Administering the Recoverable File System on UNIX
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Administering Unidata on UNIX Platforms
C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\ADMINUNIX\ADMINUNIXTITLE.fm March 5, 2010 1:34 pm Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta UniData Administering UniData on UNIX Platforms UDT-720-ADMU-1 C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\ADMINUNIX\ADMINUNIXTITLE.fm March 5, 2010 1:34 pm Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Notices Edition Publication date: July, 2008 Book number: UDT-720-ADMU-1 Product version: UniData 7.2 Copyright © Rocket Software, Inc. 1988-2010. All Rights Reserved. Trademarks The following trademarks appear in this publication: Trademark Trademark Owner Rocket Software™ Rocket Software, Inc. Dynamic Connect® Rocket Software, Inc. RedBack® Rocket Software, Inc. SystemBuilder™ Rocket Software, Inc. UniData® Rocket Software, Inc. UniVerse™ Rocket Software, Inc. U2™ Rocket Software, Inc. U2.NET™ Rocket Software, Inc. U2 Web Development Environment™ Rocket Software, Inc. wIntegrate® Rocket Software, Inc. Microsoft® .NET Microsoft Corporation Microsoft® Office Excel®, Outlook®, Word Microsoft Corporation Windows® Microsoft Corporation Windows® 7 Microsoft Corporation Windows Vista® Microsoft Corporation Java™ and all Java-based trademarks and logos Sun Microsystems, Inc. UNIX® X/Open Company Limited ii SB/XA Getting Started The above trademarks are property of the specified companies in the United States, other countries, or both. All other products or services mentioned in this document may be covered by the trademarks, service marks, or product names as designated by the companies who own or market them. License agreement This software and the associated documentation are proprietary and confidential to Rocket Software, Inc., are furnished under license, and may be used and copied only in accordance with the terms of such license and with the inclusion of the copyright notice. -

DC Console Using DC Console Application Design Software
DC Console Using DC Console Application Design Software DC Console is easy-to-use, application design software developed specifically to work in conjunction with AML’s DC Suite. Create. Distribute. Collect. Every LDX10 handheld computer comes with DC Suite, which includes seven (7) pre-developed applications for common data collection tasks. Now LDX10 users can use DC Console to modify these applications, or create their own from scratch. AML 800.648.4452 Made in USA www.amltd.com Introduction This document briefly covers how to use DC Console and the features and settings. Be sure to read this document in its entirety before attempting to use AML’s DC Console with a DC Suite compatible device. What is the difference between an “App” and a “Suite”? “Apps” are single applications running on the device used to collect and store data. In most cases, multiple apps would be utilized to handle various operations. For example, the ‘Item_Quantity’ app is one of the most widely used apps and the most direct means to take a basic inventory count, it produces a data file showing what items are in stock, the relative quantities, and requires minimal input from the mobile worker(s). Other operations will require additional input, for example, if you also need to know the specific location for each item in inventory, the ‘Item_Lot_Quantity’ app would be a better fit. Apps can be used in a variety of ways and provide the LDX10 the flexibility to handle virtually any data collection operation. “Suite” files are simply collections of individual apps. Suite files allow you to easily manage and edit multiple apps from within a single ‘store-house’ file and provide an effortless means for device deployment. -

The Ifplatform Package
The ifplatform package Original code by Johannes Große Package by Will Robertson http://github.com/wspr/ifplatform v0.4a∗ 2017/10/13 1 Main features and usage This package provides the three following conditionals to test which operating system is being used to run TEX: \ifwindows \iflinux \ifmacosx \ifcygwin If you only wish to detect \ifwindows, then it does not matter how you load this package. Note then that use of (Linux or Mac OS X or Cygwin) can then be detected with \ifwindows\else. If you also wish to determine the difference between which Unix-variant you are using (i.e., also detect \iflinux, \ifmacosx, and \ifcygwin) then shell escape must be enabled. This is achieved by using the -shell-escape command line option when executing LATEX. If shell escape is not enabled, \iflinux, \ifmacosx, and \ifcygwin will all return false. A warning will be printed in the console output to remind you in this case. ∗Thanks to Ken Brown, Joseph Wright, Zebb Prime, and others for testing this package. 1 2 Auxiliary features \ifshellescape is provided as a conditional to test whether shell escape is active or not. (Note: new versions of pdfTEX allow you to query shell escape with \ifnum\pdfshellescape>0 , and the pdftexcmds package provides the wrapper \pdf@shellescape which works with X TE EX, pdfTEX, and LuaTEX.) Also, the \platformname command is defined to expand to a macro that represents the operating system. Default definitions are (respectively): \windowsname ! ‘Windows’ \notwindowsname ! ‘*NIX’ (when shell escape is disabled) \linuxname ! ‘Linux’ \macosxname ! ‘Mac OS X’ \cygwinname ! ‘Cygwin’ \unknownplatform ! whatever is returned by uname E.g., if \ifwindows is true then \platformname expands to \windowsname, which expands to ‘Windows’. -

A First Course to Openfoam
Basic Shell Scripting Slides from Wei Feinstein HPC User Services LSU HPC & LON [email protected] September 2018 Outline • Introduction to Linux Shell • Shell Scripting Basics • Variables/Special Characters • Arithmetic Operations • Arrays • Beyond Basic Shell Scripting – Flow Control – Functions • Advanced Text Processing Commands (grep, sed, awk) Basic Shell Scripting 2 Linux System Architecture Basic Shell Scripting 3 Linux Shell What is a Shell ▪ An application running on top of the kernel and provides a command line interface to the system ▪ Process user’s commands, gather input from user and execute programs ▪ Types of shell with varied features o sh o csh o ksh o bash o tcsh Basic Shell Scripting 4 Shell Comparison Software sh csh ksh bash tcsh Programming language y y y y y Shell variables y y y y y Command alias n y y y y Command history n y y y y Filename autocompletion n y* y* y y Command line editing n n y* y y Job control n y y y y *: not by default http://www.cis.rit.edu/class/simg211/unixintro/Shell.html Basic Shell Scripting 5 What can you do with a shell? ▪ Check the current shell ▪ echo $SHELL ▪ List available shells on the system ▪ cat /etc/shells ▪ Change to another shell ▪ csh ▪ Date ▪ date ▪ wget: get online files ▪ wget https://ftp.gnu.org/gnu/gcc/gcc-7.1.0/gcc-7.1.0.tar.gz ▪ Compile and run applications ▪ gcc hello.c –o hello ▪ ./hello ▪ What we need to learn today? o Automation of an entire script of commands! o Use the shell script to run jobs – Write job scripts Basic Shell Scripting 6 Shell Scripting ▪ Script: a program written for a software environment to automate execution of tasks ▪ A series of shell commands put together in a file ▪ When the script is executed, those commands will be executed one line at a time automatically ▪ Shell script is interpreted, not compiled. -
Linking + Libraries
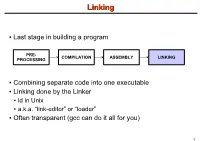
LinkingLinking ● Last stage in building a program PRE- COMPILATION ASSEMBLY LINKING PROCESSING ● Combining separate code into one executable ● Linking done by the Linker ● ld in Unix ● a.k.a. “link-editor” or “loader” ● Often transparent (gcc can do it all for you) 1 LinkingLinking involves...involves... ● Combining several object modules (the .o files corresponding to .c files) into one file ● Resolving external references to variables and functions ● Producing an executable file (if no errors) file1.c file1.o file2.c gcc file2.o Linker Executable fileN.c fileN.o Header files External references 2 LinkingLinking withwith ExternalExternal ReferencesReferences file1.c file2.c int count; #include <stdio.h> void display(void); Compiler extern int count; int main(void) void display(void) { file1.o file2.o { count = 10; with placeholders printf(“%d”,count); display(); } return 0; Linker } ● file1.o has placeholder for display() ● file2.o has placeholder for count ● object modules are relocatable ● addresses are relative offsets from top of file 3 LibrariesLibraries ● Definition: ● a file containing functions that can be referenced externally by a C program ● Purpose: ● easy access to functions used repeatedly ● promote code modularity and re-use ● reduce source and executable file size 4 LibrariesLibraries ● Static (Archive) ● libname.a on Unix; name.lib on DOS/Windows ● Only modules with referenced code linked when compiling ● unlike .o files ● Linker copies function from library into executable file ● Update to library requires recompiling program 5 LibrariesLibraries ● Dynamic (Shared Object or Dynamic Link Library) ● libname.so on Unix; name.dll on DOS/Windows ● Referenced code not copied into executable ● Loaded in memory at run time ● Smaller executable size ● Can update library without recompiling program ● Drawback: slightly slower program startup 6 LibrariesLibraries ● Linking a static library libpepsi.a /* crave source file */ … gcc .. -

“Log” File in Stata
Updated July 2018 Creating a “Log” File in Stata This set of notes describes how to create a log file within the computer program Stata. It assumes that you have set Stata up on your computer (see the “Getting Started with Stata” handout), and that you have read in the set of data that you want to analyze (see the “Reading in Stata Format (.dta) Data Files” handout). A log file records all your Stata commands and output in a given session, with the exception of graphs. It is usually wise to retain a copy of the work that you’ve done on a given project, to refer to while you are writing up your findings, or later on when you are revising a paper. A log file is a separate file that has either a “.log” or “.smcl” extension. Saving the log as a .smcl file (“Stata Markup and Control Language file”) keeps the formatting from the Results window. It is recommended to save the log as a .log file. Although saving it as a .log file removes the formatting and saves the output in plain text format, it can be opened in most text editing programs. A .smcl file can only be opened in Stata. To create a log file: You may create a log file by typing log using ”filepath & filename” in the Stata Command box. On a PC: If one wanted to save a log file (.log) for a set of analyses on hard disk C:, in the folder “LOGS”, one would type log using "C:\LOGS\analysis_log.log" On a Mac: If one wanted to save a log file (.log) for a set of analyses in user1’s folder on the hard drive, in the folder “logs”, one would type log using "/Users/user1/logs/analysis_log.log" If you would like to replace an existing log file with a newer version add “replace” after the file name (Note: PC file path) log using "C:\LOGS\analysis_log.log", replace Alternately, you can use the menu: click on File, then on Log, then on Begin. -

Encryption Introduction to Using 7-Zip
IT Services Training Guide Encryption Introduction to using 7-Zip It Services Training Team The University of Manchester email: [email protected] www.itservices.manchester.ac.uk/trainingcourses/coursesforstaff Version: 5.3 Training Guide Introduction to Using 7-Zip Page 2 IT Services Training Introduction to Using 7-Zip Table of Contents Contents Introduction ......................................................................................................................... 4 Compress/encrypt individual files ....................................................................................... 5 Email compressed/encrypted files ....................................................................................... 8 Decrypt an encrypted file ..................................................................................................... 9 Create a self-extracting encrypted file .............................................................................. 10 Decrypt/un-zip a file .......................................................................................................... 14 APPENDIX A Downloading and installing 7-Zip ................................................................. 15 Help and Further Reference ............................................................................................... 18 Page 3 Training Guide Introduction to Using 7-Zip Introduction 7-Zip is an application that allows you to: Compress a file – for example a file that is 5MB can be compressed to 3MB Secure the -

Red Hat Jboss Data Grid 7.2 Data Grid for Openshift
Red Hat JBoss Data Grid 7.2 Data Grid for OpenShift Developing and deploying Red Hat JBoss Data Grid for OpenShift Last Updated: 2019-06-10 Red Hat JBoss Data Grid 7.2 Data Grid for OpenShift Developing and deploying Red Hat JBoss Data Grid for OpenShift Legal Notice Copyright © 2019 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. -

21Files2.Pdf
Here is a portion of a Unix directory tree. The ovals represent files, the rectangles represent directories (which are really just special cases of files). A simple implementation of a directory consists of an array of pairs of component name and inode number, where the latter identifies the target file’s inode to the operating system (an inode is data structure maintained by the operating system that represents a file). Note that every directory contains two special entries, “.” and “..”. The former refers to the directory itself, the latter to the directory’s parent (in the case of the slide, the directory is the root directory and has no parent, thus its “..” entry is a special case that refers to the directory itself). While this implementation of a directory was used in early file systems for Unix, it suffers from a number of practical problems (for example, it doesn’t scale well for large directories). It provides a good model for the semantics of directory operations, but directory implementations on modern systems are more complicated than this (and are beyond the scope of this course). Here are two directory entries referring to the same file. This is done, via the shell, through the ln command which creates a (hard) link to its first argument, giving it the name specified by its second argument. The shell’s “ln” command is implemented using the link system call. Here are the (abbreviated) contents of both the root (/) and /etc directories, showing how /unix and /etc/image are the same file. Note that if the directory entry /unix is deleted (via the shell’s “rm” command), the file (represented by inode 117) continues to exist, since there is still a directory entry referring to it. -

Steganography and Vulnerabilities in Popular Archives Formats.| Nyxengine Nyx.Reversinglabs.Com
Hiding in the Familiar: Steganography and Vulnerabilities in Popular Archives Formats.| NyxEngine nyx.reversinglabs.com Contents Introduction to NyxEngine ............................................................................................................................ 3 Introduction to ZIP file format ...................................................................................................................... 4 Introduction to steganography in ZIP archives ............................................................................................. 5 Steganography and file malformation security impacts ............................................................................... 8 References and tools .................................................................................................................................... 9 2 Introduction to NyxEngine Steganography1 is the art and science of writing hidden messages in such a way that no one, apart from the sender and intended recipient, suspects the existence of the message, a form of security through obscurity. When it comes to digital steganography no stone should be left unturned in the search for viable hidden data. Although digital steganography is commonly used to hide data inside multimedia files, a similar approach can be used to hide data in archives as well. Steganography imposes the following data hiding rule: Data must be hidden in such a fashion that the user has no clue about the hidden message or file's existence. This can be achieved by -

Chapter 11. Media Formats for Data Submission and Archive 11-1
Chapter 11. Media Formats for Data Submission and Archive 11-1 Chapter 11. Media Formats for Data Submission and Archive This standard identifies the physical media formats to be used for data submission or delivery to the PDS or its science nodes. The PDS expects flight projects to deliver all archive products on magnetic or optical media. Electronic delivery of modest volumes of special science data products may be negotiated with the science nodes. Archive Planning - During archive planning, the data producer and PDS will determine the medium (or media) to use for data submission and archiving. This standard lists the media that are most commonly used for submitting data to and subsequently archiving data with the PDS. Delivery of data on media other than those listed here may be negotiated with the PDS on a case- by-case basis. Physical Media for Archive - For archival products only media that conform to the appropriate International Standards Organization (ISO) standard for physical and logical recording formats may be used. 1. The preferred data delivery medium is the Compact Disk (CD-ROM or CD-Recordable) produced in ISO 9660 format, using Interchange Level 1, subject to the restrictions listed in Section 10.1.1. 2. Compact Disks may be produced in ISO 9660 format using Interchange Level 2, subject to the restrictions listed in Section 10.1.2. 3. Digital Versatile Disk (DVD-ROM or DVD-R) should be produced in UDF-Bridge format (Universal Disc Format) with ISO 9660 Level 1 or Level 2 compatibility. Because of hardware compatibility and long-term stability issues, the use of 12-inch Write Once Read Many (WORM) disk, 8-mm Exabyte tape, 4-mm DAT tape, Bernoulli Disks, Zip disks, Syquest disks and Jaz disks is not recommended for archival use. -
![User Commands GZIP ( 1 ) Gzip, Gunzip, Gzcat – Compress Or Expand Files Gzip [ –Acdfhllnnrtvv19 ] [–S Suffix] [ Name ... ]](https://docslib.b-cdn.net/cover/1609/user-commands-gzip-1-gzip-gunzip-gzcat-compress-or-expand-files-gzip-acdfhllnnrtvv19-s-suffix-name-561609.webp)
User Commands GZIP ( 1 ) Gzip, Gunzip, Gzcat – Compress Or Expand Files Gzip [ –Acdfhllnnrtvv19 ] [–S Suffix] [ Name ... ]
User Commands GZIP ( 1 ) NAME gzip, gunzip, gzcat – compress or expand files SYNOPSIS gzip [–acdfhlLnNrtvV19 ] [– S suffix] [ name ... ] gunzip [–acfhlLnNrtvV ] [– S suffix] [ name ... ] gzcat [–fhLV ] [ name ... ] DESCRIPTION Gzip reduces the size of the named files using Lempel-Ziv coding (LZ77). Whenever possible, each file is replaced by one with the extension .gz, while keeping the same ownership modes, access and modification times. (The default extension is – gz for VMS, z for MSDOS, OS/2 FAT, Windows NT FAT and Atari.) If no files are specified, or if a file name is "-", the standard input is compressed to the standard output. Gzip will only attempt to compress regular files. In particular, it will ignore symbolic links. If the compressed file name is too long for its file system, gzip truncates it. Gzip attempts to truncate only the parts of the file name longer than 3 characters. (A part is delimited by dots.) If the name con- sists of small parts only, the longest parts are truncated. For example, if file names are limited to 14 characters, gzip.msdos.exe is compressed to gzi.msd.exe.gz. Names are not truncated on systems which do not have a limit on file name length. By default, gzip keeps the original file name and timestamp in the compressed file. These are used when decompressing the file with the – N option. This is useful when the compressed file name was truncated or when the time stamp was not preserved after a file transfer. Compressed files can be restored to their original form using gzip -d or gunzip or gzcat.