Prediction of Water in Asteroids from Spectral Data Shortward of 3 Ȑm
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Minor Planet Bulletin 44 (2017) 142
THE MINOR PLANET BULLETIN OF THE MINOR PLANETS SECTION OF THE BULLETIN ASSOCIATION OF LUNAR AND PLANETARY OBSERVERS VOLUME 44, NUMBER 2, A.D. 2017 APRIL-JUNE 87. 319 LEONA AND 341 CALIFORNIA – Lightcurves from all sessions are then composited with no TWO VERY SLOWLY ROTATING ASTEROIDS adjustment of instrumental magnitudes. A search should be made for possible tumbling behavior. This is revealed whenever Frederick Pilcher successive rotational cycles show significant variation, and Organ Mesa Observatory (G50) quantified with simultaneous 2 period software. In addition, it is 4438 Organ Mesa Loop useful to obtain a small number of all-night sessions for each Las Cruces, NM 88011 USA object near opposition to look for possible small amplitude short [email protected] period variations. Lorenzo Franco Observations to obtain the data used in this paper were made at the Balzaretto Observatory (A81) Organ Mesa Observatory with a 0.35-meter Meade LX200 GPS Rome, ITALY Schmidt-Cassegrain (SCT) and SBIG STL-1001E CCD. Exposures were 60 seconds, unguided, with a clear filter. All Petr Pravec measurements were calibrated from CMC15 r’ values to Cousins Astronomical Institute R magnitudes for solar colored field stars. Photometric Academy of Sciences of the Czech Republic measurement is with MPO Canopus software. To reduce the Fricova 1, CZ-25165 number of points on the lightcurves and make them easier to read, Ondrejov, CZECH REPUBLIC data points on all lightcurves constructed with MPO Canopus software have been binned in sets of 3 with a maximum time (Received: 2016 Dec 20) difference of 5 minutes between points in each bin. -
Meteorite Wis91600: a New Sample Related to a D- Or T-Type Asteroid
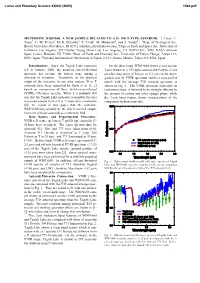
Lunar and Planetary Science XXXVI (2005) 1564.pdf METEORITE WIS91600: A NEW SAMPLE RELATED TO A D- OR T-TYPE ASTEROID. T. Hiroi1, E. Tonui2, C. M. Pieters1, M. E. Zolensky3, Y. Ueda4, M. Miyamoto4, and S. Sasaki4,5, 1Dept. of Geological Sci., Brown University, Providence, RI 02912 ([email protected]), 2Dept. of Earth and Space Sci., University of California Los Angeles, 595 Charles Young Drive East, Los Angeles, CA 90095-1567, 3SN2, NASA Johnson Space Center, Houston, TX 77058, 4Dept. of Earth and Planetary Sci., University of Tokyo, Hongo, Tokyo 113- 0033, Japan, 5National Astronomical Observatory of Japan, 2-21-1 Osawa, Mitaka, Tokyo 181-8588, Japan. Introduction: Since the Tagish Lake meteorite On the other hand, WIS91600 shows a very similar fell in January 2000, the assumed one-of-the-kind 3-µm feature to a T/D-type asteroid 308 Polyxo, if one meteorite has become the hottest issue among a peculiar data point of Polyxo at 3.5 µm can be disre- diversity of scientists. Meanwhile, as the physical garded and its VNIR spectrum shows a near-perfect origin of the meteorite in our solar system, D or T match with the average T/D asteroid spectrum as asteroids have been suggested by Hiroi et al. [1, 2] shown in Fig. 1. The VNIR spectrum, especially its based on comparison of their visible-near-infrared continuum slope, is believed to be strongly affected by (VNIR) reflectance spectra. While it is probably still the amount of carbon and other opaque phase, while true that the Tagish Lake meteorite is possibly the first the 3-µm band feature shows characteristics of the recovered sample from a D or T asteroid as a meteorite component hydrous minerals. -

Uhm Ms 3980 R.Pdf
UNIVERSITY OF HAWAI'I LIBRARY The Enigmatic Surface of(3200) Phaethon: Comparison with cometary candidates A THESIS SUBMITTED TO THE GRADUATE DIVISION OF THE UNIVERSITY OF HAWAI'I IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF SCIENCE IN ASTRONOMY August 2005 By Luke R. Dundon Thesis Committee: K. Meech, Chairperson S. Bus D. Tholen To my parents, David and Colleen Dundon. III Acknowledgments lowe much gratitude to my advisor, Karen Meech, as well as the other members of my thesis committee, Dave Tholen and Bobby Bus. Karen, among many other things, trained me in the art of data reduction and good observing technique, as well as successful writing of telescope proposals. Bobby helped me perform productive near-IR spectral observation and subsequent data reduction. Dave provided keen analytical insight throughout the entire process of my project. With the tremendous guidance, expertise and advice of my committee, I was able to complete this project. They were always willing to aid me through my most difficult dilemmas. This work would not have been possible without their help. Thanks is also due to numerous people at the !fA who have helped me through my project in various ways. Dave Jewitt was always available to offer practical scientific advice, as well as numerous data reduction strategies. Van Fernandez allowed me to use a few of his numerous IDL programs for lightcurve analysis and spectral reduction. His advice was also quite insightful and helped focus my own thought processes. Jana Pittichova guided me through the initial stages of learning how to observe, which was crucial for my successful observations of (3200) Phaethon in the Fall of 2004. -

The Relationship Between Centaurs and Jupiter Family Comets with Implications for K-Pg-Type Impacts K
1 The Relationship between Centaurs and Jupiter Family Comets with Implications for K-Pg-type Impacts K. R. Grazier1*†, J. Horner2, J. C. Castillo-Rogez3 1United States Military Academy, West Point, NY, United States 2Centre for Astrophysics, University of Southern Queensland, Toowoomba, Queensland 4350, Australia 3Jet Propulsion Laboratory, California Institute of Technology, Pasadena, CA, United States. *Corresponding Author. E-mail: [email protected] †Now at NASA/Marshall Space Flight Center, Huntsville, AL, United States Centaurs—icy bodies orbiting beyond Jupiter and interior to Neptune—are believed to be dynamically related to Jupiter Family Comets (JFCs), which have aphelia near Jupiter’s orbit, and perihelia in the inner Solar System. Previous dynamical simulations have recreated the Centaur/JFC conversion, but the mechanism behind that process remains poorly described. We have performed a numerical simulation of Centaur analogues that recreates this process, generating a dataset detailing over 2.6 million close planet/planetesimal interactions. We explore scenarios stored within that database and, from those, describe the mechanism by which Centaur objects are converted into JFCs. Because many JFCs have perihelia in the terrestrial planet region, and since Centaurs are constantly resupplied from the Scattered Disk and other reservoirs, the JFCs are an ever-present impact threat. Keywords: dynamical evolution and stability, celestial mechanics, comets, asteroids 1. Introduction Over the past decade, a number of studies have brought into question the long-held belief that Jupiter acts to shield the Earth from comet impacts. The work of Wetherill (1994, 1995), who studied the influence of the giant planets in clearing debris from the outer Solar System, is often heralded as the source of the “Jupiter: the Shield” paradigm, and was one of the core tenets of the Rare Earth hypothesis of Ward & Brownlee (2000) who popularized the notion. -

Disk-Resolved Optical Spectra of Near-Earth Asteroid 25143 Itokawa with Hayabusa/AMICA Observations
발표논문 초록 (태양계) [구SS-01] Disk-Resolved Optical Spectra of Near-Earth Asteroid 25143 Itokawa with Hayabusa/AMICA observations Masateru Ishiguro Seoul National University The Hayabusa mission successfully rendezvoused with its target asteroid 25143 Itokawa in 2005 and brought the asteroidal sample to the Earth in 2009. This mission enabled to connect the S-type asteroids to ordinary chondrites, the counterpart meteorites which exist in near Earth orbit. Recent finding of a fragment from 25143 Itokawa [1] suggested that the asteroid experienced an impact after the injection to the near-Earth orbit. In this presentation, we investigated the evidence of the recent impact on 25143 Itokawa using the onboard camera, AMICA. AMICA took more than 1400 images of Itokawa during the rendezvous phase. It is reported that AMICA images are highly contaminated by lights scattered inside the optics in the longer wavelength. We developed a technique to subtract the scattered light by determining the point spread functions for all available channels. As the result, we first succeeded in the determination of the surface spectra in all available bands. We consider a most fresh-looking compact crater, Kamoi, is a possible impact site. [1] Ohtsuka, K., Publications of the Astronomical Society of Japan, 63, 6, L73-L77 [구SS-02] Dynamical Evolution of the Dark Asteroids with Tisserand parameter 김윤영1, Masateru Ishiguro2, 정진훈2, 양홍규2, Fumihiko Usui3 1 이화여자대학교 물리학과, 2서울대학교 물리천문학부, 3우주과학연구소 (일본) It has been speculated that there could be dormant or extinct comets in the list of known asteroids, which appear asteroidal but are icy bodies originating from outer solar system. -

Orbital Shapes of Asteroids in Cometary Orbits Based on 0.7M Telescope Imaging
Orbital Shapes of Asteroids in Cometary Orbits based on 0.7m Telescope Imaging 1,2,3 2,3 S Dueantakhu , S Wannawichian 1 Graduate School, Chiang Mai University, Chiang Mai, Thailand 2 Department of physics and Materials Science, Faculty of Science, Chiang Mai University, Chiang Mai, Thailand 3 National Astronomical Research Institute of Thailand(NARIT), Chiang Mai, Thailand E-mail: [email protected] Abstract. The study of orbital elements of Asteroids in Cometary Orbits (ACOs) is based on images taken by a 0.7-m telescope to find positions of asteroids and calculate their orbital elements. This work focuses on variation of positions and orbital shape of an asteroid, 1667Pels, which is obtained by analyzing orbital elements and minimum orbital intersection distances. Each observation, those parameters are affected by the gravity from Jupiter on ACOs. The accuracy of single site data was calibrated by comparing the result from this work to other observations in Minor Planet Center database. 1. Introduction Asteroids are members of minor planet group. Some of their movements are affected by giant planets, especially Jupiter, which make orbits of asteroids highly variable. The three-body problem is the major case for discussion about position of planet and its satellite. For asteroid, it is a special case that is called restricted three-body problem [3] because it has infinitesimal mass and moves in the gravitational field of the sun and giant planets. Solution of restricted three-body problem is [3] " " " "(()*) "* � = � + � + + − � (1) , , - . Where � is the speed of the infinitesimal mass. � and � are position of the mass. �(and �" are positioning vectors of the mass, � is mass of secondary body and 1 − � is mass of primary body � is Jacobi's integral parameter, � is a planet and 1 − � is the Sun. -
Appendix 1 1311 Discoverers in Alphabetical Order
Appendix 1 1311 Discoverers in Alphabetical Order Abe, H. 28 (8) 1993-1999 Bernstein, G. 1 1998 Abe, M. 1 (1) 1994 Bettelheim, E. 1 (1) 2000 Abraham, M. 3 (3) 1999 Bickel, W. 443 1995-2010 Aikman, G. C. L. 4 1994-1998 Biggs, J. 1 2001 Akiyama, M. 16 (10) 1989-1999 Bigourdan, G. 1 1894 Albitskij, V. A. 10 1923-1925 Billings, G. W. 6 1999 Aldering, G. 4 1982 Binzel, R. P. 3 1987-1990 Alikoski, H. 13 1938-1953 Birkle, K. 8 (8) 1989-1993 Allen, E. J. 1 2004 Birtwhistle, P. 56 2003-2009 Allen, L. 2 2004 Blasco, M. 5 (1) 1996-2000 Alu, J. 24 (13) 1987-1993 Block, A. 1 2000 Amburgey, L. L. 2 1997-2000 Boattini, A. 237 (224) 1977-2006 Andrews, A. D. 1 1965 Boehnhardt, H. 1 (1) 1993 Antal, M. 17 1971-1988 Boeker, A. 1 (1) 2002 Antolini, P. 4 (3) 1994-1996 Boeuf, M. 12 1998-2000 Antonini, P. 35 1997-1999 Boffin, H. M. J. 10 (2) 1999-2001 Aoki, M. 2 1996-1997 Bohrmann, A. 9 1936-1938 Apitzsch, R. 43 2004-2009 Boles, T. 1 2002 Arai, M. 45 (45) 1988-1991 Bonomi, R. 1 (1) 1995 Araki, H. 2 (2) 1994 Borgman, D. 1 (1) 2004 Arend, S. 51 1929-1961 B¨orngen, F. 535 (231) 1961-1995 Armstrong, C. 1 (1) 1997 Borrelly, A. 19 1866-1894 Armstrong, M. 2 (1) 1997-1998 Bourban, G. 1 (1) 2005 Asami, A. 7 1997-1999 Bourgeois, P. 1 1929 Asher, D. -

ABSTRACT Title of Dissertation: WATER in the EARLY SOLAR
ABSTRACT Title of Dissertation: WATER IN THE EARLY SOLAR SYSTEM: INFRARED STUDIES OF AQUEOUSLY ALTERED AND MINIMALLY PROCESSED ASTEROIDS Margaret M. McAdam, Doctor of Philosophy, 2017. Dissertation directed by: Professor Jessica M. Sunshine, Department of Astronomy This thesis investigates connections between low albedo asteroids and carbonaceous chondrite meteorites using spectroscopy. Meteorites and asteroids preserve information about the early solar system including accretion processes and parent body processes active on asteroids at these early times. One process of interest is aqueous alteration. This is the chemical reaction between coaccreted water and silicates producing hydrated minerals. Some carbonaceous chondrites have experienced extensive interactions with water through this process. Since these meteorites and their parent bodies formed close to the beginning of the Solar System, these asteroids and meteorites may provide clues to the distribution, abundance and timing of water in the Solar nebula at these times. Chapter 2 of this thesis investigates the relationships between extensively aqueously altered meteorites and their visible, near and mid-infrared spectral features in a coordinated spectral-mineralogical study. Aqueous alteration is a parent body process where initially accreted anhydrous minerals are converted into hydrated minerals in the presence of coaccreted water. Using samples of meteorites with known bulk properties, it is possible to directly connect changes in mineralogy caused by aqueous alteration with spectral features. Spectral features in the mid-infrared are found to change continuously with increasing amount of hydrated minerals or degree of alteration. Building on this result, the degrees of alteration of asteroids are estimated in a survey of new asteroid data obtained from SOFIA and IRTF as well as archived the Spitzer Space Telescope data. -

(2000) Forging Asteroid-Meteorite Relationships Through Reflectance
Forging Asteroid-Meteorite Relationships through Reflectance Spectroscopy by Thomas H. Burbine Jr. B.S. Physics Rensselaer Polytechnic Institute, 1988 M.S. Geology and Planetary Science University of Pittsburgh, 1991 SUBMITTED TO THE DEPARTMENT OF EARTH, ATMOSPHERIC, AND PLANETARY SCIENCES IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN PLANETARY SCIENCES AT THE MASSACHUSETTS INSTITUTE OF TECHNOLOGY FEBRUARY 2000 © 2000 Massachusetts Institute of Technology. All rights reserved. Signature of Author: Department of Earth, Atmospheric, and Planetary Sciences December 30, 1999 Certified by: Richard P. Binzel Professor of Earth, Atmospheric, and Planetary Sciences Thesis Supervisor Accepted by: Ronald G. Prinn MASSACHUSES INSTMUTE Professor of Earth, Atmospheric, and Planetary Sciences Department Head JA N 0 1 2000 ARCHIVES LIBRARIES I 3 Forging Asteroid-Meteorite Relationships through Reflectance Spectroscopy by Thomas H. Burbine Jr. Submitted to the Department of Earth, Atmospheric, and Planetary Sciences on December 30, 1999 in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy in Planetary Sciences ABSTRACT Near-infrared spectra (-0.90 to ~1.65 microns) were obtained for 196 main-belt and near-Earth asteroids to determine plausible meteorite parent bodies. These spectra, when coupled with previously obtained visible data, allow for a better determination of asteroid mineralogies. Over half of the observed objects have estimated diameters less than 20 k-m. Many important results were obtained concerning the compositional structure of the asteroid belt. A number of small objects near asteroid 4 Vesta were found to have near-infrared spectra similar to the eucrite and howardite meteorites, which are believed to be derived from Vesta. -

42. the MOTION of HIDALGO and the MASS of SATURN Unusual Though the Orbits of Many of the Minor Planets May Be, None Is So Anoma
42. THE MOTION OF HIDALGO AND THE MASS OF SATURN B. G. MARSDEN Smithsonian Astrophysical Observatory, Cambridge, Mass., U.S.A. Abstract. The principal features of the motion of Hidalgo over the interval 1400-2900 are described. The possibility that this object is an extinct (or nearly extinct) comet nucleus is discussed. A determination of the mass of Saturn, using observations of Hidalgo during 1920-1964, is presented and compared with other recent determinations. Unusual though the orbits of many of the minor planets may be, none is so anomalous in so many different ways as that of 944 Hidalgo. In many respects the orbit of Hidalgo represents a compromise among those of the periodic comets Tuttle, Wild, and Neuj- min 1, all four objects having their aphelia near the orbit of Saturn and rather high orbital eccentricities and inclinations. Perhaps the most significant difference between minor planets and short-period comets is that the orbits of the latter are continually being disturbed as the result of passages near Jupiter, while the orbits of the former - except for Hidalgo - are stable. That Hidalgo can pass only 0.4 AU from Jupiter (Belyaev and Chebotarev, 1968) can certainly be regarded as suggestive of its cometary nature. Actually, the orbit of Hidalgo would be relatively stable for a short-period comet, only P/Neujmin 1 and P/Arend-Rigaux having been more successful at avoiding Jupiter in recent cen turies (Marsden, 1970). These two comets are unusual in that they are almost invari ably asteroidal in appearance, their cometary character having been evident only when they were considerably closer to the Earth than Hidalgo ever comes. -

The Minor Planet Bulletin Is Open to Papers on All Aspects of 6500 Kodaira (F) 9 25.5 14.8 + 5 0 Minor Planet Study
THE MINOR PLANET BULLETIN OF THE MINOR PLANETS SECTION OF THE BULLETIN ASSOCIATION OF LUNAR AND PLANETARY OBSERVERS VOLUME 32, NUMBER 3, A.D. 2005 JULY-SEPTEMBER 45. 120 LACHESIS – A VERY SLOW ROTATOR were light-time corrected. Aspect data are listed in Table I, which also shows the (small) percentage of the lightcurve observed each Colin Bembrick night, due to the long period. Period analysis was carried out Mt Tarana Observatory using the “AVE” software (Barbera, 2004). Initial results indicated PO Box 1537, Bathurst, NSW, Australia a period close to 1.95 days and many trial phase stacks further [email protected] refined this to 1.910 days. The composite light curve is shown in Figure 1, where the assumption has been made that the two Bill Allen maxima are of approximately equal brightness. The arbitrary zero Vintage Lane Observatory phase maximum is at JD 2453077.240. 83 Vintage Lane, RD3, Blenheim, New Zealand Due to the long period, even nine nights of observations over two (Received: 17 January Revised: 12 May) weeks (less than 8 rotations) have not enabled us to cover the full phase curve. The period of 45.84 hours is the best fit to the current Minor planet 120 Lachesis appears to belong to the data. Further refinement of the period will require (probably) a group of slow rotators, with a synodic period of 45.84 ± combined effort by multiple observers – preferably at several 0.07 hours. The amplitude of the lightcurve at this longitudes. Asteroids of this size commonly have rotation rates of opposition was just over 0.2 magnitudes. -

The V-Band Photometry of Asteroids from ASAS-SN
Astronomy & Astrophysics manuscript no. 40759˙ArXiV © ESO 2021 July 22, 2021 V-band photometry of asteroids from ASAS-SN Finding asteroids with slow spin ? J. Hanusˇ1, O. Pejcha2, B. J. Shappee3, C. S. Kochanek4;5, K. Z. Stanek4;5, and T. W.-S. Holoien6;?? 1 Institute of Astronomy, Faculty of Mathematics and Physics, Charles University, V Holesoviˇ ckˇ ach´ 2, 18000 Prague, Czech Republic 2 Institute of Theoretical Physics, Faculty of Mathematics and Physics, Charles University, V Holesoviˇ ckˇ ach´ 2, 18000 Prague, Czech Republic 3 Institute for Astronomy, University of Hawai’i, 2680 Woodlawn Drive, Honolulu, HI 96822, USA 4 Department of Astronomy, The Ohio State University, 140 West 18th Avenue, Columbus, OH 43210, USA 5 Center for Cosmology and Astroparticle Physics, The Ohio State University, 191 W. Woodruff Avenue, Columbus, OH 43210, USA 6 The Observatories of the Carnegie Institution for Science, 813 Santa Barbara St., Pasadena, CA 91101, USA Received x-x-2021 / Accepted x-x-2021 ABSTRACT We present V-band photometry of the 20,000 brightest asteroids using data from the All-Sky Automated Survey for Supernovae (ASAS-SN) between 2012 and 2018. We were able to apply the convex inversion method to more than 5,000 asteroids with more than 60 good measurements in order to derive their sidereal rotation periods, spin axis orientations, and shape models. We derive unique spin state and shape solutions for 760 asteroids, including 163 new determinations. This corresponds to a success rate of about 15%, which is significantly higher than the success rate previously achieved using photometry from surveys.