Going Beyond T-SNE: Exposing Whatlies in Text Embeddings
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Malware Classification with BERT
San Jose State University SJSU ScholarWorks Master's Projects Master's Theses and Graduate Research Spring 5-25-2021 Malware Classification with BERT Joel Lawrence Alvares Follow this and additional works at: https://scholarworks.sjsu.edu/etd_projects Part of the Artificial Intelligence and Robotics Commons, and the Information Security Commons Malware Classification with Word Embeddings Generated by BERT and Word2Vec Malware Classification with BERT Presented to Department of Computer Science San José State University In Partial Fulfillment of the Requirements for the Degree By Joel Alvares May 2021 Malware Classification with Word Embeddings Generated by BERT and Word2Vec The Designated Project Committee Approves the Project Titled Malware Classification with BERT by Joel Lawrence Alvares APPROVED FOR THE DEPARTMENT OF COMPUTER SCIENCE San Jose State University May 2021 Prof. Fabio Di Troia Department of Computer Science Prof. William Andreopoulos Department of Computer Science Prof. Katerina Potika Department of Computer Science 1 Malware Classification with Word Embeddings Generated by BERT and Word2Vec ABSTRACT Malware Classification is used to distinguish unique types of malware from each other. This project aims to carry out malware classification using word embeddings which are used in Natural Language Processing (NLP) to identify and evaluate the relationship between words of a sentence. Word embeddings generated by BERT and Word2Vec for malware samples to carry out multi-class classification. BERT is a transformer based pre- trained natural language processing (NLP) model which can be used for a wide range of tasks such as question answering, paraphrase generation and next sentence prediction. However, the attention mechanism of a pre-trained BERT model can also be used in malware classification by capturing information about relation between each opcode and every other opcode belonging to a malware family. -

15 Things You Should Know About Spacy
15 THINGS YOU SHOULD KNOW ABOUT SPACY ALEXANDER CS HENDORF @ EUROPYTHON 2020 0 -preface- Natural Language Processing Natural Language Processing (NLP): A Unstructured Data Avalanche - Est. 20% of all data - Structured Data - Data in databases, format-xyz Different Kinds of Data - Est. 80% of all data, requires extensive pre-processing and different methods for analysis - Unstructured Data - Verbal, text, sign- communication - Pictures, movies, x-rays - Pink noise, singularities Some Applications of NLP - Dialogue systems (Chatbots) - Machine Translation - Sentiment Analysis - Speech-to-text and vice versa - Spelling / grammar checking - Text completion Many Smart Things in Text Data! Rule-Based Exploratory / Statistical NLP Use Cases � Alexander C. S. Hendorf [email protected] -Partner & Principal Consultant Data Science & AI @hendorf Consulting and building AI & Data Science for enterprises. -Python Software Foundation Fellow, Python Softwareverband chair, Emeritus EuroPython organizer, Currently Program Chair of EuroSciPy, PyConDE & PyData Berlin, PyData community organizer -Speaker Europe & USA MongoDB World New York / San José, PyCons, CEBIT Developer World, BI Forum, IT-Tage FFM, PyData London, Berlin, PyParis,… here! NLP Alchemy Toolset 1 - What is spaCy? - Stable Open-source library for NLP: - Supports over 55+ languages - Comes with many pretrained language models - Designed for production usage - Advantages: - Fast and efficient - Relatively intuitive - Simple deep learning implementation - Out-of-the-box support for: - Named entity recognition - Part-of-speech (POS) tagging - Labelled dependency parsing - … 2 – Building Blocks of spaCy 2 – Building Blocks I. - Tokenization Segmenting text into words, punctuations marks - POS (Part-of-speech tagging) cat -> noun, scratched -> verb - Lemmatization cats -> cat, scratched -> scratch - Sentence Boundary Detection Hello, Mrs. Poppins! - NER (Named Entity Recognition) Marry Poppins -> person, Apple -> company - Serialization Saving NLP documents 2 – Building Blocks II. -

Arxiv:2002.06235V1
Semantic Relatedness and Taxonomic Word Embeddings Magdalena Kacmajor John D. Kelleher Innovation Exchange ADAPT Research Centre IBM Ireland Technological University Dublin [email protected] [email protected] Filip Klubickaˇ Alfredo Maldonado ADAPT Research Centre Underwriters Laboratories Technological University Dublin [email protected] [email protected] Abstract This paper1 connects a series of papers dealing with taxonomic word embeddings. It begins by noting that there are different types of semantic relatedness and that different lexical representa- tions encode different forms of relatedness. A particularly important distinction within semantic relatedness is that of thematic versus taxonomic relatedness. Next, we present a number of ex- periments that analyse taxonomic embeddings that have been trained on a synthetic corpus that has been generated via a random walk over a taxonomy. These experiments demonstrate how the properties of the synthetic corpus, such as the percentage of rare words, are affected by the shape of the knowledge graph the corpus is generated from. Finally, we explore the interactions between the relative sizes of natural and synthetic corpora on the performance of embeddings when taxonomic and thematic embeddings are combined. 1 Introduction Deep learning has revolutionised natural language processing over the last decade. A key enabler of deep learning for natural language processing has been the development of word embeddings. One reason for this is that deep learning intrinsically involves the use of neural network models and these models only work with numeric inputs. Consequently, applying deep learning to natural language processing first requires developing a numeric representation for words. Word embeddings provide a way of creating numeric representations that have proven to have a number of advantages over traditional numeric rep- resentations of language. -

Automatic Correction of Real-Word Errors in Spanish Clinical Texts
sensors Article Automatic Correction of Real-Word Errors in Spanish Clinical Texts Daniel Bravo-Candel 1,Jésica López-Hernández 1, José Antonio García-Díaz 1 , Fernando Molina-Molina 2 and Francisco García-Sánchez 1,* 1 Department of Informatics and Systems, Faculty of Computer Science, Campus de Espinardo, University of Murcia, 30100 Murcia, Spain; [email protected] (D.B.-C.); [email protected] (J.L.-H.); [email protected] (J.A.G.-D.) 2 VÓCALI Sistemas Inteligentes S.L., 30100 Murcia, Spain; [email protected] * Correspondence: [email protected]; Tel.: +34-86888-8107 Abstract: Real-word errors are characterized by being actual terms in the dictionary. By providing context, real-word errors are detected. Traditional methods to detect and correct such errors are mostly based on counting the frequency of short word sequences in a corpus. Then, the probability of a word being a real-word error is computed. On the other hand, state-of-the-art approaches make use of deep learning models to learn context by extracting semantic features from text. In this work, a deep learning model were implemented for correcting real-word errors in clinical text. Specifically, a Seq2seq Neural Machine Translation Model mapped erroneous sentences to correct them. For that, different types of error were generated in correct sentences by using rules. Different Seq2seq models were trained and evaluated on two corpora: the Wikicorpus and a collection of three clinical datasets. The medicine corpus was much smaller than the Wikicorpus due to privacy issues when dealing Citation: Bravo-Candel, D.; López-Hernández, J.; García-Díaz, with patient information. -

Combining Word Embeddings with Semantic Resources
AutoExtend: Combining Word Embeddings with Semantic Resources Sascha Rothe∗ LMU Munich Hinrich Schutze¨ ∗ LMU Munich We present AutoExtend, a system that combines word embeddings with semantic resources by learning embeddings for non-word objects like synsets and entities and learning word embeddings that incorporate the semantic information from the resource. The method is based on encoding and decoding the word embeddings and is flexible in that it can take any word embeddings as input and does not need an additional training corpus. The obtained embeddings live in the same vector space as the input word embeddings. A sparse tensor formalization guar- antees efficiency and parallelizability. We use WordNet, GermaNet, and Freebase as semantic resources. AutoExtend achieves state-of-the-art performance on Word-in-Context Similarity and Word Sense Disambiguation tasks. 1. Introduction Unsupervised methods for learning word embeddings are widely used in natural lan- guage processing (NLP). The only data these methods need as input are very large corpora. However, in addition to corpora, there are many other resources that are undoubtedly useful in NLP, including lexical resources like WordNet and Wiktionary and knowledge bases like Wikipedia and Freebase. We will simply refer to these as resources. In this article, we present AutoExtend, a method for enriching these valuable resources with embeddings for non-word objects they describe; for example, Auto- Extend enriches WordNet with embeddings for synsets. The word embeddings and the new non-word embeddings live in the same vector space. Many NLP applications benefit if non-word objects described by resources—such as synsets in WordNet—are also available as embeddings. -

Bros:Apre-Trained Language Model for Understanding Textsin Document
Under review as a conference paper at ICLR 2021 BROS: A PRE-TRAINED LANGUAGE MODEL FOR UNDERSTANDING TEXTS IN DOCUMENT Anonymous authors Paper under double-blind review ABSTRACT Understanding document from their visual snapshots is an emerging and chal- lenging problem that requires both advanced computer vision and NLP methods. Although the recent advance in OCR enables the accurate extraction of text seg- ments, it is still challenging to extract key information from documents due to the diversity of layouts. To compensate for the difficulties, this paper introduces a pre-trained language model, BERT Relying On Spatiality (BROS), that represents and understands the semantics of spatially distributed texts. Different from pre- vious pre-training methods on 1D text, BROS is pre-trained on large-scale semi- structured documents with a novel area-masking strategy while efficiently includ- ing the spatial layout information of input documents. Also, to generate structured outputs in various document understanding tasks, BROS utilizes a powerful graph- based decoder that can capture the relation between text segments. BROS achieves state-of-the-art results on four benchmark tasks: FUNSD, SROIE*, CORD, and SciTSR. Our experimental settings and implementation codes will be publicly available. 1 INTRODUCTION Document intelligence (DI)1, which understands industrial documents from their visual appearance, is a critical application of AI in business. One of the important challenges of DI is a key information extraction task (KIE) (Huang et al., 2019; Jaume et al., 2019; Park et al., 2019) that extracts struc- tured information from documents such as financial reports, invoices, business emails, insurance quotes, and many others. -
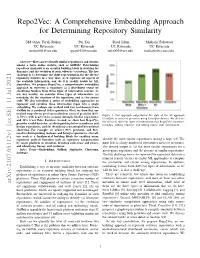
A Comprehensive Embedding Approach for Determining Repository Similarity
Repo2Vec: A Comprehensive Embedding Approach for Determining Repository Similarity Md Omar Faruk Rokon Pei Yan Risul Islam Michalis Faloutsos UC Riverside UC Riverside UC Riverside UC Riverside [email protected] [email protected] [email protected] [email protected] Abstract—How can we identify similar repositories and clusters among a large online archive, such as GitHub? Determining repository similarity is an essential building block in studying the dynamics and the evolution of such software ecosystems. The key challenge is to determine the right representation for the diverse repository features in a way that: (a) it captures all aspects of the available information, and (b) it is readily usable by ML algorithms. We propose Repo2Vec, a comprehensive embedding approach to represent a repository as a distributed vector by combining features from three types of information sources. As our key novelty, we consider three types of information: (a) metadata, (b) the structure of the repository, and (c) the source code. We also introduce a series of embedding approaches to represent and combine these information types into a single embedding. We evaluate our method with two real datasets from GitHub for a combined 1013 repositories. First, we show that our method outperforms previous methods in terms of precision (93% Figure 1: Our approach outperforms the state of the art approach vs 78%), with nearly twice as many Strongly Similar repositories CrossSim in terms of precision using CrossSim dataset. We also see and 30% fewer False Positives. Second, we show how Repo2Vec the effect of different types of information that Repo2Vec considers: provides a solid basis for: (a) distinguishing between malware and metadata, adding structure, and adding source code information. -

Word-Like Character N-Gram Embedding
Word-like character n-gram embedding Geewook Kim and Kazuki Fukui and Hidetoshi Shimodaira Department of Systems Science, Graduate School of Informatics, Kyoto University Mathematical Statistics Team, RIKEN Center for Advanced Intelligence Project fgeewook, [email protected], [email protected] Abstract Table 1: Top-10 2-grams in Sina Weibo and 4-grams in We propose a new word embedding method Japanese Twitter (Experiment 1). Words are indicated called word-like character n-gram embed- by boldface and space characters are marked by . ding, which learns distributed representations FNE WNE (Proposed) Chinese Japanese Chinese Japanese of words by embedding word-like character n- 1 ][ wwww 自己 フォロー grams. Our method is an extension of recently 2 。␣ !!!! 。␣ ありがと proposed segmentation-free word embedding, 3 !␣ ありがと ][ wwww 4 .. りがとう 一个 !!!! which directly embeds frequent character n- 5 ]␣ ございま 微博 めっちゃ grams from a raw corpus. However, its n-gram 6 。。 うござい 什么 んだけど vocabulary tends to contain too many non- 7 ,我 とうござ 可以 うござい 8 !! ざいます 没有 line word n-grams. We solved this problem by in- 9 ␣我 がとうご 吗? 2018 troducing an idea of expected word frequency. 10 了, ください 哈哈 じゃない Compared to the previously proposed meth- ods, our method can embed more words, along tion tools are used to determine word boundaries with the words that are not included in a given in the raw corpus. However, these segmenters re- basic word dictionary. Since our method does quire rich dictionaries for accurate segmentation, not rely on word segmentation with rich word which are expensive to prepare and not always dictionaries, it is especially effective when the available. -

Information Extraction Based on Named Entity for Tourism Corpus
Information Extraction based on Named Entity for Tourism Corpus Chantana Chantrapornchai Aphisit Tunsakul Dept. of Computer Engineering Dept. of Computer Engineering Faculty of Engineering Faculty of Engineering Kasetsart University Kasetsart University Bangkok, Thailand Bangkok, Thailand [email protected] [email protected] Abstract— Tourism information is scattered around nowa- The ontology is extracted based on HTML web structure, days. To search for the information, it is usually time consuming and the corpus is based on WordNet. For these approaches, to browse through the results from search engine, select and the time consuming process is the annotation which is to view the details of each accommodation. In this paper, we present a methodology to extract particular information from annotate the type of name entity. In this paper, we target at full text returned from the search engine to facilitate the users. the tourism domain, and aim to extract particular information Then, the users can specifically look to the desired relevant helping for ontology data acquisition. information. The approach can be used for the same task in We present the framework for the given named entity ex- other domains. The main steps are 1) building training data traction. Starting from the web information scraping process, and 2) building recognition model. First, the tourism data is gathered and the vocabularies are built. The raw corpus is used the data are selected based on the HTML tag for corpus to train for creating vocabulary embedding. Also, it is used building. The data is used for model creation for automatic for creating annotated data. -

ACL 2019 Social Media Mining for Health Applications (#SMM4H)
ACL 2019 Social Media Mining for Health Applications (#SMM4H) Workshop & Shared Task Proceedings of the Fourth Workshop August 2, 2019 Florence, Italy c 2019 The Association for Computational Linguistics Order copies of this and other ACL proceedings from: Association for Computational Linguistics (ACL) 209 N. Eighth Street Stroudsburg, PA 18360 USA Tel: +1-570-476-8006 Fax: +1-570-476-0860 [email protected] ISBN 978-1-950737-46-8 ii Preface Welcome to the 4th Social Media Mining for Health Applications Workshop and Shared Task - #SMM4H 2019. The total number of users of social media continues to grow worldwide, resulting in the generation of vast amounts of data. Popular social networking sites such as Facebook, Twitter and Instagram dominate this sphere. According to estimates, 500 million tweets and 4.3 billion Facebook messages are posted every day 1. The latest Pew Research Report 2, nearly half of adults worldwide and two- thirds of all American adults (65%) use social networking. The report states that of the total users, 26% have discussed health information, and, of those, 30% changed behavior based on this information and 42% discussed current medical conditions. Advances in automated data processing, machine learning and NLP present the possibility of utilizing this massive data source for biomedical and public health applications, if researchers address the methodological challenges unique to this media. In its fourth iteration, the #SMM4H workshop takes place in Florence, Italy, on August 2, 2019, and is co-located with the -

Mapping the Hyponymy Relation of Wordnet Onto
Under review as a conference paper at ICLR 2019 MAPPING THE HYPONYMY RELATION OF WORDNET ONTO VECTOR SPACES Anonymous authors Paper under double-blind review ABSTRACT In this paper, we investigate mapping the hyponymy relation of WORDNET to feature vectors. We aim to model lexical knowledge in such a way that it can be used as input in generic machine-learning models, such as phrase entailment predictors. We propose two models. The first one leverages an existing mapping of words to feature vectors (fastText), and attempts to classify such vectors as within or outside of each class. The second model is fully supervised, using solely WORDNET as a ground truth. It maps each concept to an interval or a disjunction thereof. On the first model, we approach, but not quite attain state of the art performance. The second model can achieve near-perfect accuracy. 1 INTRODUCTION Distributional encoding of word meanings from the large corpora (Mikolov et al., 2013; 2018; Pen- nington et al., 2014) have been found to be useful for a number of NLP tasks. These approaches are based on a probabilistic language model by Bengio et al. (2003) of word sequences, where each word w is represented as a feature vector f(w) (a compact representation of a word, as a vector of floating point values). This means that one learns word representations (vectors) and probabilities of word sequences at the same time. While the major goal of distributional approaches is to identify distributional patterns of words and word sequences, they have even found use in tasks that require modeling more fine-grained relations between words than co-occurrence in word sequences. -

Pairwise Fasttext Classifier for Entity Disambiguation
Pairwise FastText Classifier for Entity Disambiguation a,b b b Cheng Yu , Bing Chu , Rohit Ram , James Aichingerb, Lizhen Qub,c, Hanna Suominenb,c a Project Cleopatra, Canberra, Australia b The Australian National University c DATA 61, Australia [email protected] {u5470909,u5568718,u5016706, Hanna.Suominen}@anu.edu.au [email protected] deterministically. Then we will evaluate PFC’s Abstract performance against a few baseline methods, in- cluding SVC3 with hand-crafted text features. Fi- For the Australasian Language Technology nally, we will discuss ways to improve disambig- Association (ALTA) 2016 Shared Task, we uation performance using PFC. devised Pairwise FastText Classifier (PFC), an efficient embedding-based text classifier, 2 Pairwise Fast-Text Classifier (PFC) and used it for entity disambiguation. Com- pared with a few baseline algorithms, PFC Our Pairwise FastText Classifier is inspired by achieved a higher F1 score at 0.72 (under the the FastText. Thus this section starts with a brief team name BCJR). To generalise the model, description of FastText, and proceeds to demon- we also created a method to bootstrap the strate PFC. training set deterministically without human labelling and at no financial cost. By releasing 2.1 FastText PFC and the dataset augmentation software to the public1, we hope to invite more collabora- FastText maps each vocabulary to a real-valued tion. vector, with unknown words having a special vo- cabulary ID. A document can be represented as 1 Introduction the average of all these vectors. Then FastText will train a maximum entropy multi-class classi- The goal of the ALTA 2016 Shared Task was to fier on the vectors and the output labels.