Why Does the Cloud Stop Computing? Lessons from Hundreds of Service Outages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Big Data for Measuring the Information Society
BIG DATA FOR MEASURING THE INFORMATION SOCIETY COUNTRY REPORT SWEDEN 1 / 44 Acknowledgments: The big data analysis contained in this report was carried out by Ivan Vallejo Vall, Market Analyst at the ICT Data and Statistics Division within the Telecommunication Development Bureau of ITU. Fredrik Eriksson, Statistician in the same division, made substantial contributions to the analysis. The Internet Foundation in Sweden (IIS) provided the data used in this report, as well as insightful information on the methodology of the data collection. IIS’s cooperation is duly acknowledged. 2 / 44 CONTENTS Contents ........................................................................................................................................................ 3 1. Background and Context ........................................................................................................................... 4 1.1. Project Description ............................................................................................................................. 4 1.2. Pilot Country Context ......................................................................................................................... 4 1.3. Stakeholders in the pilot and project timeline .................................................................................. 6 2. Getting Access to the Data: Procedures, Legal Documents and Challenges ............................................ 7 2.1. Legal Documents and Challenges ..................................................................................................... -

Padma Vibhushan Shri Dhirubhai H. Ambani (28Th December, 1932 - 6Th July, 2002) Reliance Group - Founder and Visionary Profile
Communications Annual Report 2015-16 Padma Vibhushan Shri Dhirubhai H. Ambani (28th December, 1932 - 6th July, 2002) Reliance Group - Founder and Visionary Profile Reliance Communications Limited is the flagship Company of Reliance Group, one of the leading business houses in India. Reliance Communications is India’s foremost and truly integrated telecommunications service provider. The Company has a customer base of over 111 million including over 2.6 million individual overseas retail customers. Reliance Communications corporate clientele includes over 39,000 Indian and multinational corporations including small and medium enterprises and over 290 global, regional and domestic carriers. Reliance Communications has established a pan-India, next generation, integrated (wireless and wireline), convergent (voice, data and video) digital network that is capable of supporting best-of-class services spanning the entire communications value chain, covering over 21,000 cities and towns and over 400,000 villages. Reliance Communications owns and operates the world’s largest next generation IP enabled connectivity infrastructure, comprising over 280,000 kilometers of fibre optic cable systems in India, USA, Europe, Middle East and the Asia Pacific region. Mission: Excellence in Communication Arena To attain global best practices and become a world-class communication service provider – guided by its purpose to move towards greater degree of sophistication and maturity. To work with vigour, dedication and innovation to achieve excellence in service, quality, reliability, safety and customer care as the ultimate goal. To earn the trust and confidence of all stakeholders, exceeding their expectations and make the Company a respected household name. To consistently achieve high growth with the highest levels of productivity. -

Relilance Navi Mumbai - 400 710, India +91 22 3038 6286 Fax: +91 22 3037 6622
Reliance Communications Limited Dhirubhai Ambani Knowledge City Tel: +91 2230373333 ReLIlANce Navi Mumbai - 400 710, India +91 22 3038 6286 Fax: +91 22 3037 6622 www.rcom.co.in September 18, 2019 The General Manager The Manager Corporate Relationship Department National Stock Exchange of India Ltd. SSE Limited Exchange Plaza, C/1, Block G Phiroze Jeejeebhoy Towers Bandra - Kurla Complex, Bandra (East) Dalal Street, Fort, Mumbai 400 051 Mumbai 400 001 Fax No.: 26598237/38/8347/48/ Fax No.: 22722037/39/41/61/3121/3719 66418124/25/26 SSE Scrip Code: 532712 NSE Symbol: RCOM Dear Sir, Sub: Press Release In continuation with our letter dated September 17, 2019, we enclose herewith the Press Release issued by Global Cloud Xchange (HGCX"), Bermuda, which is self explanatory. Kindly inform your members accordingly. Thanking you. Yours faithfully, For Reliance Communicqtions Limited ~&vu-P+cr Rakesh Gupta Company Secretary Encl.:- as above. Registered Office: Reliance Communications Limited. H Block, 1st Floor, Dhirubhai Ambani Knowledge City, Navi Mumbai - 400 710 CIN No.: L45309MH2004PLC147531 MEDIA RELEASE NEW Global Cloud Xchange Announces Plan to Secure Financial Future Company initiates voluntary, pre-packaged Chapter 11 restructuring with support from more than 75 percent of lenders Proposed plan of reorganization positions the Company to aggressively pursue growth and development with $150 million in bond debt reduction, new working capital financing and strong new ownership NEW YORK, 15 September 2019: Global Cloud Xchange (“GCX” or the “Company”) today announced a pre-packaged Plan of Reorganization (the “Plan”) that will support its long-term growth and development by reducing bond debt by $150 million, providing a permanent capital structure that includes working capital facility and transitioning the business to new ownership. -

Trade Marks Journal No: 1795 , 01/05/2017 Class 28
Trade Marks Journal No: 1795 , 01/05/2017 Class 28 3378457 25/05/2016 [International Registration No. : 1303365] Hunter, Jeff 15478 Sylvan Street Van Nuys CA 91411 United States of America Coker, Kristina 15478 Sylvan Street Van Nuys CA 91411 United States of America Proposed to be Used IR DIVISION Athletic equipment, namely, guards for protecting the hand and wrist. 4801 Trade Marks Journal No: 1795 , 01/05/2017 Class 29 3363961 21/12/2015 [International Registration No. : 1301504] Laixishi Shunxiang Peanut Products Co., Ltd. Zhanjiahui Village, Yuanshang Town, Laixi City, Qingdao City Shandong Province China Proposed to be Used IR DIVISION Processed sesame; processed manufactured bean; processed hazelnuts; processed pine nut; potato crisps; peanut butter; refined nuts; nuts, prepared; processed melon seeds. 4802 Trade Marks Journal No: 1795 , 01/05/2017 Class 29 3387243 16/03/2016 [International Registration No. : 1305603] FUJIAN HAISHAN FOODS CO., LTD. Xiaye Village, Chengxi, Longhai Fujian China Proposed to be Used IR DIVISION Charcuterie; fish (food products made from -); fruits, tinned [canned (Am.)]; meat, tinned [canned (Am.)]; seafoods, tinned [canned (Am.)]; vegetables, tinned [canned (Am.)]; vegetables, preserved; pickled vegetables. 4803 Trade Marks Journal No: 1795 , 01/05/2017 Class 29 3387514 20/03/2016 [International Registration No. : 1305990] Qingdao Chengyang Vegetables and Aquatic Products Wholesale Market Co., Ltd. Chengyang Village, Chengyang District, Qingdao City Shandong Province China Proposed to be Used IR DIVISION Meat; shellfish, not live; shrimps, not live; frozen fruits; vegetables, preserved; milk products; edible oils; jellies for food; vegetable salads. 4804 Trade Marks Journal No: 1795 , 01/05/2017 Class 30 2910059 15/09/2014 [International Registration No. -

Before the STATE of NEW YORK PUBLIC SERVICE COMMISSION
Before the STATE OF NEW YORK PUBLIC SERVICE COMMISSION Joint Petition of GCX LIMITED (DEBTOR-IN-POSSESSION), Matter/Case No. Transferor VANCO US, LLC, Authority Holder and GCX LIMITED (REORGANIZED), Transferee for Approval (1) to assign CPCN held by Authority Holder to Vanco US, LLC (Reorganized), (2) to Transfer Indirect Ownership of Vanco US, LLC (Reorganized) and (3) for Vanco US, LLC (Reorganized) to Participate in Certain Financing Arrangements JOINT PETITION GCX Limited (Debtor-in-Possession) (“GCX Limited DIP” or “Transferor”); Vanco US, LLC (“Authority Holder”); and GCX Limited (Reorganized) ( “Reorganized GCX Limited” or “Transferee”) (collectively, “Petitioners”) hereby respectfully request that the New York State Public Service Commission (the “Commission”) grant the requisite authority and approvals, to the extent required, under the New York Public Service Law Sections 99, 100 and 101 and the regulations of the Commission: (1) to transfer indirect ownership and control of the Authority Holder from Transferor to Transferee through the proposed acquisition of Transferor’s assets by Transferee pursuant to the Joint Prepackaged Chapter 11 Plan of GCX Limited and Its Debtor Affiliates;1 (2) for the Authority Holder, only upon completion of the Proposed Transaction (as defined below), to participate in certain financing arrangements. In support of this Petition, Petitioners provide the following information: I. PRELIMINARY STATEMENT On September 15, 2019, the Authority Holder, along with its parent company, VNO Direct Limited, -

Winners Book 2
TRANSFORM 2018 WINNERS BOOK WELCOME 04 The judges 06 The winners CONTENT 08 Best use of a visual property 09 Best brand architecture solution Best use of copy style or tone of voice 10 Best brand experience 12 Best use of packaging 13 Best wayfinding or signage 14 Best use of audio branding 15 Best use of typography 16 Fortune favours the brave PROCESS One of the most rewarding things to see 18 Best external stakeholder relations during in Transform magazine is a brand project a brand development project that takes into account all the various 19 Best internal communications during a brand development project touchpoints, platforms and media that could contribute to a better communication of 20 Best implementation of a brand development project a brand’s positioning and purpose. At this 21 Best localisation of an international brand year’s Transform Awards Asia-Pacific, that 23 Localisation is the key to unlocking relevance and driving growth has been true of the majority of projects considered by the judges. STRATEGY The premiere winners exhibit this in spades. 24 Best creative strategy The ‘Best overall visual identity’ winner for 25 Best brand evolution 2019, the Chongqing Industrial Museum, explored its positioning through a shift 26 Best strategic or creative development of a new brand in tone of voice and the introduction of 27 Best naming strategy a beloved mascot that helps the brand communicate visually and physically. TYPE The ‘Grand prix’ winner Harneys put 28 Best corporate rebrand following a merger or acquisition repositioning at the core of its brand update. -

October 4, 2019 by ELECTRONIC FILING Ms. Marlene H
October 4, 2019 BY ELECTRONIC FILING Ms. Marlene H. Dortch Secretary Federal Communications Commission 445 12th Street, S.W. Washington, D.C. 20554 Re: Pro Forma Assignment of Domestic Section 214 Authorization and International Section 214 Authorization, File No. ITC-214-20070703-00262, in Connection with Chapter 11 Filings Under the U.S. Bankruptcy Code Dear Ms. Dortch: Pursuant to 47 U.S.C. § 214 and 47 C.F.R. §§ 63.03(d)(2) and 63.24(g), the undersigned hereby notify the Commission of the pro forma assignment of the domestic and international Section 214 authorizations held by Vanco US, LLC, a Delaware limited liability company (FRN 0020057881), from Vanco US, LLC (“Vanco US”) to Vanco US, LLC, Debtor-in-Possession (“Vanco US DIP”) (FRN 0028867695) (“Assignment”) in connection with the pending bankruptcy of Vanco DIP and its affiliates and of other pro forma transactions discovered in preparation for that bankruptcy. Vanco US DIP is a provider of domestic and international private line services, with authorization to provide global or limited global facilities-based and resale service. Vanco US and certain of Vanco US affiliates filed for bankruptcy protection under chapter 11 and, concurrently therewith, filed that certain Joint Prepackaged Chapter 11 Plan of GCX Limited as Debtor and Its Debtor Affiliates in the United States Bankruptcy Court for the District of Delaware on September 15, 2019 (the “Plan”). During the pendency of the Chapter 11 proceeding, Mr. Michael Katzenstein, Vanco US DIP’s Chief Restructuring Officer will oversee Vanco US DIP's management and operations.1 Mr. Katzenstein has extensive experience in restructuring in the telecommunications sector. -

Big Food, Big Tech, and the Global Childhood Obesity Pandemic
Big Food, Big Tech, and the Global Childhood Obesity Pandemic AUTHORS: Jeff Chester, MSW Kathryn C. Montgomery, PhD MAY 2021 Katharina Kopp, PhD Big Food, Big Tech, and the Global Childhood Obesity Pandemic | 2 Acknowledgments This report is part of a unique partnership of four organizations—Berkeley Media Studies Group, Color of Change, UnidosUS, and Center for Digital Democracy—working together to promote policies to ensure health equity for youth, communities of color, and other at-risk populations. The partnership is funded through a generous grant from the Robert Wood Johnson Foundation, which has also supported CDD’s ongoing research to investigate how contemporary digital marketing and Big Data practices impact young people’s health. We are very grateful to the Foundation’s commitment to these efforts. We also want to thank the following individuals and organizations who helped us with the writing and publication of the report: Jamie Bussel, Lori Dorfman, Gary O. Larson, and Burness Communications. Big Food, Big Tech, and the Global Childhood Obesity Pandemic INTRODUCTION | 3 INTRODUCTION devastating. For decades, there has been a steady and disturbing rise in The coronavirus pandemic triggered a dramatic obesity among children and youth. For example, obesity rates among increase in online use. With tens of millions of families teens ages 12 to 19 have quadrupled remaining in their homes, people turned to the internet since the 1980s. According to the most recent public health data, 19.3 to order food, stay up with the fast-breaking news, percent of all youth between the ages and engage with family and friends. -

Connections Open the World. Open Access
PTC MEMBERSHIP Recognized as PTC, we are the global non-profit membership organization promoting the advancement of information and communication technologies (ICT) in the Pacific Rim, the most dynamic geography of the world, spanning over 40 nations. As a membership organization, PTC mobilizes global leaders in telecommunications and information technology industries so they can drive the development and deployment of ICT across the Pacific region and beyond. As a non-profit, PTC is dedicated to educating professionals, while sparking and guiding conversations and collaborations, setting the stage for the deployment and growth of ICT, throughout the region and beyond. As a global organization, PTC engages the broadest community of professionals, organizations, technologists, researchers, and influencers, who together ensure progress in our industry while improving the quality of life in Pacific Rim communities. CONNECTIONS OPEN THE WORLD. OPEN ACCESS. OPEN MINDS. OPEN DISCUSSIONS. OPEN MARKETS. WHAT TO EXPECT TELECOM PTC is a rich community, active every day of the year. Helping Mobile, wireline, subsea, satellite, and solar-powered drones. our members innovate and grow advances in our industry. Helping nations develop infrastructure that changes lives. ICT IT, cloud, edge computing, the Internet of Things, cybersecurity, privacy, and Business strategies, such as moving beyond ping, power, and connected applications, products, services, and solutions. pipe, to profitably participate in the exploding digital economy Business and partner development between startups, carriers, BUSINESS equipment and service providers, integrators, and academic institutions Theory, strategy, and execution for commercial profitability, development of innovative ideas, the role of government regulatory bodies, and the achievement Emerging technologies, such as SDN/NFV and optical satellites of societal goals. -
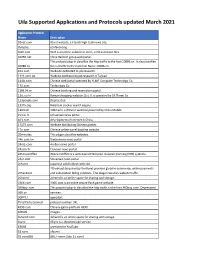
3000 Applications
Uila Supported Applications and Protocols updated March 2021 Application Protocol Name Description 01net.com 05001net plus website, is a Japanese a French embedded high-tech smartphonenews site. application dedicated to audio- 050 plus conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also classifies 10086.cn the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese cloudweb portal storing operated system byof theYLMF 115 Computer website. TechnologyIt is operated Co. by YLMF Computer 115.com Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr ThisKorean protocol shopping plug-in website classifies 11st. the It ishttp operated traffic toby the SK hostPlanet 123people.com. Co. 123people.com Deprecated. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt ChineseLithuanian web news portal portal 163. It is operated by NetEase, a company which pioneered the 163.com development of Internet in China. 17173.com Website distributing Chinese games. 17u.com 20Chinese minutes online is a travelfree, daily booking newspaper website. available in France, Spain and Switzerland. 20minutes This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Checkout (acquired by Verifone) provides global e-commerce, online payments 2Checkout and subscription billing solutions. -

Translation FORM 56-1 Dated December 31, 2016 CS Loxinfo
Translation FORM 56-1 Dated December 31, 2016 CS LoxInfo Public Company Limited (CSL) CONTENTS Page Part I Business Operations 1. Policy and Business Overview 1 - 10 2. Natural of Business Operations 11 - 36 3. Risk Factors 37 - 40 4. Properties and Equipment Used in Business Operations 41 - 43 5. Legal Dispute 44 6. General Information of the Company and Others Related Information 45 - 56 Part II Management and Corporate Governance 7. Capital Structure and Shareholders 57 - 58 8. Management Structure 59 - 76 9. Corporate Governance 77 - 119 10. Corporate Social Responsibilities 120 11. Internal Control and Risk Management 121 - 124 12. Related Transactions 125 - 134 Part III Financial Positions and Operating Results 13. Financial Highlight 135 - 147 14. Management’s Discussion and Analysis 148 - 154 Certification of the Correctness of the Information Attachment Attachment 1: - Details of Directors, Management Team and Company Secretary - Duties and Responsibilities of the Company Secretary - Details of Directors and Management Team in Company, Holding Company, Subsidiary and Other Related Parties (Directly and Indirectly) Attachment 2: Details of Directors of the Company's Subsidiaries Attachment 3: Details of the Head of Internal Audit and Head of Compliance Unit Attachment 4: - Independent Directors and Audit Committee’s Opinion regarding the Connected Transactions - Audit Committee Report, Remuneration Committee Report, Nomination and Corporate Governance Committee Report, Executive Committee Report - Board of Directors’ responsibility for Financial Reporting CS LOXINFO PLC. FORM 56-1 FOR YEAR 2016 1. Policy and Business Overview 1.1 Vision and Mission Vision Strive towards long - term sustainability. By continuous development and innovation, and with social responsibility. -

Tackling the Illegal Trade in the Digital World
Cyber-laundering: dirty money digitally laundered- Tackling the illegal trade in the Digital world Graham Butler Special Presentation to the Academy of European Law Budapest – March 2016 Co-funded by the Justice Programme of the European Union 2014-2020 Graham Butler – Chairman Bitek Group of Companies © 2016 Tackling the illegal trade in the Digital world Supporting the Cyber-Security agenda ERA (Academy of European Law) – Lisbon / Trier / Sofia / Brussels Address: Threats to Financial Systems – VoIP, lawful intercept, money laundering CTO (Commonwealth Telecommunications Organisation) London Address: Working group on strategic development for 2016-2020 ITU High level Experts Group – Cybersecurity Agenda – Geneva (United Nations) Address: VoIP and P2P Security – Lawful Intercept ENFSC (European Network Forensic and Security Conference) - Maastricht Address: Risks of P2P in Corporate Networks CTITF (Counter Terrorism Implementation Taskforce) - Seattle Address: Terrorist use of encrypted VoIP/P2P protocols - Skype Norwegian Police Investigation Section - Oslo Address: Next Generation Networks – VoIP Security (fixed and mobile networks) IGF (Internet Governance Forum) – Sharm El Sheikh, Egypt Address: Threats to Carrier Revenues and Government Taxes – VoIP bypass EastWest Institute Working Group on Cybercrime - Brussels / London Working Groups: Global Treaty on Cybersecurity / Combating Online Child Abuse CANTO (Caribbean Association of National Telecoms Org) – Belize / Barbados Address: Reversing Declines in Telecommunications Revenue ICLN (International Criminal Law Network) - The Hague Address: Cybercrime Threats to Financial Systems CIRCAMP (Interpol / Europol) - Brussels Working Groups: Online Child Abuse – The Fight Against illegal Content Graham Butler – President and CEO Bitek © 2013 1 Tackling the illegal trade in the Digital world The evolution of interception - circuit switched networks 1. Threat to National Security 3.