Geometric Algorithms for Geographic Information Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Simulating Quantum Field Theory with a Quantum Computer
Simulating quantum field theory with a quantum computer John Preskill Lattice 2018 28 July 2018 This talk has two parts (1) Near-term prospects for quantum computing. (2) Opportunities in quantum simulation of quantum field theory. Exascale digital computers will advance our knowledge of QCD, but some challenges will remain, especially concerning real-time evolution and properties of nuclear matter and quark-gluon plasma at nonzero temperature and chemical potential. Digital computers may never be able to address these (and other) problems; quantum computers will solve them eventually, though I’m not sure when. The physics payoff may still be far away, but today’s research can hasten the arrival of a new era in which quantum simulation fuels progress in fundamental physics. Frontiers of Physics short distance long distance complexity Higgs boson Large scale structure “More is different” Neutrino masses Cosmic microwave Many-body entanglement background Supersymmetry Phases of quantum Dark matter matter Quantum gravity Dark energy Quantum computing String theory Gravitational waves Quantum spacetime particle collision molecular chemistry entangled electrons A quantum computer can simulate efficiently any physical process that occurs in Nature. (Maybe. We don’t actually know for sure.) superconductor black hole early universe Two fundamental ideas (1) Quantum complexity Why we think quantum computing is powerful. (2) Quantum error correction Why we think quantum computing is scalable. A complete description of a typical quantum state of just 300 qubits requires more bits than the number of atoms in the visible universe. Why we think quantum computing is powerful We know examples of problems that can be solved efficiently by a quantum computer, where we believe the problems are hard for classical computers. -

Geometric Algorithms
Geometric Algorithms primitive operations convex hull closest pair voronoi diagram References: Algorithms in C (2nd edition), Chapters 24-25 http://www.cs.princeton.edu/introalgsds/71primitives http://www.cs.princeton.edu/introalgsds/72hull 1 Geometric Algorithms Applications. • Data mining. • VLSI design. • Computer vision. • Mathematical models. • Astronomical simulation. • Geographic information systems. airflow around an aircraft wing • Computer graphics (movies, games, virtual reality). • Models of physical world (maps, architecture, medical imaging). Reference: http://www.ics.uci.edu/~eppstein/geom.html History. • Ancient mathematical foundations. • Most geometric algorithms less than 25 years old. 2 primitive operations convex hull closest pair voronoi diagram 3 Geometric Primitives Point: two numbers (x, y). any line not through origin Line: two numbers a and b [ax + by = 1] Line segment: two points. Polygon: sequence of points. Primitive operations. • Is a point inside a polygon? • Compare slopes of two lines. • Distance between two points. • Do two line segments intersect? Given three points p , p , p , is p -p -p a counterclockwise turn? • 1 2 3 1 2 3 Other geometric shapes. • Triangle, rectangle, circle, sphere, cone, … • 3D and higher dimensions sometimes more complicated. 4 Intuition Warning: intuition may be misleading. • Humans have spatial intuition in 2D and 3D. • Computers do not. • Neither has good intuition in higher dimensions! Is a given polygon simple? no crossings 1 6 5 8 7 2 7 8 6 4 2 1 1 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 2 18 4 18 4 19 4 19 4 20 3 20 3 20 1 10 3 7 2 8 8 3 4 6 5 15 1 11 3 14 2 16 we think of this algorithm sees this 5 Polygon Inside, Outside Jordan curve theorem. -

Object Oriented Programming
No. 52 March-A pril'1990 $3.95 T H E M TEe H CAL J 0 URN A L COPIA Object Oriented Programming First it was BASIC, then it was structures, now it's objects. C++ afi<;ionados feel, of course, that objects are so powerful, so encompassing that anything could be so defined. I hope they're not placing bets, because if they are, money's no object. C++ 2.0 page 8 An objective view of the newest C++. Training A Neural Network Now that you have a neural network what do you do with it? Part two of a fascinating series. Debugging C page 21 Pointers Using MEM Keep C fro111 (C)rashing your system. An AT Keyboard Interface Use an AT keyboard with your latest project. And More ... Understanding Logic Families EPROM Programming Speeding Up Your AT Keyboard ((CHAOS MADE TO ORDER~ Explore the Magnificent and Infinite World of Fractals with FRAC LS™ AN ELECTRONIC KALEIDOSCOPE OF NATURES GEOMETRYTM With FracTools, you can modify and play with any of the included images, or easily create new ones by marking a region in an existing image or entering the coordinates directly. Filter out areas of the display, change colors in any area, and animate the fractal to create gorgeous and mesmerizing images. Special effects include Strobe, Kaleidoscope, Stained Glass, Horizontal, Vertical and Diagonal Panning, and Mouse Movies. The most spectacular application is the creation of self-running Slide Shows. Include any PCX file from any of the popular "paint" programs. FracTools also includes a Slide Show Programming Language, to bring a higher degree of control to your shows. -

A Computational Basis for Conic Arcs and Boolean Operations on Conic Polygons
A Computational Basis for Conic Arcs and Boolean Operations on Conic Polygons Eric Berberich, Arno Eigenwillig, Michael Hemmer Susan Hert, Kurt Mehlhorn, and Elmar Schomer¨ [eric|arno|hemmer|hert|mehlhorn|schoemer]@mpi-sb.mpg.de Max-Planck-Institut fur¨ Informatik, Stuhlsatzenhausweg 85 66123 Saarbruck¨ en, Germany Abstract. We give an exact geometry kernel for conic arcs, algorithms for ex- act computation with low-degree algebraic numbers, and an algorithm for com- puting the arrangement of conic arcs that immediately leads to a realization of regularized boolean operations on conic polygons. A conic polygon, or polygon for short, is anything that can be obtained from linear or conic halfspaces (= the set of points where a linear or quadratic function is non-negative) by regularized boolean operations. The algorithm and its implementation are complete (they can handle all cases), exact (they give the mathematically correct result), and efficient (they can handle inputs with several hundred primitives). 1 Introduction We give an exact geometry kernel for conic arcs, algorithms for exact computation with low-degree algebraic numbers, and a sweep-line algorithm for computing arrangements of curved arcs that immediately leads to a realization of regularized boolean operations on conic polygons. A conic polygon, or polygon for short, is anything that can be ob- tained from linear or conic halfspaces (= the set of points where a linear or quadratic function is non-negative) by regularized boolean operations (Figure 1). A regularized boolean operation is a standard boolean operation (union, intersection, complement) followed by regularization. Regularization replaces a set by the closure of its interior and eliminates dangling low-dimensional features. -

Introduction to Computational Social Choice
1 Introduction to Computational Social Choice Felix Brandta, Vincent Conitzerb, Ulle Endrissc, J´er^omeLangd, and Ariel D. Procacciae 1.1 Computational Social Choice at a Glance Social choice theory is the field of scientific inquiry that studies the aggregation of individual preferences towards a collective choice. For example, social choice theorists|who hail from a range of different disciplines, including mathematics, economics, and political science|are interested in the design and theoretical evalu- ation of voting rules. Questions of social choice have stimulated intellectual thought for centuries. Over time the topic has fascinated many a great mind, from the Mar- quis de Condorcet and Pierre-Simon de Laplace, through Charles Dodgson (better known as Lewis Carroll, the author of Alice in Wonderland), to Nobel Laureates such as Kenneth Arrow, Amartya Sen, and Lloyd Shapley. Computational social choice (COMSOC), by comparison, is a very young field that formed only in the early 2000s. There were, however, a few precursors. For instance, David Gale and Lloyd Shapley's algorithm for finding stable matchings between two groups of people with preferences over each other, dating back to 1962, truly had a computational flavor. And in the late 1980s, a series of papers by John Bartholdi, Craig Tovey, and Michael Trick showed that, on the one hand, computational complexity, as studied in theoretical computer science, can serve as a barrier against strategic manipulation in elections, but on the other hand, it can also prevent the efficient use of some voting rules altogether. Around the same time, a research group around Bernard Monjardet and Olivier Hudry also started to study the computational complexity of preference aggregation procedures. -

Parameter-Free Locality Sensitive Hashing for Spherical Range Reporting˚
Parameter-free Locality Sensitive Hashing for Spherical Range Reporting˚ Thomas D. Ahle, Martin Aumüller, and Rasmus Pagh IT University of Copenhagen, Denmark, {thdy, maau, pagh}@itu.dk July 21, 2016 Abstract We present a data structure for spherical range reporting on a point set S, i.e., reporting all points in S that lie within radius r of a given query point q (with a small probability of error). Our solution builds upon the Locality-Sensitive Hashing (LSH) framework of Indyk and Motwani, which represents the asymptotically best solutions to near neighbor problems in high dimensions. While traditional LSH data structures have several parameters whose optimal values depend on the distance distribution from q to the points of S (and in particular on the number of points to report), our data structure is essentially parameter-free and only takes as parameter the space the user is willing to allocate. Nevertheless, its expected query time basically matches that of an LSH data structure whose parameters have been optimally chosen for the data and query in question under the given space constraints. In particular, our data structure provides a smooth trade-off between hard queries (typically addressed by standard LSH parameter settings) and easy queries such as those where the number of points to report is a constant fraction of S, or where almost all points in S are far away from the query point. In contrast, known data structures fix LSH parameters based on certain parameters of the input alone. The algorithm has expected query time bounded by Optpn{tqρq, where t is the number of points to report and ρ P p0; 1q depends on the data distribution and the strength of the LSH family used. -

On Combinatorial Approximation Algorithms in Geometry Bruno Jartoux
On combinatorial approximation algorithms in geometry Bruno Jartoux To cite this version: Bruno Jartoux. On combinatorial approximation algorithms in geometry. Distributed, Parallel, and Cluster Computing [cs.DC]. Université Paris-Est, 2018. English. NNT : 2018PESC1078. tel- 02066140 HAL Id: tel-02066140 https://pastel.archives-ouvertes.fr/tel-02066140 Submitted on 13 Mar 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Université Paris-Est École doctorale MSTIC On Combinatorial Sur les algorithmes d’approximation Approximation combinatoires Algorithms en géométrie in Geometry Bruno Jartoux Thèse de doctorat en informatique soutenue le 12 septembre 2018. Composition du jury : Lilian Buzer ESIEE Paris Jean Cardinal Université libre de Bruxelles président du jury Guilherme Dias da Fonseca Université Clermont Auvergne rapporteur Jesús A. de Loera University of California, Davis rapporteur Frédéric Meunier École nationale des ponts et chaussées Nabil H. Mustafa ESIEE Paris directeur Vera Sacristán Universitat Politècnica de Catalunya Kasturi R. Varadarajan The University of Iowa rapporteur Last revised 16th December 2018. Thèse préparée au laboratoire d’informatique Gaspard-Monge (LIGM), équipe A3SI, dans les locaux d’ESIEE Paris. LIGM UMR 8049 ESIEE Paris Cité Descartes, bâtiment Copernic Département IT 5, boulevard Descartes Cité Descartes Champs-sur-Marne 2, boulevard Blaise-Pascal 77454 Marne-la-Vallée Cedex 2 93162 Noisy-le-Grand Cedex Bruno Jartoux 2018. -

2020 SIGACT REPORT SIGACT EC – Eric Allender, Shuchi Chawla, Nicole Immorlica, Samir Khuller (Chair), Bobby Kleinberg September 14Th, 2020
2020 SIGACT REPORT SIGACT EC – Eric Allender, Shuchi Chawla, Nicole Immorlica, Samir Khuller (chair), Bobby Kleinberg September 14th, 2020 SIGACT Mission Statement: The primary mission of ACM SIGACT (Association for Computing Machinery Special Interest Group on Algorithms and Computation Theory) is to foster and promote the discovery and dissemination of high quality research in the domain of theoretical computer science. The field of theoretical computer science is the rigorous study of all computational phenomena - natural, artificial or man-made. This includes the diverse areas of algorithms, data structures, complexity theory, distributed computation, parallel computation, VLSI, machine learning, computational biology, computational geometry, information theory, cryptography, quantum computation, computational number theory and algebra, program semantics and verification, automata theory, and the study of randomness. Work in this field is often distinguished by its emphasis on mathematical technique and rigor. 1. Awards ▪ 2020 Gödel Prize: This was awarded to Robin A. Moser and Gábor Tardos for their paper “A constructive proof of the general Lovász Local Lemma”, Journal of the ACM, Vol 57 (2), 2010. The Lovász Local Lemma (LLL) is a fundamental tool of the probabilistic method. It enables one to show the existence of certain objects even though they occur with exponentially small probability. The original proof was not algorithmic, and subsequent algorithmic versions had significant losses in parameters. This paper provides a simple, powerful algorithmic paradigm that converts almost all known applications of the LLL into randomized algorithms matching the bounds of the existence proof. The paper further gives a derandomized algorithm, a parallel algorithm, and an extension to the “lopsided” LLL. -

On Range Searching with Semialgebraic Sets*
Discrete Comput Geom 11:393~,18 (1994) GeometryDiscrete & Computational 1994 Springer-Verlag New York Inc. On Range Searching with Semialgebraic Sets* P. K. Agarwal 1 and J. Matou~ek 2 1 Computer Science Department, Duke University, Durham, NC 27706, USA 2 Katedra Aplikovan6 Matamatiky, Universita Karlova, 118 00 Praka 1, Czech Republic and Institut fiir Informatik, Freie Universit~it Berlin, Arnirnallee 2-6, D-14195 Berlin, Germany matou~ek@cspguk 11.bitnet Abstract. Let P be a set of n points in ~d (where d is a small fixed positive integer), and let F be a collection of subsets of ~d, each of which is defined by a constant number of bounded degree polynomial inequalities. We consider the following F-range searching problem: Given P, build a data structure for efficient answering of queries of the form, "Given a 7 ~ F, count (or report) the points of P lying in 7." Generalizing the simplex range searching techniques, we give a solution with nearly linear space and preprocessing time and with O(n 1- x/b+~) query time, where d < b < 2d - 3 and ~ > 0 is an arbitrarily small constant. The acutal value of b is related to the problem of partitioning arrangements of algebraic surfaces into cells with a constant description complexity. We present some of the applications of F-range searching problem, including improved ray shooting among triangles in ~3 1. Introduction Let F be a family of subsets of the d-dimensional space ~d (d is a small constant) such that each y e F can be described by some fixed number of real parameters (for example, F can be the set of balls, or the set of all intersections of two ellipsoids, * Part of the work by P. -

New Data Structures for Orthogonal Range Searching
Alcom-FT Technical Report Series ALCOMFT-TR-01-35 New Data Structures for Orthogonal Range Searching Stephen Alstrup∗ The IT University of Copenhagen Glentevej 67, DK-2400, Denmark [email protected] Gerth Stølting Brodal† BRICS ‡ Department of Computer Science University of Aarhus Ny Munkegade, DK-8000 Arhus˚ C, Denmark [email protected] Theis Rauhe§ The IT University of Copenhagen Glentevej 67, DK-2400, Denmark [email protected] 5th April 2001 Abstract We present new general techniques for static orthogonal range searching problems in two and higher dimensions. For the general range reporting problem in R3, we achieve ε query time O(log n + k) using space O(n log1+ n), where n denotes the number of stored points and k the number of points to be reported. For the range reporting problem on ε an n n grid, we achieve query time O(log log n + k) using space O(n log n). For the two-dimensional× semi-group range sum problem we achieve query time O(log n) using space O(n log n). ∗Partially supported by a grant from Direktør Ib Henriksens Fond. †Partially supported by the IST Programme of the EU under contract number IST-1999-14186 (ALCOM- FT). ‡Basic Research in Computer Science, Center of the Danish National Research Foundation. §Partially supported by a grant from Direktør Ib Henriksens Fond. Part of the work was done while the author was at BRICS. 1 1 Introduction Let P be a finite set of points in Rd and Q a query range in Rd. Range searching is the problem of answering various types of queries about the set of points which are contained within the query range, i.e., the point set P Q. -
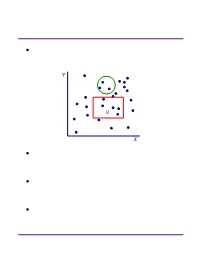
Range Searching
Range Searching ² Data structure for a set of objects (points, rectangles, polygons) for efficient range queries. Y Q X ² Depends on type of objects and queries. Consider basic data structures with broad applicability. ² Time-Space tradeoff: the more we preprocess and store, the faster we can solve a query. ² Consider data structures with (nearly) linear space. Subhash Suri UC Santa Barbara Orthogonal Range Searching ² Fix a n-point set P . It has 2n subsets. How many are possible answers to geometric range queries? Y 5 Some impossible rectangular ranges 6 (1,2,3), (1,4), (2,5,6). 1 4 Range (1,5,6) is possible. 3 2 X ² Efficiency comes from the fact that only a small fraction of subsets can be formed. ² Orthogonal range searching deals with point sets and axis-aligned rectangle queries. ² These generalize 1-dimensional sorting and searching, and the data structures are based on compositions of 1-dim structures. Subhash Suri UC Santa Barbara 1-Dimensional Search ² Points in 1D P = fp1; p2; : : : ; png. ² Queries are intervals. 15 71 3 7 9 21 23 25 45 70 72 100 120 ² If the range contains k points, we want to solve the problem in O(log n + k) time. ² Does hashing work? Why not? ² A sorted array achieves this bound. But it doesn’t extend to higher dimensions. ² Instead, we use a balanced binary tree. Subhash Suri UC Santa Barbara Tree Search 15 7 24 3 12 20 27 1 4 9 14 17 22 25 29 1 3 4 7 9 12 14 15 17 20 22 24 25 27 29 31 u v xlo =2 x hi =23 ² Build a balanced binary tree on the sorted list of points (keys). -

Further Results on Colored Range Searching
28:2 Further Results on Colored Range Searching colored range reporting: report all the distinct colors in the query range. colored “type-1” range counting: find the number of distinct colors in the query range. colored “type-2” range counting: report the number of points of color χ in the query range, for every color χ in the range. In this paper, we focus on colored range reporting and type-2 colored range counting. Note that the output size in both instances is equal to the number k of distinct colors in the range, and we aim for query time bounds that depend linearly on k, of the form O(f(n) + kg(n)). Naively using an uncolored range reporting data structure and looping through all points in the range would be too costly, since the number of points in the range can be significantly larger than k. 1.1 Colored orthogonal range reporting The most basic version of the problem is perhaps colored orthogonal range reporting: report the k distinct colors inside an orthogonal range (an axis-aligned box). It is not difficult to obtain an O(n polylog n)-space data structure with O(k polylog n) query time [22] for any constant dimension d: one approach is to directly modify the d-dimensional range tree [15, 43], and another approach is to reduce colored range reporting to uncolored range emptiness [26] (by building a one-dimensional range tree over the colors and storing a range emptiness structure at each node). Both approaches require O(k polylog n) query time rather than O(polylog n + k) as in traditional (uncolored) orthogonal range searching: the reason is that in the first approach, each color may be discovered polylogarithmically many times, whereas in the second approach, each discovered color costs us O(log n) range emptiness queries, each of which requires polylogarithmic time.