the cumu- up to 70% of their time just getting up to tors. Considering that Java developers earn lative productivity boost for your whole speed with the existing codebase. -

Java Script Programming, Introduction
Java Script abelski Introduction © 2008 Haim Michael What is Java Script? Java Script is a scripting language running within the browser. Java Script appeared for the first time in 1995, as a scripting language supported by Netscape Navigator. JScript is Microsoft's variation for JavaScript. © 2008 Haim Michael ECMA Script In 1997 Java Script 1.1 was submitted to the European Computer Manufacturers Association (ECMA). ECMA Script, defined by ECMA-262, is the standard Java Script language. ECMA Script defines the very basic parts of the language, including the following: Syntax, Types, Statements, Keywords, Reserved Words, Operators and Objects. © 2008 Haim Michael ECMA Script Each browser implements ECMA Script in a different level. Some implements ECMA Script edition 1, some implements edition 2, some implements edition 3 and some implements edition 4. © 2008 Haim Michael HTML We can embed Java Script code within our HTML page using the <script> element. < script type=”text/javascript” > function do_something() { alert(“Good Morning!”); } < /script > We can have the Java Script code saved within a separated file the HTML shall refer to. < script type=”text/javascript” src=”mycode.js” > < /script > © 2008 Haim Michael HTML We usually place the <script> tag within the <head> element. <head> < script type=”text/javascript” > function do_something() { alert(“Good Morning!”); } < /script > </head> © 2008 Haim Michael IDEs We can develop simple code in JavaScript using a simple text editor. We can alternatively use an Integrated Development Environment, such as IntelliJ, Visual Studio, Eclipse and Netbeans. © 2008 Haim Michael IntelliJ IDEA This IDE is well known as a Java IDE. It is developed by JetBrains. -

Jformdesigner 5.1 Documentation
JFormDesigner 5.1 Documentation JFormDesigner 5.1 Documentation Version: 5.1 Copyright © 2004-2012 FormDev Software GmbH. All rights reserved. Contents 1 Introduction .......................................................................................................................................... 2 2 User Interface ....................................................................................................................................... 3 2.1 Menus ............................................................................................................................................ 4 2.2 Toolbars ......................................................................................................................................... 7 2.3 Design View .................................................................................................................................... 8 2.3.1 Headers .................................................................................................................................. 10 2.3.2 In-place-editing ........................................................................................................................ 13 2.3.3 Keyboard Navigation ................................................................................................................. 13 2.3.4 Menu Designer ......................................................................................................................... 13 2.3.5 Button Groups .........................................................................................................................