Free Books: Hathi Trust Cataloging Records
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Using Digital Libraries: Search Strategies for Family Historians
Using Digital Libraries: Search Strategies for Family Historians Elizabeth M. O’Neal PO Box 1259, Lompoc, CA 93436 [email protected] https://www.swangenealogy.net https://mydescendantsancestors.com Looking for books about your family history? You may be able to find them without leaving the comfort of your home! Millions of books have already been digitized and are free to use, as well as download to your personal library. Learn where to find the best digital book collections, how to strategically search them, and how to save your finds to your computer or cloud storage for later reference. Digital Libraries – Family History FamilySearch Digital Library - https://www.familysearch.org/library/books The newly-updated FamilySearch Digital Library contains more than 440,000 digitized genealogy and family history books and publications from the archives of family history libraries such as the Allen County Public Library, the Family History Library in Salt Lake City, and others. Included in the collection are family histories, county and local histories, genealogy magazines and how-to books, gazetteers, medieval histories and pedigrees. While some books are only viewable in a Family History Center, many can be viewed from – as well as downloaded to – your home computer. To access the FamilySearch Digital Library, visit FamilySearch.org, and click “Search” in the top menu. In the drop-down menu, select “Books.” On the home page of the digital library, you will see a simple search bar. Here, you can type in a surname, historical events, groups of people, or names of places. A search will cover every word of text. -

The Project Gutenberg Ebook of Things to Make, by Archibald Williams This Ebook Is for the Use of Anyone Anywhere at No Cost
The Project Gutenberg EBook of Things To Make, by Archibald Williams This eBook is for the use of anyone anywhere at no cost and with almost no restrictions whatsoever. You may copy it, give it away or re-use it under the terms of the Project Gutenberg License included with this eBook or online at www.gutenberg.net Title: Things To Make Author: Archibald Williams Release Date: January 11, 2005 [EBook #14664] Language: English Character set encoding: ASCII *** START OF THIS PROJECT GUTENBERG EBOOK THINGS TO MAKE *** Produced by Don Kostuch Transcriber's Note: If the pdf version of the book is viewed using facing pages with even numbered pages on the left, you will see a close approximation of the original book. Notations of the form "(1,650) 2" appear at the bottom of some pages; they are probably printer's references for assembling to book. The text only version is of limited use because of the many figures used. I recommend the pdf or rtf versions. Some of the projects should be approached with care since they involve corrosive or explosive chemicals, electricity and steam boilers. Do not use lead solder, particularly on cooking utensils. Whether you simply want to travel back into the mind of a young boy at the beginning of the twentieth century, or want to try your hand at some interesting projects in carpentry, machinery, kites and many other areas, have fun. The following four pages have definitions of unusual (to me) terms used frequently in the text. Terms Batten - Narrow strip of wood. -

Downloading Ebooks from Project Gutenberg to Your Computer, Kindle, Nook, Or Ipad
Downloading eBooks from Project Gutenberg to Your Computer, Kindle, Nook, or iPad Downloading to Your Computer Downloading to Your iPad Downloading to Your Kindle Downloading to Your Nook Downloading to Your Computer Click the Download this ebook to your ereader, tablet PC, or computer link. This will take you to the download page for the current title. Select “EPUB” format. A window will pop up with – “Save file” – click “OK,” choose an appropriate place to save, and click “Save.” This ebook format must be viewed using Adobe Digital Editions. Click here to download. Enjoy! Downloading to Your iPad Click the Download this ebook to your ereader, tablet PC, or computer link. This will take you to the download page for the current title. Click on “EPUB” format. Click “Open in iBooks.” The ebook will automatically download and open in iBooks. Enjoy! Downloading to Your Kindle Using USB Cord Using Email Click the Download this ebook to your ereader, Click the Download this ebook to your ereader, tablet PC, or computer link. This will take you to the tablet PC, or computer link. This will take you to the download page for the current title. download page for the current title. Use the “Kindle” format. Attach the USB cord to your computer and Kindle. A window will pop up with – “Save file” – click “OK,” Use the “Kindle” format. choose an appropriate place to save, and click A window will pop up with – “Save file” – click “OK,” “Save.” This will save your selection to your choose an appropriate place to save, and click computer, and it can then be emailed to your “Save.” This will save your selection to your Kindle. -

Spring 2015 Tech Workshop Project Gutenberg.Pdf
Amazon Kindle Getting Started With You will need to first download the file to your comput- er, then transfer it over to your device. Please refer to your manual for more in depth instructions. Find the title you would like to read on your com- puter and select the KINDLE format. Save the file to your computer and connect your Kindle device to your computer. Transfer the file over to your device. (Please refer to your Kindle manual for more information) Once you have finished transferring the E-Book, it should appear in your library. Nook E-Reader and Nook Tablets Similar to the Amazon Kindle, you will need to transfer the E-Book from your computer to your device. Find the title you would like to read on your com- puter and select the EPUB format. Save the file to your computer and connect your Nook device to your computer. Transfer the file over to your device. (Please refer to your Nook manual for more information) Once you have finished transferring the e-book, it should appear in your device’s library. For nook tablets you can download from directly from Visit Project Gutenberg at: www.gutenberg.org Project Gutenberg: Or on Your Mobile Device at: m.gutenberg.org Navigate to the title you want o read on your Nook Workshop Taught by: Tablet web browser and select EPUB. 53 E. 79th Street NY, NY 10075 Kathleen Fox Simen Kot It should download automatically and be added (212)288-6900 Senior Circulation Page Circulation Assistant your device’s Library. -

The Gutenberg-Hathitrust Parallel Corpus: a Real-World Dataset for Noise Investigation in Uncorrected OCR Texts
The Gutenberg-HathiTrust Parallel Corpus: A Real-World Dataset for Noise Investigation in Uncorrected OCR Texts Ming Jiang1, Yuerong Hu2, Glen Worthey2[0000−0003−2785−0040], Ryan C. Dubnicek2[0000−0001−7153−7030], Boris Capitanu1, Deren Kudeki2, and J. Stephen Downie2[0000−0001−9784−5090] 1 Illinois Informatics Institute, University of Illinois at Urbana-Champaign 2 School of Information Sciences, University of Illinois at Urbana-Champaign fmjiang17|yuerong2|gworthey|rdubnic2|capitanu|dkudeki|[email protected] Abstract. This paper proposes large-scale parallel corpora of English- language publications for exploring the effects of optical character recog- nition (OCR) errors in the scanned text of digitized library collections on various corpus-based research. We collected data from: (1) Project Gutenberg (Gutenberg) for a human-proofread clean corpus; and, (2) HathiTrust Digital Library (HathiTrust) for an uncorrected OCR-impacted corpus. Our data is parallel regarding the content. So far as we know, this is the first large-scale benchmark dataset intended to evaluate the effects of text noise in digital libraries. In total, we collected and aligned 19,049 pairs of uncorrected OCR-impacted and human-proofread books in six domains published from 1780 to 1993. Keywords: Parallel Text Dataset · Optical Character Recognition · Digital Library · Digital Humanities · Data Curation 1 Introduction The rapid growth of large-scale curated datasets in digital libraries (DL) has made them an essential source for computational research among various schol- arly communities, especially in digital humanities (DH) and cultural analytics (CA). Particularly, recent studies in DH and CA have popularly employed state- of-the-art natural language processing (NLP) techniques for corpus analysis. -

Introduction to Ebooks Handout
INTRODUCTION TO eBOOKS GETTING STARTED PAGE 02 Prerequisites What You Will Learn INTRODUCTION PAGE 03 What is an eBook? What is an eReader? eBOOKS AT ORANGE COUNTY PUBLIC LIBRARIES PAGE 06 Lending policies Accessing Overdrive NAVIGATING THE OVERDRIVE WEBSITE PAGE 08 Searching and Browsing Understanding eBook Records Using the Patron Account DOWNLOADING eBOOKS PAGE 14 For Kindles For iPad/iPod/iPhone, Android Phones & Tablets For Nooks For Sony Readers OTHER SOURCES OF eBOOKS PAGE 20 View our full schedule, handouts, and additional tutorials on our website: cws.web.unc.edu Last Updated November 2014 2 WHAT YOU WILL LEARN Prerequisites: It is assumed for this class that the user is comfortable with basic computer operations as well as basic Internet experience. • This workshop is intended for new eBook and eReader users and/or those who want to learn about eBooks available through Orange County Public Library via Overdrive. • Please let the instructor know if you have any questions or concerns prior to starting class. What You Will Learn Learn to search Familiarize you Learn about Download library and use the with eBooks different eBook eBooks to your Overdrive readers eReader! website 3 INTRODUCTION What Are eBooks? • Short for electronic book, a book-length publication in digital form • Can be read on a computer or transferred to a device (Nook, Kindle, iPhone, etc.) What Is an eBook Reader? • Also known as eReaders, they come in many shapes and sizes. Amazon Kindle Barnes & Noble Nook Apple iPod/iPhone/iPad Sony eReader 4 Features and Specifications to Consider: • eInk vs. LCD o eInk looks like the page of a book and is not backlighted which makes it easier to read outside but requires a reading light to read in the dark. -

Digital Access to Materials
Digital Access to Research Materials Patrons are able to access digital materials via the following services, while the Library is closed: Jacob Edwards Library: https://www.jacobedwardslibrary.org/ Local History & Genealogy: https://www.jacobedwardslibrary.org/genealogy.htm LEA-Library E-books and Audio-books: Massachusetts Library Networks are collaborating to bring you LEA, a new and innovative way to gain access to more eBooks and audiobooks. Powered by OverDrive, LEA makes it possible for you to borrow eContent in all Networks regardless of your home library: https://libraries.state.ma.us/pages/LEA OverDrive Digital Catalog: read e-books, audio-books, magazines, and watch video: https://cwmars.overdrive.com/ Project Gutenberg: a library of over 60,000 free eBooks. You will find the world's great literature here, with focus on older works for which U.S. copyright has expired: https://www.gutenberg.org/ Internet Archive: a non-profit library of millions of free books, movies, software, music, websites, and more: https://archive.org/ HathiTrust Digital Library: HathiTrust is a partnership of academic & research institutions, offering a collection of millions of titles digitized from libraries around the world: https://www.hathitrust.org/ Google Scholar: Google Scholar provides a simple way to broadly search for scholarly literature: https://scholar.google.com/ Boston Public Library e-card: https://www.bpl.org/ecard/ Digital Commonwealth: Explore historical collections from libraries, museums, and archives across Massachusetts: https://www.digitalcommonwealth.org/ DPLA: Digital Public Library of America: Discover 36,807,992 images, texts, videos, and sounds from across the United States: https://dp.la/ Europeana: Explore inspiring cultural heritage from European museums, galleries, libraries and archives: https://www.europeana.eu/portal/en . -

Web Sites for Electronic Books on the Kindle and Audio Books
India International Centre Library WEB SITES FOR ELECTRONIC BOOKS ON THE KINDLE AND AUDIO BOOKS In accordance with the decision of the Library Committee meeting held on 13th May 2011, placed herewith important sites which has large number of audio and Kindle based e-text. Members are requested to go through the sites and suggest the books which can be downloaded to be read using Kindle and can be used as audio books. Project Gutenberg Books on Kindle : Project Gutenberg is the first and largest single collection of free electronic books, or eBooks. Michael Hart, founder of Project Gutenberg, invented eBooks in 1971 and continues to inspire the creation of eBooks and related technologies today. Project Gutenberg offers over 36,000 free eBooks to download to your PC, Kindle, iPad, iPhone, Android or other portable device. Feedbooks on Kindle : Feedbooks is a cloud publishing and distribution service, connected to a large ecosystem of reading systems and social networks. Every month, Feedbooks distributes millions of books to an increasingly growing community of readers. Books from Amazon on Kindle : 7000 books containing fiction and non-fiction; classical and non- classical on MOBI Format which can be read on Kindle from Amazon. Top 100 Books on Kindle from United States: Top 100 books from US on Kindle from Amazon. Kindle Books from Manybooks: has large number of books that can be read on Kindle. Few Books on Google ebookstore : Few Books on Google ebookstore. The Open Library: The Free Books can be searched by Author, Title or by Subjects. Many of the books are available in MOBI Format that can be read on Kindle. -

Project Gutenberg Canada, ( a Website Distributing Free Digital Editions of Books in the Canadian Public Domain
20 January 2011 1 of 7 Protecting and Enhancing Canada's Public Domain A brief to the Legislative Committee on Bill C-32 by Mark Akrigg, founder of Project Gutenberg Canada, (http://gutenberg.ca/) a website distributing free digital editions of books in the Canadian Public Domain. Executive Summary Canada's Public Domain is at risk, and needs the active protection of the Parliament of Canada. The author of this brief, Dr. Mark Akrigg, makes two major recommendations: 1. A "Safe Harbour" provision for works more than 75 years old where the life dates of the authors are not known. This has long been needed, and will be absolutely essential if copyright terms for photographs are extended, as currently proposed in Bill C-32. 2. No extensions of copyright durations. Specific language is proposed for related amendments to Bill C-32. These amendments are intended to be concise, straightforward, and uncontroversial. 20 January 2011 2 of 7 Protecting and Enhancing Canada's Public Domain A brief to the Legislative Committee on Bill C-32 by Mark Akrigg, founder of Project Gutenberg Canada, (http://gutenberg.ca/) a website distributing free digital editions of books in the Canadian Public Domain. An executive summary is provided on page 1 of this brief. Background to this Brief I am the founder of Project Gutenberg Canada, which was launched on Canada Day 2007, with the mission of providing free high-quality digital editions of books in the Public Domain. We give a place of honour in our collection to Canadian history and literature, in English and French. -
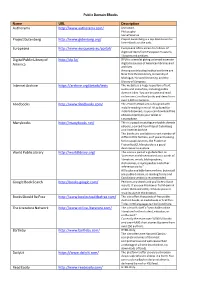
Public Domain Ebooks Name URL Description Authorama
Public Domain EBooks Name URL Description Authorama http://www.authorama.com/ Literature, Phi l osophy Social Science Project Gutenberg http://www.gutenberg.org/ Project Gutenberg is a top destination for free eBooks on the web. Europeana http://www.europeana.eu/portal/ Europeana offers access to millions of digitized items from European museums, libraries and archives. Digital Public Library of http://dp.la/ DPLA is aimed at giving universal access to America digital resources of American libraries and archives. Among contributing institutions there are New York Public Library, University of Michigan, Harvard University, and the LIbrary of Congress. Internet Archive https://archive.org/details/texts The website is a huge repository of text, audio and video files, including public domain titles. You can browse and read online over 5 million books and items from over 1,500 collections. Feedbooks http://www.feedbooks.com/ This French eBook site is designed with mobile reading in mind. It’s tailored for mobile browsers, so you can download free eBooks directly to your tablet or s martphone. Manybooks http://manybooks.net/ This is a popular catalogue of public domain eBooks, s ourced from Project Gutenberg and Internet Archive. The books are available in a vast number of different file formats, so if you are looking for less popular ones, like Plucker or Fi cti onBook2, Ma nybooks is a good destination to explore. World Public Library http://worldlibrary.org/ The site is a part of a global effort to “preserve and disseminate classic works of literature, serials, bibliographies, dictionaries, encyclopaedias and other reference works.” All books available here are free, but not all are public domain, so reading Terms and Conditions s ection is recommended. -

Ebooks & Audiobooks
eBooks & Audiobooks What is an eBook? eBooks are electronic versions of books. They can be downloaded from many websites and their text can be displayed on a computer screen, on eBook readers and other mobile devices like smart phones. What is an audiobook? Audiobooks are recorded readings of books. They may be available on CDs and as downloadable files (MP3 or WMA format) that can be played on a computer or portable listening device like an iPod or MP3 player. Downloadable Library eBooks & Audiobooks and “DRM” The library has partnered with a company called OverDrive to make free downloadable eBooks and Audiobooks available to members of Halifax Public Libraries. They can be “checked out” for a limited time just like paper books but you’ll never get a fine because the books expire automatically when your loan period ends! They just stop working on your computer/device. Publishers can’t afford to give books away for free, so they protect their copyright by placing restrictions on the use and transfer of eBooks and Audiobooks. By adding “Digital Rights Management” (DRM) to the book, they prevent users from copying and saving the books in ways that would violate copyright laws. Because of the DRM on library eBooks and Audiobooks you will need special software installed on your computer to use them and they may not be compatible with all devices. What You Need to Get Started eBooks: Adobe Digital Editions Audiobooks OverDrive Windows Media Media Console Player 9 or higher Computer with Library Card Internet Connection Software eBooks Page 1 of 14 www.halifaxpubliclibraries.ca Updated: December 2010 What if I Have a Portable Device? You can listen to Audiobooks and read eBooks on your computer, but you might wish to transfer them to portable devices like e-readers, smart phones, iPods or mp3 players. -

Using Google Books, Hathitrust, and Other Online Book Sites
MARITIME HISTORY ON THE INTERNET by Peter McCracken Using Google Books, HathiTrust, and other Online Book Sites oogle's goal to digitize the world's libraries is one of its typical of their 53,000 titles are out of copyright. HathiTrust (https:// "shoot-for-the-moon" projects, which seem nearly impossible www.hathitrust.org) is a very large compiler of digital titles from Guntil they turn out to be well on their way to reaching the many sources, including Google Books, the Internet Archive, goal. Its impact is already immeasurable, and will continue to and Microsoft. HathiTrust has a number of particularly valuable grow. Nevertheless, the project is not without its challenges, and features: you can choose to either search the full text of the books there is much one should know about the process and alternatives. available, or search the catalog that describes the books. If you Begun in secret in 2002 and launched publically in 2004, the want to look for a broad topic, like "Australian schooners," you concept was something that Google's cofounders always planned might try searching the catalog to locate books on the subj ect. to pursue. The project had both altruistic and commercial aims: If you want to look something more specific, then searching the it has always had a goal of making out-of-prim resources available full text for, say, "Wollongong schooners" might be better. You to anyone, but also has involved direct work with publishers to can use AND and OR terms when searching, and * as a wildcard earn revenue when making publishers' content findable, if not ac (a search for "sail*" will return "sail," "sails," "sailors," "sailing," cessible.