Issues Related to Non-Latin Characters in Name Authority Records
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

F(P,Q) = Ffeic(R+TQ)
674 MATHEMA TICS: N. H. McCOY PR.OC. N. A. S. ON THE FUNCTION IN QUANTUM MECHANICS WHICH CORRESPONDS TO A GIVEN FUNCTION IN CLASSICAL MECHANICS By NEAL H. MCCoy DEPARTMENT OF MATHEMATICS, SMrTH COLLEGE Communicated October 11, 1932 Let f(p,q) denote a function of the canonical variables p,q of classical mechanics. In making the transition to quantum mechanics, the variables p,q are represented by Hermitian operators P,Q which, satisfy the com- mutation rule PQ- Qp = 'y1 (1) where Y = h/2ri and 1 indicates the unit operator. From group theoretic considerations, Weyll has obtained the following general rule for carrying a function over from classical to quantum mechanics. Express f(p,q) as a Fourier integral, f(p,q) = f feiC(r+TQ) r(,r)d(rdT (2) (or in any other way as a linear combination of the functions eW(ffP+T)). Then the function F(P,Q) in quantum mechanics which corresponds to f(p,q) is given by F(P,Q)- ff ei(0P+7Q) t(cr,r)dodr. (3) It is the purpose of this note to obtain an explicit expression for F(P,Q), and although we confine our statements to the case in which f(p,q) is a polynomial, the results remain formally correct for infinite series. Any polynomial G(P,Q) may, by means of relation (1), be written in a form in which all of the Q-factors occur on the left in each term. This form of the function G(P,Q) will be denoted by GQ(P,Q). -

College Summit, Inc. D/B/A Peerforward Financial Statements
College Summit, Inc. d/b/a PeerForward Financial Statements For the Years Ended April 30, 2020 and 2019 and Report Thereon COLLEGE SUMMIT, INC. d/b/a PeerForward TABLE OF CONTENTS For the Years Ended April 30, 2020 and 2019 _______________ Page Independent Auditors’ Report ............................................................................................................. 1-2 Financial Statements Statements of Financial Position ........................................................................................................ 3 Statements of Activities ...................................................................................................................... 4 Statements of Functional Expenses ................................................................................................ 5-6 Statements of Cash Flows .................................................................................................................. 7 Notes to Financial Statements ....................................................................................................... 8-17 INDEPENDENT AUDITORS’ REPORT To the Board of Directors of College Summit, Inc. d/b/a PeerForward Report on the Financial Statements We have audited the accompanying financial statements of College Summit, Inc. d/b/a PeerForward (PeerForward), which comprise the statements of financial position as of April 30, 2020 and 2019, and the related statements of activities, functional expenses and cash flows for the years then ended, and the related notes -

How Can We Create Environments Where Hate Cannot Flourish?
How can we create environments where hate cannot flourish? Saturday, February 1 9:30 a.m. – 10:00 a.m. Check-In and Registration Location: Field Museum West Entrance 10:00 a.m. – 10:30 a.m. Introductions and Program Kick-Off JoAnna Wasserman, USHMM Education Initiatives Manager Location: Lecture Hall 1 10:30 a.m. – 11:30 a.m. Watch “The Path to Nazi Genocide” and Reflections JoAnna Wasserman, USHMM Education Initiatives Manager Location: Lecture Hall 1 11:30 a.m. – 11:45 a.m. Break and walk to State of Deception 11:45 a.m. – 12:30 p.m. Visit State of Deception Interpretation by Holocaust Survivor Volunteers from the Illinois Holocaust Museum Location: Upper level 12:30 p.m. – 1:00 p.m. Breakout Session: Reflections on Exhibit Tim Kaiser, USHMM Director, Education Initiatives David Klevan, USHMM Digital Learning Strategist JoAnna Wasserman, USHMM Education Initiatives Manager Location: Lecture Hall 1, Classrooms A and B Saturday, February 2 (continued) 1:00 p.m. – 1:45 p.m. Lunch 1:45 p.m. – 2:45 p.m. A Survivor’s Personal Story Bob Behr, USHMM Survivor Volunteer Interviewed by: Ann Weber, USHMM Program Coordinator Location: Lecture Hall 1 2:45 p.m. – 3:00 p.m. Break 3:00 p.m. – 3:45 p.m. Student Panel: Beyond Indifference Location: Lecture Hall 1 Moderator: Emma Pettit, Sustained Dialogue Campus Network Student/Alumni Panelists: Jazzy Johnson, Northwestern University Mary Giardina, The Ohio State University Nory Kaplan-Kelly, University of Chicago 3:45 p.m. – 4:30 p.m. Breakout Session: Sharing Personal Reflections Tim Kaiser, USHMM Director, Education Initiatives David Klevan, USHMM Digital Learning Strategist JoAnna Wasserman, USHMM Education Initiatives Manager Location: Lecture Hall 1, Classrooms A and B 4:30 p.m. -

Stroke Training for EMS Professionals (PDF)
STROKE TRAINING FOR EMS PROFESSIONALS 1 COURSE OBJECTIVES About Stroke Stroke Policy Recommendations Stroke Protocols and Stroke Hospital Care Stroke Assessment Tools Pre-Notification Stroke Treatment ABOUT STROKE STROKE FACTS • A stroke is a medical emergency! Stroke occurs when blood flow is either cut off or is reduced, depriving the brain of blood and oxygen • Approximately 795,000 strokes occur in the US each year • Stroke is the fifth leading cause of death in the US • Stroke is a leading cause of adult disability • On average, every 40 seconds, someone in the United States has a stroke • Over 4 million stroke survivors are in the US • The indirect and direct cost of stroke: $38.6 billion annually (2009) • Crosses all ethnic, racial and socioeconomic groups Berry, Jarett D., et al. Heart Disease and Stroke Statistics --2013 Update: A Report from the American Heart Association. Circulation. 127, 2013. DIFFERENT TYPES OF STROKE Ischemic Stroke • Caused by a blockage in an artery stopping normal blood and oxygen flow to the brain • 87% of strokes are ischemic • There are two types of ischemic strokes: Embolism: Blood clot or plaque fragment from elsewhere in the body gets lodged in the brain Thrombosis: Blood clot formed in an artery that provides blood to the brain Berry, Jarett D., et al. Heart Disease and Stroke Statistics --2013 Update: A Report from the American Heart Association. Circulation. 127, 2013. http://www.strokeassociation.org/STROKEORG/AboutStroke/TypesofStroke/IschemicClots/Ischemic-Strokes- Clots_UCM_310939_Article.jsp -

Form 1095-B Health Coverage Department of the Treasury ▶ Do Not Attach to Your Tax Return
560118 VOID OMB No. 1545-2252 Form 1095-B Health Coverage Department of the Treasury ▶ Do not attach to your tax return. Keep for your records. CORRECTED 2020 Internal Revenue Service ▶ Go to www.irs.gov/Form1095B for instructions and the latest information. Part I Responsible Individual 1 Name of responsible individual–First name, middle name, last name 2 Social security number (SSN) or other TIN 3 Date of birth (if SSN or other TIN is not available) 4 Street address (including apartment no.) 5 City or town 6 State or province 7 Country and ZIP or foreign postal code 9 Reserved 8 Enter letter identifying Origin of the Health Coverage (see instructions for codes): . ▶ Part II Information About Certain Employer-Sponsored Coverage (see instructions) 10 Employer name 11 Employer identification number (EIN) 12 Street address (including room or suite no.) 13 City or town 14 State or province 15 Country and ZIP or foreign postal code Part III Issuer or Other Coverage Provider (see instructions) 16 Name 17 Employer identification number (EIN) 18 Contact telephone number 19 Street address (including room or suite no.) 20 City or town 21 State or province 22 Country and ZIP or foreign postal code Part IV Covered Individuals (Enter the information for each covered individual.) (a) Name of covered individual(s) (b) SSN or other TIN (c) DOB (if SSN or other (d) Covered (e) Months of coverage First name, middle initial, last name TIN is not available) all 12 months Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 23 24 25 26 27 28 For Privacy Act and Paperwork Reduction Act Notice, see separate instructions. -

State of New Physics in B->S Transitions
New physics in b ! s transitions after LHC run 1 Wolfgang Altmannshofera and David M. Straubb a Perimeter Institute for Theoretical Physics, 31 Caroline St. N, Waterloo, Ontario, Canada N2L 2Y5 b Excellence Cluster Universe, TUM, Boltzmannstr. 2, 85748 Garching, Germany E-mail: [email protected], [email protected] We present results of global fits of all relevant experimental data on rare b s decays. We observe significant tensions between the Standard Model predictions! and the data. After critically reviewing the possible sources of theoretical uncer- tainties, we find that within the Standard Model, the tensions could be explained if there are unaccounted hadronic effects much larger than our estimates. Assuming hadronic uncertainties are estimated in a sufficiently conservative way, we discuss the implications of the experimental results on new physics, both model indepen- dently as well as in the context of the minimal supersymmetric standard model and models with flavour-changing Z0 bosons. We discuss in detail the violation of lepton flavour universality as hinted by the current data and make predictions for additional lepton flavour universality tests that can be performed in the future. We find that the ratio of the forward-backward asymmetries in B K∗µ+µ− and B K∗e+e− at low dilepton invariant mass is a particularly sensitive! probe of lepton! flavour universality and allows to distinguish between different new physics scenarios that give the best description of the current data. Contents 1. Introduction2 2. Observables and uncertainties3 2.1. Effective Hamiltonian . .4 2.2. B Kµ+µ− .....................................4 2.3. B ! K∗µ+µ− and B K∗γ ............................6 ! + − ! 2.4. -

THE ZEROS of QUASI-ANALYTIC FUNCTIONS1 (3) H(V) = — F U-2 Log
THE ZEROS OF QUASI-ANALYTICFUNCTIONS1 ARTHUR O. GARDER, JR. 1. Statement of the theorem. Definition 1. C(Mn, k) is the class of functions f(x) ior which there exist positive constants A and k and a sequence (Af„)"_0 such that (1) |/(n)(x)| ^AknM„, - oo < x< oo,» = 0,l,2, • • • . Definition 2. C(Mn, k) is a quasi-analytic class if 0 is the only element / of C(Mn, k) ior which there exists a point x0 at which /<">(*„)=0 for « = 0, 1, 2, ••• . We introduce the functions (2) T(u) = max u"(M„)_l, 0 ^ m < oo, and (3) H(v) = — f u-2 log T(u)du. T J l The following property of H(v) characterizes quasi-analytic classes. Theorem 3 [5, 78 ].2 Let lim,,.,*, M„/n= °o.A necessary and sufficient condition that C(Mn, k) be a quasi-analytic class is that (4) lim H(v) = oo, where H(v) is defined by (2) and (3). Definition 4. Let v(x) be a function satisfying (i) v(x) is continuously differentiable for 0^x< oo, (ii) v(0) = l, v'(x)^0, 0^x<oo, (iii) xv'(x)/v(x)=0 (log x)-1, x—>oo. We shall say that/(x)GC* if and only if f(x)EC(Ml, k), where M* = n\[v(n)]n and v(n) satisfies the above conditions. Definition 5. Let Z(u) be a real-valued function which is less Received by the editors November 29, 1954 and, in revised form, February 24, 1955. 1 Presented to the Graduate School of Washington University in partial fulfill- ment of the requirements for the degree of Doctor of Philosophy. -

Medical Terminology Abbreviations Medical Terminology Abbreviations
34 MEDICAL TERMINOLOGY ABBREVIATIONS MEDICAL TERMINOLOGY ABBREVIATIONS The following list contains some of the most common abbreviations found in medical records. Please note that in medical terminology, the capitalization of letters bears significance as to the meaning of certain terms, and is often used to distinguish terms with similar acronyms. @—at A & P—anatomy and physiology ab—abortion abd—abdominal ABG—arterial blood gas a.c.—before meals ac & cl—acetest and clinitest ACLS—advanced cardiac life support AD—right ear ADL—activities of daily living ad lib—as desired adm—admission afeb—afebrile, no fever AFB—acid-fast bacillus AKA—above the knee alb—albumin alt dieb—alternate days (every other day) am—morning AMA—against medical advice amal—amalgam amb—ambulate, walk AMI—acute myocardial infarction amt—amount ANS—automatic nervous system ant—anterior AOx3—alert and oriented to person, time, and place Ap—apical AP—apical pulse approx—approximately aq—aqueous ARDS—acute respiratory distress syndrome AS—left ear ASA—aspirin asap (ASAP)—as soon as possible as tol—as tolerated ATD—admission, transfer, discharge AU—both ears Ax—axillary BE—barium enema bid—twice a day bil, bilateral—both sides BK—below knee BKA—below the knee amputation bl—blood bl wk—blood work BLS—basic life support BM—bowel movement BOW—bag of waters B/P—blood pressure bpm—beats per minute BR—bed rest MEDICAL TERMINOLOGY ABBREVIATIONS 35 BRP—bathroom privileges BS—breath sounds BSI—body substance isolation BSO—bilateral salpingo-oophorectomy BUN—blood, urea, nitrogen -

Grading System the Grades of A, B, C, D and P Are Passing Grades
Grading System The grades of A, B, C, D and P are passing grades. Grades of F and U are failing grades. R and I are interim grades. Grades of W and X are final grades carrying no credit. Individual instructors determine criteria for letter grade assignments described in individual course syllabi. Explanation of Grades The quality of performance in any academic course is reported by a letter grade, assigned by the instructor. These grades denote the character of study and are assigned quality points as follows: A Excellent 4 grade points per credit B Good 3 grade points per credit C Average 2 grade points per credit D Poor 1 grade point per credit F Failure 0 grade points per credit I Incomplete No credit, used for verifiable, unavoidable reasons. Requirements for satisfactory completion are established through student/faculty consultation. Courses for which the grade of I (incomplete) is awarded must be completed by the end of the subsequent semester or another grade (A, B, C, D, F, W, P, R, S and U) is awarded by the instructor based upon completed course work. In the case of I grades earned at the end of the spring semester, students have through the end of the following fall semester to complete the requirements. In exceptional cases, extensions of time needed to complete course work for I grades may be granted beyond the subsequent semester, with the written approval of the vice president of learning. An I grade can change to a W grade only under documented mitigating circumstances. The vice president of learning must approve the grade change. -
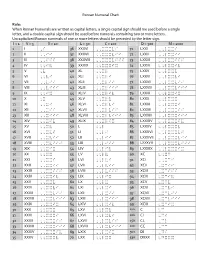
Roman Numeral Chart
Roman Numeral Chart Rule: When Roman Numerals are written as capital letters, a single capital sign should me used before a single letter, and a double capital sign should be used before numerals containing two or more letters. Uncapitalized Roman numerals of one or more letters should be preceded by the letter sign. I = 1 V = 5 X = 10 L = 50 C = 100 D = 500 M = 1000 1 I ,I 36 XXXVI ,,XXXVI 71 LXXI ,,LXXI 2 II ,,II 37 XXXVII ,,XXXVII 72 LXXII ,,LXXII 3 III ,,III 38 XXXVIII ,,XXXVIII 73 LXXIII ,,LXXIII 4 IV ,,IV 39 XXXIX ,,XXXIX 74 LXXIV ,,LXXIV 5 V ,V 40 XL ,,XL 75 LXXV ,,LXXV 6 VI ,,VI 41 XLI ,,XLI 76 LXXVI ,,LXXVI 7 VII ,,VII 42 XLII ,,XLII 77 LXXVII ,,LXXVII 8 VIII ,,VIII 43 XLIII ,,XLIII 78 LXXVIII ,,LXXVIII 9 IX ,,IX 44 XLIV ,,XLIV 79 LXXIX ,,LXXIX 10 X ,X 45 XLV ,,XLV 80 LXXX ,,LXXX 11 XI ,,XI 46 XLVI ,,XLVI 81 LXXXI ,,LXXXI 12 XII ,,XII 47 XLVII ,,XLVII 82 LXXXII ,,LXXXII 13 XIII ,,XIII 48 XLVIII ,,XLVIII 83 LXXXIII ,,LXXXIII 14 XIV ,,XIV 49 XLIX ,,XLIX 84 LXXXIV ,,LXXXIV 15 XV ,,XV 50 L ,,L 85 LXXXV ,,LXXXV 16 XVI ,,XVI 51 LI ,,LI 86 LXXXVI ,,LXXXVI 17 XVII ,,XVII 52 LII ,,LII 87 LXXXVII ,,LXXXVII 18 XVIII ,,XVIII 53 LIII ,,LIII 88 LXXXVIII ,,LXXXVIII 19 XIX ,,XIX 54 LIV ,,LIV 89 LXXXIX ,,LXXXIX 20 XX ,,XX 55 LV ,,LV 90 XC ,,XC 21 XXI ,,XXI 56 LVI ,,LVI 91 XCI ,,XCI 22 XXII ,,XXII 57 LVII ,,LVII 92 XCII ,XCII 23 XXIII ,,XXIII 58 LVIII ,,LVIII 93 XCIII ,XCIII 24 XXIV ,,XXIV 59 LIX ,,LIX 94 XCIV ,XCIV 25 XXV ,,XXV 60 LX ,,LX 95 XCV ,XCV 26 XXVI ,,XXVI 61 LXI ,,LXI 96 XCVI ,XCVI 27 XXVII ,,XXVII 62 LXII ,,LXII 97 XCVII ,XCVII 28 XXVIII ,,XXVIII 63 LXIII ,,LXIII 98 XCVIII ,XCVIII 29 XXIX ,,XXIX 64 LXIV ,,LXIV 99 XCIX ,XCIX 30 XXX ,,XXX 65 LXV ,,LXV 100 C ,C 31 XXXI ,,XXXI 66 LXVI ,,LXVI 101 CI ,CI 32 XXXII ,,XXXII 67 LXVII ,,LXVII 150 CL ,CL 33 XXXIII ,,XXXIII 68 LXVIII ,,LXVIII 200 CC ,CC 34 XXXIV ,,XXXIV 69 LXIX ,,LXIX 501 DI ,DI 35 XXXV ,,XXXV 70 LXX ,,LXX 530 DXXX ,DXXX . -
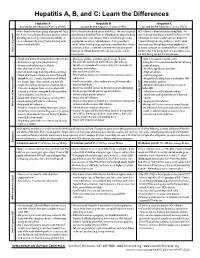
Hepatitis A, B, and C: Learn the Differences
Hepatitis A, B, and C: Learn the Differences Hepatitis A Hepatitis B Hepatitis C caused by the hepatitis A virus (HAV) caused by the hepatitis B virus (HBV) caused by the hepatitis C virus (HCV) HAV is found in the feces (poop) of people with hepa- HBV is found in blood and certain body fluids. The virus is spread HCV is found in blood and certain body fluids. The titis A and is usually spread by close personal contact when blood or body fluid from an infected person enters the body virus is spread when blood or body fluid from an HCV- (including sex or living in the same household). It of a person who is not immune. HBV is spread through having infected person enters another person’s body. HCV can also be spread by eating food or drinking water unprotected sex with an infected person, sharing needles or is spread through sharing needles or “works” when contaminated with HAV. “works” when shooting drugs, exposure to needlesticks or sharps shooting drugs, through exposure to needlesticks on the job, or from an infected mother to her baby during birth. or sharps on the job, or sometimes from an infected How is it spread? Exposure to infected blood in ANY situation can be a risk for mother to her baby during birth. It is possible to trans- transmission. mit HCV during sex, but it is not common. • People who wish to be protected from HAV infection • All infants, children, and teens ages 0 through 18 years There is no vaccine to prevent HCV. -

CONDITIONAL EXPECTATION Definition 1. Let (Ω,F,P)
CONDITIONAL EXPECTATION 1. CONDITIONAL EXPECTATION: L2 THEORY ¡ Definition 1. Let (,F ,P) be a probability space and let G be a σ algebra contained in F . For ¡ any real random variable X L2(,F ,P), define E(X G ) to be the orthogonal projection of X 2 j onto the closed subspace L2(,G ,P). This definition may seem a bit strange at first, as it seems not to have any connection with the naive definition of conditional probability that you may have learned in elementary prob- ability. However, there is a compelling rationale for Definition 1: the orthogonal projection E(X G ) minimizes the expected squared difference E(X Y )2 among all random variables Y j ¡ 2 L2(,G ,P), so in a sense it is the best predictor of X based on the information in G . It may be helpful to consider the special case where the σ algebra G is generated by a single random ¡ variable Y , i.e., G σ(Y ). In this case, every G measurable random variable is a Borel function Æ ¡ of Y (exercise!), so E(X G ) is the unique Borel function h(Y ) (up to sets of probability zero) that j minimizes E(X h(Y ))2. The following exercise indicates that the special case where G σ(Y ) ¡ Æ for some real-valued random variable Y is in fact very general. Exercise 1. Show that if G is countably generated (that is, there is some countable collection of set B G such that G is the smallest σ algebra containing all of the sets B ) then there is a j 2 ¡ j G measurable real random variable Y such that G σ(Y ).