HAPPY VALLEY BAND a Dissertation Submitted in Parti
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2021 Contemporary Women Composers Music Catalog
Catalog of Recent Highlights of Works by Women Composers Spring 2021 Agócs, Kati, 1975- Debrecen Passion : For Twelve Female Voices and Chamber Orchestra (2015). ©2015,[2020] Spiral; Full Score; 43 cm.; 94 p. $59.50 Needham, MA: Kati Agócs Music Immutable Dreams : For Pierrot Ensemble (2007). ©2007,[2020] Spiral; Score & 5 Parts; 33 $59.50 Needham, MA: Kati Agócs Music Rogue Emoji : For Flute, Clarinet, Violin and Cello (2019). ©2019 Score & 4 Parts; 31 cm.; 42, $49.50 Needham, MA: Kati Agócs Music Saint Elizabeth Bells : For Violoncello and Cimbalom (2012). ©2012,[2020] Score; 31 cm.; 8 p. $34.50 Needham, MA: Kati Agócs Music Thirst and Quenching : For Solo Violin (2020). ©2020 Score; 31 cm.; 4 p. $12.50 Needham, MA: Kati Agócs Music Albert, Adrienne, 1941- Serenade : For Solo Bassoon. ©2020 Score; 28 cm.; 4 p. $15.00 Los Angeles: Kenter Canyon Music Tango Alono : For Solo Oboe. ©2020 Score; 28 cm.; 4 p. $15.00 Los Angeles: Kenter Canyon Music Amelkina-Vera, Olga, 1976- Cloches (Polyphonic Etude) : For Solo Guitar. ©2020 Score; 30 cm.; 3 p. $5.00 Saint-Romuald: Productions D'oz DZ3480 9782897953973 Ensueño Y Danza : For Guitar. ©2020 Score; 30 cm.; 8 p. $8.00 Saint-Romuald: Productions D'oz DZ3588 9782897955052 Andrews, Stephanie K., 1968- On Compassion : For SATB Soli, SATB Chorus (Divisi) and Piano (2014) ©2017 Score - Download; 26 cm.; 12 $2.35 Boston: Galaxy Music 1.3417 Arismendi, Diana, 1962- Aguas Lustrales : For String Quartet (1992). ©2019 Score & 4 Parts; 31 cm.; 15, $40.00 Minot, Nd: Latin American Frontiers International Pub. -

Robert Starer: a Remembrance 3
21ST CENTURY MUSIC AUGUST 2001 INFORMATION FOR SUBSCRIBERS 21ST-CENTURY MUSIC is published monthly by 21ST-CENTURY MUSIC, P.O. Box 2842, San Anselmo, CA 94960. ISSN 1534-3219. Subscription rates in the U.S. are $84.00 (print) and $42.00 (e-mail) per year; subscribers to the print version elsewhere should add $36.00 for postage. Single copies of the current volume and back issues are $8.00 (print) and $4.00 (e-mail) Large back orders must be ordered by volume and be pre-paid. Please allow one month for receipt of first issue. Domestic claims for non-receipt of issues should be made within 90 days of the month of publication, overseas claims within 180 days. Thereafter, the regular back issue rate will be charged for replacement. Overseas delivery is not guaranteed. Send orders to 21ST-CENTURY MUSIC, P.O. Box 2842, San Anselmo, CA 94960. e-mail: [email protected]. Typeset in Times New Roman. Copyright 2001 by 21ST-CENTURY MUSIC. This journal is printed on recycled paper. Copyright notice: Authorization to photocopy items for internal or personal use is granted by 21ST-CENTURY MUSIC. INFORMATION FOR CONTRIBUTORS 21ST-CENTURY MUSIC invites pertinent contributions in analysis, composition, criticism, interdisciplinary studies, musicology, and performance practice; and welcomes reviews of books, concerts, music, recordings, and videos. The journal also seeks items of interest for its calendar, chronicle, comment, communications, opportunities, publications, recordings, and videos sections. Typescripts should be double-spaced on 8 1/2 x 11 -inch paper, with ample margins. Authors with access to IBM compatible word-processing systems are encouraged to submit a floppy disk, or e-mail, in addition to hard copy. -

Brian Eno • • • His Music and the Vertical Color of Sound
BRIAN ENO • • • HIS MUSIC AND THE VERTICAL COLOR OF SOUND by Eric Tamm Copyright © 1988 by Eric Tamm DEDICATION This book is dedicated to my parents, Igor Tamm and Olive Pitkin Tamm. In my childhood, my father sang bass and strummed guitar, my mother played piano and violin and sang in choirs. Together they gave me a love and respect for music that will be with me always. i TABLE OF CONTENTS DEDICATION ............................................................................................ i TABLE OF CONTENTS........................................................................... ii ACKNOWLEDGEMENTS ....................................................................... iv CHAPTER ONE: ENO’S WORK IN PERSPECTIVE ............................... 1 CHAPTER TWO: BACKGROUND AND INFLUENCES ........................ 12 CHAPTER THREE: ON OTHER MUSIC: ENO AS CRITIC................... 24 CHAPTER FOUR: THE EAR OF THE NON-MUSICIAN........................ 39 Art School and Experimental Works, Process and Product ................ 39 On Listening........................................................................................ 41 Craft and the Non-Musician ................................................................ 44 CHAPTER FIVE: LISTENERS AND AIMS ............................................ 51 Eno’s Audience................................................................................... 51 Eno’s Artistic Intent ............................................................................. 55 “Generating and Organizing Variety in -

National Endowment for the Arts Aual Report 1988
Z < oO National Endowment for the Arts Washington, D.C. Dear Mr. President: I have the honor to submit to you the Annual Report of the National Endowment for the Arts and the National Council on the Arts for the Fiscal Year ended September 30, 1988. Respectfully, Hugh Southern Acting Chairman The President The White House Washington, D.C. May 1989 CONTENTS CHAIRMAN’S STATEMENT v THE AGENCY AND ITS FUNCTIONS vi THE NATIONAL COUNCIL ON THE ARTS vii PROGRAMS 1 Dance 3 Design Arts 19 Expansion Arts 31 Folk Arts 53 Inter Arts 63 Literature 77 Media Arts: Filrn/Radio/Television 89 Museum 103 Music 127 Opera-Musical Theater 163 Theater 173 Visual Arts 187 OFFICE FOR PUBLIC PARTNERSHIP 203 Arts in Education 205 Local Programs 211 State Programs 215 OFFICE FOR PRIVATE PARTNERSHIP 219 Challenge 221 Advancement 226 OFFICE OF POLICY, PLANNING, AND RESEARCH 229 Fellowship Program for Arts Managers 230 Intemational Activities 233 Research Division 236 Office for Special Constituencies 237 APPENDIX 239 Statement of Mission 240 Overview and Challenge Advisory Panels 241 Financial Summary 247 History of Authorizations and Appropriations 248 iii CHAIRMAN’ S STATEMENT "These sudden ends of time must give of the arts in our nation’s schools, gan in paying tribute to 12 recipients of us pause..." Waming of a "major gap between the the National Medal of Arts--including Year’s End stated commitment and resources avail- architect I.M. Pei, choreographer Richard Wilbur able to arts education and the actual Jerome Robbins, and actress Helen Poet Laureate of the United States practice of arts education in schools," Hayes--and to ten design professionals, 1987-88 the report is motivating school districts winners of Presidential Design Awards throughout the country to take its for such Federal projects as Tampa’s recommendations to heart. -
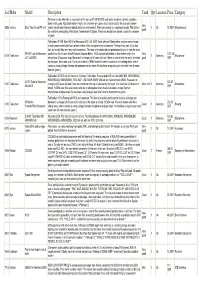
Lot Make Model Description Cond Qty Location Price Category We Have No Idea What This Is - Some Sort of Film Sync Unit? UNTESTED, Sold As Is
Lot Make Model Description Cond Qty Location Price Category We have no idea what this is - some sort of film sync unit? UNTESTED, sold as is. Excellent cosmetic condition - looks hardly used. Adjustable bottom height, one chunky 4-pin captive lead, and a lead for the auto-start system Very 5555 various Elmo Tape Sound FP unit (which almost looks like early optical cable, but who knows?). The mains socket is a Japanese two-pin. This is from 1 Uk 15 GBP Miscellaneous good the collection amassed by Felix Visser, former head of Synton. They have mostly been stored unused for a number of years. Telefunken VF14M Tube Nr214 for Neumann U47, U48. NOS. Hand selected. Maybe other auctions were cheaper. In most cases these tubes had not been tested in the microphone and a tubetester. Perhaps they work, if you had luck, but mostly they are noisy and microphonic. This tube is handselected and professionally burnt in from the most VF14M Tube for Neumann qualified tec for this sort of stuff (Andreas Grosser Berlin). NOS and carefully tested on tube testers and in the Very 1221,06 6139 Telefunken 1 Germany Microphone U47 U48 NOS microphone (3 days non stop). Because it is vintage (ca 50 years old) and I have no control over the way it is treated good GBP by the buyer, this is sold as is. No return or refund. (VEMIA note: this seller knows what he is talking about when it comes to classy vintage German microphones and pre-amps. He has been a regular buyer and seller here for more than ten years.) Telefunken AC701 Tube for Neumann, Schoeps, Telefunken, Brauner and AKG mics like M49, M50, KM54(KM254), KM53(KM253), KM56(KM256), SM2, M221, C60, M269, SM69, VMA etc etc. -

The Machine As Artist • Frederic Fol Leymarie, Juliette Bessette and G.W
The Machine as Art/ The Machine as Artist • Frederic Fol Leymarie, Juliette Bessette Smith and G.W. The Machine as Art/ The Machine as Artist Edited by Frederic Fol Leymarie, Juliette Bessette and G.W. Smith Printed Edition of the Special Issues Published in Arts www.mdpi.com/journal/arts The Machine as Art/ The Machine as Artist The Machine as Art/ The Machine as Artist Editors Frederic Fol Leymarie Juliette Bessette G.W. Smith MDPI • Basel • Beijing • Wuhan • Barcelona • Belgrade • Manchester • Tokyo • Cluj • Tianjin Editors Frederic Fol Leymarie Juliette Bessette G.W. Smith University of London Sorbonne University Space Machines Corporation UK France USA Editorial Office MDPI St. Alban-Anlage 66 4052 Basel, Switzerland This is a reprint of articles from the Special Issues published online in the open access journal Arts (ISSN 2076-0752) (available at: https://www.mdpi.com/journal/arts/special issues/Machine Art and https://www.mdpi.com/journal/arts/special issues/Machine Artist). For citation purposes, cite each article independently as indicated on the article page online and as indicated below: LastName, A.A.; LastName, B.B.; LastName, C.C. Article Title. Journal Name Year, Article Number, Page Range. ISBN 978-3-03936-064-2 (Hbk) ISBN 978-3-03936-065-9 (PDF) Cover image courtesy of Liat Grayver (www.liatgrayver.com). A detail of her robotically-assisted painting “LG02”. c 2020 by the authors. Articles in this book are Open Access and distributed under the Creative Commons Attribution (CC BY) license, which allows users to download, copy and build upon published articles, as long as the author and publisher are properly credited, which ensures maximum dissemination and a wider impact of our publications. -

CONCERT REVIEWS Fresh Choice 3 WILLIAM SUSMAN
21ST CENTURY MUSIC NOVEMBER 2001 INFORMATION FOR SUBSCRIBERS 21ST-CENTURY MUSIC is published monthly by 21ST-CENTURY MUSIC, P.O. Box 2842, San Anselmo, CA 94960. ISSN 1534-3219. Subscription rates in the U.S. are $84.00 (print) and $42.00 (e-mail) per year; subscribers to the print version elsewhere should add $36.00 for postage. Single copies of the current volume and back issues are $8.00 (print) and $4.00 (e-mail) Large back orders must be ordered by volume and be pre-paid. Please allow one month for receipt of first issue. Domestic claims for non-receipt of issues should be made within 90 days of the month of publication, overseas claims within 180 days. Thereafter, the regular back issue rate will be charged for replacement. Overseas delivery is not guaranteed. Send orders to 21ST-CENTURY MUSIC, P.O. Box 2842, San Anselmo, CA 94960. e-mail: [email protected]. Typeset in Times New Roman. Copyright 2001 by 21ST-CENTURY MUSIC. This journal is printed on recycled paper. Copyright notice: Authorization to photocopy items for internal or personal use is granted by 21ST-CENTURY MUSIC. INFORMATION FOR CONTRIBUTORS 21ST-CENTURY MUSIC invites pertinent contributions in analysis, composition, criticism, interdisciplinary studies, musicology, and performance practice; and welcomes reviews of books, concerts, music, recordings, and videos. The journal also seeks items of interest for its calendar, chronicle, comment, communications, opportunities, publications, recordings, and videos sections. Typescripts should be double-spaced on 8 1/2 x 11 -inch paper, with ample margins. Authors with access to IBM compatible word-processing systems are encouraged to submit a floppy disk, or e-mail, in addition to hard copy.