Enhancements to the Scalable Coherent Interface Cache Protocol
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

New Products Latest Releases for Open Systems
New Products Latest Releases for Open Systems Application Management Microsoft ODBC. Tivoli Systems has announced the AMS Forte Express for clients or servers Developer’s Kit and general availability supports Digital Unix, DG-UX, IBM AIX, of version 1.0 of the Applications Man- Sequent Dynix, Sun Solaris HP-UX, Digi- agement Specification (AMS). AMS defines tal OpenVMS and Windows NT. The price a standard interface for creating manage- is $20,000 for a site license. ment objects. These objects enable the Forte Software, Inc., 1800 Harrison connection of applications with client/- St., Oakland, CA 94612; (510) 869-3400. server enterprise management systems WANT MORE INFO? CIRCLE READER SERVICE NO. 205. such as Tivoli Management Environment. SOFTWARE The AMS Developer’s Kit allows users to Process Configuration develop AMS-enabled applications. Management System Management The developer’s kit supports AMS SQL Software has introduced PCMS 4.3, Innovative Software has announced applications for IBM AIX, AT&T SVR4, a process configuration management tool Power Center, an operations automa- Digital Unix, DG-UX, HP-UX, Motorola for concurrent and distributed application tion and system management applica- Unix, SunOS and Sun Solaris. Prices for systems development. Version 4.3 tion. The product detects and works to the developer’s kit start at $250. includes a worksets feature that allows correct problems with computer sys- Tivoli Systems, Inc., 9442 Capital of management to separate individual-team tems, networks, peripherals and appli- Texas Hwy. N, Austin, TX, 78759; (512) work for parallel development and par- cations. Power Center interoperates with 794-9070. allel builds on multiple platforms. -

SCO Vs. IBM: Clarity As Push Approaches Shove
Managing L'unix Paul Murphy March 12th, 2007 SCO vs. IBM: clarity as push approaches shove Posted by Paul Murphy @ 12:15 am Just recently groklaw published both IBM's motion for summary judgement on SCO's contractual claims and SCO's rebuttal argument. The judge could rule on those today or later or this week, but the outcome is less interesting than the documents themselves because here, for the first time, both SCO and IBM state their cases clearly and relatively simply. As the motions make clear everything ultimately comes down to one issue: did IBM breach contracts now held by SCO? For a judge to grant a motion for summary judgement, however, the judge has to agree that the facts are undisputed, and since they're not my belief is that IBM's lawyers had to know that the only motion that counts, the one on contractual issues, would not succeed. The key question, therefore, is why they decided to waste the court's time with it - and my guess, because as regular readers known my belief is that SCO has a strong case, is first that they're trying to use IBM's financial strength to bankrupt SCO, and, secondly, that they're trying to establish a fundamental misrepresentation of the key issues as fact. Here's part of the critical text, from the SCO side: First, IBM argues briefly otherwise, but the plain language of the standard AT&T UNIX license agreement required the licensee to hold in confidence all parts of the modifications and derivative works the licensee developed based on the licensed UNIX software product. -

Understanding the Linux Kernel, 3Rd Edition by Daniel P
1 Understanding the Linux Kernel, 3rd Edition By Daniel P. Bovet, Marco Cesati ............................................... Publisher: O'Reilly Pub Date: November 2005 ISBN: 0-596-00565-2 Pages: 942 Table of Contents | Index In order to thoroughly understand what makes Linux tick and why it works so well on a wide variety of systems, you need to delve deep into the heart of the kernel. The kernel handles all interactions between the CPU and the external world, and determines which programs will share processor time, in what order. It manages limited memory so well that hundreds of processes can share the system efficiently, and expertly organizes data transfers so that the CPU isn't kept waiting any longer than necessary for the relatively slow disks. The third edition of Understanding the Linux Kernel takes you on a guided tour of the most significant data structures, algorithms, and programming tricks used in the kernel. Probing beyond superficial features, the authors offer valuable insights to people who want to know how things really work inside their machine. Important Intel-specific features are discussed. Relevant segments of code are dissected line by line. But the book covers more than just the functioning of the code; it explains the theoretical underpinnings of why Linux does things the way it does. This edition of the book covers Version 2.6, which has seen significant changes to nearly every kernel subsystem, particularly in the areas of memory management and block devices. The book focuses on the following topics: • Memory management, including file buffering, process swapping, and Direct memory Access (DMA) • The Virtual Filesystem layer and the Second and Third Extended Filesystems • Process creation and scheduling • Signals, interrupts, and the essential interfaces to device drivers • Timing • Synchronization within the kernel • Interprocess Communication (IPC) • Program execution Understanding the Linux Kernel will acquaint you with all the inner workings of Linux, but it's more than just an academic exercise. -

(For Solaris) User Guide Contents
Hitachi Command Suite Dynamic Link Manager (for Solaris) 8.6 User Guide This document describes how to use the Hitachi Dynamic Link Manager for Solaris. The document is intended for storage administrators who use Hitachi Dynamic Link Manager to operate and manage storage systems. Administrators should have knowledge of Solaris and its management functionality, storage system management functionality, cluster software functionality, and volume management software functionality. MK-92DLM114-42 May 2018 © 2014, 2018 Hitachi, Ltd. All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including copying and recording, or stored in a database or retrieval system for commercial purposes without the express written permission of Hitachi, Ltd., or Hitachi Vantara Corporation (collectively "Hitachi"). Licensee may make copies of the Materials provided that any such copy is: (i) created as an essential step in utilization of the Software as licensed and is used in no other manner; or (ii) used for archival purposes. Licensee may not make any other copies of the Materials. "Materials" mean text, data, photographs, graphics, audio, video and documents. Hitachi reserves the right to make changes to this Material at any time without notice and assumes no responsibility for its use. The Materials contain the most current information available at the time of publication. Some of the features described in the Materials might not be currently available. Refer to the most recent product announcement for information about feature and product availability, or contact Hitachi Vantara Corporation at https://support.hitachivantara.com/en_us/contact-us.html. -
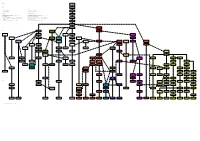
Unix History 2.6 Unix Geschichte 2.6 1972
1960 AT&T UNICS 1969 1970 UNIX 1 1971 UNIX 2 Unix history 2.6 Unix Geschichte 2.6 1972 Small UNIX history Kleine UNIX-Geschichte UNIX 3 1973 Represented are only the origin lines. Dargestellt sind nur die Ursprungslinien. The different influences are shown only with Apple, since they impair Die verschiedenen Einflüsse sind nur bei Apple abgebildet, da sie die the clarity strongly. Übersichtlichkeit stark beeinträchtigen. UNIX 4 Further data are: Manufacturer, operating system name as well as the Weitere Daten sind: Hersteller, Betriebssystem-Name sowie das 1973 feature year of the software. The individual versions are listed only with Erscheinungsjahr der Software. Die einzelnen Versionen sind nur bei UNIX and Linux. UNIX und Linux aufgelistet. More detailed list under: http://www.levenez.com/unix/ Detailliertere Liste unter: http://www.levenez.com/unix/ UNIX 5 1974 UNIX 6 1976 UNIX 7 Berkeley Software 1979 Distribution: BSD 1978 1980 UNIX System III Microsoft BSD 4.1 1981 XENIX 1981 1980 UNIX V UNIX 8 SUN SPIX QUNIX 1983 1985 Sun OS 1.0 1982 1981 1982 UNIX V.2 Microsoft/SCO Siemens UNIX 9 Sun OS 2.0 Dynix Venix 1984 XENIX 3.0 Sinix 1.0 1986 1985 1984 1985 1984 1984 HP IBM UNIX 10 MIPS BSD 4.2 GNU Sun OS 3.0 Andrew S. Mach HP-UX AIX/RT 2 End: 1989 MIPS OS 1985 Trix 1986 Tanenbaum: Minix 1985 1986 1986 1985 1986 1987 UNIX V.3 SGI Mach 2.0 Minix 1.0 NonStop-UX 1986 IRIX 1996 1987 1987 1988 UNIX V.4 AIX/6000 v3 BOS MIPS OS NeXT A/UX 1988 1989 1989 End: 1989 NeXTSTEP 1988 1988 1990 UNIX V.x Trusted AIX 3.1 IRIX 4.0 Mach 3.0 Linus Torvalds -

Postgresql Freebsd 12 12 PROC PDEATHSIG CTL
Walking Through Walls PostgreSQL ♥ FreeBSD [email protected] [email protected] [email protected] About me • New to FreeBSD hacking Mentors: mjg, allanjude • ~20 years work on proprietary C, C++, … applications on lots of different kinds of Unix • Past ~4 years working on PostgreSQL at EnterpriseDB • Past ~3 years dabbling in FreeBSD, beginning with the gateway drug of ZFS home storage boxes, now my main development and server environment • Personal goal: make FreeBSD and PostgreSQL the best relational database stack Berkeley • INGRES: Developed at UC Berkeley, 197x-1985 • Relational database ideas inspired by IBM’s System/R (though using QUEL instead of SQL), developed on PDPs just as Unix arrived at Berkeley • First software released entirely under BSD licence (CSRG distribution still needed AT&T licence for parts) Michael Stonebraker • POSTGRES: Developed at UC Berkeley, 1986-1994 • Entirely new system (but still using INGRES’s QUEL query language) • Developed on SunOS (derived from 4.3BSD) and Dynix (derived from 4.2BSD, added SMP support for Sequent computers) and (probably) various other flavours of BSD • PostgreSQL: Modern open source project, 1996- • We current claim to support Linux, {Open,Net,Free}BSD, macOS, AIX, HP/ UX, Solaris, Windows; in the past we supported IRIX, Tru64, UnixWare, Latter day PostgreSQL BSD/OS, BeOS, QNX, SunOS, SCO OpenServer hackers on a pilgrimage to Berkeley How operating systems look to database hackers • APIs, man pages, standards chiselled in stone • Administration tools, tunables, -

Developer Relations Withdrawal: Willow Family of Products — Replacements Available
Withdrawal Announcement December 14, 2004 Developer Relations withdrawal: Willow Family of Products — Replacements available Overview IBM withdraws from marketing the following products under the Developer Marketing Partnerships-Remarketing Software program. Program Description number WebSphere MQ for SCO OpenServer 5620-FKV WebSphere MQ for UnixWare & Open Unix 5620-FKW WebSphere MQ for SGI IRIX 5620-FKX WebSphere MQ for DYNIX/ptx 5620-FKY WebSphere MQ for NCR MP-RAS 5620-FKZ WebSphere MQ for Linux (Alpha Edition) 5620-FLA WebSphere MQ for Linux (PowerPC Edition) 5620-FLB WebSphere MQ for Linux (SPARC Edition) 5620-FLC WebSphere MQ Client for SCO OpenServer 5620-FLD WebSphere MQ Client for UnixWare & Open Unix 5620-FLE WebSphere MQ Client for MPE/IX 5620-FLF WebSphere MQ Client for SGI IRIX 5620-FLG WebSphere MQ Client for DG/UX 5620-FLH WebSphere MQ Client for MAC OS 5620-FLI This withdrawal applies to the IBM Developer Marketing Partnership relationship only. Other relationships between Willow Technology, Inc., and IBM, both in the U.S. and worldwide, are unaffected. Replacement product information Program Description number WebSphere MQ for BSD 5620-FRT WebSphere MQ for DYNIX/PTX 5620-FRU WebSphere MQ for HP-UX (Itanium Edition) 5620-FRV WebSphere MQ for Linux (Alpha Edition) 5620-FRW WebSphere MQ for Linux 5620-FRX (iSeries /pSeries Edition) WebSphere MQ for NCR MP-RAS 5620-FRY WebSphere MQ for SCO OpenServer 5620-FRZ WebSphere MQ for SGI IRIX 5620-FSA WebSphere MQ for UnixWare 5620-FSB WebSphere MQ Client for DG/UX 5620-FSC WebSphere MQ Client for MPE/iX 5620-FSD WebSphere MQ Client for SCO OpenServer 5620-FSE WebSphere MQ Client for UnixWare 5620-FSF For additional information refer to Software announcement 204-313, dated December 14, 2004. -

A Bibliography of Books and Articles About UNIX and UNIX Programming
A Bibliography of Books and Articles about UNIX and UNIX Programming Nelson H. F. Beebe University of Utah Department of Mathematics, 110 LCB 155 S 1400 E RM 233 Salt Lake City, UT 84112-0090 USA Tel: +1 801 581 5254 FAX: +1 801 581 4148 E-mail: [email protected], [email protected], [email protected] (Internet) WWW URL: http://www.math.utah.edu/~beebe/ 02 July 2021 Version 4.44 Abstract General UNIX texts [AL92a, AL95a, AL95b, AA86, AS93b, Ari92, Bou90a, Chr83a, Chr88, CR94, Cof90, Coh94, Dun91a, Gar91, Gt92a, Gt92b, This bibliography records books and historical Hah93, Hah94a, HA90, Hol92, KL94, LY93, publications about the UNIX operating sys- LR89a, LL83a, MM83a, Mik89, MBL89, tem, and UNIX programming tools. It mostly NS92, NH91, POLo93, PM87, RRF90, excludes networks and network programming, RRF93, RRH94, Rus91, Sob89, Sob91, which are treated in a separate bibliography, Sob95, Sou92, TY82b, Tim93, Top90a, internet.bib. This bibliography was started Top90b, Val92b, SSC93, WMP92] from material in postings to the sunflash list, volume 46, number 17, October 1992, and volume 57, number 29, September 1993, by Samuel Ko (e-mail: [email protected]), and then significantly extended by the present Catalogs and book lists author. Entry commentaries are largely due to S. Ko. [O'R93, Spu92, Wri93] 1 2 Communications software History [Cam87, dC87, dG93, Gia90] [?, ?, Cat91, RT74, RT79a] Compilers Linux [DS88, JL78, Joh79, JL87a, LS79, LMB92, [BBD+96, BF97, HP+95, Kir95a, Kir95b, MB90, SF85] PR96b, Sob97, SU94b, SU95, SUM95, TGB95, TG96, VRJ95, -

Optimizing Multi-Processor Operating Systems Software Research Review
Optimizing Multi-Processor Operating Systems Software Research Review Jonathan Appavoo 1 In this paper we review general purpose multiprocessor operating systems research that is relevant to maximizing performance, focusing on the exploitation of locality in large scale systems. We cover three areas in particular: 1. A historical review of multiprocessor operating systems research. 2. A discussion of disciplined approaches to applying distributed data structures to systems construction. 3. A review of modern operating systems research that addresses the unique characteristics of scalable hardware platforms. Utilizing concurrency to improve performance is not new and certainly not restricted to the domain of operating systems. Many of the features introduced into microprocessor architectures attempt to extract parallelism at the instruction level in order to hide latencies and improve the number of instructions executed per cycle. Increasingly scientific users split their calculations into independent components which can be executed in parallel in order to decrease absolute runtime. Operating systems are unique, from a software perspective, in their requirement to support and enable parallelism rather than exploiting it to improve their own performance. An operating sys- tem (OS) must ensure good overall system utilization and high degrees of parallelism for those applications which demand it. To do this, operating systems must: 1) utilize the characteristics of the hardware to exploit concurrency in general purpose workloads and 2) facilitate concurrent ap- plications, which include providing models and facilities for applications to exploit the concurrency available in the hardware. It is critical that an OS reflect the parallelism of the workloads and individual applications to ensure that the OS facilities do not hinder overall system or individual application performance. -
Distributed Operating System: a Perspective
COMMUNICATIONCOMMUNICATION ARTICLE 9(21), January 1, 2014 ISSN 2278–5469 EISSN 2278–5450 DDiissccoovveerryy Distributed operating system: a perspective Annu, Himanshu rehani Department of Computer Science and Engineering, Dronacharya College of Engineering, Khentawas, Farukhnagar, Gurgaon, India Publication History Received: 12 November 2013 Accepted: 19 December 2013 Published: 1 January 2014 Citation Annu, Himanshu Rehani. Distributed operating system: a perspective. Discovery, 2014, 9(21), 21-33 Publication License This work is licensed under a Creative Commons Attribution 4.0 International License. General Note Article is recommended to print as color digital version in recycled paper. ABSTACT A distributed operating system is software over a collection of independent, networked, communicating, and physically separate computational nodes. Individual nodes each hold a specific software subset of the global aggregate operating system. Each subset is a composite of two distinct service provisioners. First is a ubiquitous minimal kernel, or microkernel, that directly controls that node’s hardware. Second is a higher-level collection of system management components that coordinate the node's individual and collaborative activities. These components abstract microkernel functions and support user applications. A collection of independent computers which can cooperate, but which appear to users of the system as a uniprocessor computer the microkernel and the management components collection work together. They support the system’s goal of integrating multiple resources and processing functionality into an efficient and stable system. This seamless integration of individual nodes into a global system is referred to as transparency, or single system image; describing the illusion provided to users of the global system’s appearance as a single computational entity. -

Linux 诞生和发展的五个重要支柱 Five Vital Supports for the Inception & Development of Linux
Linux 诞生和发展的五个重要支柱 Five Vital Supports for the Inception & Development of Linux 赵炯 [email protected] www.plinux.org 2002-12-22 ©赵炯,2002 年 I 《Linux 的诞生和发展及其五个重要支柱》 [email protected] www.plinux.org 目录 1 概述 ................................................................... 1 2 起源(UNIX 操作系统) .................................................... 2 3 MINIX 操作系统 ......................................................... 7 4 GNU 发展历史 .......................................................... 10 5 POSIX 标准 ............................................................ 14 6 LINUX 操作系统 ........................................................ 16 7 早期主要贡献者 ........................................................ 33 8 结论 .................................................................. 37 参考资料 ................................................................ 37 I 《Linux 的诞生和发展及其五个重要支柱》 [email protected] www.plinux.org 1 概述 Linux 操作系统诞生于 1991 年的 10 月 5 日(第一次正式向外公布的时间)。以后借助 于 Internet 网络,经过全世界各地计算机爱好者的共同努力下,才成为今天世界上使用最 多的一种 UNIX 类操作系统,并且使用人数还在迅猛增长。 LINUX 诞生和成长的五大重要支柱: LINUX INTERNET POSIX UNIX GNU MINIX UNIX 操作系统 -- UNIX 于 1969 年诞生在 Bell 实验室。Linux 就是 UNIX 的一种克 隆系统。UNIX 的重要性就不用多说了。 MINIX 操作系统 -- Minix 操作系统也是 UNIX 的一种克隆系统,它于 1987 年由著 名计算机教授 AST 开发完成。由于 MINIX 系统的出现并且提供源代码(只能免费用 于大学内)在全世界的大学中刮起了学习 UNIX 系统旋风。Linux 刚开始就是参照 Minix 系统于 1991 年才开始开发。 GNU 计划(项目、工程)-- 开发 Linux 操作系统,以及 Linux 上所用大多数软件 基本上都出自 GNU 计划。Linux 只是操作系统的一个内核,没有 GNU 软件环境(比 如说 bash shell),则 Linux 将寸步难行。 POSIX 标准 -- 该标准在推动 Linux 操作系统以后朝着正规路上发展,起着重要的 作用。是 Linux 前进的灯塔。 INTERNET -- 如果没有 Intenet 网,没有遍布全世界的无数计算机骇客的无私奉献, -

AIX 5L for Itanium-Based Systems: Product History
AIX 5L for Itanium-based Systems: Product History https://web.archive.org/web/20030215143911/http://www-1.ibm.c... The Wayback Machine - https://web.archive.org/web/20030215143911/http://www-1.ibm.com:80/servers/aix/itanium/history.html Home | Products & services | Support & downloads | My account Select a country AIX AIX 5L for Itanium Based Systems History Early Adopters Release Product History More Information Notes AIX 5L, the most open UNIX operating system in the industry, was achieved through IBM's AIX 5L: An the successful collaborative efforts of IBM, Caldera, and Intel to create an Examination of a Next- Developer Tools enterprise operating system solution for the Intel® Itanium™ hardware platform. Generation UNIX Operating System by AIX 5L combines the heritage of previous AIX versions with elements of DYNIX/ptx Andrews Consulting and Caldera UnixWare, as well as a strong affinity for Linux on today's most vital Group, Inc. (June, 2001) enterprise processors. 1998: Project Monterey For years, the UNIX market presented a fragmented landscape dotted with various "flavors" of UNIX platforms optimized for specific processors. This had limited the developer and ISVs ability to leverage their development efforts across multiple platforms without significantly rewriting applications. To overcome this problem, IBM, Caldera, and Intel embarked on "Project Monterey," a cooperative effort to create an open, flexible enterprise UNIX platform with broad- based support for today's and tomorrow's leading 64-bit enterprise microprocessors, the IBM POWER processors and the upcoming Intel Itanium processors. 2000: AIX 5L With the successful release of AIX® 5L for Itanium-based systems, we have fulfilled -- and in many ways exceeded -- the original goals of "Project Monterey." AIX 5L is the next generation of AIX that supports both IBM POWER and the Intel Itanium processors, offering a strong affinity with Linux, and extending the AIX enterprise strengths to the Intel Itanium processor architecture.