Deep Learning and Improved Particle Swarm Optimization Based Multimodal Brain Tumor Classi�Cation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Full Flow and I Started Recovering Fast
JULY 11-17, 2021 HERE . NOW P 3,4 1 2 3 4 5 6 7 8 SUNDAY POST July 11-17, 2021 MIXED BAG Weekly schedule My music teacher Guru Ratan Kumar Pujhari visits me every Sunday so that we can compose and rehearse new Sambalpuri songs. Nature lover I am fond of gardening and needless to say that my garden is my paradise. Since I don’t get much time With husband on other days of the week, I take Folk singer care of my paradise on Sundays. Padmini Dora is a household Teamwork I team up with my name in Western husband Mohit Kumar Swain, an Odisha for her acclaimed artiste, to discuss Sambalpuri strategies for the revival of songs like Sambalpuri music. ‘Kanhu dakidesi nisha rati, ‘Chutkuchuta, Home Mayura chulia’ de-cluttering and ‘E murali’. A tidy and organised home always radiates Dora, often positive energy. Being a homemaker, referred to as I ensure to keep my house clean all the “Teejan Bai the time. of Odisha”, loves to cook Padmini being felicitated traditional mutton curry for Expert cook Sunday sounds boring if I don’t cook traditional her family. mutton curry. Everyone in my family loves the dish. The only exception is my son who loves paneer Do Pyaza. RASHMI REKHA DAS, OP WhatsApp VISUAL DELIGHT LETTERS Dear Sir, 'The Monsoon Chasers'(July 5) was a This Week sheer delight.The collage of monsoon photo- graphs capturing the myriad hues of the rainy season provided the much-needed soothing Only on Sunday POST! touch amidst the prevailing heatwave in the national capital. -

Dated : 23/4/2016
Dated : 23/4/2016 Signatory ID Name CIN Company Name Defaulting Year 01750017 DUA INDRAPAL MEHERDEEP U72200MH2008PTC184785 ALFA-I BPO SERVICES 2009-10 PRIVATE LIMITED 01750020 ARAVIND MYLSWAMY U01120TZ2008PTC014531 M J A AGRO FARMS PRIVATE 2008-09, 2009-10 LIMITED 01750025 GOYAL HEMA U18263DL1989PLC037514 LEISURE WEAR EXPORTS 2007-08 LTD. 01750030 MYLSWAMY VIGNESH U01120TZ2008PTC014532 M J V AGRO FARM PRIVATE 2008-09, 2009-10 LIMITED 01750033 HARAGADDE KUMAR U74910KA2007PTC043849 HAVEY PLACEMENT AND IT 2008-09, 2009-10 SHARATH VENKATESH SOLUTIONS (INDIA) PRIVATE 01750063 BHUPINDER DUA KAUR U72200MH2008PTC184785 ALFA-I BPO SERVICES 2009-10 PRIVATE LIMITED 01750107 GOYAL VEENA U18263DL1989PLC037514 LEISURE WEAR EXPORTS 2007-08 LTD. 01750125 ANEES SAAD U55101KA2004PTC034189 RAHMANIA HOTELS 2009-10 PRIVATE LIMITED 01750125 ANEES SAAD U15400KA2007PTC044380 FRESCO FOODS PRIVATE 2008-09, 2009-10 LIMITED 01750188 DUA INDRAPAL SINGH U72200MH2008PTC184785 ALFA-I BPO SERVICES 2009-10 PRIVATE LIMITED 01750202 KUMAR SHILENDRA U45400UP2007PTC034093 ASHOK THEKEDAR PRIVATE 2008-09, 2009-10 LIMITED 01750208 BANKTESHWAR SINGH U14101MP2004PTC016348 PASHUPATI MARBLES 2009-10 PRIVATE LIMITED 01750212 BIAPPU MADHU SREEVANI U74900TG2008PTC060703 SCALAR ENTERPRISES 2009-10 PRIVATE LIMITED 01750259 GANGAVARAM REDDY U45209TG2007PTC055883 S.K.R. INFRASTRUCTURE 2008-09, 2009-10 SUNEETHA AND PROJECTS PRIVATE 01750272 MUTHYALA RAMANA U51900TG2007PTC055758 NAGRAMAK IMPORTS AND 2008-09, 2009-10 EXPORTS PRIVATE LIMITED 01750286 DUA GAGAN NARAYAN U74120DL2007PTC169008 -

Tamil Nadu Government Gazette
© GOVERNMENT OF TAMIL NADU [Regd. No. TN/CCN/467/2009-11. 2009 [Price: Rs. 15.20 Paise. TAMIL NADU GOVERNMENT GAZETTE PUBLISHED BY AUTHORITY No. 43] CHENNAI, WEDNESDAY, NOVEMBER 4, 2009 Aippasi 18, Thiruvalluvar Aandu–2040 Part VI—Section 4 Advertisements by private individuals and private institutions CONTENTS PRIVATE ADVERTISEMENTS Pages Change of Names .. .. 1661-1697 Notices .. .. 1697 NoticeNOTICE .. .... .. 1446 NO LEGAL RESPONSIBILITY IS ACCEPTED FOR THE PUBLICATION OF ADVERTISEMENTS REGARDING CHANGE OF NAME IN THE TAMIL NADU GOVERNMENT GAZETTE. PERSONS NOTIFYING THE CHANGES WILL REMAIN SOLELY RESPONSIBLE FOR THE LEGAL CONSEQUENCES AND ALSO FOR ANY OTHER MISREPRESENTATION, ETC. (By Order) Director of Stationery and Printing. CHANGE OF NAMES My son, Aditya Krishnan, born on 20th July 1994 My daughter, Josephin Amalda Rebecca Miranda, (native district: Coimbatore), residing at Old No. 69, born on 12th January 1993 (native district: Thoothukkudi), New No. 27, 2nd Layout School Road, Krishnaswamy Nagar, residing at No. 2/185, Peter Street, Virapandianpatnam, Coimbatore-641 045, shall henceforth be known Tiruchendur Taluk, Thoothukkudi-628 216, shall henceforth as ADITHYA KRISHNAN. be known as REBECCA MIRANDA. RAGUNATH KRISHNAN. JULIAN MIRANDA. Coimbatore, 26th October 2009. (Father.) Virapandianpatnam, 26th October 2009. (Father.) My daughter, Sudhandiradevi, B., born on 18th February I, K. Parthasarathi, son of Thiru S. Kanakasabapathy, 2000 (native district: Nagapattinam), residing at born on 25th February 1984 (native district: Tiruppur), residing Old No. 5/5.492, New No. 4/112A, Matha Kovil Street, at No. 85, Ram Nagar 3rd Street, Tiruppur-641 602, Melaiyur Post, Sirkali Taluk, Nagapattinam-609 107, shall henceforth be known as K.K. -

AHMEDABAD | DELHI Page 1 of 33
MRP: ₹ 30 Weekly Current Affairs Compilations A holistic magazine for UPSC Prelims, Mains and Interview Preparation Volume 25 Special Edition - DIARY OF EVENTS 2019 (The Hindu) AHMEDABAD 204, Ratna Business Square, Opp HK College, Ashram Road, Ahmedabad - 380009 Landline: 079-484 33599 Mobile:73037 33599 Mail: [email protected] NEW DELHI 9/13, Near Bikaner Sweets, Bada Bazar Road, Old Rajinder Nagar, New Delhi - 110060 Landline: 011-405 33599 Mobile: 93197 33599 Mail: [email protected] www.civilsias.com AHMEDABAD | DELHI Page 1 of 33 COURSES conducted by CIVIL’S IAS 1. GS FOUNDATION [PRELIMS cum MAINS] a. LECTURE - 15 hours / week: 10 hours (Static Subjects) + 5 hours (Current Affairs) b. All NCERTs / Reference Books / Materials will be provided from academy free of cost. c. Weekly MCQs and ANSWER WRITING Tests d. 24 x 7 AC Library facilities e. Weekly Performance Report of students. f. Revision Lecture before Prelims and Mains exam g. Personal mentorship to students 2. CURRENT AFFAIRS Module [PRELIMS cum MAINS] a. Current Affairs lecture - 5 hours / week b. Weekly Current Affairs compilations and Monthly Yojana Magazine will be provided from academy free of cost. c. MCQs and ANSWER WRITING Tests based on Current Affairs d. 24 x 7 AC Library facilities e. Revision Lecture before Prelims and Mains exam 3. DAILY MAINS ANSWER WRITING (Online / Offline) a. Total 16 Questions and 1 Essay per Week b. Model Answers / Essay will be provided to students c. Evaluation by Faculty only d. One to one interaction with students 4. NCERT based TEST SERIES (Online / Offline) a. MCQs and Answer Writing tests based on NCERT 6 - 12th Standards 5. -

Madam's Profile
LATHA RAJINIKANTH P R O F I L E PERSONAL Smt.Latha is the daughter of Shri. Doraiswamy Rangachari and Smt. Alamelu Rangachari who instilled a deep cultural heritage and a strong value structure in her. She is the wife of Superstar Rajinikanth the iconic star known worldwide, who enjoys the love and following of millions of people all over the world. She is the proud mother of Aishwarya Rajinikanth Dhanush & Soundarya Rajinikanth, who have made a mark for themselves in their chosen careers. LATHA RAJINIKANTH – THE EDUCATIONIST Latha Rajinikanth is an Educationist and founder of the The Ashram Group of Institutions that was started in 1991. At The Ashram, education is imparted with a difference and a rich learning atmosphere is evolved in order to facilitate sharing of knowledge. OUR FOUNDER’S PHILOSOPHY AT THE ASHRAM FOR EDUCATION UNDERSTANDING what a student is, what he would like to be and what he is naturally capable of being . BELIEVES that the choice of subjects and curriculum should compliment students abilities towards the choice of Profession and Career. EMPHASIZES that by forcing students into a rigid /fixed pattern we fail to identify what is best in each individual. “Working towards meaningful, purposeful and wholesome education” Right Education…. For Right Living….. - Latha Rajinikanth THE ASHRAM GROUP OF INSTITUTIONS ENTERS ITS SILVER JUBILEE IN 2016 We move forward in the 25 th year of the The Ashram Group of Institutions with more goals to achieve …… …… Open our own campus…… …… Open more Academies for the betterment of children like The Ashram’s Aptitude & Skill Academy and many more…. -
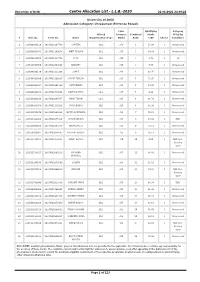
Centre Allocation List - L.L.B.-2020 22-01-2021 14:46:22
University of Delhi Centre Allocation List - L.L.B.-2020 22-01-2021 14:46:22 University of Delhi Admission Category: Unreserved (Entrance Based) Final Qualifying Category Alloted Entrance Combined Marks Filled by # Roll. No. Form No. Name Department/College Marks Rank %/GP Choice Candidate 1 210506030110 20LAWC1167749 PARTEEK CLC 356 1 58.00 1 Unreserved 2 210506010041 20LAWC1162678 KIRTI TEHLAN CLC 355 2 69.09 1 Unreserved 3 210506030001 20LAWC1147776 KAPIL CLC 350 3 3.72 1 SC 4 210528010050 20LAWC1063666 MANJEET CLC 350 3 0.00 1 Unreserved 5 210506030130 20LAWC1131206 SUMIT CLC 346 4 63.75 1 Unreserved 6 210506010060 20LAWC1162635 SAVITA TEHLAN CLC 335 5 72.25 1 Unreserved 7 210502010044 20LAWC1095390 VIJIT POONIA CLC 335 5 59.85 1 Unreserved 8 210506030158 20LAWC1139901 ROHIT DAHIYA LC-1 335 5 0.00 1 Unreserved 9 210511060146 20LAWC1067457 AMAR TIWARI LC-1 325 6 66.70 1 Unreserved 10 210506030058 20LAWC1130131 VIKAS DABAS CLC 325 6 62.90 1 Unreserved 11 210511550070 20LAWC1008034 ADITYA BARTHWAL CLC 321 7 70.51 1 Unreserved 12 210511320004 20LAWC1075234 SHASHANK RAI CLC 317 8 93.00 1 EWS 13 210511060166 20LAWC1067378 NIKHIL MALIK CLC 315 9 74.54 1 Unreserved 14 210524010067 20LAWC1034597 HARSHIT DAGAR CLC 315 9 56.13 1 Unreserved 15 210511720075 20LAWC1151683 MOHIT BAISLA CLC 310 10 0.00 1 OBC Non- Creamy layer 16 210511530017 20LAWC1001013 SAURABH CLC 307 11 68.80 1 Unreserved KHARWAL 17 210511390149 20LAWC1073590 SACHIN CLC 306 12 56.10 1 Unreserved 18 210511540106 20LAWC1004010 OM RAM CLC 305 13 79.02 1 OBC Non- Creamy layer 19 210511760049 -

Top Current Affairs of the Week (3 – 7 November 2019)
www.gradeup.co Top Current Affairs of the Week (3 – 7 November 2019) 1. Rajinikanth to be honoured with first “Icon of Golden Jubilee Award” at IFFI • The International Film Festival of India (IFFI) 2019 that is to be held in Goa from 20th November to 28th November, 2019, will honour Indian Film star S Rajnikant with a special Icon of Golden Jubilee Award. • The IFFI will also confer with the Lifetime Achievement Award for a Foreign Artiste to French Actress Isabelle Huppert. • The Icon of Golden Jubilee Award is a special award constituted by the Government of India in the year 2019. • Rajinikanth made his acting debut with director K Balachandar's Apoorva Ragangal in 1975. Note: • This year would commemorate the 50th edition of the International Film Festival. • To celebrate the same, 50 films by women directors will be showcased at the event. • Russia will be the partner country of the IFFI 2019. • The first-ever IFFI was organized by the Films Division, Government of India, with the patronage of the first Prime Minister of India – Pt. Jawaharlal Nehru. • The International Film Festival of India (IFFI) aims at providing a common platform to the cinemas across the world to project the excellence of the art of film making. 2. Writer Anand selected for Ezhuthachan Puraskaram • Noted writer Anand has been selected for the 27th Ezhuthachan Puraskaram, the highest literary honour of the Kerala state government. • This award is given by the Kerala Sahitya Akademi Award and the Government of Kerala. • His one of the famous novel is Aalkoottam which portrays the unique crises that the nation had witnessed with a rare finesse. -

Ati Utkrisht Seva Padak
अवर्गीकृत (.) केन्द रीय ्र वल स बल ील की ‘’83वीĂ थासना बदव ’’ (Raising Day) बदनाĂक 27, लाई, 2021 के अव र सर महाबनदेशक के्रस ील ने माननीय र्गृहमĂत्री द्वारा Ă थाबसत ंवĂ र्गृह मĂत्रालय, भारत रकार के बदनाĂक 23/07/2018 की अबध ूचना Ă奍 या 11024/02/2018-PMA तथा बदनाĂक 26/07/2021 के आई०डी० नोट Ă奍 या 11024/31/2020-PMA के अन रण मᴂ ील के अधोबलखित अबधका्रयोĂ ंवĂ काबमलकोĂ को उनकी अन करणीय ेवाओĂ, कतल핍 यसरायणता, कायलदक्षता तथा ाह के बलं ‘’अबत उत्कृष्ट ेवा सदक’’ तथा ‘’उ配 कृ ष्ट ेवा सदक’’ े हर्ल म्माबनत बकया है, ब का बववरण बन륍 नान ार है - ATI UTKRISHT SEVA PADAK Sl. IRLA/ Rank Name/Shri Zone Unit/Office No. Force No. 1. 11897 SDG SANJAY CHANDER, IPS ADG-WORKS DTE-GEN 2. ADG (NOW DTE-GEN DTE-GEN 9113 ZULFIQUAR HASAN, IPS SDG) 3. 25585 IG SATPAL RAWAT NEZ IG-TPA 4. 28086 DIG NARENDRA KUMAR SINGH NEZ IG-TPA (Now Rectt Dte) 5. 41999 COMDT AMIT KUMAR SINGH SZ SZ (u/o tfr to 45 Bn) 6. 47704 COMDT KALYAN SINGHA NEZ 086-BN (u/o tfr to GC SLR) 7. 56106 2-I/C DHARAM SINGH JKZ 152-BN 8. 60281 2-I/C VINOD KUMAR RAWAT CZ 197-BN 9. 64073 DC ARVIND KUMAR SINGH DTE-GEN DTE-GEN 10. 87341 DC MIN MANOJ KUMAR JKZ JKZ 11. -

Padma Vibhushan * * the Padma Vibhushan Is the Second-Highest Civilian Award of the Republic of India , Proceeded by Bharat Ratna and Followed by Padma Bhushan
TRY -- TRUE -- TRUST NUMBER ONE SITE FOR COMPETITIVE EXAM SELF LEARNING AT ANY TIME ANY WHERE * * Padma Vibhushan * * The Padma Vibhushan is the second-highest civilian award of the Republic of India , proceeded by Bharat Ratna and followed by Padma Bhushan . Instituted on 2 January 1954, the award is given for "exceptional and distinguished service", without distinction of race, occupation & position. Year Recipient Field State / Country Satyendra Nath Bose Literature & Education West Bengal Nandalal Bose Arts West Bengal Zakir Husain Public Affairs Andhra Pradesh 1954 Balasaheb Gangadhar Kher Public Affairs Maharashtra V. K. Krishna Menon Public Affairs Kerala Jigme Dorji Wangchuck Public Affairs Bhutan Dhondo Keshav Karve Literature & Education Maharashtra 1955 J. R. D. Tata Trade & Industry Maharashtra Fazal Ali Public Affairs Bihar 1956 Jankibai Bajaj Social Work Madhya Pradesh Chandulal Madhavlal Trivedi Public Affairs Madhya Pradesh Ghanshyam Das Birla Trade & Industry Rajashtan 1957 Sri Prakasa Public Affairs Andhra Pradesh M. C. Setalvad Public Affairs Maharashtra John Mathai Literature & Education Kerala 1959 Gaganvihari Lallubhai Mehta Social Work Maharashtra Radhabinod Pal Public Affairs West Bengal 1960 Naryana Raghvan Pillai Public Affairs Tamil Nadu H. V. R. Iyengar Civil Service Tamil Nadu 1962 Padmaja Naidu Public Affairs Andhra Pradesh Vijaya Lakshmi Pandit Civil Service Uttar Pradesh A. Lakshmanaswami Mudaliar Medicine Tamil Nadu 1963 Hari Vinayak Pataskar Public Affairs Maharashtra Suniti Kumar Chatterji Literature -

Deepika Com Tamilcinema Com Maayboli
LOUNGE WEB L7 TECH 2010 SATURDAY, MAY 29, 2010 ° WWW.LIVEMINT.COM The creators of the first Indian language websites braved rudimentary technology and digital nation limited reach to become dot-com pioneers. We trace the stories of four of them SHARP IMAGE kuvempu com or 37-year-old Gyanesh M. Khanolkar, Fbeing the creator of the world’s first Kannada .com was only partly sparked by the thrill of the new. In 1997, the Bangalore- based software engineer registered Kuvempu.com, an online resource for the work of the celebrated Kannada writer and Part of history: Kerala's 110-year-old news- poet, Kuppali Venkataiah Gowda Puttappa. paper was the first to go online. “The Internet was coming up then, so I started collecting information, and talking to people who could contribute,” he says. But driving Khanolkar’s exploratory spirit deepika com was another, equally central concern: “He’s also my wife’s grandfather.” Khanolkar and his wife, Eshanye Kup- emember the joke about Neil Arm- palli Poornachandra Tejaswi, had access Rstrong finding a Malayali tea vendor to a vast number of rare documents from when he landed on the moon? It was with the poet’s life. Nearly a year’s worth of this peripatetic Keralite in mind that in research went into the first iteration of 1997, in the early days of the dot-com in the site, which had content in both India, a 110-year-old newspaper decided Early bird: M. Anto Peter's Tamilcinema.com was once mistaken for a film project. English and Kannada. -

Chengalpattu
CHENGALPATTU S. NO ROLL.NO NAME OF ADVOCATE ADDRESS NO.32, CHINNA MANIYAKARA STREET, CHENGALPATTU, KANCHIPURAM DIST - 603, 001 1 311/2012 ABIRAMI A. NO.28, STATION MAIN ST. KATTANKOLTHUR, CHENGALPATTU 603203 2 2089/2010 ABITH HUSSAIN K. NO 116, KILAKKADI VILLAGE, THULUKKANATHAMMAN KOIL STREET, UTHIRAMERUR TALUK, KANCHEPURAM DIST. 3 729/2007 ADIKESAVAN P. 3-C, CHUNNAMPUKARA ST.CHENGALPATTU KANCHEEPURAM -603002 4 1630/2008 AKBAR BASHA N.T. NO.10, CHINNA AMMAN KOILST. CHENGALPATTU 603001 5 1328/2006 ALAMELU R. NO.3, MAHATHMAGANDHI STREET, ATHIYUR VILLAGE, MAIYUR POST, MADHURANTAKAM TALIUK - 603 111,KANCHIPURAM 6 3234/2012 AMBETHKAR K. NO.88, ROJA STREET, J.C.K. NAGAR, CHENGALPATTU TOWN & TALUK, KANCHEEPURAM DIST 7 723/1980 AMBROSE P.A. 8/W2, MALAIINATHAM, MELARIPAKKAM POST, T.K.M. ROAD, OPP TO IYAPPAN KOVIL CHENGALPATTU. 8 2798/2008 AMEETHA BANU A.R. NO.15/9, N.H.2, MARAI MALAI NAGAR, CHENGLEPUT TK, KANCHIPIRAM-603209. 9 1059/2000 ANANDEESWARAN M. 4/30, NEW STREET, G.M.NAGAR, PUDUPADI POST, ARCOT TK. VELLORE DIST. 632503 10 3156/2013 ANANDHARAJ S. NO.6, DOOR NO.F-2, BALAJI NAGAR, VEDHA NARAYANAPURAM, VENBAKKAM POST, CHENGALPATT, KANCHEEPURAM, DISTRICT 11 637/2009 ANANTH T. NO.10/A, TIRUMALAIYAPILLAI SANDU, UTHIRAMERUR, KANCHIPURAM DIST - 603 406 12 3977/2012 ANANTHAJOTHI A. S. NO ROLL.NO NAME OF ADVOCATE ADDRESS B.47, ALAGESAN NAGAR, CHENGALPATTU, KACHEPURAM - 603001. 13 213/1975 ANBAN R. NO:1076, BHARATHIYAR STREET, SANTHINAMPATTU VILLAGE, MANAMPATTY POST, CHENGALPATTU TALUK, KANCHIPURAM 14 2357/2012 ANBARASU K. DIST - 603 105 NO.1/C 32, III CROSS ST, ANNA NAGAR, CHENGALPATTU-603001, KANCHIPURAM-DT. -

Film Preservation & Restoration Workshop
FILM PRESERVATION & RESTORATION WORKSHOP, INDIA 2016 1 2 FILM PRESERVATION & RESTORATION WORKSHOP, INDIA 2016 1 Cover Image: Ulagam Sutrum Valiban, 1973 Tamil (M. G. Ramachandran) Courtesy: Gnanam FILM PRESERVATION OCT 7TH - 14TH & RESTORATION Prasad Film Laboratories WORKSHOP 58, Arunachalam Road Saligramam INDIA 2017 Chennai 600 093 Vedhala Ulagam, 1948, Tamil The Film Preservation & Restoration Workshop India 2017 (FPRWI 2017) is an initiative of Film Heritage Foundation (FHF) and The International Federation of Film Archives (FIAF) in association with The Film Foundation’s World Cinema Project, L’Immagine Ritrovata, The Academy of Motion Picture Arts & Sciences, Prasad Corp., La Cinémathèque française, Imperial War Museums, Fondazione Cineteca di Bologna, The National Audivisual Institute of Finland (KAVI), Národní Filmový Archiv (NFA), Czech Republic and The Criterion Collection to provide training in the specialized skills required to safe- guard India’s cinematic heritage. The seven-day course designed by David Walsh, Head of the FIAF Training and Outreach Program will cover both theory and practical classes in the best practices of the preservation and restoration of both filmic and non-filmic material and daily screenings of restored classics from around the world. Lectures and practical sessions will be conducted by leading archivists and restorers from preeminent institutions from around the world. Preparatory reading material will be shared with selected candidates in seven modules beginning two weeks prior to the commencement of the workshop. The goal of the programme is to continue our commitment for the third successive year to train an indigenous pool of film archivists and restorers as well as to build on the movement we have created all over India and in our neighbouring countries to preserve the moving image legacy.