Mining Software Engineering Data for Useful Knowledge Boris Baldassari
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SEO Footprints
SEO Footprints Brought to you by: Jason Rushton Copyright 2013 Online - M a r k e t i n g - T o o l s . c o m Page 1 Use these “Footprints” with your niche specific keywords to find Backlink sources. Some of the footprints below have already been formed into ready made search queries. TIP* If you find a footprint that returns the results you are looking for, there is no need to use the rest in that section. For example if I am looking for wordpress sites that allow comments and the search query “powered by wordpress” “YOUR YOUR KEYWORDS” returns lots of results there is no need to use all of the others that target wordpress sites as a lot of them will produce similar results. I would use one or two from each section. You can try them out and when you find one you like add it to your own list of favourites. Blogs “article directory powered by wordpress” “YOUR YOUR KEYWORDS” “blog powered by wordpress” “YOUR YOUR KEYWORDS” “blogs powered by typepad” “YOUR YOUR KEYWORDS” “YOURYOUR KEYWORDS” inurl:”trackback powered by wordpress” “powered by blogengine net 1.5.0.7” “YOUR YOUR KEYWORDS” “powered by blogengine.net” “YOUR YOUR KEYWORDS” “powered by blogengine.net add comment” “YOUR YOUR KEYWORDS” “powered by typepad” “YOUR YOUR KEYWORDS” “powered by wordpress” “YOUR YOUR KEYWORDS” “powered by wordpress review theme” “YOUR YOUR KEYWORDS” “proudly powered by wordpress” “YOUR YOUR KEYWORDS” “remove powered by wordpress” “YOUR YOUR KEYWORDS” Copyright 2013 Online - M a r k e t i n g - T o o l s . -

Java Programming Standards & Reference Guide
Java Programming Standards & Reference Guide Version 3.2 Office of Information & Technology Department of Veterans Affairs Java Programming Standards & Reference Guide, Version 3.2 REVISION HISTORY DATE VER. DESCRIPTION AUTHOR CONTRIBUTORS 10-26-15 3.2 Added Logging Sid Everhart JSC Standards , updated Vic Pezzolla checkstyle installation instructions and package name rules. 11-14-14 3.1 Added ground rules for Vic Pezzolla JSC enforcement 9-26-14 3.0 Document is continually Raymond JSC and several being edited for Steele OI&T noteworthy technical accuracy and / PD Subject Matter compliance to JSC Experts (SMEs) standards. 12-1-09 2.0 Document Updated Michael Huneycutt Sr 4-7-05 1.2 Document Updated Sachin Mai L Vo Sharma Lyn D Teague Rajesh Somannair Katherine Stark Niharika Goyal Ron Ruzbacki 3-4-05 1.0 Document Created Sachin Sharma i Java Programming Standards & Reference Guide, Version 3.2 ABSTRACT The VA Java Development Community has been establishing standards, capturing industry best practices, and applying the insight of experienced (and seasoned) VA developers to develop this “Java Programming Standards & Reference Guide”. The Java Standards Committee (JSC) team is encouraging the use of CheckStyle (in the Eclipse IDE environment) to quickly scan Java code, to locate Java programming standard errors, find inconsistencies, and generally help build program conformance. The benefits of writing quality Java code infused with consistent coding and documentation standards is critical to the efforts of the Department of Veterans Affairs (VA). This document stands for the quality, readability, consistency and maintainability of code development and it applies to all VA Java programmers (including contractors). -

Command Line Interface
Command Line Interface Squore 21.0.2 Last updated 2021-08-19 Table of Contents Preface. 1 Foreword. 1 Licence. 1 Warranty . 1 Responsabilities . 2 Contacting Vector Informatik GmbH Product Support. 2 Getting the Latest Version of this Manual . 2 1. Introduction . 3 2. Installing Squore Agent . 4 Prerequisites . 4 Download . 4 Upgrade . 4 Uninstall . 5 3. Using Squore Agent . 6 Command Line Structure . 6 Command Line Reference . 6 Squore Agent Options. 6 Project Build Parameters . 7 Exit Codes. 13 4. Managing Credentials . 14 Saving Credentials . 14 Encrypting Credentials . 15 Migrating Old Credentials Format . 16 5. Advanced Configuration . 17 Defining Server Dependencies . 17 Adding config.xml File . 17 Using Java System Properties. 18 Setting up HTTPS . 18 Appendix A: Repository Connectors . 19 ClearCase . 19 CVS . 19 Folder Path . 20 Folder (use GNATHub). 21 Git. 21 Perforce . 23 PTC Integrity . 25 SVN . 26 Synergy. 28 TFS . 30 Zip Upload . 32 Using Multiple Nodes . 32 Appendix B: Data Providers . 34 AntiC . 34 Automotive Coverage Import . 34 Automotive Tag Import. 35 Axivion. 35 BullseyeCoverage Code Coverage Analyzer. 36 CANoe. 36 Cantata . 38 CheckStyle. .. -

Squore Acceptance Provides a Fast and High Return on Investment by Efficiently
Acceptance SQUORE Squoring Technologies delivers an innovative decision-making dashboard dedicated to managing outsourced software development projects. Acceptance represents a key phase of every software development project, whatever the process: Acquisition or Third Party Application Maintenance. Beyond functional suitability, Acceptance must consider all software product dimensions, from quality characteristics such as Reliability, Maintainability and Performance, to work products like source code, requirements and test cases. TREND As required by the CMMI®, Supplier Management INDICATOR implies an objective and impartial assessment of these components, based on quantified measurement criteria adapted to the context and objectives of each project. Squore Acceptance provides a fast and high return on investment by efficiently: Contractualizing non- Increasing confidence Securing deployment functional, technical between customer and and operation. requirements. supplier. Defining common and Demonstrating compliance Reducing acceptance shared acceptance of deliverables with costs and efforts. criteria. quality requirements. Visit www.squore-acceptance.com Innovative features dedicated to the management of outsourced software projects. “Out-of-the-box” standardized control points, metrics and rules using best industry standards, and still customizable to fit in-house practices. Predefined software product quality models based on international standards: ISO SQuaRE 25010, ISO/IEC 9126, ECSS Quality Handbook, SQUALE . Standardized evaluation process in accordance with ISO/IEC 14598 and ISO/IEC 15939 standards. Squore covers all software product quality characteristics under a standard breakdown Quantified acceptance criteria for every type of deliverable, from requirements to documentation, via source code and test cases. Comprehensive overview of software product compliance through Key Performance Indicators and trend analysis. Unrivaled in-depth analysis where at-risk components are immediately identified, down to the most elementary function or method. -

Write Your Own Rules and Enforce Them Continuously
Ultimate Architecture Enforcement Write Your Own Rules and Enforce Them Continuously SATURN May 2017 Paulo Merson Brazilian Federal Court of Accounts Agenda Architecture conformance Custom checks lab Sonarqube Custom checks at TCU Lessons learned 2 Exercise 0 – setup Open www.dontpad.com/saturn17 Follow the steps for “Exercise 0” Pre-requisites for all exercises: • JDK 1.7+ • Java IDE of your choice • maven 3 Consequences of lack of conformance Lower maintainability, mainly because of undesired dependencies • Code becomes brittle, hard to understand and change Possible negative effect • on reliability, portability, performance, interoperability, security, and other qualities • caused by deviation from design decisions that addressed these quality requirements 4 Factors that influence architecture conformance How effective the architecture documentation is Turnover among developers Haste to fix bugs or implement features Size of the system Distributed teams (outsourcing, offshoring) Accountability for violating design constraints 5 How to avoid code and architecture disparity? 1) Communicate the architecture to developers • Create multiple views • Structural diagrams + behavior diagrams • Capture rationale Not the focus of this tutorial 6 How to avoid code and architecture disparity? 2) Automate architecture conformance analysis • Often done with static analysis tools 7 Built-in checks and custom checks Static analysis tools come with many built-in checks • They are useful to spot bugs and improve your overall code quality • But they’re -

Open Source Tools for Measuring the Internal Quality of Java Software Products
Open source tools for measuring the Internal Quality of Java software products. Asurvey P. Tomas, M.J. Escalona , M. Mejias Department of Computer and Systems, ETS Ingenieria Informatica, University of Seville, Av. Reina Mercedes S/N, 41012 Seville,Spain abstract Keywords: Collecting metrics and indicators to assess objectively the different products resulting during the lifecycle Software product of a software project is a research area that encompasses many different aspects, apart from being highly Tools demanded by companies and software development teams. Open source Focusing on software products, one of the most used methods by development teams for measuring Internal Metrics Quality is the static analysis of the source code. This paper works in this line and presents a study of the state- Internal Quality of-the-art open source software tools that automate the collection of these metrics, particularly for Automation fi Static analysis developments in Java. These tools have been compared according to certain criteria de ned in this study. Source code Java Contents 1. Introduction.............................................................. 245 2. Relatedwork............................................................. 246 3. Planningandconductingthereview................................................... 246 3.1. Acharacterizationschema.................................................... 247 3.1.1. Metricsimplemented.................................................. 248 3.1.2. Functionalfeaturescovered.............................................. -

Adhering to Coding Standards and Finding Bugs in Code Automatically
Adhering to Coding Standards and Finding Bugs in Code Automatically Presenters: Muhammad Wasim Hammad Ali Butt Al-khawarzimi Institute of Computer Science Agenda Introduction Software Quality Assurance Code: The base for Quality Code: Writing it Code: Reviewing it How Review tools help? Selecting a Code Review Tools How they compare to each other? Conclusion Al-khawarizimi Institute of Computer Science Introduction Software Quality Quality Attributes • Maintainability • Flexibility • Testability • Portability • Reusability • Interoperability • Correctness • Reliability • Efficiency • Integrity • Usability Code: The Base for Quality Software Quality comes with a lot of benefits Al-khawarizimi Institute of Computer Science SQA and Benefits Development/Technical: Increase Readability Easy to locate problem area Performance Enhancements Compliance between Specs & Code Criteria for software acceptance Management: Better Progress visibility Better decision criteria Reduced Maintenance cost Al-khawarizimi Institute of Computer Science Code: The Base for Quality Better Coding Styles (Structured to OOP) Commenting of Code Coding Conventions Design Patterns Low Coupling High Cohesiveness Resource Management Remove Repetition of Code Al-khawarizimi Institute of Computer Science Code: Writing it Well Managed Code Well Written Code Standardized Code Defensive Coding An ideal programmer won’t leave any bugs for compiler or QA team. Al-khawarizimi Institute of Computer Science Code: Reviewing It Review Meetings Peer Review Benefits: Code Optimization Reduced Cost Programmer Improvement Static Code Analysis is used for Code Review. Al-khawarizimi Institute of Computer Science Code Review on a Typical Project http://smartbear.com/docs/articles/before-code-review.jpg Al-khawarizimi Institute of Computer Science Code Review on a Typical Project http://smartbear.com/docs/articles/after-code-review.jpg Al-khawarizimi Institute of Computer Science Code Review & Issues Human is error prone. -

Appendix a the Ten Commandments for Websites
Appendix A The Ten Commandments for Websites Welcome to the appendixes! At this stage in your learning, you should have all the basic skills you require to build a high-quality website with insightful consideration given to aspects such as accessibility, search engine optimization, usability, and all the other concepts that web designers and developers think about on a daily basis. Hopefully with all the different elements covered in this book, you now have a solid understanding as to what goes into building a website (much more than code!). The main thing you should take from this book is that you don’t need to be an expert at everything but ensuring that you take the time to notice what’s out there and deciding what will best help your site are among the most important elements of the process. As you leave this book and go on to updating your website over time and perhaps learning new skills, always remember to be brave, take risks (through trial and error), and never feel that things are getting too hard. If you choose to learn skills that were only briefly mentioned in this book, like scripting, or to get involved in using content management systems and web software, go at a pace that you feel comfortable with. With that in mind, let’s go over the 10 most important messages I would personally recommend. After that, I’ll give you some useful resources like important websites for people learning to create for the Internet and handy software. Advice is something many professional designers and developers give out in spades after learning some harsh lessons from what their own bitter experiences. -

Locating Exploits and Finding Targets
452_Google_2e_06.qxd 10/5/07 12:52 PM Page 223 Chapter 6 Locating Exploits and Finding Targets Solutions in this chapter: ■ Locating Exploit Code ■ Locating Vulnerable Targets ■ Links to Sites Summary Solutions Fast Track Frequently Asked Questions 223 452_Google_2e_06.qxd 10/5/07 12:52 PM Page 224 224 Chapter 6 • Locating Exploits and Finding Targets Introduction Exploits, are tools of the hacker trade. Designed to penetrate a target, most hackers have many different exploits at their disposal. Some exploits, termed zero day or 0day, remain underground for some period of time, eventually becoming public, posted to newsgroups or Web sites for the world to share. With so many Web sites dedicated to the distribution of exploit code, it’s fairly simple to harness the power of Google to locate these tools. It can be a slightly more difficult exercise to locate potential targets, even though many modern Web application security advisories include a Google search designed to locate potential targets. In this chapter we’ll explore methods of locating exploit code and potentially vulnerable targets.These are not strictly “dark side” exercises, since security professionals often use public exploit code during a vulnerability assessment. However, only black hats use those tools against systems without prior consent. Locating Exploit Code Untold hundreds and thousands of Web sites are dedicated to providing exploits to the gen- eral public. Black hats generally provide exploits to aid fellow black hats in the hacking community.White hats provide exploits as a way of eliminating false positives from auto- mated tools during an assessment. Simple searches such as remote exploit and vulnerable exploit locate exploit sites by focusing on common lingo used by the security community. -

Robustbase: Basic Robust Statistics
Package ‘robustbase’ June 2, 2021 Version 0.93-8 VersionNote Released 0.93-7 on 2021-01-04 to CRAN Date 2021-06-01 Title Basic Robust Statistics URL http://robustbase.r-forge.r-project.org/ Description ``Essential'' Robust Statistics. Tools allowing to analyze data with robust methods. This includes regression methodology including model selections and multivariate statistics where we strive to cover the book ``Robust Statistics, Theory and Methods'' by 'Maronna, Martin and Yohai'; Wiley 2006. Depends R (>= 3.5.0) Imports stats, graphics, utils, methods, DEoptimR Suggests grid, MASS, lattice, boot, cluster, Matrix, robust, fit.models, MPV, xtable, ggplot2, GGally, RColorBrewer, reshape2, sfsmisc, catdata, doParallel, foreach, skewt SuggestsNote mostly only because of vignette graphics and simulation Enhances robustX, rrcov, matrixStats, quantreg, Hmisc EnhancesNote linked to in man/*.Rd LazyData yes NeedsCompilation yes License GPL (>= 2) Author Martin Maechler [aut, cre] (<https://orcid.org/0000-0002-8685-9910>), Peter Rousseeuw [ctb] (Qn and Sn), Christophe Croux [ctb] (Qn and Sn), Valentin Todorov [aut] (most robust Cov), Andreas Ruckstuhl [aut] (nlrob, anova, glmrob), Matias Salibian-Barrera [aut] (lmrob orig.), Tobias Verbeke [ctb, fnd] (mc, adjbox), Manuel Koller [aut] (mc, lmrob, psi-func.), Eduardo L. T. Conceicao [aut] (MM-, tau-, CM-, and MTL- nlrob), Maria Anna di Palma [ctb] (initial version of Comedian) 1 2 R topics documented: Maintainer Martin Maechler <[email protected]> Repository CRAN Date/Publication 2021-06-02 10:20:02 UTC R topics documented: adjbox . .4 adjboxStats . .7 adjOutlyingness . .9 aircraft . 12 airmay . 13 alcohol . 14 ambientNOxCH . 15 Animals2 . 18 anova.glmrob . 19 anova.lmrob . -

A Practical Guide to Support Predictive Tasks in Data Science
A Practical Guide to Support Predictive Tasks in Data Science Jose´ Augusto Camaraˆ Filho1, Jose´ Maria Monteiro1,Cesar´ Lincoln Mattos1 and Juvencioˆ Santos Nobre2 1Department of Computing, Federal University of Ceara,´ Fortaleza, Ceara,´ Brazil 2Department of Statistics and Applied Mathematics, Federal University of Ceara,´ Fortaleza, Ceara,´ Brazil Keywords: Practical Guide, Prediction, Data Science. Abstract: Currently, professionals from the most diverse areas of knowledge need to explore their data repositories in order to extract knowledge and create new products or services. Several tools have been proposed in order to facilitate the tasks involved in the Data Science lifecycle. However, such tools require their users to have specific (and deep) knowledge in different areas of Computing and Statistics, making their use practically unfeasible for non-specialist professionals in data science. In this paper, we propose a guideline to support predictive tasks in data science. In addition to being useful for non-experts in Data Science, the proposed guideline can support data scientists, data engineers or programmers which are starting to deal with predic- tive tasks. Besides, we present a tool, called DSAdvisor, which follows the stages of the proposed guideline. DSAdvisor aims to encourage non-expert users to build machine learning models to solve predictive tasks, ex- tracting knowledge from their own data repositories. More specifically, DSAdvisor guides these professionals in predictive tasks involving regression and classification. 1 INTRODUCTION dict the future, and create new services and prod- ucts (Ozdemir, 2016). Data science makes it pos- Due to a large amount of data currently available, sible to identifying patterns hidden and obtain new arises the need for professionals of different areas to insights hidden in these datasets, from complex ma- extract knowledge from their repositories to create chine learning algorithms. -
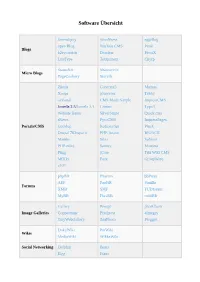
Software Übersicht
Software Übersicht Serendipity WordPress eggBlog open Blog Nucleus CMS Pixie Blogs b2evolution Dotclear PivotX LifeType Textpattern Chyrp StatusNet Sharetronix Micro Blogs PageCookery Storytlr Zikula Concrete5 Mahara Xoops phpwcms Tribiq ocPortal CMS Made Simple ImpressCMS Joomla 2.5/Joomla 3.1 Contao Typo3 Website Baker SilverStripe Quick.cms sNews PyroCMS ImpressPages Portals/CMS Geeklog Redaxscript Pluck Drupal 7/Drupal 8 PHP-fusion BIGACE Mambo Silex Subrion PHP-nuke Saurus Monstra Pligg jCore Tiki Wiki CMS MODx Fork GroupWare e107 phpBB Phorum bbPress AEF PunBB Vanilla Forums XMB SMF FUDforum MyBB FluxBB miniBB Gallery Piwigo phpAlbum Image Galleries Coppermine Pixelpost 4images TinyWebGallery ZenPhoto Plogger DokuWiki PmWiki Wikis MediaWiki WikkaWiki Social Networking Dolphin Beatz Elgg Etano Jcow PeoplePods Oxwall Noahs Classifieds GPixPixel Ad Management OpenX OSClass OpenClassifieds WebCalendar phpScheduleIt Calenders phpicalendar ExtCalendar BlackNova Traders Word Search Puzzle Gaming Shadows Rising MultiPlayer Checkers phplist Webmail Lite Websinsta maillist OpenNewsletter Mails SquirrelMail ccMail RoundCube LimeSurvey LittlePoll Matomo Analytics phpESP Simple PHP Poll Open Web Analytics Polls and Surveys CJ Dynamic Poll Aardvark Topsites Logaholic EasyPoll Advanced Poll dotProject Feng Office Traq phpCollab eyeOSh Collabtive Project PHProjekt The Bug Genie Eventum Management ProjectPier TaskFreak FlySpray Mantis Bug tracker Mound Zen Cart WHMCS Quick.cart Magento Open Source Point of Axis osCommerce Sale TheHostingTool Zuescart