Understanding the Elements of Operational Reliability a Key for Achieving High Reliability
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Architect's Guide to Site Reliability Engineering Nathaniel T
An Architect's Guide to Site Reliability Engineering Nathaniel T. Schutta @ntschutta ntschutta.io https://content.pivotal.io/ ebooks/thinking-architecturally Sofware development practices evolve. Feature not a bug. It is the agile thing to do! We’ve gone from devs and ops separated by a large wall… To DevOps all the things. We’ve gone from monoliths to service oriented to microserivces. And it isn’t all puppies and rainbows. Shoot. A new role is emerging - the site reliability engineer. Why? What does that mean to our teams? What principles and practices should we adopt? How do we work together? What is SRE? Important to understand the history. Not a new concept but a catchy name! Arguably goes back to the Apollo program. Margaret Hamilton. Crashed a simulator by inadvertently running a prelaunch program. That wipes out the navigation data. Recalculating… Hamilton wanted to add error-checking code to the Apollo system that would prevent this from messing up the systems. But that seemed excessive to her higher- ups. “Everyone said, ‘That would never happen,’” Hamilton remembers. But it did. Right around Christmas 1968. — ROBERT MCMILLAN https://www.wired.com/2015/10/margaret-hamilton-nasa-apollo/ Luckily she did manage to update the documentation. Allowed them to recover the data. Doubt that would have turned into a Hollywood blockbuster… Hope is not a strategy. But it is what rebellions are built on. Failures, uh find a way. Traditionally, systems were run by sys admins. AKA Prod Ops. Or something similar. And that worked OK. For a while. But look around your world today. -

Chapter 6 Structural Reliability
MIL-HDBK-17-3E, Working Draft CHAPTER 6 STRUCTURAL RELIABILITY Page 6.1 INTRODUCTION ....................................................................................................................... 2 6.2 FACTORS AFFECTING STRUCTURAL RELIABILITY............................................................. 2 6.2.1 Static strength.................................................................................................................... 2 6.2.2 Environmental effects ........................................................................................................ 3 6.2.3 Fatigue............................................................................................................................... 3 6.2.4 Damage tolerance ............................................................................................................. 4 6.3 RELIABILITY ENGINEERING ................................................................................................... 4 6.4 RELIABILITY DESIGN CONSIDERATIONS ............................................................................. 5 6.5 RELIABILITY ASSESSMENT AND DESIGN............................................................................. 6 6.5.1 Background........................................................................................................................ 6 6.5.2 Deterministic vs. Probabilistic Design Approach ............................................................... 7 6.5.3 Probabilistic Design Methodology..................................................................................... -

Training-Sre.Pdf
C om p lim e nt s of Training Site Reliability Engineers What Your Organization Needs to Create a Learning Program Jennifer Petoff, JC van Winkel & Preston Yoshioka with Jessie Yang, Jesus Climent Collado & Myk Taylor REPORT Want to know more about SRE? To learn more, visit google.com/sre Training Site Reliability Engineers What Your Organization Needs to Create a Learning Program Jennifer Petoff, JC van Winkel, and Preston Yoshioka, with Jessie Yang, Jesus Climent Collado, and Myk Taylor Beijing Boston Farnham Sebastopol Tokyo Training Site Reliability Engineers by Jennifer Petoff, JC van Winkel, and Preston Yoshioka, with Jessie Yang, Jesus Climent Collado, and Myk Taylor Copyright © 2020 O’Reilly Media. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com). For more infor‐ mation, contact our corporate/institutional sales department: 800-998-9938 or [email protected]. Acquistions Editor: John Devins Proofreader: Charles Roumeliotis Development Editor: Virginia Wilson Interior Designer: David Futato Production Editor: Beth Kelly Cover Designer: Karen Montgomery Copyeditor: Octal Publishing, Inc. Illustrator: Rebecca Demarest November 2019: First Edition Revision History for the First Edition 2019-11-15: First Release See http://oreilly.com/catalog/errata.csp?isbn=9781492076001 for release details. The O’Reilly logo is a registered trademark of O’Reilly Media, Inc. Training Site Reli‐ ability Engineers, the cover image, and related trade dress are trademarks of O’Reilly Media, Inc. -

Reliability: Software Software Vs
Reliability Theory SENG 521 Re lia bility th eory d evel oped apart f rom th e mainstream of probability and statistics, and Software Reliability & was usedid primar ily as a tool to h hlelp Software Quality nineteenth century maritime and life iifiblinsurance companies compute profitable rates Chapter 5: Overview of Software to charge their customers. Even today, the Reliability Engineering terms “failure rate” and “hazard rate” are often used interchangeably. Department of Electrical & Computer Engineering, University of Calgary Probability of survival of merchandize after B.H. Far ([email protected]) 1 http://www. enel.ucalgary . ca/People/far/Lectures/SENG521/ ooene MTTF is R e 0.37 From Engineering Statistics Handbook [email protected] 1 [email protected] 2 Reliability: Natural System Reliability: Hardware Natural system Hardware life life cycle. cycle. Aging effect: Useful life span Life span of a of a hardware natural system is system is limited limited by the by the age (wear maximum out) of the system. reproduction rate of the cells. Figure from Pressman’s book Figure from Pressman’s book [email protected] 3 [email protected] 4 Reliability: Software Software vs. Hardware So ftware life cyc le. Software reliability doesn’t decrease with Software systems time, i.e., software doesn’t wear out. are changed (updated) many Hardware faults are mostly physical faults, times during their e. g., fatigue. life cycle. Each update adds to Software faults are mostly design faults the structural which are harder to measure, model, detect deterioration of the and correct. software system. Figure from Pressman’s book [email protected] 5 [email protected] 6 Software vs. -

Software Reliability and Dependability: a Roadmap Bev Littlewood & Lorenzo Strigini
Software Reliability and Dependability: a Roadmap Bev Littlewood & Lorenzo Strigini Key Research Pointers Shifting the focus from software reliability to user-centred measures of dependability in complete software-based systems. Influencing design practice to facilitate dependability assessment. Propagating awareness of dependability issues and the use of existing, useful methods. Injecting some rigour in the use of process-related evidence for dependability assessment. Better understanding issues of diversity and variation as drivers of dependability. The Authors Bev Littlewood is founder-Director of the Centre for Software Reliability, and Professor of Software Engineering at City University, London. Prof Littlewood has worked for many years on problems associated with the modelling and evaluation of the dependability of software-based systems; he has published many papers in international journals and conference proceedings and has edited several books. Much of this work has been carried out in collaborative projects, including the successful EC-funded projects SHIP, PDCS, PDCS2, DeVa. He has been employed as a consultant to industrial companies in France, Germany, Italy, the USA and the UK. He is a member of the UK Nuclear Safety Advisory Committee, of IFIPWorking Group 10.4 on Dependable Computing and Fault Tolerance, and of the BCS Safety-Critical Systems Task Force. He is on the editorial boards of several international scientific journals. 175 Lorenzo Strigini is Professor of Systems Engineering in the Centre for Software Reliability at City University, London, which he joined in 1995. In 1985-1995 he was a researcher with the Institute for Information Processing of the National Research Council of Italy (IEI-CNR), Pisa, Italy, and spent several periods as a research visitor with the Computer Science Department at the University of California, Los Angeles, and the Bell Communication Research laboratories in Morristown, New Jersey. -

Big Data for Reliability Engineering: Threat and Opportunity
Reliability, February 2016 Big Data for Reliability Engineering: Threat and Opportunity Vitali Volovoi Independent Consultant [email protected] more recently, analytics). It shares with the rest of the fields Abstract - The confluence of several technologies promises under this umbrella the need to abstract away most stormy waters ahead for reliability engineering. News reports domain-specific information, and to use tools that are mainly are full of buzzwords relevant to the future of the field—Big domain-independent1. As a result, it increasingly shares the Data, the Internet of Things, predictive and prescriptive lingua franca of modern systems engineering—probability and analytics—the sexier sisters of reliability engineering, both statistics that are required to balance the otherwise orderly and exciting and threatening. Can we reliability engineers join the deterministic engineering world. party and suddenly become popular (and better paid), or are And yet, reliability engineering does not wear the fancy we at risk of being superseded and driven into obsolescence? clothes of its sisters. There is nothing privileged about it. It is This article argues that“big-picture” thinking, which is at the rarely studied in engineering schools, and it is definitely not core of the concept of the System of Systems, is key for a studied in business schools! Instead, it is perceived as a bright future for reliability engineering. necessary evil (especially if the reliability issues in question are safety-related). The community of reliability engineers Keywords - System of Systems, complex systems, Big Data, consists of engineers from other fields who were mainly Internet of Things, industrial internet, predictive analytics, trained on the job (instead of receiving formal degrees in the prescriptive analytics field). -

Reducing Product Development Risk with Reliability Engineering Methods
Reducing Product Development Risk with Reliability Engineering Methods Mike McCarthy Reliability Specialist Who am I? • Mike McCarthy, Principal Reliability Engineer – BSc Physics, MSc Industrial Engineering – MSaRS (council member), MCMI, – 18+ years as a reliability practitioner – Extensive experience in root cause analysis of product and process issues and their corrective action. • Identifying failure modes, predicting failure rates and cost of ‘unreliability’ – I use reliability tools to gain insight into business issues - ‘Risk’ based decision making 2 Agenda ‘Probable’ Duration 1. Risk 2 min 2. Reliability Tools to Manage Risk 4 min 3. FMECA 6 min 4. Design of Experiments (DoE) 5 min 5. Accelerated Testing 5 min 6. Summary 3 min 7. Questions 5 min Total: 30 min 3 Managing Risk? Design Installation Terry Harris © GreenHunter Bio Fuels Inc. Maintenance Operation Chernobyl 4 Likelihood-Consequence Curve Consequence Catastrophic Prohibited ‘Acceptable’ Negligible Likelihood Impossible Certain (frequency) to occur 5 Reliability Tools to Manage Risk 6 Tools to Manage Risk • Design Reviews • FRACAS/DRACAS Review & • Subcontractor Review Control • Part Selection & Control (including de-rating) • Computer Aided Engineering Tools (FEA/CFD) • FME(C)A / FTA Design & • System Prediction & Allocation (RBDs) • Quality Function Deployment (QFD) Analysis • Critical Item Analysis • Thermal/Vibration Analysis & Management • Predicting Effects of Storage, Handling etc • Life Data Analysis (eg Weibull) • Reliability Qualification Testing Test & • Maintainability -

Site Reliability Engineering HOW GOOGLE RUNS PRODUCTION SYSTEMS
Site Reliability Engineering HOW GOOGLE RUNS PRODUCTION SYSTEMS Edited by Betsy Beyer, Chris Jones, Jennifer Petof & Niall Richard Murphy Praise for Site Reliability Engineering Google’s SREs have done our industry an enormous service by writing up the principles, practices and patterns—architectural and cultural—that enable their teams to combine continuous delivery with world-class reliability at ludicrous scale. You owe it to yourself and your organization to read this book and try out these ideas for yourself. —Jez Humble, coauthor of Continuous Delivery and Lean Enterprise I remember when Google first started speaking at systems administration conferences. It was like hearing a talk at a reptile show by a Gila monster expert. Sure, it was entertaining to hear about a very different world, but in the end the audience would go back to their geckos. Now we live in a changed universe where the operational practices of Google are not so removed from those who work on a smaller scale. All of a sudden, the best practices of SRE that have been honed over the years are now of keen interest to the rest of us. For those of us facing challenges around scale, reliability and operations, this book comes none too soon. —David N. Blank-Edelman, Director, USENIX Board of Directors, and founding co-organizer of SREcon I have been waiting for this book ever since I left Google’s enchanted castle. It is the gospel I am preaching to my peers at work. —Björn Rabenstein, Team Lead of Production Engineering at SoundCloud, Prometheus developer, and Google SRE until 2013 A thorough discussion of Site Reliability Engineering from the company that invented the concept. -

The Evolution of System Reliability Optimization David Coit, Enrico Zio
The evolution of system reliability optimization David Coit, Enrico Zio To cite this version: David Coit, Enrico Zio. The evolution of system reliability optimization. Reliability Engineering and System Safety, Elsevier, 2019, 192, pp.106259. 10.1016/j.ress.2018.09.008. hal-02428529 HAL Id: hal-02428529 https://hal.archives-ouvertes.fr/hal-02428529 Submitted on 8 Apr 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Accepted Manuscript The Evolution of System Reliability Optimization David W. Coit , Enrico Zio PII: S0951-8320(18)30602-1 DOI: https://doi.org/10.1016/j.ress.2018.09.008 Reference: RESS 6259 To appear in: Reliability Engineering and System Safety Received date: 14 May 2018 Revised date: 26 July 2018 Accepted date: 7 September 2018 Please cite this article as: David W. Coit , Enrico Zio , The Evolution of System Reliability Optimization, Reliability Engineering and System Safety (2018), doi: https://doi.org/10.1016/j.ress.2018.09.008 This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. -

Fayssal M. Safie, Ph. D., NASA R&M Tech Fellow Marshall Space Flight Center
Mission Success Starts with Safety Reliability Engineering Applications and Case Studies Fayssal M. Safie, Ph. D., NASA R&M Tech Fellow Marshall Space Flight Center RAM VI Workshop Tutorial Huntsville, Alabama October 15-16, 2013 Agenda • Reliability Engineering Overview – Reliability Engineering Definition – The Reliability Engineering Case – The Relationship to Safety, Mission Success, and Affordability – Design VS. Process Reliability – Reliability Prediction VS. Reliability Demonstration – Uncertainty Analysis VS. Statistical Confidence – Reliability VS. Probabilistic Risk Assessment (PRA) • Applications and Case Studies – Conceptual System Reliability Trade Studies • The ARES V Conceptual Design Case – Development Issues • The Roller Bearing Inner Race Fracture Case – Technical Issues • The High Pressure Fuel Turbo-pump (HPFTP) First Stage Blade – Integrated Failure Analysis • The Columbia Accident • The NASA Engineering Center (NSC) Reliability and Maintainability Engineering Training Program • The Reliability Challenges 2 Background Reliability Engineering Definition • Reliability Engineering is: – The application of engineering and scientific principles to the design and processing of products, both hardware and software, for the purpose of meeting product reliability requirements or goals. – The ability or capability of the product to perform the specified function in the designated environment for a specified length of time or specified number of cycles • Reliability as a Figure of Merit is: The probability that an item will perform its intended function for a specified mission profile. • Reliability is a very broad design-support discipline. It has important interfaces with most engineering disciplines • Reliability analysis is critical for understanding component failure mechanisms and identifying reliability critical design and process drivers. • A comprehensive reliability program is critical for addressing the entire spectrum of design engineering and programmatic concerns to sustainment and system life cycle costs. -

Reliability Performance and Specifications in New Product Development
Reliability Performance and Specifications in New Product Development T. Østeras1, D.N.P. Murthy2 and M. Rausand3 1 Associate Professor of Design Engineering, the Norwegian University of Science and Technology, Trondheim, Norway. 2 Professor of Engineering and Operations Management, The University of Queensland, Australia and Senior scientific Advisor, Norwegian University of Science and Technology, Trondheim, Norway. 3 Professor of Safety and Reliability Engineering, the Norwegian University of Science and Technology, Trondheim, Norway Preface The establishment of a framework for Reliability Performance and Specifications in New Product Development is the objective of a joint research project between University of Queensland and the Norwegian University of Science and Technology. The project is divided into three parts: • Part I: Establish a conceptual framework for determining reliability specifications and assessing reliability performance in new product development. • Part II: Discuss briefly the tools and techniques needed in the above framework. • Part III: Conduct case studies. This report documents the results from Parts I and II of the research project. The conceptual framework presented in Part I provides the basis for Part II of the research project which deals with the tools and techniques needed. Reliability Performance and Specifications in New Product Development T. Østeras1, D.N.P. Murthy2 and M. Rausand3 Part I: A Conceptual Framework 1 Associate Professor of Design Engineering, the Norwegian University of Science and Technology, Trondheim, Norway. 2 Professor of Engineering and Operations Management, The University of Queensland, Australia and Senior Scientific Advisor, Norwegian University of Science and Technology, Trondheim, Norway. 3 Professor of Safety and Reliability Engineering, the Norwegian University of Science and Technology, Trondheim, Norway. -
Reliability-Engg.Pdf
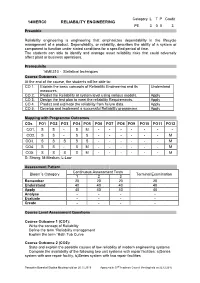
Category L T P Credit 14MERC0 RELIABILITY ENGINEERING PE 3 0 0 3 Preamble Reliability engineering is engineering that emphasizes dependability in the lifecycle management of a product. Dependability, or reliability, describes the ability of a system or component to function under stated conditions for a specified period of time. The students can able to identify and manage asset reliability risks that could adversely affect plant or business operations. Prerequisite 14ME310 - Statistical techniques Course Outcomes At the end of the course, the students will be able to: CO 1. Explain the basic concepts of Reliability Engineering and its Understand measures. CO 2. Predict the Reliability at system level using various models. Apply CO 3. Design the test plan to meet the reliability Requirements. Apply CO 4. Predict and estimate the reliability from failure data. Apply CO 5. Develop and implement a successful Reliability programme. Apply Mapping with Programme Outcomes COs PO1 PO2 PO3 PO4 PO5 PO6 PO7 PO8 PO9 PO10 PO11 PO12 CO1. S S - S M - - - - - - - CO2. S S - S S - - - - - - M CO3. S S S S S - - - - - - M CO4. S S - S M - - - - - - M CO5. S S S S M - - - - - - M S- Strong; M-Medium; L-Low Assessment Pattern Continuous Assessment Tests Bloom‟s Category Terminal Examination 1 2 3 Remember 20 20 20 20 Understand 40 40 40 40 Apply 40 40 40 40 Analyse - - - - Evaluate - - - - Create - - - - Course Level Assessment Questions Course Outcome 1 (CO1): Write the concept of Reliability Define the term “Reliability management Explain the term “Bath Tub Curve Course Outcome 2 (CO2): State and explain the possible causes of low reliability of modern engineering systems Compare the availability of the following two unit systems with repair facilities: a)Series system with one repair facility, b)Series system with two repair facilities Passed in Board of Studies Meeting held on 26.11.2016 Approved in 53rd Academic Council Meeting held on 22.12.2016 B.E.