On-Line Measurement of Broken Rice Percentage from Image Analysis of Length and Shape
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Specifications Guide Global Rice Latest Update: February 2021
Specifications Guide Global Rice Latest update: February 2021 Definitions of the trading locations for which Platts publishes indexes or assessments 2 Asia 5 Europe, the Middle East and Africa 12 Americas 14 Revision history 18 www.spglobal.com/platts Specifications Guide Global Rice: February 2021 DEFINITIONS OF THE TRADING LOCATIONS FOR WHICH PLATTS PUBLISHES INDEXES OR ASSESSMENTS All the assessments listed here employ Platts Assessments Methodology, as published at https://www.spglobal.com/platts/plattscontent/_assets/_files/en/our-methodology/methodology- specifications/platts-assessments-methodology-guide.pdf. These guides are designed to give Platts subscribers as much information as possible about a wide range of methodology and specification questions. This guide is current at the time of publication. Platts may issue further updates and enhancements to this guide and will announce these to subscribers through its usual publications of record. Such updates will be included in the next version of this guide. Platts editorial staff and managers are available to provide guidance when assessment issues require clarification. The assessments listed in this guide reflect the prevailing market value of the specified product at the following times daily: Asia – 11:30 GMT / BST EMEA – 13:30 GMT / BST Americas – 23:59 GMT /BST on the day prior to publication Platts may take into account price information that varies from the specifications below. Where appropriate, contracts, offers and bids which vary from these specifications, will be normalized to the standards stated in this guide. All other terms when not in contradiction with the below as per London Rice Brokers’ Association Standard Contract Terms (September 1997), amended 1 November, 2008. -

Rice: Bioactive Compounds and Their Health Benefits
The Pharma Innovation Journal 2021; 10(5): 845-853 ISSN (E): 2277- 7695 ISSN (P): 2349-8242 NAAS Rating: 5.23 Rice: Bioactive compounds and their health benefits TPI 2021; 10(5): 845-853 © 2021 TPI www.thepharmajournal.com Arsha RS, Prasad Rasane and Jyoti Singh Received: 22-03-2021 Accepted: 24-04-2021 Abstract Arsha RS Rice is the primary source of calories in many developing countries, and about 60% of the world's Department of Food Technology population consumes rice as a staple food. Rice has high nutritional value such as carbohydrate, fat, fibre, and Nutrition, School of protein, vitamins as well as food energy, minerals profile and fatty acids. The processing steps of rice is Agriculture, Lovely Professional cleaning, parboiling, drying, dehusking, partial milling, grading, packing and storage. The pigmented rice University, Phagwara, Punjab, varieties are available with reddish, purple or even blackish colour. Various extraction methods are used India for extraction bioactive compounds from rice including traditional methods (like Soxhlet extraction Prasad Rasane method and maceration method) to modern methods ( like accelerated solvent extraction method (ASE), Department of Food Technology solid-phase extraction (SPE), pressurized liquid extraction (PLE), pressurized fluid extraction (PFE), and Nutrition, School of subcritical water extraction (SWE), subcritical fluid extraction (SFE), microwave-assisted extraction Agriculture, Lovely Professional (MAE), vortex-assisted extraction (VAE), ultrasound-assisted extraction (UAE)) -

Properties and Structures of Flours and Starches from Whole, Broken, and Yellowed Rice Kernels in a Model Study
Properties and Structures of Flours and Starches from Whole, Broken, and Yellowed Rice Kernels in a Model Study Ya-Jane Wang,1,2 Linfeng Wang,1 Donya Shephard,1 Fudong Wang,1 and James Patindol1 ABSTRACT Cereal Chem. 79(3):383–386 The objective of this study was to compare the structure and properties perature and enthalpy compared with flours from the whole or the broken of flours and starches from whole, broken, and yellowed rice kernels that rice kernels. However, all starches showed similar pasting, gelling, thermal were broken or discolored in the laboratory. Physicochemical properties properties, and X-ray diffraction patterns, and no structural differences including pasting, gelling, thermal properties, and X-ray diffraction patterns could be detected among different starches by HPSEC and HPAEC-PAD. were determined. Structure was elucidated using high-performance size- α-Amylase may be responsible for the decreased amylopectin fraction, exclusion chromatography (HPSEC) and high-performance anion-exchange decreased apparent amylose content, and increased amounts of low molecular chromatography with pulsed amperometric detection (HPAEC-PAD). The weight saccharides in the yellowed rice flour. The increased amount of yellowed rice kernels contained a slightly higher protein content and reducing sugars from starch hydrolysis promoted the interaction between produced a significantly lower starch yield than did the whole or broken starch and protein. The alkaline-soluble fraction during starch isolation is rice kernels. Flour from the yellowed rice kernels had a significantly presumed to contribute to the difference in pasting, gelling, and thermal higher pasting temperature, higher Brabender viscosities, increased damaged properties among whole, broken, and yellowed rice flours. -

Grain Quality of Australian Wild Rice (Compared to Domesticated Rice)
Grain quality of Australian wild rice (compared to domesticated rice) Tiparat Tikapunya MSc of Food Science and Technology A thesis submitted for the degree of Doctor of Philosophy at The University of Queensland in 2017 Queensland Alliance for Agriculture and Food Innovation Abstract Wild rice may be an important resource for rice food security. Studies of the grain quality of wild rices may facilitate their use in rice breeding. Australian wild rice populations have been shown to be genetically distinct from those found elsewhere indicating that they may be a potential source of valuable alleles for rice improvement. To date, two taxa belonging to the A genome clade have been described in Australia: wild rice taxa A (Oryza rufipogon like) and wild rice taxa B (Oryza meridionalis like). To explore the grain quality of these wild rices from their natural environment, a collection from eleven sites within 300 kms north of Cairns, Queensland, Australia at the beginning of the dry season in May 2014 and 2015 was evaluated. Analysis of the physical traits of three Australian wild rice taxa revealed that the wild A genome taxa were of a size that could be classified as extra-long paddy rice with grains that were long or medium while Oryza australiensis was categorized as a long paddy rice with short grain. Australian wild rice grains were coloured and varied from light red brown to dark brown while domesticated rice is brighter. Due to the difficulty of obtaining sufficient mature wild rice seeds as well as the colour of the wild rice, further analysis of grain quality was conducted on unpolished wild rice. -

A City-Retail Outlet Inventory of Processed Dairy and Grain Foods: Evidence from Mali
A city-retail outlet inventory of processed dairy and grain foods: Evidence from Mali Veronique Theriault, Amidou Assima, Ryan Vroegindewey, and Naman Keita AAEA, July 31, 2017 Motivation • Urban consumers are shifting away from traditional staples and moving toward processed rice and wheat-based products (Hollinger and Staatz 2015). • Income increases are associated with growth in foods with high- income elasticities of demand (Zhou and Staatz 2016). • Processed foods can play a central role in diet transformation (Tschirley et al. 2015) and retailing modernization (Reardon et al. 2015). Objectives • Examine the general trends in terms of diversity, availability, and prevalence of imports of processed grain and dairy products. Couscous Rice • Analyze key characteristics of processed grain and dairy products, including branding, packaging, labeling, primary ingredients, and pricing. Sterilized milk Sweetened condensed milk Processed food product • “a retail item derived from a covered commodity that has undergone specific processing resulting in a change in the character of the covered commodity, or that has been combined with at least one other covered commodity or other substantive food component” (USDA 2017; 7 CFR § 65.220). Methods • Cities • Bamako, Sikasso, Kayes, and Segou • Neighborhoods Using tablets for data collection • Low, medium, and high-income • Retail outlets Product information • Grocery stores, traditional shops, neighborhood markets, central markets, and supermarkets. Retail outlet General trends Processed dairy and grain products Diversity of products • 4,000 processed dairy and cereal food items observed in 100 retail outlets. • A total of 36 and 15 different processed cereal and dairy product types = high repetition of products across retail outlets. • Coexistence of modernity with tradition, but traditional products account for very few observations. -

FICHE 23 White Broken Rice
SPECIFICATION SHEET REF. 23 v14 FI 32 - 8 WHITE BROKEN RICE RICE CULTIVATED IN CAMARGUE – ORIGIN FRANCE Product available in : - Organic Culture (ECOCERT Certification) - Reasoned Culture ORYZA SATIVA Rice issued from non GMO seeds Reference : 23 The 12/11/13 CHARACTERISTICS BEFORE COOKING Length = 1 to 6 mm CLASSIFICATION : Width = 1 to 1.5 mm COLOUR : White Typical rice without additive or any other ODOUR : flavour ASPECT : Fluid COOKING 8 Minutes cooking, +/ - 1 min TIME : for 2 persons : 125 g uncooked rice in 1 l salty boiling water WATER 246 g of cooked rice for 100 g uncooked : ABSORPTION rice CHARACTERISTICS AFTER COOKING COLOUR : Shiny white ODOUR : White rice odour TASTE : Light Cream taste ASPECT : Open breaks, squat TEXTURE : Homogeneous, pasty, creamy. NUTRITION CLAIMS (Regulation EC 41/2009 and Regulation EC 1924/2006) - Gluten free - Very low sodium p. 1/3 Siège administratif : Mas du grand Mollégès – Route de Port Saint Louis – 13200 ARLES - FRANCE Tél : 33-0490963647 Fax : 33-0490930707 E-mail : [email protected] SPECIFICATION SHEET REF. 23 v14 FI 32 - 8 NUTRITION AND ENERGY PROPERTIES average in 100 g uncooked rice 357 kcal PROTEIN : 6.0 g sodium : 2.2 mg ENERGY : 1493 kJ FIBER : 0.6 g selenium : 7.5 µg FAT TOTAL : 0.4 g ASHES : 0.3 g vitamin E : 0.04 mg saturated : 0.1 g magnesium : 26 mg thiamin : 0.04 mg mono - : 0.15 g phosphorus : 76 mg riboflavin : 0.01 mg unsaturated poly unsaturated : 0.15 g potassium : 72 mg niacin : 0.13 mg CARBOHYDRATE : 80.2 g calcium : 11 mg pantothenic ac : 0.45 mg starch : 80.0 g iron : 0.4 mg Pyridoxin : 0.03 mg sugar : 0.2 g zinc : 1.8 mg folate : 1.3 µg MICROBIOLOGICAL PROPERTIES by g of uncooked rice TOTAL PLATE COUNT : ≤ 1 000 000 YEASTS : ≤ 10 000 COLIFORMS : ≤ 50 000 MOULDS : ≤ 10 000 CLOSTRIDIUM PERFRINGENS : ≤ 10 ESCHERICHIA COLI : ≤ 100 STAPHYLOCOCCUS AUREUS : ≤ 10 BACILLUS CEREUS : ≤ 100 LISTERIA MONOCYTOGENES : free in 25 g SALMONELLA SPP. -

ITS Impex Ltd. Switzerland 7000 CHUR
ITS Impex Ltd. Switzerland ITS GROUPE 7000 CHUR Tel: ++41 81 356 70 14, Fax: ++41 81 356 70 15 E-Mail: [email protected] Product list & Specification for Export Market 1. VIETNAM RICE CODE Product Spezifikation Picture FOB PRICE Name VTE-LW- LONG White Long Grain Rice 5% broken 1001.1305 GRAIN Broken: 5.0% max Moisture: 14% max Damaged kernels: 1% max Yellow kernels: 0.5% max Foreign matters: 0.1% max Paddy kernels: 15 seeds/KG max Chalky kernels: 8.0% max Immature kernels: 0.2% max Glutinous rice: 1% max Red kernels: 2% max Milling degree: Well milled and polished VET-LW- LONG White Long Grain Rice 10% broken 1001.1310 GRAIN Broken: 10.0% max Moisture: 14% max Damaged kernels: 1.25% max Yellow kernels: 1.0% max Foreign matters: 0.2% max Paddy kernels: 20 seeds/KG max Chalky kernels: 8.0% max Immature kernels: 0.2% max Red kernels: 2% max Milling degree: Well milled and polished VET-LW- LONG White Long Grain Rice 15% broken 1001.1315 GRAIN Broken: 15.0% max Moisture: 14% max Damaged kernels: 1.50% max Yellow kernels: 1.25% max Foreign matters: 0.2% max ITS Impex Ltd. Switzerland ITS GROUPE 7000 CHUR Tel: ++41 81 356 70 14, Fax: ++41 81 356 70 15 E-Mail: [email protected] Product list & Specification for Export Market Paddy kernels: 25 seeds/KG max Chalky kernels: 8.0% max Immature kernels: 0.3% max Red kernels: 2% max Milling degree: Well milled and polished VET-LW-25 LONG White Long Grain Rice 25% broken GRAIN Broken: 25.0% max Moisture: 14.5% max Damaged kernels: 2.0% max Yellow kernels: 1.50% max Foreign matters: 0.5% max Paddy kernels: 30 seeds/KG max Chalky kernels: 8.0% max Immature kernels: 1.50% max Red kernels: 3.5% max Milling degree: Well milled and polished VET-LG 100 LONG White rice 100% Broken GRAIN VET-SW-5 SHORT Moisture: max. -

Degruyter Revac Revac-2021-0137 272..292 ++
Reviews in Analytical Chemistry 2021; 40: 272–292 Review Article Vinita Ramtekey*, Susmita Cherukuri, Kaushalkumar Gunvantray Modha, Ashutosh Kumar*, Udaya Bhaskar Kethineni, Govind Pal, Arvind Nath Singh, and Sanjay Kumar Extraction, characterization, quantification, and application of volatile aromatic compounds from Asian rice cultivars https://doi.org/10.1515/revac-2021-0137 crop and deposits during seed maturation. So far, litera- received December 31, 2020; accepted May 30, 2021 ture has been focused on reporting about aromatic com- Abstract: Rice is the main staple food after wheat for pounds in rice but its extraction, characterization, and fi more than half of the world’s population in Asia. Apart quanti cation using analytical techniques are limited. from carbohydrate source, rice is gaining significant Hence, in the present review, extraction, characterization, - interest in terms of functional foods owing to the presence and application of aromatic compound have been eluci of aromatic compounds that impart health benefits by dated. These VACs can give a new way to food processing fl - lowering glycemic index and rich availability of dietary and beverage industry as bio avor and bioaroma com fibers. The demand for aromatic rice especially basmati pounds that enhance value addition of beverages, food, - rice is expanding in local and global markets as aroma is and fermented products such as gluten free rice breads. considered as the best quality and desirable trait among Furthermore, owing to their nutritional values these VACs fi consumers. There are more than 500 volatile aromatic com- can be used in bioforti cation that ultimately addresses the pounds (VACs) vouched for excellent aroma and flavor in food nutrition security. -

RICE WEEKLY February 26, 2021
RICE WEEKLY February 26, 2021 PLATTS WEEKLY RICE ASSESSMENTS ($/mt) Price Change Price Change Price Change Thailand - Long Grain White Rice Myanmar - Long Grain Parboiled Rice US - Gulf Long Grain Rice 100% Grade B LRAAC00 529.00 +7.00 Parboiled Milled 5% STX (FOB FCL) LRHDB00 530.00 0.00 US #2, 4% Broken, Hard Milled LRIAH00 630.00 0.00 5% Broken LRABB00 519.00 +7.00 (FOB Lake Charles) 10% Broken LRACA00 518.00 +7.00 India - Long Grain White Rice US #2, 4% Broken, Hard Milled LRIBH00 525.00 0.00 15% Broken LRADD00 515.00 +7.00 5% Broken LRCAB00 415.00 +10.00 (FOB Bulk NOLA) 25% Broken LRAEE00 502.00 +5.00 25% Broken LRCBE00 385.00 +5.00 US #3, 15% Broken, Hard Milled LRICD00 515.00 0.00 A1 Super 100% Broken LRAFC00 460.00 0.00 100% Broken LRCCC00 285.00 +10.00 US #5, 20% Broken, Hard Milled LRIDF00 525.00 0.00 Swarna 5% Broken LRCDB00 390.00 0.00 US #1, Parboiled Milled 4% Broken LRIEH00 570.00 +5.00 Thailand - Long Grain Parboiled Rice Sharbati 2% Broken (FOB FCL) LRCEG00 623.00 -8.00 US #2, Paddy, 55/70 Yield LRIFI00 315.00 +3.00 Parboiled Milled 100% STX LRAGC00 524.00 +10.00 Southern Flour Quality Broken (Ex-works) LRIGI00 457.00 0.00 India - Long Grain Parboiled Rice Parboiled Milled 100% LRAHC00 514.00 +10.00 Southern Pet Food Quality Broken LRIHI00 425.00 0.00 Parboiled Milled 5% STX LRAIB00 519.00 +10.00 Parboiled Milled 5% STX LRCFG00 385.00 0.00 (Ex-works) Parboiled Milled 5% LRAJB00 509.00 +10.00 India - Basmati Rice US - Californian Medium Grain Rice Thailand - Long Grain Fragrant Rice Traditional White Basmati 2% (FOB FCL) -

Analysis of Paddy Grain and Rice Quality in Madagascar
TECHNICAL GUIDE ANALYSIS OF PADDY GRAIN AND RICE QUALITY IN MADAGASCAR TECHNICAL GUIDE ANALYSIS OF PADDY GRAIN AND RICE QUALITY IN MADAGASCAR 2 TECHNICAL GUIDE ANALYSIS OF PADDY GRAIN AND RICE QUALITY IN MADAGASCAR CENTRE DE FORMATION ET D’APPLICATION DU MACHINISME AGRICOLE (CFAMA), ANTSIRABE 2012 3 ANALYSIS OF PADDY GRAIN AND RICE QUALITY IN MADAGASCAR EPPENDIX : FINAL REPORT, ON PROJECT FOR PRODUCTIVITY IMPROVEMENT IN CENTRAL HIGHLAND IN THE REPUBLIC OF MADAGASCAR Mr. SUISMONO, Expert from the Republic of Indonesia (Third Country Expert /TCE Post-Harvest Technologies, August 2012 - February 2013) Papriz - Japan International Cooperation Agency (JICA) 4 I. INTRODUCTION Rice quality affects consumer preferences and the price of rice. Understanding the quality of rice is rice physico-chemical characteristics that affect the price of rice. Therefore, to determine the price of rice should be made Rice quality standard with the quality criteria that determine the price of rice. Characteristics of rice that determine the price of rice become rice quality criteria such as level of dryness (moisture content), clean (percentage of foreign materials), the appearance of intact rice (percentage of head rice, broken rice, minutes kernel, green and chalkyness grain), the condition is not damage rice (percentage of yellow / damage grain), the color of white rice (polished degree, the percentage of red grains) and contains no paddy grain. Quality rice different as rice quality manipulation. Factors affecting the quality (varieties, agro-ecosystems, cultivation techniques, post-harvest handling and processing, equipment, human resources and social culture. Madagascar does not have: (a) National Standard Madagascar (SNM) for the paddy grain and rice quality. -
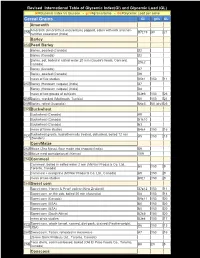
Cereal Grains GI Gr/S GL Amaranth
Revised International Table of Glycemic Index(GI) and Glycemic Load (GL) GI=Glycemic Index Vs Glucose - gr/s=grams/serve - GL=Glycemic Load per serve Cereal Grains GI gr/s GL Amaranth Amaranth (Amaranthus esculentum) popped, eaten with milk and non- 255 97±19 30 21 nutritive sweetener (India) Barley 256 Pearl Barley Barley, pearled (Canada) 22 Barley (Canada) 22 Barley, pot, boiled in salted water 20 min (Gouda's foods, Concord, 25±2 Canada) Barley (Canada) 27 Barley, pearled (Canada) 29 mean of five studies 25±1 150 11 257 Barley (Hordeum vulgare) (India) 37 Barley (Hordeum vulgare) (India) 48 mean of two groups of subjects 43±6 150 26 258 Barley, cracked (Malthouth, Tunisia) 50 150 21 259 Barley, rolled (Australia) 66±5 50 (dry) 25 260 Buckwheat Buckwheat (Canada) 49 Buckwheat (Canada) 51±10 Buckwheat (Canada) 63 mean of three studies 54±4 150 16 Buckwheat groats, hydrothermally treated, dehusked, boiled 12 min 261 45 150 13 (Sweden) Corn/Maize 262 Maize (Zea Mays), flour made into chapatti (India) 59 263 Maize meal porridge/gruel (Kenya) 109 264 Cornmeal Cornmeal, boiled in salted water 2 min (McNair Products Co. Ltd., 68 150 9 Toronto, Canada) Cornmeal + margarine (McNair Products Co. Ltd., Canada) 69 150 9 mean of two studies 69±1 150 9 265 Sweet corn Sweet corn, 'Honey & Pearl' variety (New Zealand) 37±12 150 11 Sweet corn, on the cob, boiled 20 min (Australia) 48 150 14 Sweet corn (Canada) 59±11 150 20 Sweet corn (USA) 60 150 20 Sweet corn (USA) 60 150 20 Sweet corn (South Africa) 62±5 150 20 mean of six studies 53±4 150 17 Sweet -

Part I: What Is Rice – History & Production
PART I: WHAT IS RICE – HISTORY & PRODUCTION OBJECTIVES After completing this section students will be able to: • Outline the history of rice’s diffusion throughout the world • Understand the evolution of the U.S. rice industry and the states that currently produce rice • Understand and define the components of a rice kernel • Describe traditional and modern methods for cultivating and harvesting rice • Describe major steps in the milling process • Differentiate between the different forms of rice and explain how these forms correspond to the steps of the milling process LESSON PLAN Topic Suggested Activity Suggested Time What is Rice? Lecture/Discussion 5 min U.S. Rice History Lecture/Discussion 5 min Demonstration to trace the 10 min worldwide spread of rice, arrival in America and the U.S. rice industry Rice Production Lecture/Discussion 15 min Cultivation Class Activity: Draw a flowchart tracing the 10 min Milling different processing steps WHAT IS RICE? Rice is the seed of a semi-aquatic grass ( Oryza sativa ) that is cultivated extensively in warm climates in many countries, including the United States, for its edible grain. RICE AND THE It is a staple food throughout the world. ENVIRONMENT Rice growing is eco-friendly and has a positive impact on the Is Wild Rice a Variety of Rice? environment. Rice fields create Wild rice is an aquatic grass species native to North America. Although it is called “rice,” it is not actually related to the rice species Oryza sativa , and is therefore a wetland habitat for many not technically rice. species of birds, mammals and In the U.S., wild rice is grown primarily in Minnesota and California.