Poverty and Inequality Mapping in Transition Countries
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A4 Cover EN LQ
BECOMEBECOME PARTPART OFOF THETHE IPARDIPARD PROGRAMPROGRAM 33RDRD CALLCALL WEWE SUPPORTSUPPORT THETHE DEVELOPMENTDEVELOPMENT OFOF ALBANIANALBANIAN AGRICULTUREAGRICULTURE 10 December 2020 - 25 January 2021 azhbr.gov.al - ipard.gov.al GRANTS SCHEMES IPARD II 2014-2020 Guideline for Applicants THIRD CALL FOR GRANT SUPPORT 10 December 2020 -25 January 2021 Measure 1 (All Sectors) And Measure 3 ( Sektor of Fruits – Vegitables) *Sector of Wine is not included SUPPORT OF GRANTS IS CO-FINANCED BY THE EUROPEAN UNION AND ALBANIAN GOVERNMENT EU contribution in total - 75% Contribution of Albanian Government in total - 25% 2020 Contents 1. Objectives, Priorities and Measures of the IPARD II Programme ............................................... 3 1.1 Background ....................................................................................................................................... 3 1.2 Objectives of the IPARD II Programme for the period of 2014-2020 ........................................... 4 1.3 Key Definitions ................................................................................................................................... 6 2. Measure 1 - Investments in physical assets of Agricultural Holdings: ................................................ 7 2.1 Aid Intensity under Measure 1 ......................................................................................................... 7 2.2 Eligibility of Recipients under Measure 1 ....................................................................................... -

Mbi Shërbimet Sociale Në Territorin E Qarkut Elbasan
GUIDË mbi shërbimet sociale në territorin e Qarkut Elbasan Ky publikim është realizuar nga Këshilli i Qarkut Elbasan Guidë mbi shërbimet sociale Përmbajtja 1.Parathënia 2.Përshkrimi i bashkive sipas ndarjes së re territoriale 3.Hartëzimi i shërbimeve sociale (i shpjeguar) 4.Adresari 5.Sfidat dhe rekomandimet Kontribuan në realizimin e Guidës mbi shërbimet sociale në territorin e Qarkut Elbasan: Blendi Gremi, Shef i Sektorit të Kulturës dhe Përkujdesit Social, në Këshillin e Qarkut Elbasan Ardiana Kasa, Eksperte “Tjetër Vizion” Prill 2016 Guidë mbi shërbimet sociale Parathënie Kam kënaqësinë të shpreh të gjitha falenderimet e mia për drejtuesit dhe specialistët e Këshillit të Qarkut Elbasan si dhe ekspertët e fushës, të cilët u bënë pjesë e hartimit dhe finalizimit të Guidës mbi shërbimet sociale në Territorin e Qarkut Elbasan, një guidë e qartë e situatës aktuale sociale në Qarkun e Elbasanit. Publikimi ka si objektiv tё prezantojё nё mёnyrё tё plotё mundёsitё e ofruara nga shërbimet sociale publike dhe jo publike nё mbёshtetje tё njerëzve nё nevojë, si dhe shёrbimet ekzistuese nё territor pёr to. Nё kёtё këndvështrim, publikimi mund tё shihet si njё lloj “udhërrëfyesi” ku mund të sigurohen, nё mёnyrё sintetike e tё qartё, informacione nё lidhje me tё gjitha shёrbimet nё favor tё shtresave më në nevojë tё ofruara nga ente publike e private nё Qarkun e Elbasanit. Ky publikim përcakton, burimet ekzistuese, nevojat e ndërhyrjes, mungesat, sfidat e përballura si dhe rekomandimet për të ardhmen. Kjo guidë do t’i vijë në ndihmë hartimit të planveprimit të përfshirjes sociale të Bashkisë Elbasan si dhe bashkive të tjera, pjesë e Qarkut Elbasan dhe do t’i hapë rrugë përqasjes së donatorëve vendas dhe të huaj në zbatimin e projekteve të nevojshme në fushën sociale. -

Violence Against Kosovar Albanians, Nato's
VIOLENCE AGAINST KOSOVAR ALBANIANS, NATO’S INTERVENTION 1998-1999 MSF SPEAKS OUT MSF Speaks Out In the same collection, “MSF Speaking Out”: - “Salvadoran refugee camps in Honduras 1988” Laurence Binet - Médecins Sans Frontières [October 2003 - April 2004 - December 2013] - “Genocide of Rwandan Tutsis 1994” Laurence Binet - Médecins Sans Frontières [October 2003 - April 2004 - April 2014] - “Rwandan refugee camps Zaire and Tanzania 1994-1995” Laurence Binet - Médecins Sans Frontières [October 2003 - April 2004 - April 2014] - “The violence of the new Rwandan regime 1994-1995” Laurence Binet - Médecins Sans Frontières [October 2003 - April 2004 - April 2014] - “Hunting and killings of Rwandan Refugee in Zaire-Congo 1996-1997” Laurence Binet - Médecins Sans Frontières [August 2004 - April 2014] - ‘’Famine and forced relocations in Ethiopia 1984-1986” Laurence Binet - Médecins Sans Frontières [January 2005 - November 2013] - “MSF and North Korea 1995-1998” Laurence Binet - Médecins Sans Frontières [January 2008 - 2014] - “War Crimes and Politics of Terror in Chechnya 1994-2004” Laurence Binet - Médecins Sans Frontières [June 2010 -2014] -”Somalia 1991-1993: Civil war, famine alert and UN ‘military-humanitarian’ intervention” Laurence Binet - Médecins Sans Frontières [October 2013] Editorial Committee: Laurence Binet, Françoise Bouchet-Saulnier, Marine Buissonnière, Katharine Derderian, Rebecca Golden, Michiel Hofman, Theo Kreuzen, Jacqui Tong - Director of Studies (project coordination-research-interviews-editing): Laurence Binet - Assistant: Berengere Cescau - Transcription of interviews: Laurence Binet, Christelle Cabioch, Bérengère Cescau, Jonathan Hull, Mary Sexton - Typing: Cristelle Cabioch - Translation into English: Aaron Bull, Leah Brummer, Nina Friedman, Imogen Forst, Malcom Leader, Caroline Lopez-Serraf, Roger Leverdier, Jan Todd, Karen Tucker - Proof reading: Rebecca Golden, Jacqui Tong - Design/lay out: - Video edit- ing: Sara Mac Leod - Video research: Céline Zigo - Website designer and webmaster: Sean Brokenshire. -

Regjistri I Koleksioneve Ex Situ Të Bankës Gjenetike
UNIVERSITETI BUJQËSOR I TIRANËS INSTITUTI I RESURSEVE GJENETIKE TË BIMËVE REGJISTRI I KOLEKSIONEVE EX SITU TË BANKËS GJENETIKE Tiranë, 2017 UNIVERSITETI BUJQËSOR I TIRANËS INSTITUTI I RESURSEVE GJENETIKE TË BIMËVE REGJISTRI I KOLEKSIONEVE EX SITU TË BANKËS GJENETIKE Përgatiti: B. Gixhari Botim i Institutit të Resurseve Gjenetike të Bimëve http://qrgj.org Tiranë, 2017 Regjistri i “KOLEKSIONEVE EX SITU” të Bankës Gjenetike është hartuar në kuadër të informimit të publikut të interesuar për Resurset Gjenetike të Bimëve në Shqipëri. Regjistri përmban informacione për gjermoplazmën bimore të grumbulluar/ koleksionuar gjatë viteve në pjesë të ndryshme të Shqipërisë dhe që ruhet jashtë vendorigjinës së tyre (ex situ) nga Banka Gjenetike Shqiptare. Në të dhënat e paraqitura në këtë regjistër janë treguesit (deskriptorët) e domosdoshëm të pasaportës së aksesioneve të bimëve të koleksionuara si: numri i aksesionit (ACCENUMB), numri i koleksionimit (COLLNUMB), kodi i koleksionimit (COLLCODE), emërtimi i pranuar taksonomik (TaxonName_Accepted), emri i aksesionit (ACCENAME), data e pranimit (ACQDATE), vendi i origjinës (ORIGCTY), vendi i koleksionimit (COLLSITE), gjerësia gjeografike (LATITUDE), gjatësia gjeografike (LONGITUTE), lartësia mbi nivelin e detit (ELEVATION) dhe data e koleksionimit (COLLDATE). Në koleksionet në ruajtje ex situ përfshihen aksesione të bimëve të kultivuara, aksesione të formave bimore lokale të njohura si varietete të vjetër të fermerit ose landrace, aksesione të pemëve frutore, të bimëve foragjere, bimëve industriale, bimëve mjekësore dhe aromatike dhe të bimëve të egra. Pjesa më e madhe e gjermoplazmës që ruhet në formën ex situ i përket formave të vjetra lokale ose varietetet e fermerit, të njohura për vlerat e tyre kryesisht cilësore, që janë përdorur në bujqësinë shqiptare dekada më parë, por që aktualisht përdoren në sipërfaqe të kufizuara ose nuk përdoren më në strukturën e bujqësisë intensive. -
Crystal Reports
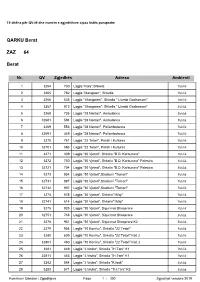
Të dhëna për QV-të dhe numrin e zgjedhësve sipas listës paraprake QARKU Berat ZAZ 64 Berat Nr. QV Zgjedhës Adresa Ambienti 1 3264 730 Lagjia "Kala",Shkolla Publik 2 3265 782 Lagjia "Mangalen", Shkolla Publik 3 3266 535 Lagjia " Mangalem", Shkolla " Llambi Goxhomani" Publik 4 3267 813 Lagjia " Mangalem", Shkolla " Llambi Goxhomani" Publik 5 3268 735 Lagjia "28 Nentori", Ambulanca Publik 6 32681 594 Lagjia "28 Nentori", Ambulanca Publik 7 3269 553 Lagjia "28 Nentori", Poliambulanca Publik 8 32691 449 Lagjia "28 Nentori", Poliambulanca Publik 9 3270 751 Lagjia "22 Tetori", Pallati I Kultures Publik 10 32701 593 Lagjia "22 Tetori", Pallati I Kultures Publik 11 3271 409 Lagjia "30 Vjetori", Shkolla "B.D. Karbunara" Publik 12 3272 750 Lagjia "30 Vjetori", Shkolla "B.D. Karbunara" Palestra Publik 13 32721 704 Lagjia "30 Vjetori", Shkolla "B.D. Karbunara" Palestra Publik 14 3273 854 Lagjia "30 Vjetori",Stadiumi "Tomori" Publik 15 32731 887 Lagjia "30 Vjetori",Stadiumi "Tomori" Publik 16 32732 907 Lagjia "30 Vjetori",Stadiumi "Tomori" Publik 17 3274 578 Lagjia "30 Vjetori", Shkolla"1Maji" Publik 18 32741 614 Lagjia "30 Vjetori", Shkolla"1Maji" Publik 19 3275 925 Lagjia "30 Vjetori", Sigurimet Shoqerore Publik 20 32751 748 Lagjia "30 Vjetori", Sigurimet Shoqerore Publik 21 3276 951 Lagjia "30 Vjetori", Sigurimet Shoqerore K2 Publik 22 3279 954 Lagjia "10 Korriku", Shkolla "22 Tetori" Publik 23 3280 509 Lagjia "10 Korriku", Shkolla "22 Tetori" Kati 2 Publik 24 32801 450 Lagjia "10 Korriku", Shkolla "22 Tetori" Kati 2 Publik 25 3281 649 Lagjia "J.Vruho", -

Gazeta Jonë Dërgohet Kudo Në Botë Me Postë Elektronike
Kurora e Gjelbër 1 FKPKK Kurora APPK FKPKK e APPK Federata Kombëtare e Asosacioni i Pyjeve dhe Kullotave Pronarëve të Pyjeve Komunale, Shqipëri Privatë, Kosovë www.shkpkk.org Gjelbër www.akppp.org Gazetë Periodike, Tiranë (Viti i katërmbëdhjetë i botimit) Nr. 117, qershor 2012 Çmimi 20 lekë EdheEdhe unëunë vendos!vendos! “Pylli im”, Në respekt të vajzave e grave që kontribuojnë për zhvillimin e qendrueshëm të Pylltarisë Komunale libërlibër meme shumëshumë vleravlera Albora KACANI, Federata Kombëtare e Pyjeve dhe Kullotave Komunale, Tiranë Sebiha AHMETI, RAMAXHIKU, SNV, Kosovë isur nga fakti që Maji i dhura mbi çështjet e barazisë ylli privat është pronë e këtij viti u shpall muaji gjinore dhe integrimit gjinor në familjes. Në çdo familje, i Evropës për vendin qeverisjen mjedisore vendore. N njëri prej anëtarëve është tonë, jo pa qëllim, vendosëm që Po ashtu, rritja e ndërgjegjësimit P këtë numër të Gazetës t’ia ku- të komunitetit mbi ndikimin që kujdestar dhe menaxher i këtij shtojmë pjesëmarrjes dhe rri- ka pjesëmarrja e grave në proce- pylli. Kujdesi dhe menaxhimi, tjes së rolit të grave në vendim- set vendimmarrëse, promovimi nënkuptojnë, të qenit përgjegjës marrje dhe shkrimet e botuara i përfaqësimit më të madh të për pyllin, kujdesin e duhur për të jenë vetëm nga autore femra. grave në strukturat vendim- të, si dhe mbrojtjen e pyjeve, duke Vendi ynë tashmë ka hyrë në marrëse, fuqizimi i kapaciteteve i përdorur me kujdes. Prandaj, rrugën për marrjen e statusit të të grave të zgjedhura në struktu- nëse e përdorim pyllin për ecje, vendit kandidat për anëtarësim rat vendimmarrëse dhe grave gjueti apo për marrjen e drurit, në BE dhe për këtë duhet të për- drejtuese në strukturat e Shoqa- duhet të jemi “kujdestarë e mbushë disa kritere. -

Bashkia Burrel,Njesia Administrative Baz,Derjan,Macukull,Komsi,Lis,Rukaj,Ulez Monitoruar: Bashkia Klos, Me Njesite Administrative Gurre,Klos,Suc,Xiber
Shtojca nr.3 Raporti i ndërmjetëm i Monitoruesve I. Përmbledhje Vëzhguesi: (Emri, mbiemri) Rajoni/ Komuna e Bashkia Burrel,njesia administrative Baz,Derjan,Macukull,Komsi,Lis,Rukaj,Ulez monitoruar: Bashkia Klos, me njesite administrative Gurre,Klos,Suc,Xiber Subjektet zgjedhore të Partia Socialiste, Partia Demokratike monitoruar: Periudha e mbuluar nga 01.04.2021- 10.04.2021 raporti: Data e dorëzimit të 10 Prill 2021 raportit: Nënshkrimi Shënim: për Seksionin II (monitorimi i aktiviteteve të fushatës), një raport monitorimi i veçantë duhet të plotësohet për secilin subjekt zgjedhor, duke përdorur formularin e dhënë. Për seksionin III (monitorimi i abuzimit/ keqpërdorimit të burimeve shtetërore), një raport duhet të plotësohet për të gjithë zonën gjeografike të monitoruar. II. SUBJEKTI ZGJEDHOR –AKTIVITETET E MONITORUARA TË FUSHATËS Një raport monitorimi i veçantë duhet të plotësohet për secilin subjekt zgjedhor, duke përdorur formularin e mëposhtëm. Raporti i Monitorimit për Subjektin Zgjedhor _Partia Socialiste, Partia Demokratike_ (shtoni emrin e subjektit zgjedhor) 1. Përmbledhja e aktiviteteve të monitoruara të subjektit zgjedhor Lloji i aktivitetit të Detaje Parregullsi për tu përmendur këtu dhe për monitoruar tu identifikuar më vonë a) Zyrat elektorale Numri dhe vendndodhja e zyrave elektorale të Te marra me qera, por ende nuk jane funksionale monitoruara b) Ngjarjet e Fushatës Numri i aktiviteteve të monitoruara të fushatës të Jo organizuara nga subjekti zgjedhor të cilatu monitoruan c) Materialet Numri i materialeve të monitoruara (të bashkangjiten Jo propagandistike mostra/foto për secilen) Numri i materialeve vizive propagandistike të shqyrtuara Jo për përfshirjen e shënimit: ‘Prodhuar nën përgjegjësinë ligjore të …’ d) Monitorimi i Faqeve te Identifikimi i platformave të faqeve të internetit Te dyja partite kan facebook gjithashtu dhe Internetit kandidatet kane faqet e tyre ku postoje rreth fushates. -

Pasqyra 1 Numrat Që Përdoren Për Numërtimin E Zonave Të QV-Ve Për Çdo Njësi Të Qeverisjes Vendore
Pasqyra 1 Numrat që përdoren për numërtimin e zonave të QV-ve për çdo njësi të qeverisjes vendore Njësia e qeverisjes vendore Nr. i zonës se QV-së Nr Qarku Rrethi Nga Deri 1 Shkoder Malesi e Madhe GRUEMIRE 0001 0025 2 Shkoder Malesi e Madhe KASTRAT 0026 0038 3 Shkoder Malesi e Madhe KELMEND 0039 0046 4 Shkoder Malesi e Madhe KOPLIK 0047 0049 5 Shkoder Malesi e Madhe QENDER MALESI E MADHE 0050 0061 6 Shkoder Malesi e Madhe SHKREL 0062 0076 7 Shkoder Shkoder POSTRIBE 0077 0090 8 Shkoder Shkoder PULT 0091 0096 9 Shkoder Shkoder RRETHINAT 0097 0114 10 Shkoder Shkoder SHALE 0115 0125 11 Shkoder Shkoder SHLLAK 0126 0131 12 Shkoder Shkoder SHOSH 0132 0134 13 Shkoder Shkoder TEMAL 0135 0144 14 Shkoder Shkoder BUSHAT 0145 0164 15 Shkoder Shkoder HAJMEL 0165 0171 16 Shkoder Shkoder VAU-DEJES 0172 0185 17 Shkoder Shkoder VIG-MNELE 0186 0192 18 Shkoder Shkoder ANA-MALIT 0193 0214 19 Shkoder Shkoder BERDICE 0215 0223 20 Shkoder Shkoder DAJC-SHKODER 0224 0234 21 Shkoder Shkoder SHKODER 0235 0323 22 Shkoder Shkoder VELIPOJE 0324 0334 23 Shkoder Shkoder GURI I ZI 0335 0347 24 Shkoder Puke BLERIM 0348 0354 25 Shkoder Puke FIERZE-PUKE 0355 0365 26 Shkoder Puke FUSH-ARREZ 0366 0371 27 Shkoder Puke GJEGJAN 0372 0381 28 Shkoder Puke IBALLE 0382 0389 29 Shkoder Puke PUKE 0390 0396 30 Shkoder Puke QAFE-MAL 0397 0405 31 Shkoder Puke QELEZ 0406 0418 32 Shkoder Puke QERRET 0419 0430 33 Shkoder Puke RRAPE 0431 0439 34 Kukes Tropoje BAJRAM CURRI 0440 0449 35 Kukes Tropoje BUJAN 0450 0456 36 Kukes Tropoje BYTYC 0457 0471 37 Kukes Tropoje FIERZE-TROPOJE 0472 0479 38 Kukes Tropoje LEKBIBAJ 0480 0492 39 Kukes Tropoje LLUGAJ 0493 0499 40 Kukes Tropoje MARGEGAJ 0500 0509 41 Kukes Tropoje TROPOJE FSHAT 0510 0524 42 Kukes Has FAJZA 0525 0534 43 Kukes Has GJINAJ 0535 0540 44 Kukes Has GOLAJ 0541 0556 45 Kukes Has KRUME 0557 0567 46 Kukes Kukes ARREN 0568 0572 47 Kukes Kukes BUSHTRICE 0573 0579 48 Kukes Kukes GRYKE-CAJE 0580 0583 Miartuar me Udhëzim të KQZ-së Nr.6, datë 23.03.2009 faqe 1 nga 8 Pasqyra 1 Numrat që përdoren për numërtimin e zonave të QV-ve për çdo njësi të qeverisjes vendore Nr. -

Economic and Social Council
UNITED E NATIONS Economic and Social Distr. Council GENERAL E/1990/5/Add.67 11 April 2005 Original: ENGLISH Substantive session of 2005 IMPLEMENTATION OF THE INTERNATIONAL COVENANT ON ECONOMIC, SOCIAL AND CULTURAL RIGHTS Initial reports submitted by States parties under articles 16 and 17 of the Covenant Addendum ALBANIA* [5 January 2005] * The information submitted by Albania in accordance with the guidelines concerning the initial part of reports of States parties is contained in the core document (HRI/CORE/1/Add.124). GE.05-41010 (E) 110505 E/1990/5/Add.67 page 2 CONTENTS Paragraphs Page Introduction .............................................................................................. 1 - 3 3 Article 1 .................................................................................................... 4 - 9 3 Article 2 .................................................................................................... 10 - 34 11 Article 3 .................................................................................................... 35 - 44 14 Article 6 .................................................................................................... 45 - 100 16 Article 7 .................................................................................................... 101 - 154 27 Article 8 .................................................................................................... 155 - 175 38 Article 9 .................................................................................................... 176 -

Albania: Average Precipitation for December
MA016_A1 Kelmend Margegaj Topojë Shkrel TRO PO JË S Shalë Bujan Bajram Curri Llugaj MA LËSI Lekbibaj Kastrat E MA DH E KU KË S Bytyç Fierzë Golaj Pult Koplik Qendër Fierzë Shosh S HK O D Ë R HAS Krumë Inland Gruemirë Water SHK OD RË S Iballë Body Postribë Blerim Temal Fajza PUK ËS Gjinaj Shllak Rrethina Terthorë Qelëz Malzi Fushë Arrëz Shkodër KUK ËSI T Gur i Zi Kukës Rrapë Kolsh Shkodër Qerret Qafë Mali ´ Ana e Vau i Dejës Shtiqen Zapod Pukë Malit Berdicë Surroj Shtiqen 20°E 21°E Created 16 Dec 2019 / UTC+01:00 A1 Map shows the average precipitation for December in Albania. Map Document MA016_Alb_Ave_Precip_Dec Settlements Borders Projection & WGS 1984 UTM Zone 34N B1 CAPITAL INTERNATIONAL Datum City COUNTIES Tiranë C1 MUNICIPALITIES Albania: Average Produced by MapAction ADMIN 3 mapaction.org Precipitation for D1 0 2 4 6 8 10 [email protected] Precipitation (mm) December kilometres Supported by Supported by the German Federal E1 Foreign Office. - Sheet A1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Data sources 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 - - - 1 1 1 1 1 1 1 1 1 1 2 2 2 The depiction and use of boundaries, names and - - - - - - - - - - - - - F1 .1 .1 .1 GADM, SRTM, OpenStreetMap, WorldClim 0 0 0 .1 .1 .1 .1 .1 .1 .1 .1 .1 .1 .1 .1 .1 associated data shown here do not imply 6 7 8 0 0 0 0 0 0 0 0 0 0 0 0 0 9 0 1 2 3 4 5 6 7 8 9 0 1 endorsement or acceptance by MapAction. -

(Pd) 08/03/2021
Shtojca nr.2 Raporti i ndërmjetëm i Monitoruesve I. Përmbledhje Vëzhguesi: (Emri, mbiemri) Rajoni/ Komuna e Qarkun Elbasan, Bashkia Cërrik , Gostime, Klos, Mollas, Shalës dhe Bashkia Gramsh, Njesia Administrative, monitoruar: Skënderbegas, Kushove, Kodovjat, Lenie, Kukur, Pishaj, Sult, Poroçan dhe Tunje. Subjektet zgjedhore të monitoruar: Partia Demokratike (PD) Periudha e mbuluar nga raporti: 08/03/2021 – 15/03/2021 Data e dorëzimit të 15/03/2021 raportit: Nënshkrimi Shënim: për Seksionin II (monitorimi i aktiviteteve të fushatës), një raport monitorimi i veçantë duhet të plotësohet për secilin subjekt zgjedhor, duke përdorur formularin e dhënë. Për seksionin III (monitorimi i abuzimit/ keqpërdorimit të burimeve shtetërore), një raport duhet të plotësohet për të gjithë zonën gjeografike të monitoruar. II. SUBJEKTI ZGJEDHOR –AKTIVITETET E MONITORUARA TË FUSHATËS Një raport monitorimi i veçantë duhet të plotësohet për secilin subjekt zgjedhor, duke përdorur formularin e mëposhtëm. Raporti i Monitorimit për Subjektin Zgjedhor _________ Partia Demokratike(PD)__________ (shtoni emrin e subjektit zgjedhor) 1. Përmbledhja e aktiviteteve të monitoruara të subjektit zgjedhor Lloji i aktivitetit të Detaje Parregullsi për tu përmendur këtu dhe për monitoruar tu identifikuar më vonë a) Zyrat elektorale Numri dhe vendndodhja e zyrave elektorale të Po/ Jo monitoruara: Ne Qarkun Elbasan, Bashkia Cërrik , Gostime, Klos, Mollas, Shalës dhe Bashkia Gramsh, Njesia Administrative, Skënderbegas, Kushove, Kodovjat, Lenie, Kukur, Pishaj, Sult, Poroçan dhe Tunje. b) Ngjarjet e Fushatës Numri i aktiviteteve të monitoruara të fushatës të Po/ Jo organizuara nga subjekti zgjedhor të cilat u monitoruan: 1 aktivitet1 (bashkelidhur screenshot te publikimeve te aktivitetit ne Facebook, bashkelidhur ne fund te raportit te gjitha fotot).Gjate monitorimit te zyrave elektorale te kesaj partie, u vu re se nuk kishin persona brenda si pasoje e kufizimeve anti Covid. -

Bashkia Tropojë”
KONTROLLI I LARTË I SHTETIT Raport Përfundimtar për Auditimin e ushtruar në “Bashkinë Tropojë” RAPORT PËRFUNDIMTAR MBI (Auditimin Financiar dhe Përputhshmërisë) “BASHKIA TROPOJË” Tiranë 2019 KLSH 1 | P a g e KONTROLLI I LARTË I SHTETIT Raport Përfundimtar për Auditimin e ushtruar në “Bashkinë Tropojë” Nr. Përmbajtje ___ Faqe I. PËRMBLEDHJE EKZEKUTIVE......................................................................... 4-16 II. HYRJA..................................................................................................................... 16-23 a. Objektivat dhe qëllimi b. Identifikimi i çështjes c. Përgjegjësitë e strukturave drejtuese d. Përgjegjësitë e Audituesve e. Kriteret e vlerësimit f. Standardet e auditimit III. PËRSHKRIMI I AUDITIMIT........................................................................... 23-26 IV. GJETJET DHE REKOMANDIMIT............................................................... 26-106 A. Auditim mbi organizimin, mbajtjen e kontabilitetit, hartimin dhe saktësia e veprimeve rregulluese dhe mbyllëse për paraqitjen e pasqyrave financiare.............................................................................................................. 26-50 B. Mbi planifikimin dhe zbatimin e planit të buxhetit, bazuar në ligjin organik dhe ligjin nr. 130/2016, datë 17.12.2016 “Për buxhetin e vitit 2017, me ndryshime e tij; ligjin nr. 109/2017, datë 30.11.2017 “Për buxhetin e vitit 2018”..................................................................................................................