A Privacy Preserving ML System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Technical Report (Open)SSH Secure Use Recommendations
DAT-NT-007-EN/ANSSI/SDE PREMIERMINISTRE Secrétariat général Paris, August 17, 2015 de la défense et de la sécurité nationale No DAT-NT-007-EN/ANSSI/SDE/NP Agence nationale de la sécurité Number of pages des systèmes d’information (including this page): 21 Technical report (Open)SSH secure use recommendations Targeted audience Developers Administrators X IT security managers X IT managers Users Document Information Disclaimer This document, written by the ANSSI, presents the “(Open)SSH secure use recom- mendations”. It is freely available at www.ssi.gouv.fr/nt-ssh. It is an original creation from the ANSSI and it is placed under the “Open Licence” published by the Etalab mission (www.etalab.gouv.fr). Consequently, its diffusion is unlimited and unrestricted. This document is a courtesy translation of the initial French document “Recommanda- tions pour un usage sécurisé d’(Open)SSH”, available at www.ssi.gouv.fr/nt-ssh. In case of conflicts between these two documents, the latter is considered as the only reference. These recommendations are provided as is and are related to threats known at the publication time. Considering the information systems diversity, the ANSSI cannot guarantee direct application of these recommendations on targeted information systems. Applying the following recommendations shall be, at first, validated by IT administrators and/or IT security managers. Document contributors Contributors Written by Approved by Date Cisco1, DAT DAT SDE August 17, 2015 Document changelog Version Date Changelog based on 1.3 – french August 17, 2015 Translation Contact information Contact Address Email Phone 51 bd de La Bureau Communication Tour-Maubourg [email protected] 01 71 75 84 04 de l’ANSSI 75700 Paris Cedex 07 SP 1. -

Openssh Client Cryptographic Module Versions 1.0, 1.1 and 1.2
OpenSSH Client Cryptographic Module versions 1.0, 1.1 and 1.2 FIPS 140-2 Non-Proprietary Security Policy Version 3.0 Last update: 2021-01-13 Prepared by: atsec information security corporation 9130 Jollyville Road, Suite 260 Austin, TX 78759 www.atsec.com © 2021 Canonical Ltd. / atsec information security This document can be reproduced and distributed only whole and intact, including this copyright notice. OpenSSH Client Cryptographic Module FIPS 140-2 Non-Proprietary Security Policy Table of Contents 1. Cryptographic Module Specification ....................................................................................................... 5 1.1. Module Overview .................................................................................................................................... 5 1.2. Modes of Operation ................................................................................................................................ 9 2. Cryptographic Module Ports and Interfaces ......................................................................................... 10 3. Roles, Services and Authentication ...................................................................................................... 11 3.1. Roles ...................................................................................................................................................... 11 3.2. Services ................................................................................................................................................. -

Openssh-Ldap-Pubkey Documentation Release 0.3.0
openssh-ldap-pubkey Documentation Release 0.3.0 Kouhei Maeda May 18, 2020 Contents 1 openssh-ldap-pubkey 3 1.1 Status...................................................3 1.2 Requirements...............................................3 1.3 See also..................................................3 2 How to setup LDAP server for openssh-lpk5 2.1 Precondition...............................................5 2.2 Requirements...............................................5 2.3 Install...................................................5 3 How to setup OpenSSH server9 3.1 Precondition...............................................9 3.2 Requirements...............................................9 3.3 Install with nslcd (recommend).....................................9 3.4 Install without nslcd........................................... 11 4 History 13 4.1 0.3.0 (2020-05-18)............................................ 13 4.2 0.2.0 (2018-09-30)............................................ 13 4.3 0.1.3 (2018-08-18)............................................ 13 4.4 0.1.2 (2017-11-25)............................................ 13 4.5 0.1.1 (2015-10-16)............................................ 14 4.6 0.1.0 (2015-10-16)............................................ 14 5 Contributors 15 6 Indices and tables 17 i ii openssh-ldap-pubkey Documentation, Release 0.3.0 Contents: Contents 1 openssh-ldap-pubkey Documentation, Release 0.3.0 2 Contents CHAPTER 1 openssh-ldap-pubkey 1.1 Status 1.2 Requirements 1.2.1 LDAP server • Add openssh-lpk schema. • Add an objectClass ldapPublicKey to user entry. • Add one or more sshPublicKey attribute to user entry. 1.2.2 OpenSSH server • OpenSSH over 6.2. • Installing this utility. • Setup AuthorozedKeysCommand and AuthorizedKeysCommandUser in sshd_config. 1.3 See also • OpenSSH 6.2 release 3 openssh-ldap-pubkey Documentation, Release 0.3.0 • openssh-lpk 4 Chapter 1. openssh-ldap-pubkey CHAPTER 2 How to setup LDAP server for openssh-lpk 2.1 Precondition This article restricts OpenLDAP with slapd_config on Debian systems only. -

Scripting the Openssh, SFTP, and SCP Utilities on I Scott Klement
Scripting the OpenSSH, SFTP, and SCP Utilities on i Presented by Scott Klement http://www.scottklement.com © 2010-2015, Scott Klement Why do programmers get Halloween and Christmas mixed-up? 31 OCT = 25 DEC Objectives Of This Session • Setting up OpenSSH on i • The OpenSSH tools: SSH, SFTP and SCP • How do you use them? • How do you automate them so they can be run from native programs (CL programs) 2 What is SSH SSH is short for "Secure Shell." Created by: • Tatu Ylönen (SSH Communications Corp) • Björn Grönvall (OSSH – short lived) • OpenBSD team (led by Theo de Raadt) The term "SSH" can refer to a secured network protocol. It also can refer to the tools that run over that protocol. • Secure replacement for "telnet" • Secure replacement for "rcp" (copying files over a network) • Secure replacement for "ftp" • Secure replacement for "rexec" (RUNRMTCMD) 3 What is OpenSSH OpenSSH is an open source (free) implementation of SSH. • Developed by the OpenBSD team • but it's available for all major OSes • Included with many operating systems • BSD, Linux, AIX, HP-UX, MacOS X, Novell NetWare, Solaris, Irix… and yes, IBM i. • Integrated into appliances (routers, switches, etc) • HP, Nokia, Cisco, Digi, Dell, Juniper Networks "Puffy" – OpenBSD's Mascot The #1 SSH implementation in the world. • More than 85% of all SSH installations. • Measured by ScanSSH software. • You can be sure your business partners who use SSH will support OpenSSH 4 Included with IBM i These must be installed (all are free and shipped with IBM i **) • 57xx-SS1, option 33 = PASE • 5733-SC1, *BASE = Portable Utilities • 5733-SC1, option 1 = OpenSSH, OpenSSL, zlib • 57xx-SS1, option 30 = QShell (useful, not required) ** in v5r3, had 5733-SC1 had to be ordered separately (no charge.) In v5r4 or later, it's shipped automatically. -

Using Vmware Vrealize Orchestrator 8.4 Plug-Ins
Using VMware vRealize Orchestrator 8.4 Plug-Ins 15 APRIL 2021 vRealize Orchestrator 8.4 Using VMware vRealize Orchestrator 8.4 Plug-Ins You can find the most up-to-date technical documentation on the VMware website at: https://docs.vmware.com/ VMware, Inc. 3401 Hillview Ave. Palo Alto, CA 94304 www.vmware.com © Copyright 2008-2021 VMware, Inc. All rights reserved. Copyright and trademark information. VMware, Inc. 2 Contents Using VMware vRealize Orchestrator Plug-Ins 9 1 Introduction to vRealize Orchestrator Plug-Ins 10 vRealize Orchestrator Architecture 11 Plug-Ins Installed with the vRealize Orchestrator Server 11 Access the vRealize Orchestrator API Explorer 14 Time Zone Codes 15 2 Configuring the vRealize Orchestrator Plug-Ins 18 Manage vRealize Orchestrator Plug-Ins 18 Install or Update a vRealize Orchestrator Plug-In 19 Delete a Plug-In 19 3 Using the Active Directory Plug-In 21 Configuring the Active Directory Plug-In 21 Using the Active Directory Plug-In Workflow Library 22 Computer Workflows 22 Organizational Unit Workflows 22 User Workflows 23 User Group Workflows 23 Client-Side Load Balancing for the Active Directory Plug-In 24 4 Using the AMQP Plug-In 25 Configuring the AMQP Plug-In 25 Add a Broker 25 Subscribe to Queues 26 Update a Broker 27 Using the AMQP Plug-In Workflow Library 27 Declare a Binding 28 Declare a Queue 28 Declare an Exchange 29 Send a Text Message 30 Delete a Binding 31 5 Using the Configuration Plug-In 32 6 Using the Dynamic Types Plug-In 34 Dynamic Types Configuration Workflows 34 VMware, Inc. -

Z/OS Openssh User's Guide
z/OS Version 2 Release 4 z/OS OpenSSH User's Guide IBM SC27-6806-40 Note Before using this information and the product it supports, read the information in “Notices” on page 503. This edition applies to Version 2 Release 4 of z/OS (5650-ZOS) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2020-11-16 © Copyright International Business Machines Corporation 2015, 2019. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Figures................................................................................................................. ix Tables.................................................................................................................. xi About this document...........................................................................................xiii Who should use this document?............................................................................................................... xiii z/OS information........................................................................................................................................xiii Discussion list...................................................................................................................................... xiii How to send your comments to IBM......................................................................xv If you have a technical problem.................................................................................................................xv -

Gnuk — a Free Software USB Token Implementation Niibe Yutaka
Gnuk — A Free Software USB Token Implementation Niibe Yutaka <[email protected]> What’s Gnuk? Free Software implementation of Cryptographic Token For GNU Privacy Guard Supports OpenPGP card protocol version 2 Runs on STM32 processor Named after NUK® My son used to be with his NUK®, always, everywhere I wish Gnuk Token can be a soother for GnuPG user NUK® is a registered trademark owend by MAPA GmbH, Germany. Cryptographic Token? Stores your Secret Keys Performs security operations on the device Digital signature Authentication Decryption No direct access of Secret Keys How useful? Can bring secret keys securely On the go, you can do: Make digital signature Authenticate yourself Read encrypted mail GNU Privacy Guard (GnuPG) Tool for Privacy by Cryptography Conforms to OpenPGP standard Usage: Digital Signature Encryption/Decryption Authentication Supports "OpenPGP card" OpenPGP card Smartcard to put GnuPG keys Follows OpenPGP protocol standard Features of v2.0: RSA 1024-bit, 2048-bit, 3072-bit Three keys: Sign, Decrypt, Auth Key generation on the card RSA accelerator OpenPGP card Applications GnuPG OpenSSH → gpg-agent TLS/SSL Client authentication Scute (Network Security Service) PAM Poldi Problem to solve Where and how we put our secret keys? On the disk of our PC Encrypted by passphrase Not Secure Enough OpenPGP card Good (portable, secure) Not easily deployed (reader is not common) FSIJ USB Token v1 (2008) Hardware: Built a PCB CPU: Atmel AVR ATmega 328 @20MHz Software: RSA computation routine for AVR RSA 1024-bit About 5sec Data objects -

Hardware Cryptographic Support of IBM Z Systems for Openssh in RHEL 7.2 and SLES 12 SP1
Hardware cryptographic support of IBM z Systems for OpenSSH in RHEL 7.2 and SLES 12 SP1 Uwe Denneler, Harald Freudenberger, Paul Gallagher, Manfred Gnirss, Guillaume Hoareau, Arwed Tschoeke, Ingo Tuchscherer, Arthur Winterling August 18, 2016 Abstract This article summarizes our experiences with the configuration and usage of OpenSSH using hardware cryptographic support of IBM z Systems. We report our findings in the areas of performance and throughput improvement. Our positive experience indicates that you should make use of this capability when using OpenSSH. i IBM Client Center, Germany Contents 1 Introduction 1 2 Hardware cryptographic support of z Systems 1 2.1 Verification of installed LIC 3863 using the SE . .1 2.2 Verification of installed LIC 3863 using a Linux command . .2 3 Configuration of Crypto Express feature for Linux for IBM z Systems 4 4 HW- Support - Architecture for OpenSSH 4 5 Our environment 5 5.1 Installation of SLES 12 SP1 . .6 5.2 Installation of RHEL 7.2 . .9 5.3 Configuring ibmca engine . 14 6 CPACF Support for OpenSSH 15 6.1 General test using openssl speed . 15 6.2 First test with SCP of OpenSSH . 17 6.3 Test with SSH client . 19 7 Selection of cipher and MAC 21 7.1 Small comparison between SHA with CPACF support and MD5 . 21 7.2 Profiles for OpenSSH client and server . 22 7.2.1 SSH client configuration . 22 7.2.2 SSHD server configuration . 23 8 Crypto Express support for RSA with OpenSSH 24 9 Some more performance aspects 25 9.1 Choice of cipher algorithm . -

Analysis of Software Vulnerabilities Through Historical Data
Analysis of software vulnerabilities through historical data Magnus Törnquist [email protected] Department of Electrical and Information Technology Lund University Supervisor: Martin Hell Assistant Supervisor: Jonathan Sönnerup Examiner: Thomas Johansson June 29, 2017 c 2017 Printed in Sweden Tryckeriet i E-huset, Lund Popular science summary Lately there has been increasing media coverage of cyber crime, especially in re- lation to the elections in France and the United States. Every day information is being stolen from governments, businesses and private citizens. Information that can be sold, used for blackmail or for other nefarious purposes. Commonly this information is obtained through exploiting vulnerabilities in software. A vulnera- bility is essentially a bug in the code and they are very hard to avoid, especially in large complex programs. Having vulnerabilities in software is inevitable and software is everywhere: in every computer, router, webcam, mobile device and even in some coffeemakers. As long as these devices are connected an intruder has a wide variety of options on how to attack a network and the fast growth of Internet of Things (IoT) has lead to a huge amount of new devices on networks all over the world. This reality means that larger organizations have to spend a lot of time making sure all their software is updated and keeping track of potential breaches. This also means that it is very important for the software developer to maintain their code and patch any discovered vulnerabilities quickly. So how does an organization, the developer of an IoT product or a regular user choose which software to use if they are concerned about software security and is there a way to help them do it? That is what this thesis explores. -

CCE Orchestration Windows Openssh Hardening
CCE Orchestration Windows OpenSSH Hardening • CCE Orchestration Windows OpenSSH Hardening, on page 1 CCE Orchestration Windows OpenSSH Hardening Cloud Connect server establishes password-less Secure Shell (SSH) connection to Windows nodes (ICM and CVP) for Orchestration. This section describes the OpenSSH hardening for CCE Orchestration. You must make the following configuration changes in the OpenSSH service daemon configuration file located at %programdata%\ssh\sshd_config on Windows nodes and restart the OpenSSH services. Refer to the Orchestration section in the CCE Install and Upgrade Guide for details on the OpenSSH services. Settings Compliance Configuration Description Restrict SSH connection AllowUsers AllowUsers in sshd_config ensures that only localuser@CloudConnectIP the Cloud Connect server host can connect via SSH to Windows user. Note Configuration localuser@CloudConnectIP means allow the remote cloud connect node specified by Cloud Connect IP to connect via SSH to my local Windows account user. Both Publisher and Subscriber of Cloud Connect need to have an entry for this configuration. Enable DNS hostname check UseDNS yes Setting this flag to 'Yes' ensures that the server validates the hostname or IP address combination of the client (Cloud Connect server) that is connecting to it against the DNS server. Set maximum number of MaxAuthTries 3 Recommended MaxAuthTries is 3. authentication attempts CCE Orchestration Windows OpenSSH Hardening 1 CCE Orchestration Windows OpenSSH Hardening Restricting Access to OpenSSH sshd_config Settings Compliance Configuration Description Encryption Cipher HostKey By default, RSA is used as default cipher _PROGRAMDATA while establishing SSH connection between __/ssh/ssh_host_rsa_key Cloud Connect server and Windows node. #HostKey Customers can choose Cipher such as __PROGRAMDATA ECDSA. -
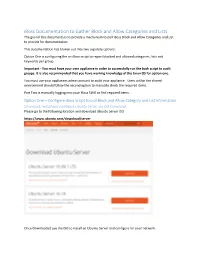
Iboss Documentation to Gather Block and Allow Categories and Lists
iBoss Documentation to Gather Block and Allow Categories and Lists. The goal of this documents is to provide a mechanism to pull iBoss Block and Allow Categories and List to provide for documentation This documentation has broken out into two separate options: Option One is configuring the an iBoss script to report blocked and allowed categories, lists and keywords per group. Important - You must have your own appliance in order to successfully run the bash script to audit groups. It is also recommended that you have working knowledge of the Linux OS for option one. You must use your appliances admin account to audit your appliance. Users within the shared environment should follow the second option to manually check the required items. Part Two is manually logging into your iBoss SWG to find required items. Option One – Configure iBoss Script to pull Block and Allow Category and List Information Download, Install and Configure Ubuntu Server via ISO Download Please go to the following location and download Ubuntu Server ISO https://www.ubuntu.com/download/server Once Downloaded use the ISO to install an Ubuntu Server and configure for your network. Once you are at a running Ubuntu Server Prompt You will need to login to the Server and Install VIM and Curl Login to the Server Install Curl and VIM Sudo apt-get install vim curl openssh-server -y Create the script files Once install is completed use VIM to create a file called categoryReport.sh Vim categoryReport.sh Copy and paste the script found in categoryReport.sh to the newly created file Use VIM to create a file called categoryKey Copy and paste the contents of the category key document to the newly created file. -

Openbsd Project Status Update Mike Belopuhov, [email protected] What’S New?
OpenBSD project status update Mike Belopuhov, [email protected] What's New? 5.9 release highlights: I i386 kernel W^X I pledge(2) I 802.11n I Xen domU I UTF-8 I 32 and 64 bit EFI on amd64 I Network stack MP improvements I New hardware support and driver updates pledge(2) 453 out of 707 base system binaries were adapted to use pledge. 14 ports now use pledge(2): some decompression tools, mutt, some pdf tools, chromium/iridium, and the i3 window manager. Various bugs exposed by pledge(2) were corrected. EFI for amd64 32 and 64 bit EFI support. GPT is enabled by default. Improved GPT support in fdisk(8) including full interactive editing. Installing to a disk partitioned with a GPT is now supported. efifb(4) driver for EFI frame buffer. Driver updates Initial support for Intel Bay Trail and Broadwell graphics. New drivers for HID-over-i2c keyboards, mice and multitouch touchpads. Initial support for hardware reduced ACPI added to acpi(4). SDHC driver can be discovered and attached by ACPI. Intel Skylake integrated NIC with i219 PHY support. Access to IPMI has been provided to userspace programs. Networking stack improvements Several Ethernet drivers are running Rx and Tx processing w/o taking the biglock. BPF now runs w/o the biglock. New intr barrier(9), if get(9) and if put(9) interfaces. etherip(4) for tunnelling Ethernet frames across IP[46] networks using RFC 3378 EtherIP encapsulation. pair(4) for creating paired virtual Ethernet interfaces. tap(4) split up from tun(4).