Forecasting Stock Market Index Daily Direction: a Bayesian Network Approach
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
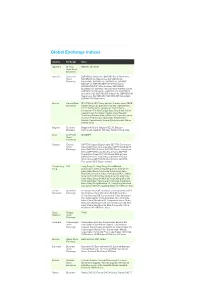
Global Exchange Indices
Global Exchange Indices Country Exchange Index Argentina Buenos MERVAL, BURCAP Aires Stock Exchange Australia Australian S&P/ASX All Ordinaries, S&P/ASX Small Ordinaries, Stock S&P/ASX Small Resources, S&P/ASX Small Exchange Industriials, S&P/ASX 20, S&P/ASX 50, S&P/ASX MIDCAP 50, S&P/ASX MIDCAP 50 Resources, S&P/ASX MIDCAP 50 Industrials, S&P/ASX All Australian 50, S&P/ASX 100, S&P/ASX 100 Resources, S&P/ASX 100 Industrials, S&P/ASX 200, S&P/ASX All Australian 200, S&P/ASX 200 Industrials, S&P/ASX 200 Resources, S&P/ASX 300, S&P/ASX 300 Industrials, S&P/ASX 300 Resources Austria Vienna Stock ATX, ATX Five, ATX Prime, Austrian Traded Index, CECE Exchange Overall Index, CECExt Index, Chinese Traded Index, Czech Traded Index, Hungarian Traded Index, Immobilien ATX, New Europe Blue Chip Index, Polish Traded Index, Romanian Traded Index, Russian Depository Extended Index, Russian Depository Index, Russian Traded Index, SE Europe Traded Index, Serbian Traded Index, Vienna Dynamic Index, Weiner Boerse Index Belgium Euronext Belgium All Share, Belgium BEL20, Belgium Brussels Continuous, Belgium Mid Cap, Belgium Small Cap Brazil Sao Paulo IBOVESPA Stock Exchange Canada Toronto S&P/TSX Capped Equity Index, S&P/TSX Completion Stock Index, S&P/TSX Composite Index, S&P/TSX Equity 60 Exchange Index S&P/TSX 60 Index, S&P/TSX Equity Completion Index, S&P/TSX Equity SmallCap Index, S&P/TSX Global Gold Index, S&P/TSX Global Mining Index, S&P/TSX Income Trust Index, S&P/TSX Preferred Share Index, S&P/TSX SmallCap Index, S&P/TSX Composite GICS Sector Indexes -

Weekly Economic Update
Electronic News That You Can Use! ONTHLY CONOMIC PDATE M E U October 2018 THIS MONTH’S THE MONTH IN BRIEF Wall Street maintained its optimism in September. While trade worries were top of HIGHLIGHT IS mind for economists and investors overseas, bulls largely shrugged at the prospect of tariffs and the probability of another interest rate hike. The S&P 500 rose 0.43% SOCIAL SECURITY for the month. On the whole, U.S. economic indicators were quite good, and some offered pleasant surprises. Social Security benefits can be a DOMESTIC ECONOMIC HEALTH As many analysts expected, the Federal Reserve raised the main interest rate by critical part of your 0.25% on September 26 to a target range of 2.00-2.25%. The word “accommodative” retirement was absent from its latest policy statement, distinctly hinting at a shift in U.S. income. It’s monetary policy. As September ended, the CME Group’s FedWatch Tool had the odds of a quarter-point December rate hike at 76.5%. important to understand how it On the last day of September, Canada joined the U.S. and Mexico in a new proposed works and trade pact representing an evolution of the existing North American Free Trade Agreement (NAFTA). The new accord, if approved by the governments of Canada, consider carefully Mexico, and the U.S., would toughen intellectual property and trade secret when to claim regulations, require 75% of autos made in North America to use parts from North American manufacturers, stipulate new labor requirements for Mexican industry, your benefits. -

Bolsas Y Mercados Argentinos Indices Methodology Consultation
Bolsas y Mercados Argentinos Indices Methodology Consultation BUENOS AIRES, NOVEMBER 5, 2018: In March 2018, Bolsas y Mercados Argentinos (“BYMA”) and S&P Dow Jones Indices (“S&P DJI”) signed an Index Operation and License Agreement. The partnership between BYMA and S&P DJI, the world’s leading provider of index-based concepts, data and research, includes the adoption of international index methodology standards and the integration of operational processes and business strategies and enhances the visibility, governance, and transparency of the existing indices. The agreement also enables the development, licensing, distribution and management of current and future indices which will be designed to serve as innovative and practical tools for local and global investors. The new and existing BYMA indices will be co- branded under the “S&P/MERVAL” and “S&P/BYMA” names (the “Indices”) that can be used to underlie liquid financial products, expanding the breadth and depth of the Argentine capital market. As part of this transition, S&P DJI and BYMA are conducting a consultation with members of the investment community on potential changes to the following BYMA indices to ensure that they continue to meet their objectives and are aligned with the needs of local and international market participants. BYMA Argentina General Index (Also known as Índice General de la Bolsa de Comercio de Buenos Aires) MERVAL Index MERVAL Argentina Index S&P DJI SUPPORTING DOCUMENTS This consultation is meant to be read in conjunction with supporting documents providing greater detail with respect to the S&P DJI policies, procedures and calculations described herein. -

Execution Version
Execution Version GUARANTEED SENIOR SECURED NOTES PROGRAMME issued by GOLDMAN SACHS INTERNATIONAL in respect of which the payment and delivery obligations are guaranteed by THE GOLDMAN SACHS GROUP, INC. (the “PROGRAMME”) PRICING SUPPLEMENT DATED 23rd SEPTEMBER 2020 SERIES 2020-12 SENIOR SECURED EXTENDIBLE FIXED RATE NOTES (the “SERIES”) ISIN: XS2233188510 Common Code: 223318851 This document constitutes the Pricing Supplement of the above Series of Secured Notes (the “Secured Notes”) and must be read in conjunction with the Base Listing Particulars dated 25 September 2019, as supplemented from time to time (the “Base Prospectus”), and in particular, the Base Terms and Conditions of the Secured Notes, as set out therein. Full information on the Issuer, The Goldman Sachs Group. Inc. (the “Guarantor”), and the terms and conditions of the Secured Notes, is only available on the basis of the combination of this Pricing Supplement and the Base Listing Particulars as so supplemented. The Base Listing Particulars has been published at www.ise.ie and is available for viewing during normal business hours at the registered office of the Issuer, and copies may be obtained from the specified office of the listing agent in Ireland. The Issuer accepts responsibility for the information contained in this Pricing Supplement. To the best of the knowledge and belief of the Issuer and the Guarantor the information contained in the Base Listing Particulars, as completed by this Pricing Supplement in relation to the Series of Secured Notes referred to above, is true and accurate in all material respects and, in the context of the issue of this Series, there are no other material facts the omission of which would make any statement in such information misleading. -

Quarterly Economic Update
DSI Wealth Management Group Presents: QUARTERLY ECONOMIC UPDATE A review of 1Q 2014 QUOTE OF THE THE QUARTER IN BRIEF QUARTER Bulls didn’t quite trample bears in the opening quarter of 2014. The S&P 500 slid “If there is no 3.56% in January, advanced 4.31% in February and gained another 0.69% in March. struggle, there is no Still, Q1 ended with the Dow in the red YTD and only minor YTD gains for the progress.” Nasdaq, S&P and Russell 2000; the broad commodities market outperformed the stock market. Some fundamental economic indicators were unimpressive during the – Frederick Douglass quarter, and analysts wondered if a ferocious winter was partly to blame. The Federal Reserve kept tapering QE3 as Ben Bernanke handed the reins to Janet QUARTERLY TIP Yellen. Unrest and currency problems hit some key emerging-market economies. Given the choice Home prices kept rising as home sales leveled off. Wall Street hoped the year 1 between a great wouldn’t mimic the quarter. lifestyle today and financial freedom DOMESTIC ECONOMIC HEALTH tomorrow, many The quarter ended with a major jump in consumer confidence. The Conference people opt to live for Board’s index reached 82.3 in March, up 4.0 points in a month. Consumer spending today – but no one improved too, rising 0.2% in January and 0.3% in February. (In a contrasting note, becomes wealthy by the University of Michigan’s consumer sentiment index slipped 2.5 points across the spending or living on quarter to a final March mark of 80.0.)2,3 margin. -

INVESTMENT STRATEGY: Monthly Index Dashboard Sign up Here to Receive Daily Commentary; Sign up Here to Join Our Weekly Live Calls August 31, 2021
INDEX INVESTMENT STRATEGY: Monthly Index Dashboard Sign up here to receive daily commentary; sign up here to join our weekly live calls August 31, 2021 HEADLINE INDICES [P2] Movers & Shakers [P3] Equity Sectors [P4] Equity Factors [P5] S&P Global BMI [P6] U.S. Industries [P7] Fixed Income [P8] Commodities & Real Assets INDEX Aug QTD YTD 12M INDEX Yield Aug QTD YTD 12M U.S. Equity U.S. Fixed Income S&P 500® 3.04% 5.49% 21.58% 31.17% S&P U.S. Aggregate Bond 1.28% -0.12% 0.91% -0.50% 0.28% S&P MidCap 400® 1.95% 2.30% 20.30% 44.77% S&P U.S. Treasury Current 2-Year 0.19% 0.03% 0.21% 0.08% 0.14% S&P SmallCap 600® 2.02% -0.42% 23.04% 53.97% S&P U.S. Treasury Current 10-Year 1.28% -0.42% 1.79% -2.42% -3.95% S&P Composite 1500® 2.95% 5.14% 21.56% 32.43% S&P 500/MarketAxess IG Corp Bond 2.05% -0.32% 1.15% -0.58% 2.40% S&P Total Market Index (TMI) 2.86% 4.63% 20.61% 33.32% S&P 500 High Yield Corporate Bond 2.93% 0.49% 1.31% 3.97% 8.43% Dow Jones Industrial Average® 1.50% 2.86% 17.04% 26.77% S&P/LSTA U.S. Leveraged Loan 100 3.82% 0.59% 0.34% 2.52% 6.00% Aug Leaders & Laggards: S&P 500 Sectors & Factors Global Fixed Income S&P/ASX Australian Gov. -

Monthly Economic Update
In this month’s recap: Stocks, gold, and oil all surge, a door opens for U.S.-China trade talks to resume, and the Federal Reserve suddenly sounds dovish. Monthly Economic Update Presented by Core Wealth Management, July 2019 THE MONTH IN BRIEF You could say June was a month of highs. The S&P 500 hit another record peak, oil prices reached year-to-date highs, and gold became more valuable than it had been in six years. (There was also a notable low during the month: the yield of the 10-year Treasury fell below 2%.) Also, a door opened to further trade talks with China, and the latest monetary policy statement from the Federal Reserve hinted at the possibility of easing. For most investors, there was much to appreciate.1 DOMESTIC ECONOMIC HEALTH On June 29, President Trump told reporters, gathered at the latest Group of 20 summit, that he and Chinese President Xi Jinping were planning a resumption of formal trade negotiations between their respective nations. Additionally, President Trump said that the U.S. would refrain from imposing tariffs on an additional $300 billion of Chinese goods for the “time being.” A six- week stalemate in trade talks had weighed on U.S. and foreign stock, bond, and commodities markets in May and June.2 The Federal Reserve left the benchmark interest rate alone at its June meeting, but its newest policy statement and dot-plot forecast drew considerable attention. Among seventeen Fed officials, eight felt rate cuts would occur by the end of the year, eight saw no rate moves for the rest of the year, and just one saw a 2019 hike. -

Thomson One Quick Reference Guide
THOMSON ONE QUICK REFERENCE GUIDE Thomson ONE (www.thomsonone.com) provides integrated access to comprehensive market and company information. All of the intelligence you need to power your knowledge gathering and drive smarter decision-making. This Quick Reference Card offers some quick tips on customizing your workspace, setting up alerts, searching and more. LOOKING UP A COMPANY To add a service to your Favorites, open the page, click , and then select Add to Favorites. PUBLIC COMPANIES: To organize your favorites 1. If the company symbol is not known, click the 1. Click , and select Organize Favorites. Search icon. 2. If you want to create and name folders, click 2. Select either Contains or Begins With, then type all or Create Folder, and type in a name. part of the company name. 3. Drag a favorite into any folder, or click up or down 3. (Optional) Click the Home Listing Only check box to arrows to move it to a different place in the list. limit results to a company’s primary (Home) exchange. 4. Click OK. 4. Click Search. 5. Select the company symbol to display content related To set any page as your Home Page to that company. Click , and select Set as Home. PRIVATE COMPANIES: To return to your home page at any time, click . 1. Click the Symbol drop-down, and select Private Co. FLEX MONITOR: MONITORING A 2. Type the private company name (use , if needed), and click Go. COVERAGE LIST 3. Select the private company name to display content Flex Monitor allows you to create and save an unlimited related to that company. -

This Material Was Prepared by Marketingpro, Inc., and Does Not Necessarily Represent the Views of the Presenting Party, Nor Their Affiliates
This material was prepared by MarketingPro, Inc., and does not necessarily represent the views of the presenting party, nor their affiliates. The information herein has been derived from sources believed to be accurate. Please note - investing involves risk, and past performance is no guarantee of future results. Investments will fluctuate and when redeemed may be worth more or less than when originally invested. This information should not be construed as investment, tax or legal advice and may not be relied on for the purpose of avoiding any Federal tax penalty. This is neither a solicitation nor recommendation to purchase or sell any investment or insurance product or service, and should not be relied upon as such. Indices do not incur management fees, costs and expenses, and cannot be invested into directly. All economic and performance data is historical and not indicative of future results. The Dow Jones Industrial Average is a price-weighted index of 30 actively traded blue-chip stocks. The NASDAQ Composite Index is a market-weighted index of all over-the-counter common stocks traded on the National Association of Securities Dealers Automated Quotation System. The Standard & Poor's 500 (S&P 500) is a market-cap weighted index composed of the common stocks of 500 leading companies in leading industries of the U.S. economy. NYSE Group, Inc. (NYSE:NYX) operates two securities exchanges: the New York Stock Exchange (the “NYSE”) and NYSE Arca (formerly known as the Archipelago Exchange, or ArcaEx®, and the Pacific Exchange). NYSE Group is a leading provider of securities listing, trading and market data products and services. -

Should Investors on Equity Markets Be Superstitious (On the Example of 52 World Stock Indices)?
Volume X Issue 29 (September 2017) JMFS pp. 73-98 Journal of Management Warsaw School of Economics and Financial Sciences Collegium of Management and Finance Krzysztof Borowski Collegium of Management and Finance Warsaw School of Economics Should Investors on Equity Markets Be Superstitious (on the Example of 52 World Stock Indices)? A b s t r a c t The problem of efficiency of financial markets, especially the weekend effect, has always fascinated scientists. The issue is significant from the point of view of assessing the portfolio management effectiveness and behavioral finance. This paper tests the hypothesis of the unfortunate dates effect upon52 equity indices in relation to the following four approaches: close - close, overnight, open-open, open-close calculated for the sessions falling on the 13th and 4th day of the month, Friday the 13th, Tuesday the 13th. In the following part of the paper, the statistical equality of one-session average rates of return (close-close) for sessions falling on Friday 13th and sessions falling on other Friday sessions will be compared, as well as for sessions falling on Tuesday the 13th and sessions falling on other Tuesdays. The last part of the paper consists of the analysis of the correlation coefficients of Friday the 13th (close-close) rates of return calculated for the analyzed equity indices’ pairs. Keywords: market efficiency, calendar anomalies, Friday the 13th, Tuesday the 13th, unfor tunate dates effect JEL Codes: G14, G15, C12 74 Krzysztof Borowski 1. Introduction The Efficient Market Hypothesis (EMH), introduced by Fama in 1970 belongs to the most important paradigms of the traditional financial theories1. -

Monthly Economic Update
MONTHLY ECONOMIC UPDATE February 2018 MONTHLY QUOTE THE MONTH IN BRIEF “Never apologize for Bulls took charge of Wall Street as 2018 began: the Dow Jones Industrial Average showing feeling. rose 5.79% in the first month of the year, even with a mild selloff on the verge of When you do so, you February. Foreign equity benchmarks largely advanced as well. Oil and gasoline apologize for truth.” futures surged, while bitcoin continued to rollercoaster. Personal spending, - Benjamin Disraeli manufacturing, and consumer confidence data encouraged investors. Home sales weakened as home prices surpassed a pre-recession peak and mortgage rates increased. Analysts kept warning that Wall Street was overdue for a pullback; while MONTHLY TIP indices did slip late in the month, optimism was little shaken.1 Personal finance apps have come a DOMESTIC ECONOMIC HEALTH long way. Besides bill America’s economy is largely driven by the consumer, and as the Bureau of paying, account Economic Analysis noted, consumers spent generously in December. There were overviews, and push 0.4% improvements in both personal income and personal spending. Retail sales notifications rose by 0.4% in the last month of 2017, even with vehicle and gasoline purchases regarding household factored out. The BEA released its first estimate of fourth-quarter GDP in late budget categories, January – a respectable 2.6%.2 some let you see all your credit and bank Consumer confidence index readings varied from extremely impressive to above transactions in one average. The Conference Board’s monthly index rose from 123.1 to 125.4 in January. -

Weekly Economic Update
Electronic News That You Can Use! ONTHLY CONOMIC PDATE M E U June 2019 THIS MONTH’S THE MONTH IN BRIEF Hopes for a quick resolution to the U.S. -China trade dispute faded in May as HIGHLIGHT IS discussions broke down and rhetoric from both sides turned tough again. The disappointment lingered on wall street: the month saw losses for stocks. On main SOCIAL SECURITY street, consumer confidence was strong and inflation tame. Mortgage rates reached year-to-date lows, but the latest data on home sales showed weak spring buying. Social Security The price of crude oil fell significantly, and so did the yield on the 10-year treasury. benefits can be a DOMESTIC ECONOMIC HEALTH critical part of your Last month, trade was the story, and tariffs were on the mind of market participants. On May 5, President Trump announced that U.S. import taxes levied on $200 billion retirement of Chinese products would soon rise from 10% to 25% and that virtually all other income. It’s goods arriving from China would “shortly” face a 25% tariff. China retaliated, important to declaring that it would hike tariffs already imposed on $60 billion worth of American products, effective June 1st. More tariff developments followed. On May17, understand how it President Trump opted to delay levies planned for imported autos until later in 2019, works and and he removed tariffs on metals arriving from Canada and Mexico. consider carefully Late May brought more attention-getting headlines. On May 29, China’s state media when to claim suggested that its government might consider banning rare-earth mineral exports in your benefits.