Contemporary Issues of Open Data in Information Systems Research: Considerations and Recommendations Georg J.P
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
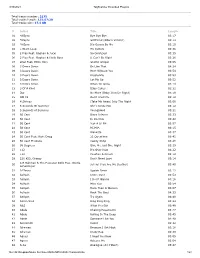
3/30/2021 Tagscanner Extended Playlist File:///E:/Dropbox/Music For
3/30/2021 TagScanner Extended PlayList Total tracks number: 2175 Total tracks length: 132:57:20 Total tracks size: 17.4 GB # Artist Title Length 01 *NSync Bye Bye Bye 03:17 02 *NSync Girlfriend (Album Version) 04:13 03 *NSync It's Gonna Be Me 03:10 04 1 Giant Leap My Culture 03:36 05 2 Play Feat. Raghav & Jucxi So Confused 03:35 06 2 Play Feat. Raghav & Naila Boss It Can't Be Right 03:26 07 2Pac Feat. Elton John Ghetto Gospel 03:55 08 3 Doors Down Be Like That 04:24 09 3 Doors Down Here Without You 03:54 10 3 Doors Down Kryptonite 03:53 11 3 Doors Down Let Me Go 03:52 12 3 Doors Down When Im Gone 04:13 13 3 Of A Kind Baby Cakes 02:32 14 3lw No More (Baby I'ma Do Right) 04:19 15 3OH!3 Don't Trust Me 03:12 16 4 Strings (Take Me Away) Into The Night 03:08 17 5 Seconds Of Summer She's Kinda Hot 03:12 18 5 Seconds of Summer Youngblood 03:21 19 50 Cent Disco Inferno 03:33 20 50 Cent In Da Club 03:42 21 50 Cent Just A Lil Bit 03:57 22 50 Cent P.I.M.P. 04:15 23 50 Cent Wanksta 03:37 24 50 Cent Feat. Nate Dogg 21 Questions 03:41 25 50 Cent Ft Olivia Candy Shop 03:26 26 98 Degrees Give Me Just One Night 03:29 27 112 It's Over Now 04:22 28 112 Peaches & Cream 03:12 29 220 KID, Gracey Don’t Need Love 03:14 A R Rahman & The Pussycat Dolls Feat. -

What Do Healthcare Providers Think of Patients Who Use the Internet?: an Exploratory Study Matt Iw Llis
University of New Mexico UNM Digital Repository Communication ETDs Electronic Theses and Dissertations 12-1-2009 What do healthcare providers think of patients who use the Internet?: An exploratory study Matt iW llis Follow this and additional works at: https://digitalrepository.unm.edu/cj_etds Recommended Citation Willis, Matt. "What do healthcare providers think of patients who use the Internet?: An exploratory study." (2009). https://digitalrepository.unm.edu/cj_etds/90 This Thesis is brought to you for free and open access by the Electronic Theses and Dissertations at UNM Digital Repository. It has been accepted for inclusion in Communication ETDs by an authorized administrator of UNM Digital Repository. For more information, please contact [email protected]. Matthew A. Willis t andidate Communication and Journalism "Depanmenr This thesis is approved, and it is acceptable in quality and form for publication: Approved by the Thesis Committee: Chairperson _—,amia I L,wt-- ` .,_.1)4 ki46 V IL -e A-- G 0 i WHAT DO HEALTHCARE PROVIDERS THINK OF PATIENTS WHO USE THE INTERNET?: AN EXPLORATORY STUDY BY MATT WILLIS BACHELOR OF ARTS THESIS Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Arts Communication The University of New Mexico Albuquerque, New Mexico December, 2009 ii DEDICATION Carol Willis, Howard Willis, Jennifer McMahon, & Nancy Wilson Thank you for your support and encouragement. Without it this research would not be possible. iii ACKNOWLEDGEMENTS I would like to acknowledge the wonderful mentors I am fortunate enough to have in my life. I heartily thank each of you for your support, encouragement, wisdom, patience, and guidance. -

Rita Ora She Is Believed to Be Keen on Rekindling Speaking to Her a Lot and Making Plans to Singer Likes to Indulge in Her Favourite Tipple Every Day
lifestyle SUNDAY, MARCH 15, 2015 Gossip McBusted have turned into ‘divas’ after touring with One Direction he six-piece supergroup - who joined the ‘Night their Most Excellent Adventure tour, where they will play Changes’ hitmakers on the Australian leg of their 21 dates across the UK, and feel as though they can now TOn The Road Again tour - has admitted they have relax more backstage after requesting items which “set started to demand more luxurious goods on their rider the mood”. Dougie told the Daily Mirror newspaper: “We since seeing what the boy band had asked for on theirs. didn’t realise you could ask for that stuff. “It kills the vibe Tom Fletcher said: “We’ve been more diva-ish on this when you are in a big dressing room and it’s just white, tour. It’s the first time in 12 years we’ve asked for our with bright lights, whereas if you have the music on, can- dressing room to be a certain way. We saw 1D’s and dles and lowlights it sets the mood.” thought ‘We want that.” Harry Judd added: “It’s worth it. Our dressing room is epic this tour. There’s dark drapes up the wall, a couple of plants and a coffee machine.” The band - which includes Tom, Harry, Danny Jones, Dougie Poynter, Matt Willis and James Bourne - have just started Kelly Clarkson thinks she is ‘too Nadine Leopold split from Harry old’ to get drunk he 32-year-old singer - who has eight-month-old because of ‘more commitment’ daughter River with husband Brandon Blackstock Tand is stepmother to his kids Savannah, 13, and he ‘Victoria’s Secret’ model and the ings for Harry and the fact that Nadine eight-year-old Seth - admits she gets intoxicated quickly One Direction singer have reportedly broke up with him kind of gives her pleas- but tries not to do so very frequently any more. -
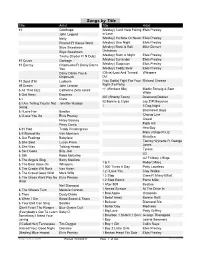
Songs by Title
Songs by Title Title Artist Title Artist #1 Goldfrapp (Medley) Can't Help Falling Elvis Presley John Legend In Love Nelly (Medley) It's Now Or Never Elvis Presley Pharrell Ft Kanye West (Medley) One Night Elvis Presley Skye Sweetnam (Medley) Rock & Roll Mike Denver Skye Sweetnam Christmas Tinchy Stryder Ft N Dubz (Medley) Such A Night Elvis Presley #1 Crush Garbage (Medley) Surrender Elvis Presley #1 Enemy Chipmunks Ft Daisy Dares (Medley) Suspicion Elvis Presley You (Medley) Teddy Bear Elvis Presley Daisy Dares You & (Olivia) Lost And Turned Whispers Chipmunk Out #1 Spot (TH) Ludacris (You Gotta) Fight For Your Richard Cheese #9 Dream John Lennon Right (To Party) & All That Jazz Catherine Zeta Jones +1 (Workout Mix) Martin Solveig & Sam White & Get Away Esquires 007 (Shanty Town) Desmond Dekker & I Ciara 03 Bonnie & Clyde Jay Z Ft Beyonce & I Am Telling You Im Not Jennifer Hudson Going 1 3 Dog Night & I Love Her Beatles Backstreet Boys & I Love You So Elvis Presley Chorus Line Hirley Bassey Creed Perry Como Faith Hill & If I Had Teddy Pendergrass HearSay & It Stoned Me Van Morrison Mary J Blige Ft U2 & Our Feelings Babyface Metallica & She Said Lucas Prata Tammy Wynette Ft George Jones & She Was Talking Heads Tyrese & So It Goes Billy Joel U2 & Still Reba McEntire U2 Ft Mary J Blige & The Angels Sing Barry Manilow 1 & 1 Robert Miles & The Beat Goes On Whispers 1 000 Times A Day Patty Loveless & The Cradle Will Rock Van Halen 1 2 I Love You Clay Walker & The Crowd Goes Wild Mark Wills 1 2 Step Ciara Ft Missy Elliott & The Grass Wont Pay -

Song Pack Listing
TRACK LISTING BY TITLE Packs 1-86 Kwizoke Karaoke listings available - tel: 01204 387410 - Title Artist Number "F" You` Lily Allen 66260 'S Wonderful Diana Krall 65083 0 Interest` Jason Mraz 13920 1 2 Step Ciara Ft Missy Elliot. 63899 1000 Miles From Nowhere` Dwight Yoakam 65663 1234 Plain White T's 66239 15 Step Radiohead 65473 18 Til I Die` Bryan Adams 64013 19 Something` Mark Willis 14327 1973` James Blunt 65436 1985` Bowling For Soup 14226 20 Flight Rock Various Artists 66108 21 Guns Green Day 66148 2468 Motorway Tom Robinson 65710 25 Minutes` Michael Learns To Rock 66643 4 In The Morning` Gwen Stefani 65429 455 Rocket Kathy Mattea 66292 4Ever` The Veronicas 64132 5 Colours In Her Hair` Mcfly 13868 505 Arctic Monkeys 65336 7 Things` Miley Cirus [Hannah Montana] 65965 96 Quite Bitter Beings` Cky [Camp Kill Yourself] 13724 A Beautiful Lie` 30 Seconds To Mars 65535 A Bell Will Ring Oasis 64043 A Better Place To Be` Harry Chapin 12417 A Big Hunk O' Love Elvis Presley 2551 A Boy From Nowhere` Tom Jones 12737 A Boy Named Sue Johnny Cash 4633 A Certain Smile Johnny Mathis 6401 A Daisy A Day Judd Strunk 65794 A Day In The Life Beatles 1882 A Design For Life` Manic Street Preachers 4493 A Different Beat` Boyzone 4867 A Different Corner George Michael 2326 A Drop In The Ocean Ron Pope 65655 A Fairytale Of New York` Pogues & Kirsty Mccoll 5860 A Favor House Coheed And Cambria 64258 A Foggy Day In London Town Michael Buble 63921 A Fool Such As I Elvis Presley 1053 A Gentleman's Excuse Me Fish 2838 A Girl Like You Edwyn Collins 2349 A Girl Like -

AA-Postscript.Qxp:Layout 1
36 TUESDAY, MARCH 25, 2014 LIFESTYLE Gossip Jay Z addresses Drake’s art reference criticisms ay Z has hit out at Drake in a new track. The Roc Nation boss addressed the ‘Hypher’ hitmaker during his verse Jon Jay Electronica’s new song, ‘We Made It’, after the rapper called him “corny” for using art references in his music. Jay Z raps: “Sorry Mrs Drizzy for so much art talk/ Silly me, rappin’ ‘bout that I really bought/ While these rappers rap about guns that they ain’t shot/ And a bunch of other silly thing that they ain’t got.” The reference comes after Drake’s controversial interview with Rolling Stone magazine in February, during which he criticized Jay Z and slated Kanye West’s “questionable” rap lyrics on his ‘Yeezus’ album. He said: “It’s like Hov can’t drop bars these days without at least four art references. I would love to collect [art] at some point, but I think the whole Rap/art world thing is getting kind of corny.” Speaking about ‘Yeezus’, Drake added: “There were some real ques- tionable bars on there.” Itr isn’t the first time Drake has criticized the two rappers, as he admitted he wasn’t on good terms with the stars when he slated Jay Z and Kanye West’s collaborative album ‘Watch The Throne’ on his 2011 track ‘I’m One One’. He admitted: “It was a lack of communication paired with natural competitiveness. But those two are Gods to me.” Liam Gallagher’s ex to write new book iam Gallagher is “very nervous” about former lover Lisa LMoorish’s autobiography. -

Transforming Lives
TRANSFORMING LIVES 2018 -19 ANNUAL REPORT President’s Note Annual Report Dear Friends of Trinity, Rose Hulman Institute of Technology, St. Louis University Madrid, Tulane Dedication Each freshman class begins University, United State Air Force This annual report their Trinity journey with the Academy, United States Naval is dedicated to Academic Convocation, a special Academy, University of Michigan, Jim Connell ’63 and unique annual tradition University of Notre Dame, and which celebrates each student’s Vanderbilt University. Together, A member of the Trinity commitment to giving the they set a school record for most Class of 1963, the late maximum effort of his soul into college merit scholarship dollars ever Jim Connell left a huge his academic pursuits at Trinity. received at $44 million. footprint during his time at Trinity High Over their four years, it’s amazing While excelling in the classroom, School. His quiet dignity ’77 to see our students transform these seniors were also generous left a permanent impact from young boys into men of to charitable causes, performed on thousands of young faith and men of character. After thousands of hours of community artists at Trinity, and his all, that is what we do at Trinity. service, excelled in academic reach extended to the What’s even more amazing is to and athletic competitions, and broader community, as witness our Trinity family working participated in religious offerings like he planted seeds that daily to transform lives inside and the voluntary senior retreat. Keep would flourish for many Thompson Painting by: Jeff outside of our school through in mind, all of this is happening alumni who went on to service and leadership. -

English Song Booklet
English Song Booklet SONG NUMBER SONG TITLE SINGER SONG NUMBER SONG TITLE SINGER 100002 1 & 1 BEYONCE 100003 10 SECONDS JAZMINE SULLIVAN 100007 18 INCHES LAUREN ALAINA 100008 19 AND CRAZY BOMSHEL 100012 2 IN THE MORNING 100013 2 REASONS TREY SONGZ,TI 100014 2 UNLIMITED NO LIMIT 100015 2012 IT AIN'T THE END JAY SEAN,NICKI MINAJ 100017 2012PRADA ENGLISH DJ 100018 21 GUNS GREEN DAY 100019 21 QUESTIONS 5 CENT 100021 21ST CENTURY BREAKDOWN GREEN DAY 100022 21ST CENTURY GIRL WILLOW SMITH 100023 22 (ORIGINAL) TAYLOR SWIFT 100027 25 MINUTES 100028 2PAC CALIFORNIA LOVE 100030 3 WAY LADY GAGA 100031 365 DAYS ZZ WARD 100033 3AM MATCHBOX 2 100035 4 MINUTES MADONNA,JUSTIN TIMBERLAKE 100034 4 MINUTES(LIVE) MADONNA 100036 4 MY TOWN LIL WAYNE,DRAKE 100037 40 DAYS BLESSTHEFALL 100038 455 ROCKET KATHY MATTEA 100039 4EVER THE VERONICAS 100040 4H55 (REMIX) LYNDA TRANG DAI 100043 4TH OF JULY KELIS 100042 4TH OF JULY BRIAN MCKNIGHT 100041 4TH OF JULY FIREWORKS KELIS 100044 5 O'CLOCK T PAIN 100046 50 WAYS TO SAY GOODBYE TRAIN 100045 50 WAYS TO SAY GOODBYE TRAIN 100047 6 FOOT 7 FOOT LIL WAYNE 100048 7 DAYS CRAIG DAVID 100049 7 THINGS MILEY CYRUS 100050 9 PIECE RICK ROSS,LIL WAYNE 100051 93 MILLION MILES JASON MRAZ 100052 A BABY CHANGES EVERYTHING FAITH HILL 100053 A BEAUTIFUL LIE 3 SECONDS TO MARS 100054 A DIFFERENT CORNER GEORGE MICHAEL 100055 A DIFFERENT SIDE OF ME ALLSTAR WEEKEND 100056 A FACE LIKE THAT PET SHOP BOYS 100057 A HOLLY JOLLY CHRISTMAS LADY ANTEBELLUM 500164 A KIND OF HUSH HERMAN'S HERMITS 500165 A KISS IS A TERRIBLE THING (TO WASTE) MEAT LOAF 500166 A KISS TO BUILD A DREAM ON LOUIS ARMSTRONG 100058 A KISS WITH A FIST FLORENCE 100059 A LIGHT THAT NEVER COMES LINKIN PARK 500167 A LITTLE BIT LONGER JONAS BROTHERS 500168 A LITTLE BIT ME, A LITTLE BIT YOU THE MONKEES 500170 A LITTLE BIT MORE DR. -

Emma Willis on FIGHTING IMPOSTER SYNDROME and HER NEW PLAN B
AU G U S T 2 01 8 Emma Willis ON FIGHTING IMPOSTER SYNDROME AND HER NEW PLAN B 5 SEX TIPS By Caitlin Moran RED AUGUST 2018 £4.50 FORTHEBESTTHINGSINLIFE125 SUNSHINE STYLE BUYS Sailor stripes Beach dresses Cat’s eye shades COASTAL Basket bags DECOR IDEAS Espadrilles CHIC PICNICS BATHROOM TRENDS www.redonline.co.uk LIFE CHANGING TRAVEL STORIES (ANDHOWTO 08 DOITSOLO- 9 771461 131183 ORWITHKIDS) WWW.REDONLINE.CO.UK Red woman JUMPER, £355, ZADIG & VOLTAIRE. BIKINI BOTTOMS, £25, BEIJA LONDON. NECKLACE, £19; NECKLACE, £85, BOTH ESTELLA BARTLETT.EARRINGS; RINGS; BRACELET,ALL EMMA’S OWN. OPPOSITE PAGE: JUMPER, £89, MARKS & SPENCER. JEANS, £485, ALTUZARRA Photography DAVID GUBERT Styling NICOLA ROSE Red woman lood and guts and bodies The Brit Awards alongside her Sunday radio show with are what I like,’ says Emma Stephen Mulhern for Heart FM. People connect with her, ‘ Willis, plunging her teeth into whether she’s bouncing with excitement outside the Big a posh chicken burger. ‘It’s Brother House or making a new mum her first round of what I thought I would do. tea and toast, she seems genuine in whatever she does. Both my parents worked in I got a taste of this myself on our cover shoot in hospitals and I grew up in an Portugal. Emma arrived to discover rain had been forecast environment where you did for the following shoot day. As her entourage started to jobs like that.’ She pauses for arrange themselves on to sunloungers by the pool, I a moment, then adds, ‘And tentatively suggested we try to squeeze the six-hour cover Bthen I found myself being a shoot into whatever sunshine we had left that afternoon model, which was a bit weird.’ instead. -

Dan Blaze's Karaoke Song List
Dan Blaze's Karaoke Song List - By Artist 112 Peaches And Cream 411 Dumb 411 On My Knees 411 Teardrops 911 A Little Bit More 911 All I Want Is You 911 How Do You Want Me To Love You 911 More Than A Woman 911 Party People (Friday Night) 911 Private Number 911 The Journey 10 cc Donna 10 cc I'm Mandy 10 cc I'm Not In Love 10 cc The Things We Do For Love 10 cc Wall St Shuffle 10 cc Dreadlock Holiday 10000 Maniacs These Are The Days 1910 Fruitgum Co Simon Says 1999 Man United Squad Lift It High 2 Evisa Oh La La La 2 Pac California Love 2 Pac & Elton John Ghetto Gospel 2 Unlimited No Limits 2 Unlimited No Limits 20 Fingers Short Dick Man 21st Century Girls 21st Century Girls 3 Doors Down Kryptonite 3 Oh 3 feat Katy Perry Starstrukk 3 Oh 3 Feat Kesha My First Kiss 3 S L Take It Easy 30 Seconds To Mars The Kill 38 Special Hold On Loosely 3t Anything 3t With Michael Jackson Why 4 Non Blondes What's Up 4 Non Blondes What's Up 5 Seconds Of Summer Don't Stop 5 Seconds Of Summer Good Girls 5 Seconds Of Summer She Looks So Perfect 5 Star Rain Or Shine Updated 08.04.2015 www.blazediscos.com - www.facebook.com/djdanblaze Dan Blaze's Karaoke Song List - By Artist 50 Cent 21 Questions 50 Cent Candy Shop 50 Cent In Da Club 50 Cent Just A Lil Bit 50 Cent Feat Neyo Baby By Me 50 Cent Featt Justin Timberlake & Timbaland Ayo Technology 5ive & Queen We Will Rock You 5th Dimension Aquarius Let The Sunshine 5th Dimension Stoned Soul Picnic 5th Dimension Up Up and Away 5th Dimension Wedding Bell Blues 98 Degrees Because Of You 98 Degrees I Do 98 Degrees The Hardest -

Equity: a Guide for Local Health Departments” Is a Product of the Public Health Institute Center for Climate Change and Health
Climate Change, Health, and A Guide For Local Equity: Health Departments Authors Contributors Linda Rudolph, MD, MPH Heather Kuiper, PhD, MPH Catherine Harrison, RN, MPH Zachariah Baker, JD Laura Buckley, MPH Neil Maizlish, PhD, MPH Savannah North, MPH Elsie Moore, MPH Acknowledgements “Climate Change, Health, and Equity: A Guide for Local Health Departments” is a product of the Public Health Institute Center for Climate Change and Health. “Climate Change, Health, and Equity: A Guide for Local Health Departments” was developed under Agreement #16-11001 with the California Department of Public Health Office of Health Equity and with funding from the American Public Health Association. Additional support was provided by The Kresge Foundation. This guide was designed by Amy Weiher at Weiher Creative, Inc. and was edited by Ann Greenberger at Greenline Editing. The authors wish to give special appreciation to the local health departments that have worked to integrate climate change into their work, and shared their experiences with the authors. Their work has inspired us to help others become more engaged in this urgent and critical issue. A special thanks to our reviewers: Charles Benjamin Beard, MS, PhD Chelsea Gridley-Smith, PhD Olubukolami Musa, MPH Centers for Disease Control and Prevention National Association of City and County American Public Health Association Health Officials Andrew Deckert, MD, MPH Kate Robb, MSPH Public Health Officer, Shasta County Linda Helland, MPH American Public Health Association California Department of Public -

Mcfly Awarded Honorary Nickelodeon Kids' Choice
MCFLY AWARDED HONORARY NICKELODEON KIDS’ CHOICE AWARD - POP GROUP McFLY RECEIVE AWARD FROM TEENAGE MUTANT NINJA TURTLES IN SURPRISE VISIT TO BE AIRED DURING NICKELODEON’S KIDS’ CHOICE AWARDS ON SUNDAY 30TH MARCH - London, 13th March 2014 –McFly are to be the first-ever group to receive an honorary Nickelodeon Kids’ Choice Award for Favourite UK Band of the Decade. In a surprise visit during rehearsals for the McBusted tour, Tom Fletcher, Dougie Poynter and Harry Judd were awarded the iconic orange blimp on behalf of the band by their childhood heroes, Nickelodeon’s Teenage Mutant Ninja Turtles and Busted’s Matt Willis and James Bourne. Fans will be able to see footage of the amazing surprise during the award ceremony which airs on Sunday 30th March from 5:00pm. The inaugural award was created especially for the band, who was the UK host of the award show in 2007. It recognises the band’s outstanding 10 years in the music industry entertaining a generation of kids. “Back in 2007 we were the UK hosts of Nickelodeon's Kids' Choice Awards handing out the blimps rather than receiving them," said McFly’s Tom Fletcher. "McFly's ten years have been insanely awesome and having the Teenage Mutant Ninja Turtles award us Favourite Band of the Decade has to be one of the highlights. Cowabunga dudes!” It was announced this week that Top 10 iTunes selling artist Aloe Blacc and new band American Authors will take the stage and perform at the epic award show, taking place at the Galen Centre in Los Angeles.