Optimizing Click-Through in Online Rankings for Partially Anonymous Consumers∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Rpa Demystified
RPA in Action for Healthcare A Challenging Council Merger DECEMBER-JANUARY 2018 RPA DEMYSTIFIED OPEN EMAIL COPY PASTE REPEAT Print Post Approved: 100002740 Ensuring the Failure of Your Knowledge Management Efforts A records manager’s job is never done..with EzeScan! Ready To Help: 1300 EZESCAN (1300 393 722 ) www.ezescan.com.au Finance looks to a new path to digital According the new Finance Discussion Paper, “In early 2018, Finance undertook a 12-week Demonstration of Concept (the record-keeping nirvana Demonstration) to test the concept of automating records capture and categorisation via machine learning and semantic data technologies. Through the Demonstration, it was concluded that while the Government is best placed to describe its functions, industry is working towards automation and would be best placed to provide digital records management systems that would be compatible with the government developed Australian Government Records Interoperability Framework (AGRIF). One industry vendor responded, “I think this means they have decided it is all too hard and could one or more of you vendors do it for us at your cost but to our theoretical and incomplete design? “I guess it will be one of those government projects that goes on More than three years into its multi-million dollar quest to for years and years costing a fortune and then is finally cancelled revolutionise digital record-keeping practices across Federal because technology has passed it by.” government, Australia’s Department of Finance has announced There is also industry concern that the co-design approach another shift in direction and a “review” of the current (and this whole project overall) puts a disproportionately heavy moratorium on new investment in records management burden on SMEs. -

OSINT) Analyst Overtly Passive / Covertly Active Surveillance / Reconnaissance Observation / Exploration Eye / Spy
Open Source Intelligence (OSINT) Analyst Overtly Passive / Covertly Active Surveillance / Reconnaissance Observation / Exploration Eye / Spy PREFACE This deskside/pocket smartbook contains information to assist you, the open source intelligence analyst, in carrying out your research responsibilities in a Intelligence Oversightmanner that first of all adhere to intelligence oversight and follow the guide lines of AR 381-10, Executive Order 12333, and unit standard operating procedures (SOP). The second is to practice and implement effective operational security (OPSEC) measures during data and information collection activities online. A fine line exists between collection and acquisition, and examples will be pointed out throughout the handbook. This handout is not written specifically for the military active or passive OSINT Analyst but rather as an all-purpose guide for anyone doing research. The one big advantage for the passive OSINT Analyst is that it does not require interaction with the mark. Therefore, it poses little risk since it does not alert the target to the presence of the analyst. If a technique violates Intelligence Oversight and OPSEC, then common sense must take center stage. For those in the civilian community (law enforcement, journalists, researchers, etc.), you are bound by a different set of rules and have more latitude. One important thing to keep in mind is that when threats are mentioned the majority tend to think they are military in nature. We think of Iran, North Korea, and other countries with a military capability. That is not the case. Threats can be the lone wolf types, a disgruntled worker, someone calling in a bomb threat to a hospital, etc. -

List Created By: Jonathan Kidder (Wizardsourcer.Com) Contact
List created by: Jonathan Kidder (WizardSourcer.com) Contact Finding Extensions: Adorito: Email Lookup for LinkedIn. Aeroleads Prospect Finder: Find Prospects and Send them to AeroLeads. AmazingHiring: Search for social media profiles across the web. This tool helps find personal contact information and so much more. Clearbit Connect: Find contact information on social media profiles. Connectifier: Search for social media profiles and contact information across the web. (Recently acquired by LinkedIn). Connectifier Social Links: Find social media profiles on individual LinkedIn profiles. ContactOut: Find anyone's email and phone number on LinkedIn. Evercontact: Is the highest-rated Contact Management App on Google Apps. Hiretual: A sourcing tool that offers contact information and so much more. Hunter: An extension that helps find corporate email addresses on LinkedIn profiles. Improver: Find contact information from social media profiles. Lead Generator: Get private emails of LinkedIn profiles and check their willingness to change a job. Leadiq.io: Browse LinkedIn Profiles, AngelList Profiles, or grab LinkedIn search results and import into Google Sheets. Lusha: Find contact information on individual LinkedIn profiles. ManyContacts: Check any email address & discover Social Profiles. MightySourcer: Helps find contact info. People.Camp: Social Media Sourcing and Application/Lead Tracking Software. People Finder: Find leads, get emails, phone numbers and other contact data. Save and share your LinkedIn connections. People Search: Find contact information and resumes on social media profiles. Prophet II: Find contact information from social media profiles. SeekOut: Find contact information from social media profiles. Sellhack: Sales Helper - Social profiles add on to gather additional info about leads. SignalHire: Find contact information on individual social media profiles. -

Download Download
International Journal of Management & Information Systems – Fourth Quarter 2011 Volume 15, Number 4 History Of Search Engines Tom Seymour, Minot State University, USA Dean Frantsvog, Minot State University, USA Satheesh Kumar, Minot State University, USA ABSTRACT As the number of sites on the Web increased in the mid-to-late 90s, search engines started appearing to help people find information quickly. Search engines developed business models to finance their services, such as pay per click programs offered by Open Text in 1996 and then Goto.com in 1998. Goto.com later changed its name to Overture in 2001, and was purchased by Yahoo! in 2003, and now offers paid search opportunities for advertisers through Yahoo! Search Marketing. Google also began to offer advertisements on search results pages in 2000 through the Google Ad Words program. By 2007, pay-per-click programs proved to be primary money-makers for search engines. In a market dominated by Google, in 2009 Yahoo! and Microsoft announced the intention to forge an alliance. The Yahoo! & Microsoft Search Alliance eventually received approval from regulators in the US and Europe in February 2010. Search engine optimization consultants expanded their offerings to help businesses learn about and use the advertising opportunities offered by search engines, and new agencies focusing primarily upon marketing and advertising through search engines emerged. The term "Search Engine Marketing" was proposed by Danny Sullivan in 2001 to cover the spectrum of activities involved in performing SEO, managing paid listings at the search engines, submitting sites to directories, and developing online marketing strategies for businesses, organizations, and individuals. -

Inclusiva-Net Nuevas Dinámicas Artísticas En Modo Web 2
Inclusiva-net Nuevas dinámicas artísticas en modo web 2 Primer encuentro Inclusiva-net Dirigido por Juan Martín Prada Julio, 2007. MEDIALAB-PRADO · Madrid www.medialab-prado.es ISBN: 978-84-96102-35-4 Edita: Área de las Artes. Dirección General de Promoción y Proyectos Culturales. Madrid. 2007 © de esta edición electrónica 2007: Ayuntamiento de Madrid © Textos e imágenes: los autores ÍNDICE Prefacio Juan Martín Prada 5 La “Web 2.0” como nuevo contexto para las prácticas artísticas Juan Martín Prada 6 Isubmit, Youprofile, WeRank La deconstrucción del mito de la Web 2.0 Geert Lovink 23 Telepatía colectiva 2.0 (Teoría de las multitudes interconectadas) José Luis Brea 39 Deslices de un avatar: prestidigitación y praxis artística en Second Life Mario-Paul Martínez Fabre y Tatiana Sentamans 55 Escenarios emergentes en las prácticas sociales y artísticas con tecnologías móviles Efraín Foglia 82 El artista como generador de swarmings. Cuestionando la sociedad red Carlos Seda 93 Procesos culturales en red Perspectivas para una política cultural digital Ptqk (Maria Perez) 110 Fósiles y monstruos: comunidades y redes sociales artísticas en el Estado Español Lourdes Cilleruelo 126 Tempus Fugit Cuando arte y tecnología encuentran a la persona equivocada Raquel Herrera 138 Impacto de las tecnologías web 2.0 En la comunicación cultural Javier Celaya 149 “No List Available” Web 2.0 para rescatar a los museos libios del olvido institucional. Prototipo para el Museo Jamahiriya de Trípoli lamusediffuse 158 “Arquitecturapública”: El concurso de arquitectura -

OSINT Handbook September 2020
OPEN SOURCE INTELLIGENCE TOOLS AND RESOURCES HANDBOOK 2020 OPEN SOURCE INTELLIGENCE TOOLS AND RESOURCES HANDBOOK 2020 Aleksandra Bielska Noa Rebecca Kurz, Yves Baumgartner, Vytenis Benetis 2 Foreword I am delighted to share with you the 2020 edition of the OSINT Tools and Resources Handbook. Once again, the Handbook has been revised and updated to reflect the evolution of this discipline, and the many strategic, operational and technical challenges OSINT practitioners have to grapple with. Given the speed of change on the web, some might question the wisdom of pulling together such a resource. What’s wrong with the Top 10 tools, or the Top 100? There are only so many resources one can bookmark after all. Such arguments are not without merit. My fear, however, is that they are also shortsighted. I offer four reasons why. To begin, a shortlist betrays the widening spectrum of OSINT practice. Whereas OSINT was once the preserve of analysts working in national security, it now embraces a growing class of professionals in fields as diverse as journalism, cybersecurity, investment research, crisis management and human rights. A limited toolkit can never satisfy all of these constituencies. Second, a good OSINT practitioner is someone who is comfortable working with different tools, sources and collection strategies. The temptation toward narrow specialisation in OSINT is one that has to be resisted. Why? Because no research task is ever as tidy as the customer’s requirements are likely to suggest. Third, is the inevitable realisation that good tool awareness is equivalent to good source awareness. Indeed, the right tool can determine whether you harvest the right information. -

Archivistica Italiana
ASSOCIAZIONE NAZIONALE ARCHIVISTICA ITALIANA ARCHIVI a. IV-n.1 (gennaio-giugno 2009) Direttore responsabile: Giorgetta Bonfiglio-Dosio Comitato scientifico e di redazione Isabella Orefice (vice-direttore), Concetta Damiani, Antonio Dentoni Litta, Luciana Duranti, Ferruccio Ferruzzi, Antonio Romiti, Diana Toccafondi, Carlo Vivoli, Gilberto Zacché Segreteria di redazione: Biagio Barbano Inviare i testi a: [email protected] I testi proposti saranno sottoposti, per l’approvazione, all’esame di referees e del Comitato scientifico e di redazione. I testi non pubblicati non verranno restituiti. La rivista non assume responsabilità di alcun tipo circa le affermazioni e i giudizi espressi dagli autori. Periodicità semestrale ISSN 1970-4070 ISBN 978-88-6129-096-9 Iscritta nel Registro Stampa del Tribunale di Padova il 3/8/2006 al n. 2036 Abbonamento per il 2007: Italia euro 45,00 – Estero euro 60,00 da sottoscrivere con: ANAI Associazione Nazionale Archivistica Italiana via Giunio Bazzoni, 15 – 00195 Roma - Tel./Fax: 06 37517714 web: www.anai.org Conto corrente postale: 17699034; Partita IVA: 05106681009; Codice fiscale: 80227410588 Tariffe della pubblicità tabellare: - per testi e immagini in bianco e nero: - 1000,00 euro per 1 pagina - 600,00 euro per mezza pagina - 300,00 euro per un quarto di pagina - per pubblicità a colori, l’inserzionista pagherà le spese tipografiche aggiuntive, oltre al costo del b/n. La pubblicità verrà collocata secondo le esigenze di impaginazione; eventuali richieste particolari verranno valutate. L’inserimento della pubblicità nella rivista non presuppone approvazione o valutazione alcuna dei prodotti pubblicizzati da parte dell’Associazione. Archivi a. IV - n. 1 Sommario Comunicato del Direttore GIORGETTA BONFIGLIO-DOSIO Allineare la rivista agli standard richiesti dall’Institute for Scien- p. -

University of Mysore Guidelines and Regulations Leading to Master of Library and Information Science (Two Years- Semester Scheme Under Cbcs)
UNIVERSITY OF MYSORE Department of Studies in Library and Information Science Manasagangotri, Mysuru-570006 Regulations and Syllabus Master of library and information science (M.L.I.Sc.) (Two-year semester scheme) Under Choice Based Credit System (CBCS) From 2018-19 onwards 1 UNIVERSITY OF MYSORE GUIDELINES AND REGULATIONS LEADING TO MASTER OF LIBRARY AND INFORMATION SCIENCE (TWO YEARS- SEMESTER SCHEME UNDER CBCS) Course Details Name of the Department : Department of Studies in Library and Information Science Subject : Library and Information Science Faculty : Science and Technology Name of the Course : Master of Library and Information Science (MLISc) Duration of the Course : 2 years- divided into 4 semesters Program Outcomes Obtain the knowledge and skills which helps them to provide leadership in creating, supporting and enhancing library and information services with a view to improving ‘information literacy’ and maintaining access to information for all. Perform administrative, service, and technical functions of professional practice in all types libraries and information centres (academic libraries, public libraries, special libraries, national libraries, and digital libraries) by demonstrating skills in information resources; reference and user service; administration and management; organization of recorded knowledge and information. Acquire the quality of critical thinking in LIS literature and related fields which equip them to carry out research in LIS domain. Acquire the ability promote high professionalism and service standards. Develop and evaluate resources and programs to suit the needs of many different kinds of users. Ready to use existing and emerging technologies to meet needs in libraries and information centres. Participate actively in the professional development, develop technology and promote positive social transformation. -

Download This PDF File
Library Technology R E P O R T S Expert Guides to Library Systems and Services Podcast Literacy: Educational, Accessible, and Diverse Podcasts for Library Users Nicole Hennig alatechsource.org American Library Association About the Author Library Technology Nicole Hennig is an independent user experience pro- REPORTS fessional, helping librarians and educators effectively use mobile technologies. See her educational offerings ALA TechSource purchases fund advocacy, awareness, and at http://nicolehennig.com. She is the author of sev- accreditation programs for library professionals worldwide. eral books, including Apps for Librarians: Using the Best Volume 53, Number 2 Mobile Technology to Educate, Create, and Engage. Her Podcast Literacy: Educational, Accessible, and Diverse online courses, such as Apps for Librarians & Educators, Podcasts for Library Users have enabled librarians from all types of institutions to ISBN: 978-0-8389-5985-5 effectively implement mobile technologies in their pro- American Library Association grams and services. Her newsletter, Mobile Apps News, 50 East Huron St. helps librarians stay current with mobile technologies. Chicago, IL 60611-2795 USA Hennig worked for the MIT Libraries for fourteen years alatechsource.org as head of user experience and web manager. She is the 800-545-2433, ext. 4299 312-944-6780 winner of several awards, including the MIT Excellence 312-280-5275 (fax) Award for Innovative Solutions. Advertising Representative Samantha Imburgia [email protected] Abstract 312-280-3244 Editors Podcasts are experiencing a renaissance today. More Patrick Hogan high-quality programming is available for more [email protected] diverse audiences than ever before. 312-280-3240 When librarians are knowledgeable about pod- Samantha Imburgia casts, how to find the best ones, and what purposes [email protected] they serve, we can point our users to the very best 312-280-3244 content and help increase digital literacy. -
To Download the Syllabus
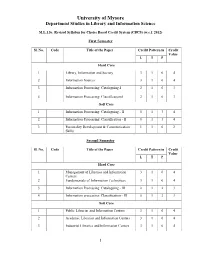
University of Mysore Department Studies in Library and Information Science M.L.I.Sc. Revised Syllabus for Choice Based Credit System (CBCS) (w.e.f. 2012) First Semester Sl. No. Code Title of the Paper Credit Pattern in Credit Value L T P Hard Core 1 Library, Information and Society 3 1 0 4 2 Information Sources 3 1 0 4 3 Information Processing: Cataloguing-I 2 1 0 3 4 Information Processing: Classification-I 2 1 0 3 Soft Core 1 Information Processing: Cataloguing - II 0 1 3 4 2 Information Processing: Classification - II 0 1 3 4 3 Personality Development & Communication 1 1 0 2 Skills Second Semester Sl. No. Code Title of the Paper Credit Pattern in Credit Value L T P Hard Core 1 Management of Libraries and Information 3 1 0 4 Centers 2 Fundamentals of Information Technology 3 1 0 4 3 Information Processing: Cataloguing - III 0 1 2 3 4 Information processing: Classification - III 0 1 2 3 Soft Core 1 Public Libraries and Information Centers 3 1 0 4 2 Academic Libraries and Information Centers 3 1 0 4 3 Industrial Libraries and Information Centers 3 1 0 4 1 4 Bio-Medical Libraries and Information Centers 3 1 0 4 5 Corporate Libraries and Information Centers 3 1 0 4 Open Elective 1 E-Publishing 3 1 0 4 2 Digital Information Management 3 1 0 4 Third Semester Sl. No. Code Title of the Paper Credit Pattern in Credit Value L T P Hard Core 1 Information Retrieval 3 1 0 4 2 Library Automation and Networks 3 1 0 4 3 Library Automation Software 0 1 3 4 Soft Core 1 Marketing of Information Products and 3 1 0 4 Services 2 Conservation and Preservation of Information 3 1 0 4 Resources 3 Users and User Studies 3 1 0 4 Open Elective 1 Web 2.0 3 1 0 4 2 Electronic Information Sources and Services 3 1 0 4 Fourth Semester Sl. -

How Does the Search Process Support Inquiry Learning?
2 ESSENTIAL QUESTIONS How does the search process support inquiry learning? What are the best instructional strategies to teach the search process? Which search engines best support students' searching and exploration? Searching the Web 23 Alisha slips off her iPod earbuds and sits down at the computer; she has about 15 minutes before she meets with her team. She's thinking about their last meeting when they brainstormed questions and discussed what they each knew about the topic. She pulls up the Research Wiki set up by Mr. Rodriquez, her teacher-librarian. He always uses a wiki so kids can work collaboratively in identifying the best search tools. A few of the search engines peak her interest as she scans the annotated list; she clicks on Quintura to see how the tag cloud is used. As she watches the screencast, she opens another window and follows along experimenting with different keywords. Satisfied that she has mastered the new search engine, she returns to Google remem bering a strategy Mr. Rodriquez recommended at the class research session- "type define: search term" to get definitions. She uses Google all the time but did not realize that it had advanced searching strategies. Cool, it worked! She scans the list of 20 or more definitions of global warming, looking at the URLs. She tags the Web page in her shared del.icio. us account to share with her teammates. She moves to another search tool, Ask.com. When the class was comparing search engines, she noticed that Ask.com had a great results page-it gave listings of videos and up-to-date news on the search term and offered suggestions to narrow and broaden the search. -
Optimizing Click-Through in Online Rankings for Partially Anonymous Consumers∗
Optimizing Click-through in Online Rankings for Partially Anonymous Consumers∗ Babur De los Santosy Sergei Koulayevz May 28, 2013 First Version: December 21, 2011 Abstract The vast amount of information available online has revolutionized the way firms present consumers with product options. Presenting the best alternatives first reduces search costs asso- ciated with a consumer finding the right product. We use novel data on consumer click-stream behavior from a major web-based hotel comparison platform to estimate a random coefficient discrete choice model and propose an optimal ranking tailored to anonymous consumers that differ in their partially revealed price sensitivity. We are able to customize rankings by relating price sensitivity to request parameters, such as the length of stay, number of guests, and day of the week of the stay. In contrast to a myopic popularity-based ranking, our model accounts for the rapidly changing prices that characterize the hotel industry and consumers' search re- finement strategies, such as sorting and filtering of product options. We propose a method of determining the hotel ordering that maximizes consumers' click-through rates (CTR) based on the information available to the platform at that time, its assessment of consumers' preferences, and the expected consumer type based on request parameters from the current visit. We find that CTRs almost double when consumers are provided with customized rankings that reflect the price/quality trade-off inferred from the consumer's request parameters. We show that