Social Media Monitoring Dashboard for University by Dicken Tan
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Personal Particular
CURRICULUM VITAE ABU DZARR BIN MUHAMMAD RUS Faculty of Business and Accountancy Universiti of Selangor Section 7, 40000 Shah Alam Selangor EDUCATION BACKGROUND 2010 Master of Economics, National University of Malaysia (UKM), Selangor. 2008 Bachelor of Economics (Hons), Northern University of Malaysia (UUM), Kedah. EMPLOYMENT 2015 – Present Lecturer Faculty of Business and Accountancy University Selangor 2010 – 2013 Lecturer Faculty of Business Administration University Technology of MARA Pahang RESEARCH INTERESTS Macroeconomics, Islamic Economics, Islamic Banking and Finance, Monetary Economics. JOURNAL PUBLICATIONS 1. Bhuiyan, A. B., Kassim, A. A. M., Ali, M. J., Saad, M, Rus, A. D. M. (2020). Microfinance Institution’s Sustainability and Mission Drift: An Empirical Review. International Journal of Academic Research in Accounting, Finance and Management Sciences. 10(3), 349-364. 2. Hafezali Iqbal Hussain, Rashidah Kamarulzaman, Zulkiflee Abd Rahim, Abu Dzarr Muhammad Rus, Halimi Poniran, Mohd Reza Ab-dul Ghoni, Azlan Ali. (2018). The Colors of Sports Organization Fringe Benefit in Malaysia. International Journal of Engineering & Technology . 7 (3.25), 170-174. 3. Norsiah Aminudin, Abu Dzarr Muhammad Rus, Shamshubaridah Ramlee, Shahida Shahimi. (2017). The Value-Based Talent Recruitment Model In Islamic Finance Industry: The Counting And Positioning Issues In Malaysia. Journal of Islamic Economics, Banking and Finance .13 (3), 95-113. 4. Norsiah Aminudin, Abu Dzarr Muhammad Rus, Abul Bashar Bhuyian. (2016). The Variation Effect of Gender on the Motivation, Social Support and Goal Orientation of the Trainee in Malaysia. International Journal of Business and Technoprenuership. 6(3). 1 5. Abu Dzarr Muhammad Rus, Mohamad Helmi Hithiir, Abul Bashar Bhuyian, Norsiah Aminudin. (2016). Budget deficit and interest rate: Evidence from Malaysia, 1965-2005. -

14Th Surgical Nursing & Nurse Education Conference
P Thamilselvam, Surgery Curr Res 2016, 6:5(Suppl) conferenceseries.com http://dx.doi.org/10.4172/2161-1076.C1.022 14th Surgical Nursing & Nurse Education ConferenceOctober 10-11, 2016 Kuala Lumpur, Malaysia P Thamilselvam Universiti Pertahanan Nasional Malaysia, Malaysia Complications of laparoscopic surgery aparoscopic cholecystectomy and appendicectomy remains one of the most common laparoscopic surgeries being Lperformed throughout the world in the present era. The advantages of laparoscopic surgery over open surgery have already been proven. Since the first documented laparoscopic cholecystectomy by Proffesor Muhe in 1985, over the years, it has become the gold standard for cholecystectomy. The advantages of laparoscopic surgery have been questioned recently due to reports of some complications inherent to the approach. These complications may be due to: Induction of pneumoperitoneum; insertion of trocars; use of thermal instruments and; lack of experience and expertise. Complications like bowel perforation and vascular injury may not be recognized intraoperatively and are the main cause of procedure specific morbidity and mortality related to laparoscopic surgery. Biography P Thamilselvam is working in National Defence University of Malaysia (UPNM). He specialized in General Surgery in 1987 (Madras Medical college –University of Madras ) and subsequently worked as Lap and General Surgeon in Chennai Apollo Hospitals, Maldives and various Universities in Malaysia-AIMST University International Medical University and Perdana University -

YEAR 2017 No Publication Page No
LIST OF PUBLICATIONS AND ABSTRACTS YEAR 2017 No Publication Page no. 1 Agarwal R, Agarwal P. Rodent models of glaucoma and their 36 applicability for drug discovery. Expert Opinion on Drug Discovery, 2017; 12(3): 261-270. (ISI IF: 3.876; CiteScore: 3.50; Tier: Q1). 2 Agarwal R, Agarwal P. Targeting ECM remodeling in disease: Could 37 resveratrol be a potential candidate? Experimental Biology and Medicine, 2017; 242(4): 374-383. (ISI IF: 2.688; CiteScore: 2.42; Tier: Q1). 3 Ahmad AA, Ikram MA. Plating of an isolated fracture of shaft of ulna 38 under local anaesthesia and periosteal nerve block. A Case Report. Trauma Case Reports, 2017; 12: 40-44. (CiteScore: 0.11; Tier: Q4). 4 Ahmadi K, Hasan SS. Implementing professionalism by 39 deprofessionalized strategies: A moral quandary. Currents in Pharmacy Teaching and Learning, 2017; 9(1): 9-11. doi: 10.1016/j.cptl.2016.08.032. (CiteScore: 0.63; Tier: Q2). 5 Ahmed SI, Ramachandran A, Ahmadi K, Hasan SS, Christopher LKC. 40 Evaluation of patient satisfaction with HIV/AIDS care and treatment: A cross-sectional study. European Journal of Person Centred Healthcare, 2017; 5(1): 138-144. DOI: 10.5750/ejpch.v5i1.1250. (IF: NA). 6 Ahmed SI, Sulaiman SAS, Hassali MA, Thiruchelvam K, Hasan SS, * Christopher LKC. Acceptance and attitude towards screening: A qualitative perspective of people with HIV/AIDS (PLWHA). Journal of Infection Prevention, 2017; 18(5): 242-247. DOI: https://doi.org/10.1177/1757177416689723. (CiteScore: 0.37; Tier: Q3). 7 Ahmed SI, Syed Sulaiman SA, Hassali MA, Thiruchelvam K, Hasan SS, 41 Lee CKC. -

Online Communication Satisfaction in Using an Internet-Based Information Management System Among Employees at Four Research Universities in Malaysia
ONLINE COMMUNICATION SATISFACTION IN USING AN INTERNET-BASED INFORMATION MANAGEMENT SYSTEM AMONG EMPLOYEES AT FOUR RESEARCH UNIVERSITIES IN MALAYSIA MOHD AZUL MOHAMAD SALLEH Doctor of Philosophy UNIVERSITY OF ADELAIDE 2013 ONLINE COMMUNICATION SATISFACTION IN USING AN INTERNET-BASED INFORMATION MANAGEMENT SYSTEM AMONG EMPLOYEES AT FOUR RESEARCH UNIVERSITIES IN MALAYSIA Submitted by Mohd Azul Mohamad Salleh Master in Corporate Communication Universiti Putra Malaysia Master in Computer Science Universiti Malaya Bachelor in Information Technology Universiti Kebangsaan Malaysia A thesis submitted in fulfilment of the requirement for the degree of Doctor of Philosophy Discipline of Media Faculty of Social Sciences and Humanities University of Adelaide December 2013 i Table of Contents Table of Contents ii List of Abbreviations viii List of Tables xii List of Figures xiv Abstract xv Declaration xvii Acknowledgements xviii List of Publications xix Chapter 1 Introduction 1.0 Introduction 1 1.1 Background of the study 8 1.2 Rationale of the study 14 1.3 Aims of the study 18 1.4 Research questions 19 1.5 Research design 22 1.6 Significance of the study 25 1.7 Outline of the thesis 32 1.8 Summary 34 Chapter 2 Higher Education Reform in Malaysia 2.0 Introduction 35 2.1 Background of higher education in Malaysia 38 2.2 Mission of the public higher education sector 41 2.3 The national higher education strategic plan for quality outcomes 44 ii 2.4 Research universities in Malaysia 46 2.5 The use of ICT applications in education 49 2.6 IBIMS in research -

Kuok Foundation Berhad (9641-T) Undergraduate Awards 2014 ( Private Universities / Colleges )
KUOK FOUNDATION BERHAD (9641-T) UNDERGRADUATE AWARDS 2014 ( PRIVATE UNIVERSITIES / COLLEGES ) KUOK FOUNDATION BERHAD invites applications for the above awards from Malaysian citizens applying for or currently pursuing full time undergraduate studies at the following institutions :- Private Universities AIMST University, Kedah Asia Pacific University of Technology and Innovation (APU), Kuala Lumpur HELP University, Kuala Lumpur International Medical University, Kuala Lumpur INTI International University, Laureate International Universities, Nilai Monash University Malaysia, Sunway Campus Multimedia University, Cyberjaya & Melaka Campus Nilai University, Nilai Sunway University, Bandar Sunway Taylor’s University, Subang Jaya University of Nottingham Malaysia Campus, Semenyih UCSI University, Kuala Lumpur Universiti Tunku Abdul Rahman, Perak / Sg. Long Campus Private University Colleges KDU University College, Petaling Jaya Tunku Abdul Rahman University College, Setapak Private Colleges INTI International College Subang, Subang Jaya KBU International College, Petaling Jaya Stamford College, Petaling Jaya Course Criteria (1) Undergraduate courses undertaken and completed in Malaysia only (including “3+0” foreign degree courses); (2) Accreditation by MQA (Course accreditation can be verified at MQR portal at the MQA website : www.mqa.gov.my); (3) Priority given to science stream courses. Type and Value of Award Loans or half-loan half-grants ranging from RM10,000 to RM30,000 per annum depending on courses undertaken. Eligibility (1) Malaysian Citizenship; (2) Genuine financial need and good academic results. Must possess relevant pre-university qualifications, eg. STPM or equivalent. Application forms can be downloaded from www.kuokfoundation.com or obtained from :- Kuok Foundation Berhad Undergraduate Awards (Private Universities / Colleges), Letter Box No. 110, 16th Floor UBN Tower, No. 10 Jalan P. -

FMHS Brochure
REGISTER NOW FACULTY OF MEDICINE AND HEALTH SCIENCES QS WORLD UNIVERSITY RANKINGS 2019 Malaysian universities that featured in the rankings UCSI’s Year of Milestones 2019 2018 Institution QS World University Rankings 2019 87 114 Universiti Malaya (UM) • Malaysia’s best private university. 184 230 Universiti Kebangsaan Malaysia (UKM) • The only private provider in Malaysia to make the top 500. • A top six university in Malaysia, along with the nation’s five 202 229 Universiti Putra Malaysia (UPM) research universities. 207 264 Universiti Sains Malaysia (USM) • One of only six Malaysian universities in the top 500 to receive a specific rank. 228 253 Universiti Teknologi Malaysia (UTM) • Malaysia’s most impressive debutant in the global rankings. 481 - UCSI University QS World Top 70 Under 50 (2019) 521-530 601-650 Universiti Teknologi Petronas (UTP) 601-650 - Taylor’s University • Malaysia’s best private university under 50 years old. • One of the world’s top 70 young universities. 601-650 701-750 Universiti Utara Malaysia (UUM) 651-700 701-750 International Islamic University Malaysia (IIUM) QS World University Rankings by Subject 2018 701-750 - Universiti Tenaga Nasional (UNITEN) • Malaysia’s best music school 751-800 751-800 Universiti Teknologi Mara (UiTM) • A top 100 university in the world for performing arts 801-1000 - Multimedia University (MMU) The 1st university in Asia to facilitate industry UCSI students obtain a placement for students merit-based government each year. scholarship or grant. OVER 35% UCSI is rated in Tier 5 (Emerging Universities) in of UCSI’s academic staff SETARA 2017, placing it on are PhD holders and a OF OUR CO-OP a par with established foreign further 17% are pursuing their doctorate. -

Dr. Fatihah Binti Mohd Universiti Malaysia
DR. FATIHAH BINTI MOHD UNIVERSITI MALAYSIA KELANTAN August 2020 Dr. Fatihah Binti Mohd Page 1 SECTION 1: PERSONAL AND SERVICE PARTICULARS Personal Information Date of Birth / Age : 1st Mac 1976 / 44 years Sex / Race / Status : Female / Malay / Married Nationality : Malaysian Email : [email protected] / [email protected] Academic Qualifications Qualification Institute Date Ph.D (Computer Sciences/ Data Mining) Universiti Malaysia Terengganu July, 2016 Master of Science (Intelligent Knowledge Base System) Universiti Utara Malaysia Sept, 2002 Bachelor of Science (Information Technology) Universiti Kebangsaan Malaysia May, 1999 Diploma (Information Technology) Kolej Sultan Zainal Abidin April, 1997 Employment History Position Discipline Institute Date Lecturer E-Commerce Faculty of Entrepreneurship And Business, Universiti Malaysia Jan, 2020 - Kelantan (UMK) present Part Time Computer Computer Science Department, Faculty of Ocean Engineering Sept, 2019- Lecturer Science Technology and Informatics, Universiti Malaysia Terengganu (UMT) Dec, 2019 Post-Doctoral Data Mining/ School of Informatics and Applied Mathematics, UMT July, 2017- DSS/ SE July, 2019 Part Time Computer Department of Computer Science, Faculty of Computer Science And Sept,2016- Lecturer Science Software Engineering, Universiti Malaysia Pahang (UMP) Dec,2016 Part Time Computer Faculty of Information Technology, Universiti Sultan Zainal Abidin July,2009- Lecturer Science (UNISZA) Nov,2009 Lecturer Computer Department of Computer Science, Kolej Teknologi Bestari (KTB) Jan,2003- Science (Currently: University College Bestari) June,2009 Lecturer Computer Department of Computer Science, Kolej Shah Putra (KSP) (Currently: Sept,1999- Science Widad University College) June,2001 SECTION 2: ACADEMIC INFORMATION Teaching Experience No Course Level 1. Introduction to Information Technology Diploma / Degree 2. E-Commerce Diploma / Degree 3. Basic Programming Diploma / Degree 4. -

Securing Study Funds
Securing study funds WHAT sets scholarship appli- cants apart are their person- al essays. Students must ensure that these essays are "personal" and not "copy and paste information" for applica- tions. Preparation for scholar- ship interviews is also key, said Star Education Fund and STPM results. representative Reuben Chan. Applicants will be shortlist- "Many students don't pre- ed in early April and pare enough for interviews. informed via e-mail, while "When they are asked to interviews will be held from speak about themselves, they April to June. should think through what they want to share and draft Giving back it out before going for the interview. Scholarship recipients "This is to ensure they give Ashley Sean Lai-Foenander Ashley (left) gives advice about the scholarships under the fund. concise answers. Interviews and Hilmy Osman volun- aren't very long. Some think teered at the fund's booth of an answer only then," he during the fair. said to an attentive crowd at Ashley, 20, and Hilmy, 22, the talk "Star Education Fund are currently pursuing a Scholarship Awards" on the Bachelor's of Biotechnology first day of the Star in Taylor's University and Education Fair 2019. Bachelor's in Quantity "At the Star Education Surveying in Heriot-Watt Fund, we want to help University Malaysia respec- deserving students and tively. invest in their lives because "I worked temporarily this is ultimately nation with the fund last year so I building," he said. felt I should use my experi- He suggested that students ence to help other students file their certificates chrono- who want to know more logically, from the most about the scholarships. -
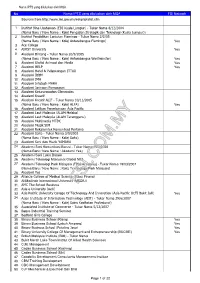
No Nama IPTS Yang Diluluskan Oleh MQA FSI Network Sources From
Nama IPTS yang diluluskan oleh MQA No Nama IPTS yang diluluskan oleh MQA FSI Network Sources from http://www.lan.gov.my/eskp/iptslist.cfm 1 Institut Bina Usahawan (EDI Kuala Lumpur) - Tukar Nama 8/12/2004 (Nama Baru / New Name : Kolej Pengajian Strategik dan Teknologi (Kuala Lumpur)) 2 Institut Pendidikan Lanjutan Flamingo - Tukar Nama 2/2/05 (Nama Baru / New Name : Kolej Antarabangsa Flamingo) Yes 3 Ace College 4 AIMST University Yes 5 Akademi Bintang - Tukar Nama 20/9/2005 (Nama Baru / New Name : Kolej Antarabangsa Westminster) Yes 6 Akademi Digital Animasi dan Media Yes 7 Akademi HELP Yes 8 Akademi Hotel & Pelancongan ITTAR 9 Akademi IBBM 10 Akademi IMH 11 Akademi Infotech MARA 12 Akademi Jaringan Pemasaran 13 Akademi Kejururawatan Gleneagles 14 Akademi Kreatif 15 Akademi Kreatif ALIF - Tukar Nama 10/11/2005 (Nama Baru / New Name : Kolej ALFA) Yes 16 Akademi Latihan Penerbangan Asia Pacific 17 Akademi Laut Malaysia (ALAM Melaka) 18 Akademi Laut Malaysia (ALAM Terengganu) 19 Akademi Multimedia MTDC 20 Akademi Muzik SIM 21 Akademi Rekabentuk Komunikasi Pertama 22 Akademi Saito - Tukar Nama 3/9/2003 (Nama Baru / New Name : Kolej Saito) 23 Akademi Seni dan Muzik YAMAHA 24 Akademi Seni Komunikasi Baruvi - Tukar Nama 15/2/2008 (Nama Baru / New Name : Akademi Yes) 25 Akademi Seni Lukis Dasein 26 Akademi Teknologi Maklumat Global NIIT 27 Akademi Teknologi Park Malaysia (TPM Academy) - Tukar Nama 19/03/2007 (Nama Baru / New Name : Kolej Technology Park Malaysia) 28 Akademi Yes 29 Allianze College of Medical Science (Pulau Pinang) 30 Al-Madinah -

Guidelines of Fundamental Research Grant Scheme (Frgs) (Amendment Year 2021)
DEPARTMENT OF HIGHER EDUCATION MINISTRY OF HIGHER EDUCATION GUIDELINES OF FUNDAMENTAL RESEARCH GRANT SCHEME (FRGS) (AMENDMENT YEAR 2021) BAHAGIAN KECEMERLANGAN PENYELIDIKAN IPT JABATAN PENDIDIKAN TINGGI KEMENTERIAN PENGAJIAN TINGGI ARAS 7, NO. 2, MENARA 2 JALAN P5/6, PRESINT 5 62200 PUTRAJAYA TEL. NO.: 03-8870 6974/6975 FAX NO.: 03-8870 6867 TABLE OF CONTENTS Vision and Mission of Fundamental Research 3 PART 1 (INTRODUCTION) 1.1 Introduction 4 1.2 Philosophy 4 1.3 Definition 4 1.4 Purpose 4 PART 2 (APPLICATION) 2.1 General terms of application 5 2.2 Research priority areas 6 2.3 Research duration 8 2.4 Ceiling of fund 8 2.5 Research output 9 2.6 Application rules 10 PART 3 (ASSESSMENT) 3.1 Application assessment 11 3.2 Assessment criteria 12 PART 4 (MONITORING) 4.1 Research implementation 13 4.2 Monitoring 13 PART 5 (FINANCIAL REGULATIONS) 5.1 Expenditure codes 15 5.2 Use of provisions 16 PART 6 (RESULTS) 6.1 Result announcement and fund distribution 18 6.2 Agreement document and contract 18 APPENDICES 19 Application Flow Chart Monitoring Flow Chart Scheduled Monitoring Cycle List of Higher Education Institutions (Appendix A) 2 VISION AND MISSION OF FUNDAMENTAL RESEARCH Vision Competitive fundamental research for knowledge transformation and national excellence. Mission Cultivate, empower and preserve high impact research capacity to generate knowledge that can contribute to talent development, intellectual growth, new technology invention and dynamic civilization. 3 1 PART 1 INTRODUCTION 1.1 INTRODUCTION The Guidelines of Fundamental Research Grant Scheme (FRGS) Amendment Year 2021 document is prepared as a reference and guide for application of research grant under the Department of Higher Education (JPT), Ministry of Higher Education (KPT). -

The Journal of Social Sciences Research ISSN(E): 2411-9458, ISSN(P): 2413-6670 Special Issue
The Journal of Social Sciences Research ISSN(e): 2411-9458, ISSN(p): 2413-6670 Special Issue. 2, pp: 800-806, 2018 Academic Research Publishing URL: https://arpgweb.com/journal/journal/7/special_issue Group DOI: https://doi.org/10.32861/jssr.spi2.800.806 Original Research Open Access The Perception of Malaysian Buddhist towards Islam in Malaysia Ahmad Faizuddin Ramli* PhD Candidate, Center for Akidah and Global Peace, Faculty of Islamic Studies, The National University of Malaysia / Lecturer at Department of Social Sciences, Faculty of Humanities and Social Sciences, Nilai University, Malaysia Jaffary Awang Assoc. Prof. Dr., Chairman, Center for Akidah and Global Peace, Faculty of Islamic Studies, The National University of Malaysia / Senior Fellow at The Institute of Islam Hadhari, The National University of Malaysia, Malaysia Abstract The existence of Muslim-Buddhist conflicts in the Southeast Asian region such as in Myanmar, Sri Lanka, Thailand is based on the perception that Islam is a threat to Buddhism. While in Malaysia, although the relationship between the Muslims and Buddhists remains in harmony, there is a certain perception among Buddhists towards Islam. Hence, this article will discuss the forms of Buddhism's perception of Islam in Malaysia. The study was qualitative using document analysis. The study found that particular group of Buddhists in Malaysia had a negative perception of Islam, particularly on the implementation of Islamization policy by the government and the Islamic resurgence movement in Malaysia. This perception is based on misunderstanding of Islam which is seen as a threat to the survival of Buddhists in practicing their teachings. The study recommends the empowerment of understanding between the religious adherents through Islamic-Buddhist dialogue at various levels of government and NGOs. -

Your Gateway to Malaysia International Student Guide Your Next Study Destination
Your Gateway to Malaysia International Student Guide Your next study destination. 2 INTERNATIONAL STUDENT GUIDE UOW MALAYSIA KDU 3 5+ stars rating university CONTENTS Where QS World University Rankings 2021 WHERE DOORS OPEN 4 — doors open MALAYSIA 6 Top 1% MALAYSIA AT A GLANCE 7 We’re here to open doors and University of Wollongong Australia THE HEART OF SOUTHEAST ASIA 8 ranking among the world’s support your choices while giving universities. MALAYSIA CULTURE 9 196th in the world – QS World University NATIONAL CELEBRATION you the freedom and resources to Rankings 2021 10 chase your dream career. TOP 10 MOST COLOURFUL FESTIVALS IN 11 — MALAYSIA MUST VISIT PLACES IN MALAYSIA 12 KUALA LUMPUR 14 TOURIST ATTRACTIONS 15 TOP 5 GREAT MALAYSIAN DISHES 16 TOP 5 MOST INSTAGRAMMABLE CAFES 17 PENANG 18 TOURIST ATTRACTIONS 19 WHERE TO EAT IN PENANG 20 5 BEST STREET FOOD IN PENANG 21 UNIVERSITY OF WOLLONGGONG Top 20 A TRULY GLOBAL UNIVERSITY 24 16th best modern university in the world. GLOBAL CAMPUSES 25 QS Top 50 Under 50 Rankings 2020 WHY STUDY IN MALAYSIA 26 — UOW MALAYSIA KDU 28 UOW MALAYSIA KDU CAMPUSES 29 From here to Top 200 ACADEMIC SCHOOLS 30 Rating for UOW graduates by global GRADUATE ATTRIBUTES 36 employers. every corner INDUSTRY PARTNERS 37 QS Graduate Employability Rankings 2020 CAMPUS FACILITIES 38 — UOW ACCOMMODATION 40 A globally recognised and respected INTERNATIONAL EXPERIENCE 42 degree from UOW is your passport Top 250 PARTNER UNIVERSITIES 43 to a world of opportunity. Ranking among the world’s best universities. 212th in the world – QS World University Rankings 2020, 201-250 band – Times Higher Education World University Rankings 2020, 220th – Academic Ranking of World Universities (ARWU) 2019 — 4 INTERNATIONAL STUDENT GUIDE UOW MALAYSIA KDU 5 Truly Asia Malaysia Situated in the midst of the Asia Pacific region, Malaysia enjoys a strategic location and a year-round tropical climate.