Bioinformatics Approaches for Functional Predictions in Diverse Informatics Environments. Paula Maria Moolhuijzen, Bsc This Thes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bioinformatics Study of Lectins: New Classification and Prediction In
Bioinformatics study of lectins : new classification and prediction in genomes François Bonnardel To cite this version: François Bonnardel. Bioinformatics study of lectins : new classification and prediction in genomes. Structural Biology [q-bio.BM]. Université Grenoble Alpes [2020-..]; Université de Genève, 2021. En- glish. NNT : 2021GRALV010. tel-03331649 HAL Id: tel-03331649 https://tel.archives-ouvertes.fr/tel-03331649 Submitted on 2 Sep 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. THÈSE Pour obtenir le grade de DOCTEUR DE L’UNIVERSITE GRENOBLE ALPES préparée dans le cadre d’une cotutelle entre la Communauté Université Grenoble Alpes et l’Université de Genève Spécialités: Chimie Biologie Arrêté ministériel : le 6 janvier 2005 – 25 mai 2016 Présentée par François Bonnardel Thèse dirigée par la Dr. Anne Imberty codirigée par la Dr/Prof. Frédérique Lisacek préparée au sein du laboratoire CERMAV, CNRS et du Computer Science Department, UNIGE et de l’équipe PIG, SIB Dans les Écoles Doctorales EDCSV et UNIGE Etude bioinformatique des lectines: nouvelle classification et prédiction dans les génomes Thèse soutenue publiquement le 8 Février 2021, devant le jury composé de : Dr. Alexandre de Brevern UMR S1134, Inserm, Université Paris Diderot, Paris, France, Rapporteur Dr. -

Maternally Inherited Pirnas Direct Transient Heterochromatin Formation
RESEARCH ARTICLE Maternally inherited piRNAs direct transient heterochromatin formation at active transposons during early Drosophila embryogenesis Martin H Fabry, Federica A Falconio, Fadwa Joud, Emily K Lythgoe, Benjamin Czech*, Gregory J Hannon* CRUK Cambridge Institute, University of Cambridge, Li Ka Shing Centre, Cambridge, United Kingdom Abstract The PIWI-interacting RNA (piRNA) pathway controls transposon expression in animal germ cells, thereby ensuring genome stability over generations. In Drosophila, piRNAs are intergenerationally inherited through the maternal lineage, and this has demonstrated importance in the specification of piRNA source loci and in silencing of I- and P-elements in the germ cells of daughters. Maternally inherited Piwi protein enters somatic nuclei in early embryos prior to zygotic genome activation and persists therein for roughly half of the time required to complete embryonic development. To investigate the role of the piRNA pathway in the embryonic soma, we created a conditionally unstable Piwi protein. This enabled maternally deposited Piwi to be cleared from newly laid embryos within 30 min and well ahead of the activation of zygotic transcription. Examination of RNA and protein profiles over time, and correlation with patterns of H3K9me3 deposition, suggests a role for maternally deposited Piwi in attenuating zygotic transposon expression in somatic cells of the developing embryo. In particular, robust deposition of piRNAs targeting roo, an element whose expression is mainly restricted to embryonic development, results in the deposition of transient heterochromatic marks at active roo insertions. We hypothesize that *For correspondence: roo, an extremely successful mobile element, may have adopted a lifestyle of expression in the [email protected] embryonic soma to evade silencing in germ cells. -
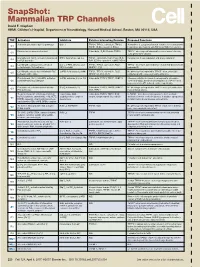
Snapshot: Mammalian TRP Channels David E
SnapShot: Mammalian TRP Channels David E. Clapham HHMI, Children’s Hospital, Department of Neurobiology, Harvard Medical School, Boston, MA 02115, USA TRP Activators Inhibitors Putative Interacting Proteins Proposed Functions Activation potentiated by PLC pathways Gd, La TRPC4, TRPC5, calmodulin, TRPC3, Homodimer is a purported stretch-sensitive ion channel; form C1 TRPP1, IP3Rs, caveolin-1, PMCA heteromeric ion channels with TRPC4 or TRPC5 in neurons -/- Pheromone receptor mechanism? Calmodulin, IP3R3, Enkurin, TRPC6 TRPC2 mice respond abnormally to urine-based olfactory C2 cues; pheromone sensing 2+ Diacylglycerol, [Ca ]I, activation potentiated BTP2, flufenamate, Gd, La TRPC1, calmodulin, PLCβ, PLCγ, IP3R, Potential role in vasoregulation and airway regulation C3 by PLC pathways RyR, SERCA, caveolin-1, αSNAP, NCX1 La (100 µM), calmidazolium, activation [Ca2+] , 2-APB, niflumic acid, TRPC1, TRPC5, calmodulin, PLCβ, TRPC4-/- mice have abnormalities in endothelial-based vessel C4 i potentiated by PLC pathways DIDS, La (mM) NHERF1, IP3R permeability La (100 µM), activation potentiated by PLC 2-APB, flufenamate, La (mM) TRPC1, TRPC4, calmodulin, PLCβ, No phenotype yet reported in TRPC5-/- mice; potentially C5 pathways, nitric oxide NHERF1/2, ZO-1, IP3R regulates growth cones and neurite extension 2+ Diacylglycerol, [Ca ]I, 20-HETE, activation 2-APB, amiloride, Cd, La, Gd Calmodulin, TRPC3, TRPC7, FKBP12 Missense mutation in human focal segmental glomerulo- C6 potentiated by PLC pathways sclerosis (FSGS); abnormal vasoregulation in TRPC6-/- -

The Biogrid Interaction Database
D470–D478 Nucleic Acids Research, 2015, Vol. 43, Database issue Published online 26 November 2014 doi: 10.1093/nar/gku1204 The BioGRID interaction database: 2015 update Andrew Chatr-aryamontri1, Bobby-Joe Breitkreutz2, Rose Oughtred3, Lorrie Boucher2, Sven Heinicke3, Daici Chen1, Chris Stark2, Ashton Breitkreutz2, Nadine Kolas2, Lara O’Donnell2, Teresa Reguly2, Julie Nixon4, Lindsay Ramage4, Andrew Winter4, Adnane Sellam5, Christie Chang3, Jodi Hirschman3, Chandra Theesfeld3, Jennifer Rust3, Michael S. Livstone3, Kara Dolinski3 and Mike Tyers1,2,4,* 1Institute for Research in Immunology and Cancer, Universite´ de Montreal,´ Montreal,´ Quebec H3C 3J7, Canada, 2The Lunenfeld-Tanenbaum Research Institute, Mount Sinai Hospital, Toronto, Ontario M5G 1X5, Canada, 3Lewis-Sigler Institute for Integrative Genomics, Princeton University, Princeton, NJ 08544, USA, 4School of Biological Sciences, University of Edinburgh, Edinburgh EH9 3JR, UK and 5Centre Hospitalier de l’UniversiteLaval´ (CHUL), Quebec,´ Quebec´ G1V 4G2, Canada Received September 26, 2014; Revised November 4, 2014; Accepted November 5, 2014 ABSTRACT semi-automated text-mining approaches, and to en- hance curation quality control. The Biological General Repository for Interaction Datasets (BioGRID: http://thebiogrid.org) is an open access database that houses genetic and protein in- INTRODUCTION teractions curated from the primary biomedical lit- Massive increases in high-throughput DNA sequencing erature for all major model organism species and technologies (1) have enabled an unprecedented level of humans. As of September 2014, the BioGRID con- genome annotation for many hundreds of species (2–6), tains 749 912 interactions as drawn from 43 149 pub- which has led to tremendous progress in the understand- lications that represent 30 model organisms. -

Flybase: Updates to the Drosophila Melanogaster Knowledge Base Aoife Larkin 1,*, Steven J
Published online 21 November 2020 Nucleic Acids Research, 2021, Vol. 49, Database issue D899–D907 doi: 10.1093/nar/gkaa1026 FlyBase: updates to the Drosophila melanogaster knowledge base Aoife Larkin 1,*, Steven J. Marygold 1, Giulia Antonazzo1, Helen Attrill 1, Gilberto dos Santos2, Phani V. Garapati1, Joshua L. Goodman3,L.SianGramates 2, Gillian Millburn1, Victor B. Strelets3, Christopher J. Tabone2, Jim Thurmond3 and FlyBase Consortium† 1 Department of Physiology, Development and Neuroscience, University of Cambridge, Downing Street, Cambridge Downloaded from https://academic.oup.com/nar/article/49/D1/D899/5997437 by guest on 15 January 2021 CB2 3DY, UK, 2The Biological Laboratories, Harvard University, 16 Divinity Avenue, Cambridge, MA 02138, USA and 3Department of Biology, Indiana University, Bloomington, IN 47405, USA Received September 15, 2020; Revised October 13, 2020; Editorial Decision October 14, 2020; Accepted October 22, 2020 ABSTRACT In this paper, we highlight a variety of new features and improvements that have been integrated into FlyBase since FlyBase (flybase.org) is an essential online database our last review (3). We have introduced a number of new fea- for researchers using Drosophila melanogaster as a tures that allow users to more easily find and use the data in model organism, facilitating access to a diverse ar- which they are interested; these include customizable tables, ray of information that includes genetic, molecular, improved searching using expanded Experimental Tool Re- genomic and reagent resources. Here, we describe ports, more links to and from other resources, and bet- the introduction of several new features at FlyBase, ter provision of precomputed bulk files. We have upgraded including Pathway Reports, paralog information, dis- tools such as Fast-Track Your Paper and ID validator. -

Trichoderma Reesei Complete Genome Sequence, Repeat-Induced Point
Li et al. Biotechnol Biofuels (2017) 10:170 DOI 10.1186/s13068-017-0825-x Biotechnology for Biofuels RESEARCH Open Access Trichoderma reesei complete genome sequence, repeat‑induced point mutation, and partitioning of CAZyme gene clusters Wan‑Chen Li1,2,3†, Chien‑Hao Huang3,4†, Chia‑Ling Chen3, Yu‑Chien Chuang3, Shu‑Yun Tung3 and Ting‑Fang Wang1,3* Abstract Background: Trichoderma reesei (Ascomycota, Pezizomycotina) QM6a is a model fungus for a broad spectrum of physiological phenomena, including plant cell wall degradation, industrial production of enzymes, light responses, conidiation, sexual development, polyketide biosynthesis, and plant–fungal interactions. The genomes of QM6a and its high enzyme-producing mutants have been sequenced by second-generation-sequencing methods and are pub‑ licly available from the Joint Genome Institute. While these genome sequences have ofered useful information for genomic and transcriptomic studies, their limitations and especially their short read lengths make them poorly suited for some particular biological problems, including assembly, genome-wide determination of chromosome architec‑ ture, and genetic modifcation or engineering. Results: We integrated Pacifc Biosciences and Illumina sequencing platforms for the highest-quality genome assem‑ bly yet achieved, revealing seven telomere-to-telomere chromosomes (34,922,528 bp; 10877 genes) with 1630 newly predicted genes and >1.5 Mb of new sequences. Most new sequences are located on AT-rich blocks, including 7 centromeres, 14 subtelomeres, and 2329 interspersed AT-rich blocks. The seven QM6a centromeres separately consist of 24 conserved repeats and 37 putative centromere-encoded genes. These fndings open up a new perspective for future centromere and chromosome architecture studies. -

Introduction to Bioinformatics (Elective) – SBB1609
SCHOOL OF BIO AND CHEMICAL ENGINEERING DEPARTMENT OF BIOTECHNOLOGY Unit 1 – Introduction to Bioinformatics (Elective) – SBB1609 1 I HISTORY OF BIOINFORMATICS Bioinformatics is an interdisciplinary field that develops methods and software tools for understanding biologicaldata. As an interdisciplinary field of science, bioinformatics combines computer science, statistics, mathematics, and engineering to analyze and interpret biological data. Bioinformatics has been used for in silico analyses of biological queries using mathematical and statistical techniques. Bioinformatics derives knowledge from computer analysis of biological data. These can consist of the information stored in the genetic code, but also experimental results from various sources, patient statistics, and scientific literature. Research in bioinformatics includes method development for storage, retrieval, and analysis of the data. Bioinformatics is a rapidly developing branch of biology and is highly interdisciplinary, using techniques and concepts from informatics, statistics, mathematics, chemistry, biochemistry, physics, and linguistics. It has many practical applications in different areas of biology and medicine. Bioinformatics: Research, development, or application of computational tools and approaches for expanding the use of biological, medical, behavioral or health data, including those to acquire, store, organize, archive, analyze, or visualize such data. Computational Biology: The development and application of data-analytical and theoretical methods, mathematical modeling and computational simulation techniques to the study of biological, behavioral, and social systems. "Classical" bioinformatics: "The mathematical, statistical and computing methods that aim to solve biological problems using DNA and amino acid sequences and related information.” The National Center for Biotechnology Information (NCBI 2001) defines bioinformatics as: "Bioinformatics is the field of science in which biology, computer science, and information technology merge into a single discipline. -

A Comprehensive Review and Performance Evaluation of Sequence Alignment Algorithms for DNA Sequences
International Journal of Advanced Science and Technology Vol. 29, No. 3, (2020), pp. 11251 - 11265 A Comprehensive Review and Performance Evaluation of Sequence Alignment Algorithms for DNA Sequences Neelofar Sohi1 and Amardeep Singh2 1Assistant Professor, Department of Computer Science & Engineering, Punjabi University Patiala, Punjab, India 2Professor, Department of Computer Science & Engineering, Punjabi University Patiala, Punjab, India [email protected],[email protected] Abstract Background: Sequence alignment is very important step for high level sequence analysis applications in the area of biocomputing. Alignment of DNA sequences helps in finding origin of sequences, homology between sequences, constructing phylogenetic trees depicting evolutionary relationships and other tasks. It helps in identifying genetic variations in DNA sequences which might lead to diseases. Objectives: This paper presents a comprehensive review on sequence alignment approaches, methods and various state-of-the-art algorithms. Performance evaluation and comparison of few algorithms and tools is performed. Methods and Results: In this study, various tools and algorithms are studied, implemented and their performance is evaluated and compared using Identity Percentage is used as the main metric. Conclusion: It is observed that for pairwise sequence alignment, Clustal Omega Emboss Matcher outperforms other tools & algorithms followed by Clustal Omega Emboss Water further followed by Blast (Needleman-Wunsch algorithm for global alignment). Keywords: sequence alignment; DNA sequences; progressive alignment; iterative alignment; natural computing approach; identity percentage. 1. Brief History Sequence alignment is very important area in the field of Biocomputing and Bioinformatics. Sequence alignment aims to identify the regions of similarity between two or more sequences. Alignment is also termed as ‘mapping’ that is done to identify and compare the nucleotide bases i.e. -

GPS@: Bioinformatics Grid Portal for Protein Sequence Analysis on EGEE Grid
Enabling Grids for E-sciencE GPS@: Bioinformatics grid portal for protein sequence analysis on EGEE grid Blanchet, C., Combet, C., Lefort, V. and Deleage, G. Pôle BioInformatique de Lyon – PBIL Institut de Biologie et Chimie des Protéines IBCP – CNRS UMR 5086 Lyon-Gerland, France [email protected] www.eu-egee.org INFSO-RI-508833 TOC Enabling Grids for E-sciencE • NPS@ Web portal – Online since 1998 – Production mode • Gridification of NPS@ • Bioinformatics description with XML-based Framework • Legacy mode for application file access • GPS@ Web portal for Bioinformatics on Grid INFSO-RI-508833 GPS@ Bioinformatics Grid Portal, EGEE User Forum, March 1st, 2006, Cern 2 Institute of Biology and Enabling Grids for E-sciencE Chemistry of Proteins • French CNRS Institute, associated to Univ. Lyon1 – Life Science – About 160 people – http://www.ibcp.fr – Located in Lyon, France • Study of proteins in their biological context ♣ Approaches used include integrative cellular (cell culture, various types of microscopies) and molecular techniques, both experimental (including biocrystallography and nuclear magnetic resonance) and theoretical (structural bioinformatics). • Three main departments, bringing together 13 groups ♣ topics such as cancer, extracellular matrix, tissue engineering, membranes, cell transport and signalling, bioinformatics and structural biology INFSO-RI-508833 GPS@ Bioinformatics Grid Portal, EGEE User Forum, March 1st, 2006, Cern 3 EGEE Biomedical Activity Enabling Grids for E-sciencE • Chair: ♣ Johan Montagnat ♣ Christophe -

Detailed Characterization of Human Induced Pluripotent Stem Cells Manufactured for Therapeutic Applications
Stem Cell Rev and Rep DOI 10.1007/s12015-016-9662-8 Detailed Characterization of Human Induced Pluripotent Stem Cells Manufactured for Therapeutic Applications Behnam Ahmadian Baghbaderani 1 & Adhikarla Syama2 & Renuka Sivapatham3 & Ying Pei4 & Odity Mukherjee2 & Thomas Fellner1 & Xianmin Zeng3,4 & Mahendra S. Rao5,6 # The Author(s) 2016. This article is published with open access at Springerlink.com Abstract We have recently described manufacturing of hu- help determine which set of tests will be most useful in mon- man induced pluripotent stem cells (iPSC) master cell banks itoring the cells and establishing criteria for discarding a line. (MCB) generated by a clinically compliant process using cord blood as a starting material (Baghbaderani et al. in Stem Cell Keywords Induced pluripotent stem cells . Embryonic stem Reports, 5(4), 647–659, 2015). In this manuscript, we de- cells . Manufacturing . cGMP . Consent . Markers scribe the detailed characterization of the two iPSC clones generated using this process, including whole genome se- quencing (WGS), microarray, and comparative genomic hy- Introduction bridization (aCGH) single nucleotide polymorphism (SNP) analysis. We compare their profiles with a proposed calibra- Induced pluripotent stem cells (iPSCs) are akin to embryonic tion material and with a reporter subclone and lines made by a stem cells (ESC) [2] in their developmental potential, but dif- similar process from different donors. We believe that iPSCs fer from ESC in the starting cell used and the requirement of a are likely to be used to make multiple clinical products. We set of proteins to induce pluripotency [3]. Although function- further believe that the lines used as input material will be used ally identical, iPSCs may differ from ESC in subtle ways, at different sites and, given their immortal status, will be used including in their epigenetic profile, exposure to the environ- for many years or even decades. -

Human Induced Pluripotent Stem Cell–Derived Podocytes Mature Into Vascularized Glomeruli Upon Experimental Transplantation
BASIC RESEARCH www.jasn.org Human Induced Pluripotent Stem Cell–Derived Podocytes Mature into Vascularized Glomeruli upon Experimental Transplantation † Sazia Sharmin,* Atsuhiro Taguchi,* Yusuke Kaku,* Yasuhiro Yoshimura,* Tomoko Ohmori,* ‡ † ‡ Tetsushi Sakuma, Masashi Mukoyama, Takashi Yamamoto, Hidetake Kurihara,§ and | Ryuichi Nishinakamura* *Department of Kidney Development, Institute of Molecular Embryology and Genetics, and †Department of Nephrology, Faculty of Life Sciences, Kumamoto University, Kumamoto, Japan; ‡Department of Mathematical and Life Sciences, Graduate School of Science, Hiroshima University, Hiroshima, Japan; §Division of Anatomy, Juntendo University School of Medicine, Tokyo, Japan; and |Japan Science and Technology Agency, CREST, Kumamoto, Japan ABSTRACT Glomerular podocytes express proteins, such as nephrin, that constitute the slit diaphragm, thereby contributing to the filtration process in the kidney. Glomerular development has been analyzed mainly in mice, whereas analysis of human kidney development has been minimal because of limited access to embryonic kidneys. We previously reported the induction of three-dimensional primordial glomeruli from human induced pluripotent stem (iPS) cells. Here, using transcription activator–like effector nuclease-mediated homologous recombination, we generated human iPS cell lines that express green fluorescent protein (GFP) in the NPHS1 locus, which encodes nephrin, and we show that GFP expression facilitated accurate visualization of nephrin-positive podocyte formation in -

Software List for Biology, Bioinformatics and Biostatistics CCT
Software List for biology, bioinformatics and biostatistics v CCT - Delta Software Version Application short read assembler and it works on both small and large (mammalian size) ALLPATHS-LG 52488 genomes provides a fast, flexible C++ API & toolkit for reading, writing, and manipulating BAMtools 2.4.0 BAM files a high level of alignment fidelity and is comparable to other mainstream Barracuda 0.7.107b alignment programs allows one to intersect, merge, count, complement, and shuffle genomic bedtools 2.25.0 intervals from multiple files Bfast 0.7.0a universal DNA sequence aligner tool analysis and comprehension of high-throughput genomic data using the R Bioconductor 3.2 statistical programming BioPython 1.66 tools for biological computation written in Python a fast approach to detecting gene-gene interactions in genome-wide case- Boost 1.54.0 control studies short read aligner geared toward quickly aligning large sets of short DNA Bowtie 1.1.2 sequences to large genomes Bowtie2 2.2.6 Bowtie + fully supports gapped alignment with affine gap penalties BWA 0.7.12 mapping low-divergent sequences against a large reference genome ClustalW 2.1 multiple sequence alignment program to align DNA and protein sequences assembles transcripts, estimates their abundances for differential expression Cufflinks 2.2.1 and regulation in RNA-Seq samples EBSEQ (R) 1.10.0 identifying genes and isoforms differentially expressed EMBOSS 6.5.7 a comprehensive set of sequence analysis programs FASTA 36.3.8b a DNA and protein sequence alignment software package FastQC