Augmented Unix Userland
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
It's Complicated but It's Probably Already Booting Your Computer
FAQ SYSTEMD SYSTEMD It’s complicated but it’s probably already booting your computer. dynamically connect to your network, a runlevel of 1 for a single-user mode, GRAHAM MORRISON while syslogd pools all the system runlevel 3 for the same command messages together to create a log of prompt we described earlier, and Surely the ‘d’ in Systemd is everything important. Another daemon, runlevel 5 to launch a graphical a typo? though it lacks the ‘d’, is init – famous environment. Changing this for your No –it’s a form of Unix notation for being the first process that runs on next boot often involved editing the used to signify a daemon. your system. /etc/inittab file, and you’d soon get used to manually starting and stopping You mean like those little Isn’t init used to switch your own services simply by executing devils inhabiting Dante’s between the command-line the scripts you found. underworld? and the graphical desktop? There is a link in that Unix usage For many of us, yes. This was the You seem to be using the past of the term daemon supposedly main way of going from the tense for all this talk about the comes from Greek mythology, where desktop to a command line and back init daemon… daemons invisibly wove their magic again without trying to figure out which That’s because the and benign influence. The word is today processes to kill or start manually. aforementioned Systemd wants more commonly spelt ‘demon’, which Typing init 3 would typically close any to put init in the past. -

CIS 90 - Lesson 2
CIS 90 - Lesson 2 Lesson Module Status • Slides - draft • Properties - done • Flash cards - NA • First minute quiz - done • Web calendar summary - done • Web book pages - gillay done • Commands - done • Lab tested – done • Print latest class roster - na • Opus accounts created for students submitting Lab 1 - • CCC Confer room whiteboard – done • Check that headset is charged - done • Backup headset charged - done • Backup slides, CCC info, handouts on flash drive - done 1 CIS 90 - Lesson 2 [ ] Has the phone bridge been added? [ ] Is recording on? [ ] Does the phone bridge have the mike? [ ] Share slides, putty, VB, eko and Chrome [ ] Disable spelling on PowerPoint 2 CIS 90 - Lesson 2 Instructor: Rich Simms Dial-in: 888-450-4821 Passcode: 761867 Emanuel Tanner Merrick Quinton Christopher Zachary Bobby Craig Jeff Yu-Chen Greg L Tommy Eric Dan M Geoffrey Marisol Jason P David Josh ? ? ? ? Leobardo Gabriel Jesse Tajvia Daniel W Jason W Terry? James? Glenn? Aroshani? ? ? ? ? ? ? = need to add (with add code) to enroll in Ken? Luis? Arturo? Greg M? Ian? this course Email me ([email protected]) a relatively current photo of your face for 3 points extra credit CIS 90 - Lesson 2 First Minute Quiz Please close your books, notes, lesson materials, forum and answer these questions in the order shown: 1. What command shows the other users logged in to the computer? 2. What is the lowest level, inner-most component of a UNIX/Linux Operating System called? 3. What part of UNIX/Linux is both a user interface and a programming language? email answers to: [email protected] 4 CIS 90 - Lesson 2 Commands Objectives Agenda • Understand how the UNIX login • Quiz operation works. -

Beginning Portable Shell Scripting from Novice to Professional
Beginning Portable Shell Scripting From Novice to Professional Peter Seebach 10436fmfinal 1 10/23/08 10:40:24 PM Beginning Portable Shell Scripting: From Novice to Professional Copyright © 2008 by Peter Seebach All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage or retrieval system, without the prior written permission of the copyright owner and the publisher. ISBN-13 (pbk): 978-1-4302-1043-6 ISBN-10 (pbk): 1-4302-1043-5 ISBN-13 (electronic): 978-1-4302-1044-3 ISBN-10 (electronic): 1-4302-1044-3 Printed and bound in the United States of America 9 8 7 6 5 4 3 2 1 Trademarked names may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, we use the names only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. Lead Editor: Frank Pohlmann Technical Reviewer: Gary V. Vaughan Editorial Board: Clay Andres, Steve Anglin, Ewan Buckingham, Tony Campbell, Gary Cornell, Jonathan Gennick, Michelle Lowman, Matthew Moodie, Jeffrey Pepper, Frank Pohlmann, Ben Renow-Clarke, Dominic Shakeshaft, Matt Wade, Tom Welsh Project Manager: Richard Dal Porto Copy Editor: Kim Benbow Associate Production Director: Kari Brooks-Copony Production Editor: Katie Stence Compositor: Linda Weidemann, Wolf Creek Press Proofreader: Dan Shaw Indexer: Broccoli Information Management Cover Designer: Kurt Krames Manufacturing Director: Tom Debolski Distributed to the book trade worldwide by Springer-Verlag New York, Inc., 233 Spring Street, 6th Floor, New York, NY 10013. -

Getting to Grips with Unix and the Linux Family
Getting to grips with Unix and the Linux family David Chiappini, Giulio Pasqualetti, Tommaso Redaelli Torino, International Conference of Physics Students August 10, 2017 According to the booklet At this end of this session, you can expect: • To have an overview of the history of computer science • To understand the general functioning and similarities of Unix-like systems • To be able to distinguish the features of different Linux distributions • To be able to use basic Linux commands • To know how to build your own operating system • To hack the NSA • To produce the worst software bug EVER According to the booklet update At this end of this session, you can expect: • To have an overview of the history of computer science • To understand the general functioning and similarities of Unix-like systems • To be able to distinguish the features of different Linux distributions • To be able to use basic Linux commands • To know how to build your own operating system • To hack the NSA • To produce the worst software bug EVER A first data analysis with the shell, sed & awk an interactive workshop 1 at the beginning, there was UNIX... 2 ...then there was GNU 3 getting hands dirty common commands wait till you see piping 4 regular expressions 5 sed 6 awk 7 challenge time What's UNIX • Bell Labs was a really cool place to be in the 60s-70s • UNIX was a OS developed by Bell labs • they used C, which was also developed there • UNIX became the de facto standard on how to make an OS UNIX Philosophy • Write programs that do one thing and do it well. -

Introduction to Unix
Introduction to Unix Rob Funk <[email protected]> University Technology Services Workstation Support http://wks.uts.ohio-state.edu/ University Technology Services Course Objectives • basic background in Unix structure • knowledge of getting started • directory navigation and control • file maintenance and display commands • shells • Unix features • text processing University Technology Services Course Objectives Useful commands • working with files • system resources • printing • vi editor University Technology Services In the Introduction to UNIX document 3 • shell programming • Unix command summary tables • short Unix bibliography (also see web site) We will not, however, be covering these topics in the lecture. Numbers on slides indicate page number in book. University Technology Services History of Unix 7–8 1960s multics project (MIT, GE, AT&T) 1970s AT&T Bell Labs 1970s/80s UC Berkeley 1980s DOS imitated many Unix ideas Commercial Unix fragmentation GNU Project 1990s Linux now Unix is widespread and available from many sources, both free and commercial University Technology Services Unix Systems 7–8 SunOS/Solaris Sun Microsystems Digital Unix (Tru64) Digital/Compaq HP-UX Hewlett Packard Irix SGI UNICOS Cray NetBSD, FreeBSD UC Berkeley / the Net Linux Linus Torvalds / the Net University Technology Services Unix Philosophy • Multiuser / Multitasking • Toolbox approach • Flexibility / Freedom • Conciseness • Everything is a file • File system has places, processes have life • Designed by programmers for programmers University Technology Services -

Ardpower Documentation Release V1.2.0
ardPower Documentation Release v1.2.0 Anirban Roy Das Sep 27, 2017 Contents 1 Introduction 1 2 Screenshot 3 3 Documentaion 5 3.1 Overview.................................................5 3.2 Installation................................................7 3.3 Usage................................................... 12 4 Indices and tables 13 i ii CHAPTER 1 Introduction Its a custom Oh-My-Zsh Theme inspired by many custom themes suited for a perfect ZSH Environment under Byobu with Tmux Backend. 1 ardPower Documentation, Release v1.2.0 2 Chapter 1. Introduction 3 ardPower Documentation, Release v1.2.0 CHAPTER 2 Screenshot 4 Chapter 2. Screenshot CHAPTER 3 Documentaion You can also find PDF version of the documentation here. Overview We will start with understanding the individual components of an entire CLI. Generally we don’t put much attention to what we do. We just fire up a terminal or some say sheel and start typing our commands and get the result. That’s all. But there are a lot of things that goes behind all this. Terminal The very first component is the Terminal. So what is a Terminal? A terminal emulator, terminal application, term, or tty for short, is a program that emulates a video ter- minal within some other display architecture. Though typically synonymous with a shell or text terminal, the term terminal covers all remote terminals, including graphical interfaces. A terminal emulator inside a graphical user interface is often called a terminal window.A terminal window allows the user access to a text terminal and all its applications such as command-line interfaces (CLI) and text user interface (TUI) applications. -
APPENDIX a Aegis and Unix Commands
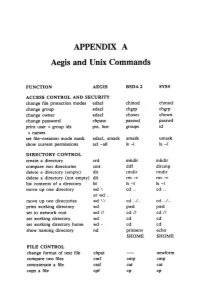
APPENDIX A Aegis and Unix Commands FUNCTION AEGIS BSD4.2 SYSS ACCESS CONTROL AND SECURITY change file protection modes edacl chmod chmod change group edacl chgrp chgrp change owner edacl chown chown change password chpass passwd passwd print user + group ids pst, lusr groups id +names set file-creation mode mask edacl, umask umask umask show current permissions acl -all Is -I Is -I DIRECTORY CONTROL create a directory crd mkdir mkdir compare two directories cmt diff dircmp delete a directory (empty) dlt rmdir rmdir delete a directory (not empty) dlt rm -r rm -r list contents of a directory ld Is -I Is -I move up one directory wd \ cd .. cd .. or wd .. move up two directories wd \\ cd . ./ .. cd . ./ .. print working directory wd pwd pwd set to network root wd II cd II cd II set working directory wd cd cd set working directory home wd- cd cd show naming directory nd printenv echo $HOME $HOME FILE CONTROL change format of text file chpat newform compare two files emf cmp cmp concatenate a file catf cat cat copy a file cpf cp cp Using and Administering an Apollo Network 265 copy std input to std output tee tee tee + files create a (symbolic) link crl In -s In -s delete a file dlf rm rm maintain an archive a ref ar ar move a file mvf mv mv dump a file dmpf od od print checksum and block- salvol -a sum sum -count of file rename a file chn mv mv search a file for a pattern fpat grep grep search or reject lines cmsrf comm comm common to 2 sorted files translate characters tic tr tr SHELL SCRIPT TOOLS condition evaluation tools existf test test -

If Data Is Confidential and Available but Altered Decryption of Altered Data Usually Gives Garbage Exception: Electronic-Codeboo
38 40 If Data is Confidential and Available but Altered Encryption • do not use ECB–Mode • use CBC– or CTR–mode (recommendation Schneier/Ferguson) • use AES or one of the finalists – Twofish (Schneier, Ferguson, Kelsey, Whiting, Wagner, Hall) decryption of altered data usually gives garbage – Serpent (Anderson, Biham, Knudsen) – MARS (Coppersmith et al., IBM) exception: electronic-codebook-mode (ECB) (uses independent blocks) – RC6 (Rivest, patented by RSA) 39 41 ECB-Mode Encrypted Penguin If Data is Non-Alterable and Confidential but not Available ,,Your message with authenticator 08931281763e1de003e5f930c449bf791c9f0db6 encryption is block by block has been received, but unfortunately the server is down. ❀ every block gets another color Your mail-service will never be accessible.” Example: lavabit.com, Snowden’s e-Mail-Provider 42 44 Authorization: Who is Allowed to Do All This? Problem: Person/Process/Role ⇐⇒ String (2) How to link a person to a string? • Person knows something (password, secret cryptographic key). • Person has something (token, USB–key, chipcard). Authorized entities only. • Person is something (biometrics, fingerprint etc.). Only Bob is allowed to enter here. We have to identify persons, processes and their roles. 43 45 Problem: Person/Process/Role ⇐⇒ String (1) Proof of Identity is Called Authentication Person identified by picture String identified by equality relation. 46 48 Proof of Identity: Links Person to a String Third party guarantees real identity. Has something: ID–card. 47 49 Proof of True Source is Called Authenticity -

GNU Coreutils Cheat Sheet (V1.00) Created by Peteris Krumins ([email protected], -- Good Coders Code, Great Coders Reuse)
GNU Coreutils Cheat Sheet (v1.00) Created by Peteris Krumins ([email protected], www.catonmat.net -- good coders code, great coders reuse) Utility Description Utility Description arch Print machine hardware name nproc Print the number of processors base64 Base64 encode/decode strings or files od Dump files in octal and other formats basename Strip directory and suffix from file names paste Merge lines of files cat Concatenate files and print on the standard output pathchk Check whether file names are valid or portable chcon Change SELinux context of file pinky Lightweight finger chgrp Change group ownership of files pr Convert text files for printing chmod Change permission modes of files printenv Print all or part of environment chown Change user and group ownership of files printf Format and print data chroot Run command or shell with special root directory ptx Permuted index for GNU, with keywords in their context cksum Print CRC checksum and byte counts pwd Print current directory comm Compare two sorted files line by line readlink Display value of a symbolic link cp Copy files realpath Print the resolved file name csplit Split a file into context-determined pieces rm Delete files cut Remove parts of lines of files rmdir Remove directories date Print or set the system date and time runcon Run command with specified security context dd Convert a file while copying it seq Print sequence of numbers to standard output df Summarize free disk space setuidgid Run a command with the UID and GID of a specified user dir Briefly list directory -

Lab 2: Using Commands
Lab 2: Using Commands The purpose of this lab is to explore command usage with the shell and miscellaneous UNIX commands. Preparation Everything you need to do this lab can be found in the Lesson 2 materials on the CIS 90 Calendar: http://simms-teach.com/cis90calendar.php. Review carefully all Lesson 2 slides, even those that may not have been covered in class. Check the forum at: http://oslab.cis.cabrillo.edu/forum/ for any tips and updates related to this lab. The forum is also a good place to ask questions if you get stuck or help others. If you would like some additional assistance come to the CIS Lab on campus where you can get help from instructors and student lab assistants: http://webhawks.org/~cislab/. Procedure Please log into the Opus server at oslab.cis.cabrillo.edu via port 2220. You will need to use the following commands in this lab. banner clear finger man uname bash date history passwd whatis bc echo id ps who cal exit info type Only your command history along with the three answers asked for by the submit script will be graded. You must issue each command below (exactly). Rather than submitting answers to any questions asked below you must instead issue the correct commands to answer them. Your command history will be scanned to verify each step was completed. The Shell 1. What shell are you currently using? What command did you use to determine this? (Hint: We did this in Lab 1) 2. The type command shows where a command is located. -

Using Parallel Execution Perl Program on Multiple Biohpc Lab Machines
Using parallel execution Perl program on multiple BioHPC Lab machines This Perl program is intended to run on multiple machines, and it is also possible to run multiple programs on each machine. This Perl program takes 2 arguments: /programs/bin/perlscripts/perl_fork_univ.pl JobListFile MachineFile JobListFile is a file containing all the commands to execute – one per line. MachineFile is the file with the list of machines to be used (one per line), with a number of processes to execute in parallel on this machine following the machine name: cbsumm14 24 cbsumm15 24 cbsumm16 24 Typical examples of parallel Perl driver use are cases when the number of tasks exceeds the number of cores. For example, when the number of libraries in RAN-seq project is large (say 500), you can prepare a file with all tophat tasks needed (50 lines, no ‘&’ at the end of lines!, each of them on 7 cores) and then run 9 of them at a time on 2 64 core machines (using total 63 cores on each machine – 9 instances at a time using 7 cores each). Using multiple machines is more complicated than running parallel Perl driver on a single machine. Local directory /workdir is not visible across machines so the processes will need to use home directory for files storage and communication. Also, you need to enable program execution between BioHPC Lab machines without a need to enter your password. It can be done using the following commands: cd ~ ssh-keygen -t rsa (use empty password when prompted) cat .ssh/id_rsa.pub >> .ssh/authorized_keys chmod 640 .ssh/authorized_keys chmod 700 .ssh A good example is PAML simulation on 110 genes. -

Unix Shell Programming – by Dinesh Kumar S
1 Unix Shell Programming – by Dinesh Kumar S PDF by http://www.k2pdf.com Contents Chapters Topic Page no. Chapter 1 Introduction 3 Chapter 2 SSH Client 4 Chapter 3 Unix Shells 8 Chapter 4 Text Editors 11 Chapter 5 A Beginning to Shell Scripting 19 Chapter 6 Operators 33 Chapter 7 Variables Manipulation (Advance) 39 Chapter 8 Conditional Statements 43 Chapter 9 Looping Statements 47 Chapter 10 Control Statements 74 Chapter 11 Functions 79 2 Unix Shell Programming – by Dinesh Kumar S Chapter 1 Introduction Linux : It is an operating system based on UNIX . Kernel : It is the backbone of Linux OS, which is used to manage resources of Linux OS like memory, I/O, software, hardware management processes. User Shell Script Kernel PC h/w User writes script. Script contains instructions. Kernel interprets the instruction in machine language. As per the instruction kernel controls the PC hardware. Shell script : It’s a collection of OS commands or instructions. Advantages of Shell Script : Script is always a platform independent. Performance will be faster than programming languages. Very easy to debug. 3 Unix Shell Programming – by Dinesh Kumar S Chapter 2 SSH Client Secure Shell (or) SSH is a network protocol that is used to exchange or share information between two different networks. This is used on Linux & UNIX systems to access SHELL accounts. All the information exchanged/transmitted between networks is encrypted . It uses public key cryptography to authenticate remote computer user. Free Serial, Telnet, and SSH client Putty Tera Term Putty : It is a terminal emulator application which acts as client for SSH, Telnet, rLogin.