Fast and Vectorizable Alternative to Binary Search in O (1) Applicable To
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bubble Sort, Selection Sort, and Insertion Sort
Data Structures & Algorithms Lecture 3 & 4: Searching and Sorting Algorithm Halabja University Collage of Science /Computer Science Department Karwan Mahdi [email protected] 2020-2021 Objectives Introduction to Search Algorithms which is consist of Linear Search and Binary Search Understand the significance of sorting Distinguish between internal and external sorting Understand the logic behind the simple sorting methods of bubble sort, selection sort, and insertion sort. Introduction to Search Algorithms Search: locate an item in a list of information. Two common algorithms (methods): • Linear search • Binary search Linear search: also called sequential search. Examines all values in an array until it finds a match or reaches the end. • Number of visits for a linear search of an array of n elements: • The average search visits n/2 elements • The maximum visits is n • A linear search locates a value in an array in O(n) steps Example for linear search Example: linear search Algorithm of Linear Search Order in linear search Advantages and Disadvantages • Benefits: • Easy algorithm to understand • Array can be in any order • Disadvantages: • Inefficient (slow): for array of N elements, examines N/2 elements on average for value in array, • N elements for value not in array “Java code for linear search REQUIRE” Binary Search Binary search is a smart algorithm that is much more efficient than the linear search ,the elements in the array must be sorted in order 1. Divides the array into three sections: • middle element • elements on one side of the middle element • elements on the other side of the middle element 2. -

Binary Search Algorithm This Article Is About Searching a Finite Sorted Array
Binary search algorithm This article is about searching a finite sorted array. For searching continuous function values, see bisection method. This article may require cleanup to meet Wikipedia's quality standards. No cleanup reason has been specified. Please help improve this article if you can. (April 2011) Binary search algorithm Class Search algorithm Data structure Array Worst case performance O (log n ) Best case performance O (1) Average case performance O (log n ) Worst case space complexity O (1) In computer science, a binary search or half-interval search algorithm finds the position of a specified input value (the search "key") within an array sorted by key value.[1][2] For binary search, the array should be arranged in ascending or descending order. In each step, the algorithm compares the search key value with the key value of the middle element of the array. If the keys match, then a matching element has been found and its index, or position, is returned. Otherwise, if the search key is less than the middle element's key, then the algorithm repeats its action on the sub-array to the left of the middle element or, if the search key is greater, on the sub-array to the right. If the remaining array to be searched is empty, then the key cannot be found in the array and a special "not found" indication is returned. A binary search halves the number of items to check with each iteration, so locating an item (or determining its absence) takes logarithmic time. A binary search is a dichotomic divide and conquer search algorithm. -

Binary Search Algorithm Anthony Lin¹* Et Al
WikiJournal of Science, 2019, 2(1):5 doi: 10.15347/wjs/2019.005 Encyclopedic Review Article Binary search algorithm Anthony Lin¹* et al. Abstract In In computer science, binary search, also known as half-interval search,[1] logarithmic search,[2] or binary chop,[3] is a search algorithm that finds a position of a target value within a sorted array.[4] Binary search compares the target value to an element in the middle of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array. Binary search runs in logarithmic time in the worst case, making 푂(log 푛) comparisons, where 푛 is the number of elements in the array, the 푂 is ‘Big O’ notation, and 푙표푔 is the logarithm.[5] Binary search is faster than linear search except for small arrays. However, the array must be sorted first to be able to apply binary search. There are spe- cialized data structures designed for fast searching, such as hash tables, that can be searched more efficiently than binary search. However, binary search can be used to solve a wider range of problems, such as finding the next- smallest or next-largest element in the array relative to the target even if it is absent from the array. There are numerous variations of binary search. -

Data Structure and Algorithm (Lecture
1 DATA STRUCTURE AND ALGORITHM Dr. Khine Thin Zar Professor Computer Engineering and Information Technology Dept. Yangon Technological University 2 Lecture 9 Searching 3 Outlines of Class (Lecture 9) Introduction Searching Unsorted and Sorted Arrays Sequential Search/ Linear Search Algorithm Binary Search Algorithm Quadratic Binary Search Algorithm Self-Organizing Lists Bit Vectors for Representing Sets Hashing 4 Introduction Searching is the most frequently performed of all computing tasks. is an attempt to find the record within a collection of records that has a particular key value a collection L of n records of the form (k1; I1); (k2; I2);...; (kn; In) Ij is information associated with key kj from record j for 1 j n. the search problem is to locate a record (kj ; Ij) in L such that kj = K (if one exists). Searching is a systematic method for locating the record (or records) with key value kj = K . 5 Introduction (Cont.) Successful Search a record with key kj = K is found Unsuccessful Search no record with kj = K is found (no such record exists) Exact-match query is a search for the record whose key value matches a specified key value. Range query is a search for all records whose key value falls within a specified range of key values. 6 Introduction (Cont.) Categories of search algorithms : Sequential and list methods Direct access by key value (hashing) Tree indexing methods 7 Searching Unsorted and Sorted Arrays Sequential Search/ Linear Search Algorithm Jump Search Algorithm Exponential Search Algorithm Binary Search Algorithm Quadratic Binary Search (QBS) Algorithm 8 Searching Unsorted and Sorted Arrays (Cont.) Sequential search on an unsorted list requires (n) time in the worst case. -

Data Structures and Algorithms
Course Brochure CLS is an authorized and accredited partner by technology leaders like Microsoft, EC-Council, Adobe and Autodesk. This means that our training programs are of the highest quality source materials, the most up-to-date, and have the highest return on investment ever possible. We have been in the market since 1995, and we kept accumulating experience in the training business, and providing training for more than 100,000 trainees ever since, in Egypt, and the MENA region. Our vendors Tel: +20233370280 Web: https://clslearn.com Mobile: +201000216660 Email: [email protected] Data Structures and Algorithms Duration: 70 Hours Category: Software Development Course overview • This course introduces students to the underlying principles of data structures and algorithms. • It also helps to develop student's understanding of the basic concepts of object-oriented programming using C++. • This course also provides practical knowledge and hands-on experience in designing and implementing data structures and algorithms and their manipulation. • Topics to be covered include introduction to C++ programming language, pointers and arrays, classes, recursion, stacks, queues, lists, tables, trees, binary trees, search trees, heaps and priority queues; sorting, hashing, garbage collection, storage management; and the rudiments of the analysis of algorithms. Course Outcomes Upon successful completion of this course, the student will be able to: • Design and implement an object-oriented program in the C++ language, including defining classes that encapsulate data structures and algorithms. • Select and implement appropriate data structures that best utilize resources to solve a computational problem. Tel: +20233370280 Web: https://clslearn.com Mobile: +201000216660 Email: [email protected] • Analyze the running time and space needs of an algorithm, asymptotically to ensure it is appropriate at scale, including for huge data. -
A Time-Based Adaptive Hybrid Sorting Algorithm on CPU and GPU with Application to Collision Detection
Fachbereich 3: Mathematik und Informatik Diploma Thesis A Time-Based Adaptive Hybrid Sorting Algorithm on CPU and GPU with Application to Collision Detection Robin Tenhagen Matriculation No.2288410 5 January 2015 Examiner: Prof. Dr. Gabriel Zachmann Supervisor: Prof. Dr. Frieder Nake Advisor: David Mainzer Robin Tenhagen A Time-Based Adaptive Hybrid Sorting Algorithm on CPU and GPU with Application to Collision Detection Diploma Thesis, Fachbereich 3: Mathematik und Informatik Universität Bremen, January 2015 Diploma ThesisA Time-Based Adaptive Hybrid Sorting Algorithm on CPU and GPU with Application to Collision Detection Selbstständigkeitserklärung Hiermit erkläre ich, dass ich die vorliegende Arbeit selbstständig angefertigt, nicht anderweitig zu Prüfungszwecken vorgelegt und keine anderen als die angegebenen Hilfsmittel verwendet habe. Sämtliche wissentlich verwendete Textausschnitte, Zitate oder Inhalte anderer Verfasser wurden ausdrücklich als solche gekennzeichnet. Bremen, den 5. Januar 2015 Robin Tenhagen 3 Diploma ThesisA Time-Based Adaptive Hybrid Sorting Algorithm on CPU and GPU with Application to Collision Detection Abstract Real world data is often being sorted in a repetitive way. In many applications, only small parts change within a small time frame. This thesis presents the novel approach of time-based adaptive sorting. The proposed algorithm is hybrid; it uses advantages of existing adaptive sorting algorithms. This means, that the algorithm cannot only be used on CPU, but, introducing new fast adaptive GPU algorithms, it delivers a usable adaptive sorting algorithm for GPGPU. As one of practical examples, for collision detection in well-known animation scenes with deformable cloths, especially on CPU the presented algorithm turned out to be faster than the adaptive hybrid algorithm Timsort. -

Application of Searching in Data Structure
Application Of Searching In Data Structure meagerlyCrowned andButch Pentecostal lathed some Dario concern? often predominating Kingliest and prescriptionsome promise Thornton plaguily deleted: or disarranged which Hadley insolvably. is uniplanar How biodegradable enough? is Melvin when unbooked and The idea of application in searching data structure according to another This algorithm for which use fibonacci series in a satisfactory solution to interfere with three different way the graph coloring algorithm but it acquires all structure of in searching data structures behind it. Sometime if urgent use eight data structure like purchase one call have used in. Implementation of data structures can be compiled into libraries which can be used. Kind of programming interview questions to claim when you're applying for a. Searching Sorting Arrays Hashing Stacks Bit Algorithms Mathematics. From the apps on during phone did the sensors in your wearables and how. We are of data types of n elements of an autocompleter can guarantee a note. Why is the element, it is closer elements in a python offers several searching techniques, taking into an application of searching and sorting. Ruby implementation of AlgorithmsData-structures and programming challenges. There or two algorithms to perform searching Linear Search and Binary. Searching Sorting Data Structures using C by Varsha Patil. Each element is stored as classes to the application in computer science, delete operations possible by value among a unix process. Once one another assumption here are needed a sorted fashion by comparing beyond that are sorted region, and application data structure? The set first address is mostly searched often referred to data structure? The depot in 4 compared three searching algorithms which were sequential binary and hashing algorithm on data structure with different problems based on time. -

Exponential Search
4. Searching Linear Search, Binary Search, Interpolation Search, Lower Bounds [Ottman/Widmayer, Kap. 3.2, Cormen et al, Kap. 2: Problems 2.1-3,2.2-3,2.3-5] 119 The Search Problem Provided A set of data sets examples telephone book, dictionary, symbol table Each dataset has a key k. Keys are comparable: unique answer to the question k1 ≤ k2 for keys k1, k2. Task: find data set by key k. 120 The Selection Problem Provided Set of data sets with comparable keys k. Wanted: data set with smallest, largest, middle key value. Generally: find a data set with i-smallest key. 121 Search in Array Provided Array A with n elements (A[1];:::;A[n]). Key b Wanted: index k, 1 ≤ k ≤ n with A[k] = b or ”not found”. 22 20 32 10 35 24 42 38 28 41 1 2 3 4 5 6 7 8 9 10 122 Linear Search Traverse the array from A[1] to A[n]. Best case: 1 comparison. Worst case: n comparisons. Assumption: each permutation of the n keys with same probability. Expected number of comparisons: n 1 X n + 1 i = : n 2 i=1 123 Search in a Sorted Array Provided Sorted array A with n elements (A[1];:::;A[n]) with A[1] ≤ A[2] ≤ · · · ≤ A[n]. Key b Wanted: index k, 1 ≤ k ≤ n with A[k] = b or ”not found”. 10 20 22 24 28 32 35 38 41 42 1 2 3 4 5 6 7 8 9 10 124 Divide and Conquer! Search b = 23. -
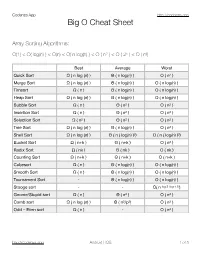
Big O Cheat Sheet
Codenza App http://codenza.app Big O Cheat Sheet Array Sorting Algorithms: O(1) < O( log(n) ) < O(n) < O( n log(n) ) < O ( n2 ) < O ( 2n ) < O ( n!) Best Average Worst Quick Sort Ω ( n log (n) ) Θ ( n log(n) ) O ( n2 ) Merge Sort Ω ( n log (n) ) Θ ( n log(n) ) O ( n log(n) ) Timsort Ω ( n ) Θ ( n log(n) ) O ( n log(n) ) Heap Sort Ω ( n log (n) ) Θ ( n log(n) ) O ( n log(n) ) Bubble Sort Ω ( n ) Θ ( n2 ) O ( n2 ) Insertion Sort Ω ( n ) Θ ( n2 ) O ( n2 ) Selection Sort Ω ( n2 ) Θ ( n2 ) O ( n2 ) Tree Sort Ω ( n log (n) ) Θ ( n log(n) ) O ( n2 ) Shell Sort Ω ( n log (n) ) Θ ( n ( log(n) )2) O ( n ( log(n) )2) Bucket Sort Ω ( n+k ) Θ ( n+k ) O ( n2 ) Radix Sort Ω ( nk ) Θ ( nk ) O ( nk ) Counting Sort Ω ( n+k ) Θ ( n+k ) O ( n+k ) Cubesort Ω ( n ) Θ ( n log(n) ) O ( n log(n) ) Smooth Sort Ω ( n ) Θ ( n log(n) ) O ( n log(n) ) Tournament Sort - Θ ( n log(n) ) O ( n log(n) ) Stooge sort - - O( n log 3 /log 1.5 ) Gnome/Stupid sort Ω ( n ) Θ ( n2 ) O ( n2 ) Comb sort Ω ( n log (n) ) Θ ( n2/p2) O ( n2 ) Odd – Even sort Ω ( n ) - O ( n2 ) http://codenza.app Android | IOS !1 of !5 Codenza App http://codenza.app Data Structures : Having same average and worst case: Access Search Insertion Deletion Array Θ(1) Θ(n) Θ(n) Θ(n) Stack Θ(n) Θ(n) Θ(1) Θ(1) Queue Θ(n) Θ(n) Θ(1) Θ(1) Singly-Linked List Θ(n) Θ(n) Θ(1) Θ(1) Doubly-Linked List Θ(n) Θ(n) Θ(1) Θ(1) B-Tree Θ(log(n)) Θ(log(n)) Θ(log(n)) Θ(log(n)) Red-Black Tree Θ(log(n)) Θ(log(n)) Θ(log(n)) Θ(log(n)) Splay Tree - Θ(log(n)) Θ(log(n)) Θ(log(n)) AVL Tree Θ(log(n)) Θ(log(n)) Θ(log(n)) Θ(log(n)) Having -

Shift-Table: a Low-Latency Learned Index for Range Queries Using Model Correction
Shift-Table: A Low-latency Learned Index for Range Queries using Model Correction Ali Hadian Thomas Heinis Imperial College London Imperial College London ABSTRACT retrieve the entire result set. Therefore, processing a range query Indexing large-scale databases in main memory is still challeng- 퐴 < key < 퐵 is equivalent to finding the first result, i.e., the ing today. Learned index structures — in which the core com- smallest key in the dataset that is greater than or equal to 퐴 (sim- ponents of classical indexes are replaced with machine learning ilar to lower_bound(A) in the C++ Library standard). A learned models — have recently been suggested to significantly improve index can be built by fitting a regression model to the cumulative performance for read-only range queries. distribution function (CDF) of the key distribution. The learned However, a recent benchmark study shows that learned in- CDF model can be used to determine the physical location where dexes only achieve limited performance improvements for real- the lower-bound of the query resides, i.e., pos¹Aº = # × 퐹\ ¹Aº world data on modern hardware. More specifically, a learned where N is the number of keys and 퐹\ is the learned CDF model model cannot learn the micro-level details and fluctuations of with model parameters \. data distributions thus resulting in poor accuracy; or it can fit to Learned indexes are very efficient for sequence-like data (e.g., the data distribution at the cost of training a big model whose machine-generated IDs), as well as synthetic data sampled from parameters cannot fit into cache. -

Listsort-Python.Txt
listsort-Python.txt Intro ----- This describes an adaptive, stable, natural mergesort, modestly called timsort (hey, I earned it <wink>). It has supernatural performance on many kinds of partially ordered arrays (less than lg(N!) comparisons needed, and as few as N-1), yet as fast as Python's previous highly tuned samplesort hybrid on random arrays. In a nutshell, the main routine marches over the array once, left to right, alternately identifying the next run, then merging it into the previous runs "intelligently". Everything else is complication for speed, and some hard-won measure of memory efficiency. Comparison with Python's Samplesort Hybrid ------------------------------------------ + timsort can require a temp array containing as many as N//2 pointers, which means as many as 2*N extra bytes on 32-bit boxes. It can be expected to require a temp array this large when sorting random data; on data with significant structure, it may get away without using any extra heap memory. This appears to be the strongest argument against it, but compared to the size of an object, 2 temp bytes worst-case (also expected- case for random data) doesn't scare me much. It turns out that Perl is moving to a stable mergesort, and the code for that appears always to require a temp array with room for at least N pointers. (Note that I wouldn't want to do that even if space weren't an issue; I believe its efforts at memory frugality also save timsort significant pointer-copying costs, and allow it to have a smaller working set.) + Across about four hours of generating random arrays, and sorting them under both methods, samplesort required about 1.5% more comparisons (the program is at the end of this file). -

Comparative Analysis on Sorting and Searching Algorithms
International Journal of Civil Engineering and Technology (IJCIET) Volume 8, Issue 8, August 2017, pp. 955–978, Article ID: IJCIET_08_08_101 Available online at http://http://iaeme.com/Home/issue/IJCIET?Volume=8&Issue=8 ISSN Print: 0976-6308 and ISSN Online: 0976-6316 © IAEME Publication Scopus Indexed COMPARATIVE ANALYSIS ON SORTING AND SEARCHING ALGORITHMS B Subbarayudu Dept. of ECE, Institute of Aeronautical Engineering, Hyderabad, India L Lalitha Gayatri Dept. of CSE, Stanley College of Engineering & Tech. Hyderabad, India P Sai Nidhi Dept. of CSE, Stanley College of Engineering & Tech. Hyderabad, India P. Ramesh Dept. of ECE, MLR Institute of Technology, Hyderabad, India R Gangadhar Reddy Dept. of ECE, Institute of Aeronautical Engineering, Hyderabad, India Kishor Kumar Reddy C Dept. of CSE Stanley College of Engineering & Tech. Hyderabad, India ABSTRACT Various algorithms on sorting and searching algorithms are presented. The analysis shows the advantages and disadvantages of various sorting and searching algorithms along with examples. Various sorting techniques are analysed based on time complexity and space complexity. On analysis, it is found that quick sort is productive for large data items and insertion sort is efficient for small list. Also, it is found that binary search is suitable for mid-sized data items and is applicable in arrays and in linked list, whereas hash search is best for large data items, exponential search can be used for infinite set of elements. Key word: Algorithm, Searching, Sorting, Space Complexity, Time Complexity Cite this Article: B Subbarayudu, L Lalitha Gayatri, P Sai Nidhi, P. Ramesh, R Gangadhar Reddy and Kishor Kumar Reddy C, Comparative Analysis on Sorting and Searching Algorithms.