Languages in the European Information Society – German –
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

489 INDEX 1 10Kwizard, 194 123People.Com, 126, 135 a AAD, 373
INDEX 1 A (cont.) 10kWizard, 194 Administrative Office of the U.S. 123People.com, 126, 135 Courts, 421, 432 Admissible Evidence, 31, 32, 119 A Internet Archive, 33 Social Networking Sites, 34 Wikipedia, 33 AAD, 373 Adobe, 69 AAJ, 298 Adobe Acrobat, 10, 71, See also ABA. See American Bar Association Adobe Reader, See also PDF ABI, 464 Adobe Reader, 71 Access Downloading, 10 GPO, 372 Toolbar, 72 Access to Archival Databases (AAD) Ads, 37 System, 373 Advanced Search, 69 ACCESSLAW Advertising California State Courts Ethics, 477 Free Case Law Database, 333 Law, 463, 464 Cases Agencies California Federal, 289, 418, 419 Free, 333 Directories, 408, 420 Accounting Forms, 472 TAXSites.com, 480 Statistics, 441 Accurint, 233, 244, 253 Local, 437 Bankruptcy, 196 State, 437 Canadian Phones, 255 Territorial (U.S.), 437 Contact Card Report, 255 Tribal (U.S.), 437 Deep Skip, 255 AGRICOLA Books, 373 Driver’s License Records, 126 AIPLA, 474 Driver’s Licenses, 255 Briefs, 477 E-mail database, 255 Air Force Personnel Foreclosure database, 257 Locator Services, 180 People Alert, 255 People at Work database, 255 Alerts Phones Plus, 255 Accurint, 255 Relavint, 255 Articles, 310 Vehicle Identification Numbers, 255 Blogs, 80 Voter’s Registration, 255 Cases, 304, 310, 327, 346 Address Bar, 6, 14, 35 Complaints, 462 Dockets, 453, 455, 461 Address Search, 233, 235, 245, 251, Dockets (Federal Courts), 453 253, 256, 262 EDGAR, 194 Past, 235 Federal Register, 409 Addresses Free, 80 E-mail, 144, 172, 215, 235 Google Scholar, 304, 310 Unlock, 144 Groups, 80 URL, 6, 26, 29, 117 Legal News, 284 Web Site, 2 Morningstar Document Research, 194 AdLawbyRequest.com, 464 News, 80 Patents, 310 489 A (cont.) A (cont.) Alerts (cont.) American Psychological Association Podcasts, 85 Citation Rules, 488 Scholar, 304, 310 SEC, 194 American Samoa Government U.S. -

Speaker Book
Table of Contents Program 5 Speakers 9 NOAH Infographic 130 Trading Comparables 137 2 3 The NOAH Bible, an up-to-date valuation and industry KPI publication. This is the most comprehensive set of valuation comps you'll find in the industry. Reach out to us if you spot any companies or deals we've missed! March 2018 Edition (PDF) Sign up Here 4 Program 5 COLOSSEUM - Day 1 6 June 2018 SESSION TITLE COMPANY TIME COMPANY SPEAKER POSITION Breakfast 8:00 - 10:00 9:00 - 9:15 Between Tradition and Digitisation: What Old and New Economy can Learn from One Another? NOAH Advisors Marco Rodzynek Founder & CEO K ® AUTO1 Group Gerhard Cromme Chairman Facebook Martin Ott VP, MD Central Europe 9:15 - 9:25 Evaneos Eric La Bonnardière CEO CP 9:25 - 9:35 Kiwi.com Oliver Dlouhý CEO 9:35 - 9:45 HomeToGo Dr. Patrick Andrae Co-Founder & CEO FC MR Insight Venture Partners Harley Miller Vice President CP 9:45 - 9:55 GetYourGuide Johannes Reck Co-Founder & CEO MR Travel & Tourism Travel 9:55 - 10:05 Revolution Precrafted Robbie Antonio CEO FC MR FC 10:05 - 10:15 Axel Springer Dr. Mathias Döpfner CEO 10:15 - 10:40 Uber Dara Khosrowshahi CEO FC hy Christoph Keese CEO CP 10:40 - 10:50 Moovit Nir Erez Founder & CEO 10:50 - 11:00 BlaBlaCar Nicolas Brusson MR Co-Founder & CEO FC 11:00 - 11:10 Taxify Markus Villig MR Founder & CEO 11:10 - 11:20 Porsche Sebastian Wohlrapp VP Digital Business Platform 11:20 - 11:30 Drivy Paulin Dementhon CEO 11:30 - 11:40 Optibus Amos Haggiag Co-Founder & CEO 11:40 - 11:50 Blacklane Dr. -

Statistics for Donauschwaben-Usa.Org (2010-06)
Statistics for donauschwaben-usa.org (2010-06) Statistics for: donauschwaben-usa.org Last Update: 04 Jul 2010 - 10:11 Reported period: Month Jun 2010 When: Monthly history Days of month Days of week Hours Who: Organizations Countries Full list Hosts Full list Last visit Unresolved IP Address Robots/Spiders visitors Full list Last visit Navigation: Visits duration File type Viewed Full list Entry Exit Operating Systems Versions Unknown Browsers Versions Unknown Referrers: Origin Referring search engines Referring sites Search Search Keyphrases Search Keywords Others: Miscellaneous HTTP Status codes Pages not found Summary Reported period Month Jun 2010 First visit 01 Jun 2010 - 00:12 Last visit 30 Jun 2010 - 23:49 Unique visitors Number of visits Pages Hits Bandwidth 3764 4634 12399 84974 6.35 GB Viewed traffic * (1.23 visits/visitor) (2.67 Pages/Visit) (18.33 Hits/Visit) (1437.87 KB/Visit) Not viewed traffic * 18670 22983 2.81 GB * Not viewed traffic includes traffic generated by robots, worms, or replies with special HTTP status codes. Monthly history Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 2010 2010 2010 2010 2010 2010 2010 2010 2010 2010 2010 2010 Month Unique visitors Number of visits Pages Hits Bandwidth Jan 2010 0 0 0 0 0 Feb 2010 0 0 0 0 0 Mar 2010 0 0 0 0 0 Apr 2010 0 0 0 0 0 May 2010 0 0 0 0 0 Jun 2010 3764 4634 12399 84974 6.35 GB Jul 2010 0 0 0 0 0 Aug 2010 0 0 0 0 0 Sep 2010 0 0 0 0 0 Oct 2010 0 0 0 0 0 Nov 2010 0 0 0 0 0 Dec 2010 0 0 0 0 0 Total 3764 4634 12399 84974 6.35 GB Days of month 01 02 03 04 05 06 07 08 09 -
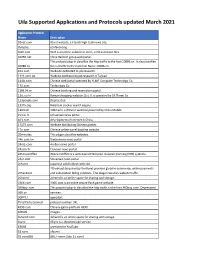
3000 Applications
Uila Supported Applications and Protocols updated March 2021 Application Protocol Name Description 01net.com 05001net plus website, is a Japanese a French embedded high-tech smartphonenews site. application dedicated to audio- 050 plus conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also classifies 10086.cn the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese cloudweb portal storing operated system byof theYLMF 115 Computer website. TechnologyIt is operated Co. by YLMF Computer 115.com Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr ThisKorean protocol shopping plug-in website classifies 11st. the It ishttp operated traffic toby the SK hostPlanet 123people.com. Co. 123people.com Deprecated. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt ChineseLithuanian web news portal portal 163. It is operated by NetEase, a company which pioneered the 163.com development of Internet in China. 17173.com Website distributing Chinese games. 17u.com 20Chinese minutes online is a travelfree, daily booking newspaper website. available in France, Spain and Switzerland. 20minutes This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Checkout (acquired by Verifone) provides global e-commerce, online payments 2Checkout and subscription billing solutions. -

Western Europe Market & Mediafact 2009 Edition
Western Europe Market & MediaFact 2009 Edition Compiled by: Anne Austin, Jonathan Barnard, Nicola Hutcheon Produced by: David Parry © 2010 ZenithOptimedia All rights reserved. This publication is protected by copyright. No part of it may be reproduced, stored in a retrieval system, or transmitted in any form, or by any means, electronic, mechanical, photocopying or otherwise, without written permission from the copyright owners. ISSN 1469-6614 Every effort has been made in the preparation of this book to ensure accuracy of the contents, but the publishers and copyright owners cannot accept liability in respect of errors or omissions. Readers will appreciate that the data is only as up-to-date as printing schedules will allow and is subject to change. ZENITHOPTIMEDIA ZenithOptimedia is one of the world's leading ZenithOptimedia is committed to delivering to global media services agencies with 218 offices clients the best possible return on their in 72 countries. advertising investment. Key clients include AlcatelLucent, Beam Global This approach is supported by a unique system Spirits & Wine, British Airways, Darden for strategy development and implementation, Restaurants, Electrolux, General Mills, Giorgio The ROI Blueprint. At each stage, proprietary Armani Parfums, Kingfisher, Mars, Nestlé, ZOOM (ZenithOptimedia Optimisation of Media) L'Oréal, Puma, Polo Ralph Lauren, Qantas, tools have been designed to add value and Richemont Group, Sanofi-Aventis, Siemens, insight. Thomson Multimedia, Toyota/Lexus, Verizon, Whirlpool and Wyeth. The -
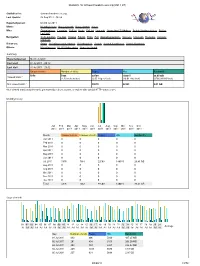
Statistics for Donauschwaben-Usa.Org (2011-07)
Statistics for donauschwaben-usa.org (2011-07) Statistics for: donauschwaben-usa.org Last Update: 03 Aug 2011 - 06:59 Reported period: Month Jul 2011 When: Monthly history Days of month Days of week Hours Who: Organizations Countries Full list Hosts Full list Last visit Unresolved IP Address Robots/Spiders visitors Full list Last visit Navigation: Visits duration File type Viewed Full list Entry Exit Operating Systems Versions Unknown Browsers Versions Unknown Referrers: Origin Referring search engines Referring sites Search Search Keyphrases Search Keywords Others: Miscellaneous HTTP Status codes Pages not found Summary Reported period Month Jul 2011 First visit 01 Jul 2011 - 00:12 Last visit 31 Jul 2011 - 23:52 Unique visitors Number of visits Pages Hits Bandwidth 5676 7363 22509 140015 26.45 GB Viewed traffic * (1.29 visits/visitor) (3.05 Pages/Visit) (19.01 Hits/Visit) (3766.98 KB/Visit) Not viewed traffic * 39670 52483 9.01 GB * Not viewed traffic includes traffic generated by robots, worms, or replies with special HTTP status codes. Monthly history Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 2011 2011 2011 2011 2011 2011 2011 2011 2011 2011 2011 2011 Month Unique visitors Number of visits Pages Hits Bandwidth Jan 2011 0 0 0 0 0 Feb 2011 0 0 0 0 0 Mar 2011 0 0 0 0 0 Apr 2011 0 0 0 0 0 May 2011 0 0 0 0 0 Jun 2011 0 0 0 0 0 Jul 2011 5676 7363 22509 140015 26.45 GB Aug 2011 0 0 0 0 0 Sep 2011 0 0 0 0 0 Oct 2011 0 0 0 0 0 Nov 2011 0 0 0 0 0 Dec 2011 0 0 0 0 0 Total 5676 7363 22509 140015 26.45 GB Days of month 01 02 03 04 05 06 07 -

Copernic Agent Search Results
Copernic Agent Search Results Search: enterprisemission.com (All the words) Found: 1850 result(s) on _Full.Search Date: 7/17/2010 6:06:07 AM 1. The Enterprise Mission Richard Hoagland's breakthrough space website, featuring stories, links, and breaking news stories. ... How Phobos is The Key to a REAL 21st Century Space Program .... ... Preliminary Enterprise Mission Analysis... http://enterprisemission.com 97% 2. Richard C. Hoagland - Wikipedia, the free encyclopedia Hoagland, Richard; Earth Rising over the Moon at enterprisemission.com ... Unless its a Hoax of a Different Color" at enterprisemission.com ... http://en.wikipedia.org/wiki/Richard_C._Hoagland 94% 3. The Enterprise Mission Return to Enterprise Mission Home - Logo Design By VAGraphics. .... [email protected], THE ENTERPRISE MISSION P.O. BOX 22008 ... http://www.bobwelch.com/The%20Enterprise%20Mission.htm 94% 4. Cosmic Preachers | News of Todays Cosmic Preachers Claim to Fame: Norway Spiral and the Denver Airport Murals. Lucas Stat Facts: Website 1: ... mbara2(at)enterprisemission.com. THE ENTERPRISE [...] Read more ... http://1mgp.com/ 93% 5. Enterprisemission.com Site Info enterprisemission.com is one of the top 100,000 sites in the world and is in the Hoagland,_Richard category http://www.alexa.com/siteinfo/enterprisemission.com 93% 6. Paranormal Radio Talk Featuring Richard Hoagland and the ... Contact Richard Hoagland at [email protected]. Visit Richard Hoagland's website Enterprise Mission. [End]. Copyright 2004. http://www.psitalk.com/hoagland.html 93% 7. www.enterprisemission.com/images/IRUpdate/Thumbs.db http://www.enterprisemission.com/images/IRUpdate/Thumbs.db 93% 8. Black helicopters hover over Martian surface 2004/02/02 Letters 1+9 = conspiracy theory http://www.theregister.co.uk/2004/02/02/black_helicopters_hover_over_martian/ 92% 9. -

Analyzer Technology Coverage VERSION 4.4 VERSION All IP Application Protocols Which Can Be Analysed, and Allanalyzed and Gathered Kpis
Analyzer Technology Coverage VERSION 4.4 Lists the details regarding wireless technology interface and protocol support for LTE/UMTS/GSM/Core, all IP Application protocols which can be analysed, and all analyzed and gathered KPIs. PRODUCT NOTE Analyzer Technology Coverage TECHNOLOGY PACKAGE PROTOCOL COVERAGE LTE TECHNOLOGY PACKAGE LTE Uu interface › LTE RRC: 3GPP 36.331 v.10.7.0, v.10.6.0, v.10.3.0, v.9.7.0, v.9.2.0, v.8.7.0 › NAS: 3GPP 24.301 v.10.3.0, v.9.2.0, v.8.3.0 › GSM/3G supplementary services: 3G TS 24.080 v.9.2.0, v.7.3.0, v.6.3.0, v.5.5.0 › LPP: 3GPP 36.355 v.9.6.0 › GSM/3G SMS: 3G TS 24.011 v.10.0.0, TS 23.040 v.7.1.0, v.6.7.0, v.5.6.1, TS 23.038 v.7.0.0, v.6.1.0, v.5.6.0 › LTE MAC: 3GPP TS 36.321 v.8.7.0 › LTE RLC: 3GPP TS 36.322 v.8.7.0 › LTE PDCP: 3GPP TS 36.323 v.9.0.0 S1, X2 interfaces › Ethernet: IETF RFC 826 (11/1982), IEEE 802.1Q-2003, IETF RFC 3032, IETF RFC 3031 (MPLS) › IPv4: IETF RFC 791 (09/1981), RFC 2507 (02/1999) › IPv6: IETF RFC 2460 (12/1998) S102 interface SGs interface › SCTP: IETF RFC 2960 (10/2000), RFC 4960, RFC 5061 › Ethernet: IETF RFC 826 (11/1982), IEEE 802.1Q-2003, › Ethernet: IETF RFC 826 (11/1982), IEEE 802.1Q-2003, (09/2007), RFC 4895, RFC 4820, RFC 3758 IETF RFC 3032, IETF RFC 3031 (MPLS) IETF RFC 3032, IETF RFC 3031 (MPLS) › S1-AP: 3GPP 36.413 v.10.6.0, v.10.2.0, v.9.6.0, v.9.2.2, v.8.7.0 › IPv4: IETF RFC 791 (09/1981), RFC 2507 (02-1999) › IPv4: IETF RFC 791 (09/1981), RFC 2507 (02/1999) › LPPa: 3GPP TS 36.455 v.9.4.1 › IPv6: IETF RFC 2460 (12/1998) › IPv6: IETF RFC 2460 (12/1998) › DoCoMo -
Optimized-Design-Ebook.Pdf
Contents Section One: The Reality Check Chapter 1 Successful Internet Marketing Begins With Goals 2 Chapter 2 A Box for Every Website Visitor 6 Chapter 3 If You Connect With Website Visitors They Will Convert 8 Chapter 4 Have a Seat Mr. Website Owner, It’s Time for a Little Introspection 11 Chapter 5 The Magic Formula of Great SEO 14 Section Two: Check Your Foundation for Cracks Chapter 6 Migrating a Website Owner Through the Five Stages of Grief 18 Chapter 7 SEO Can’t Help a Website That Sucks 21 Chapter 8 Bad Website Architecture: The Silent SEO Killer 24 Chapter 9 Browser-Based Enlightenment 26 Chapter 10 Internet Marketing is a Battlefield 29 Chapter 11 DIY SEO or Professional SEO Consultant? 33 Section Three: Plan Your Initial Attack and Execute Chapter 12 Keyword Research for the Average 36 Chapter 13 Converting Visitors is About Connecting the Website Dots 39 Chapter 14 Should You Ditch Your Website and Developer? 42 Chapter 15 Fifteen Questions to Ask Your Future Website Designer 45 Chapter 16 Each Page of Your Website is Like a Handshake 50 Chapter 17 Web Design Ain’t Over Till the SEO Sings 52 Chapter 18 Stand Back! The Geeks Are Coming 56 Section Four: The Real Work Just Begins Chapter 19 Ten Steps to Quality Link Building and Strong Organic SEO 60 Chapter 20 Twenty Tips for Creating the Perfect Blog Post 64 Chapter 21 A Good Blog Title is Like the Wrapping Paper on a Present 69 Chapter 22 304 Link Building Opportunities 71 Chapter 23 Social Media Isn’t Just a Buzz Word 83 Chapter 24 Become a Master of the Drip Campaign 85 Chapter -

Statistics for Donauschwaben-Usa.Org (2009-10)
Statistics for donauschwaben-usa.org (2009-10) Statistics for: donauschwaben-usa.org Last Update: 01 Nov 2009 - 09:26 Reported period: Month Oct 2009 When: Monthly history Days of month Days of week Hours Who: Organizations Countries Full list Hosts Full list Last visit Unresolved IP Address Robots/Spiders visitors Full list Last visit Navigation: Visits duration File type Viewed Full list Entry Exit Operating Systems Versions Unknown Browsers Versions Unknown Referrers: Origin Referring search engines Referring sites Search Search Keyphrases Search Keywords Others: Miscellaneous HTTP Status codes Pages not found Summary Reported period Month Oct 2009 First visit 01 Oct 2009 - 00:09 Last visit 31 Oct 2009 - 23:23 Unique visitors Number of visits Pages Hits Bandwidth 2271 2992 13485 76055 7.19 GB Viewed traffic * (1.31 visits/visitor) (4.5 Pages/Visit) (25.41 Hits/Visit) (2521.16 KB/Visit) Not viewed traffic * 11531 14059 1.58 GB * Not viewed traffic includes traffic generated by robots, worms, or replies with special HTTP status codes. Monthly history Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 2009 2009 2009 2009 2009 2009 2009 2009 2009 2009 2009 2009 Month Unique visitors Number of visits Pages Hits Bandwidth Jan 2009 0 0 0 0 0 Feb 2009 0 0 0 0 0 Mar 2009 0 0 0 0 0 Apr 2009 0 0 0 0 0 May 2009 0 0 0 0 0 Jun 2009 0 0 0 0 0 Jul 2009 0 0 0 0 0 Aug 2009 0 0 0 0 0 Sep 2009 0 0 0 0 0 Oct 2009 2271 2992 13485 76055 7.19 GB Nov 2009 0 0 0 0 0 Dec 2009 0 0 0 0 0 Total 2271 2992 13485 76055 7.19 GB Days of month 01 02 03 04 05 06 07 08 09 -

Liste Des Catégories Protocolaires
Sécuriser / Optimiser / Analyser l’utilisation d’Internet Guide des protocoles Olfeo ANTIVIRUS Sophos update Protocole de mise à jour de Sophos antivirus. ZoneAlarm Updates Ce plug-in classifie le trafic web destiné aux hôtes 'zonealarm.com' et 'zonelabs.com', ou associé au Common Name SSL 'cm1.zonealarm.com'. SERVICE D'APPLICATIONS Apple App Store L'App Store est une plateforme de téléchargement d'applications distribuée par Apple sur les appareils mobiles fonctionnant sous iOS (iPod Touch, iPhone, ...). Apple Push Notification Service APNS (Apple Push Notification Service) est un service d'Apple pour la réception de notifications pour les applications iOS en provenance de serveurs tiers. Dictionary Server Protocol DICT est un protocole de requêtes/réponses transactionnel permettant à un client d'accéder à des définitions de dictionnaires. End Point Mapper Le protocole End Point Mapper est utilisé par Exchange pour déterminer les ports utilisés par les différents services. Google Play Google Play (aka Android Market) est une bibliothèque d'applications en ligne par Google pour les appareils Android. iCloud iCloud est un service de cloud computing développée par Apple Inc. Il permet de stocker et partager des données, et est accessible depuis un mobile iOS (iPhone, iPad, iPod Touch), ou un Macintosh. ios_ota_update iOS OTA Update est le protocole utilisé pour les mises à jour d'iOS en utilisant OTA (Over The Air). Lighweight Directory Access Le protocole LDAP (Lightweight Directory Access Protocol) est un protocole permettant d'accéder aux informations d'un annuaire. Il est Protocol notamment utilisé dans les environnements Windows pour lancer des requêtes sur Active Directory. -
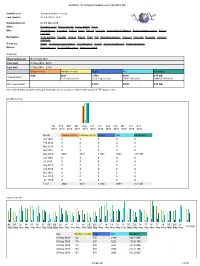
Statistics for Donauschwaben-Usa.Org (2010-05)
Statistics for donauschwaben-usa.org (2010-05) Statistics for: donauschwaben-usa.org Last Update: 01 Jun 2010 - 15:27 Reported period: Month May 2010 When: Monthly history Days of month Days of week Hours Who: Organizations Countries Full list Hosts Full list Last visit Unresolved IP Address Robots/Spiders visitors Full list Last visit Navigation: Visits duration File type Viewed Full list Entry Exit Operating Systems Versions Unknown Browsers Versions Unknown Referrers: Origin Referring search engines Referring sites Search Search Keyphrases Search Keywords Others: Miscellaneous HTTP Status codes Pages not found Summary Reported period Month May 2010 First visit 01 May 2010 - 00:15 Last visit 31 May 2010 - 23:58 Unique visitors Number of visits Pages Hits Bandwidth 3840 4631 14784 93911 8.57 GB Viewed traffic * (1.2 visits/visitor) (3.19 Pages/Visit) (20.27 Hits/Visit) (1940.02 KB/Visit) Not viewed traffic * 24819 30647 3.00 GB * Not viewed traffic includes traffic generated by robots, worms, or replies with special HTTP status codes. Monthly history Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 2010 2010 2010 2010 2010 2010 2010 2010 2010 2010 2010 2010 Month Unique visitors Number of visits Pages Hits Bandwidth Jan 2010 0 0 0 0 0 Feb 2010 0 0 0 0 0 Mar 2010 0 0 0 0 0 Apr 2010 0 0 0 0 0 May 2010 3840 4631 14784 93911 8.57 GB Jun 2010 0 0 0 0 0 Jul 2010 0 0 0 0 0 Aug 2010 0 0 0 0 0 Sep 2010 0 0 0 0 0 Oct 2010 0 0 0 0 0 Nov 2010 0 0 0 0 0 Dec 2010 0 0 0 0 0 Total 3840 4631 14784 93911 8.57 GB Days of month 01 02 03 04 05 06 07 08 09