A Nestable Vectorized Templated Dual Number Library for C++11
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hyper-Dual Numbers for Exact Second-Derivative Calculations
49th AIAA Aerospace Sciences Meeting including the New Horizons Forum and Aerospace Exposition AIAA 2011-886 4 - 7 January 2011, Orlando, Florida The Development of Hyper-Dual Numbers for Exact Second-Derivative Calculations Jeffrey A. Fike∗ andJuanJ.Alonso† Department of Aeronautics and Astronautics Stanford University, Stanford, CA 94305 The complex-step approximation for the calculation of derivative information has two significant advantages: the formulation does not suffer from subtractive cancellation er- rors and it can provide exact derivatives without the need to search for an optimal step size. However, when used for the calculation of second derivatives that may be required for approximation and optimization methods, these advantages vanish. In this work, we develop a novel calculation method that can be used to obtain first (gradient) and sec- ond (Hessian) derivatives and that retains all the advantages of the complex-step method (accuracy and step-size independence). In order to accomplish this task, a new number system which we have named hyper-dual numbers and the corresponding arithmetic have been developed. The properties of this number system are derived and explored, and the formulation for derivative calculations is presented. Hyper-dual number arithmetic can be applied to arbitrarily complex software and allows the derivative calculations to be free from both truncation and subtractive cancellation errors. A numerical implementation on an unstructured, parallel, unsteady Reynolds-Averaged Navier Stokes (URANS) solver, -

Application of Dual Quaternions on Selected Problems
APPLICATION OF DUAL QUATERNIONS ON SELECTED PROBLEMS Jitka Prošková Dissertation thesis Supervisor: Doc. RNDr. Miroslav Láviˇcka, Ph.D. Plze ˇn, 2017 APLIKACE DUÁLNÍCH KVATERNIONU˚ NA VYBRANÉ PROBLÉMY Jitka Prošková Dizertaˇcní práce Školitel: Doc. RNDr. Miroslav Láviˇcka, Ph.D. Plze ˇn, 2017 Acknowledgement I would like to thank all the people who have supported me during my studies. Especially many thanks belong to my family for their moral and material support and my advisor doc. RNDr. Miroslav Láviˇcka, Ph.D. for his guidance. I hereby declare that this Ph.D. thesis is completely my own work and that I used only the cited sources. Plzeˇn, July 20, 2017, ........................... i Annotation In recent years, the study of quaternions has become an active research area of applied geometry, mainly due to an elegant and efficient possibility to represent using them ro- tations in three dimensional space. Thanks to their distinguished properties, quaternions are often used in computer graphics, inverse kinematics robotics or physics. Furthermore, dual quaternions are ordered pairs of quaternions. They are especially suitable for de- scribing rigid transformations, i.e., compositions of rotations and translations. It means that this structure can be considered as a very efficient tool for solving mathematical problems originated for instance in kinematics, bioinformatics or geodesy, i.e., whenever the motion of a rigid body defined as a continuous set of displacements is investigated. The main goal of this thesis is to provide a theoretical analysis and practical applications of the dual quaternions on the selected problems originated in geometric modelling and other sciences or various branches of technical practise. -

Vector Bundles and Brill–Noether Theory
MSRI Series Volume 28, 1995 Vector Bundles and Brill{Noether Theory SHIGERU MUKAI Abstract. After a quick review of the Picard variety and Brill–Noether theory, we generalize them to holomorphic rank-two vector bundles of canonical determinant over a compact Riemann surface. We propose sev- eral problems of Brill–Noether type for such bundles and announce some of our results concerning the Brill–Noether loci and Fano threefolds. For example, the locus of rank-two bundles of canonical determinant with five linearly independent global sections on a non-tetragonal curve of genus 7 is a smooth Fano threefold of genus 7. As a natural generalization of line bundles, vector bundles have two important roles in algebraic geometry. One is the moduli space. The moduli of vector bun- dles gives connections among different types of varieties, and sometimes yields new varieties that are difficult to describe by other means. The other is the linear system. In the same way as the classical construction of a map to a pro- jective space, a vector bundle gives rise to a rational map to a Grassmannian if it is generically generated by its global sections. In this article, we shall de- scribe some results for which vector bundles play such roles. They are obtained from an attempt to generalize Brill–Noether theory of special divisors, reviewed in Section 2, to vector bundles. Our main subject is rank-two vector bundles with canonical determinant on a curve C with as many global sections as pos- sible: especially their moduli and the Grassmannian embeddings of C by them (Section 4). -

Exploring Mathematical Objects from Custom-Tailored Mathematical Universes
Exploring mathematical objects from custom-tailored mathematical universes Ingo Blechschmidt Abstract Toposes can be pictured as mathematical universes. Besides the standard topos, in which most of mathematics unfolds, there is a colorful host of alternate toposes in which mathematics plays out slightly differently. For instance, there are toposes in which the axiom of choice and the intermediate value theorem from undergraduate calculus fail. The purpose of this contribution is to give a glimpse of the toposophic landscape, presenting several specific toposes and exploring their peculiar properties, and to explicate how toposes provide distinct lenses through which the usual mathematical objects of the standard topos can be viewed. Key words: topos theory, realism debate, well-adapted language, constructive mathematics Toposes can be pictured as mathematical universes in which we can do mathematics. Most mathematicians spend all their professional life in just a single topos, the so-called standard topos. However, besides the standard topos, there is a colorful host of alternate toposes which are just as worthy of mathematical study and in which mathematics plays out slightly differently (Figure 1). For instance, there are toposes in which the axiom of choice and the intermediate value theorem from undergraduate calculus fail, toposes in which any function R ! R is continuous and toposes in which infinitesimal numbers exist. The purpose of this contribution is twofold. 1. We give a glimpse of the toposophic landscape, presenting several specific toposes and exploring their peculiar properties. 2. We explicate how toposes provide distinct lenses through which the usual mathe- matical objects of the standard topos can be viewed. -

Math Book from Wikipedia
Math book From Wikipedia PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Mon, 25 Jul 2011 10:39:12 UTC Contents Articles 0.999... 1 1 (number) 20 Portal:Mathematics 24 Signed zero 29 Integer 32 Real number 36 References Article Sources and Contributors 44 Image Sources, Licenses and Contributors 46 Article Licenses License 48 0.999... 1 0.999... In mathematics, the repeating decimal 0.999... (which may also be written as 0.9, , 0.(9), or as 0. followed by any number of 9s in the repeating decimal) denotes a real number that can be shown to be the number one. In other words, the symbols 0.999... and 1 represent the same number. Proofs of this equality have been formulated with varying degrees of mathematical rigour, taking into account preferred development of the real numbers, background assumptions, historical context, and target audience. That certain real numbers can be represented by more than one digit string is not limited to the decimal system. The same phenomenon occurs in all integer bases, and mathematicians have also quantified the ways of writing 1 in non-integer bases. Nor is this phenomenon unique to 1: every nonzero, terminating decimal has a twin with trailing 9s, such as 8.32 and 8.31999... The terminating decimal is simpler and is almost always the preferred representation, contributing to a misconception that it is the only representation. The non-terminating form is more convenient for understanding the decimal expansions of certain fractions and, in base three, for the structure of the ternary Cantor set, a simple fractal. -

Generalisations of Singular Value Decomposition to Dual-Numbered
Generalisations of Singular Value Decomposition to dual-numbered matrices Ran Gutin Department of Computer Science Imperial College London June 10, 2021 Abstract We present two generalisations of Singular Value Decomposition from real-numbered matrices to dual-numbered matrices. We prove that every dual-numbered matrix has both types of SVD. Both of our generalisations are motivated by applications, either to geometry or to mechanics. Keywords: singular value decomposition; linear algebra; dual num- bers 1 Introduction In this paper, we consider two possible generalisations of Singular Value Decom- position (T -SVD and -SVD) to matrices over the ring of dual numbers. We prove that both generalisations∗ always exist. Both types of SVD are motivated by applications. A dual number is a number of the form a + bǫ where a,b R and ǫ2 = 0. The dual numbers form a commutative, assocative and unital∈ algebra over the real numbers. Let D denote the dual numbers, and Mn(D) denote the ring of n n dual-numbered matrices. × arXiv:2007.09693v7 [math.RA] 9 Jun 2021 Dual numbers have applications in automatic differentiation [4], mechanics (via screw theory, see [1]), computer graphics (via the dual quaternion algebra [5]), and geometry [10]. Our paper is motivated by the applications in geometry described in Section 1.1 and in mechanics given in Section 1.2. Our main results are the existence of the T -SVD and the existence of the -SVD. T -SVD is a generalisation of Singular Value Decomposition that resembles∗ that over real numbers, while -SVD is a generalisation of SVD that resembles that over complex numbers. -

Dual Quaternion Sample Reduction for SE(2) Estimation
Dual Quaternion Sample Reduction for SE(2) Estimation Kailai Li, Florian Pfaff, and Uwe D. Hanebeck Intelligent Sensor-Actuator-Systems Laboratory (ISAS) Institute for Anthropomatics and Robotics Karlsruhe Institute of Technology (KIT), Germany [email protected], fl[email protected], [email protected] Abstract—We present a novel sample reduction scheme for random variables belonging to the SE(2) group by means of Dirac mixture approximation. For this, dual quaternions are employed to represent uncertain planar transformations. The Cramer–von´ Mises distance is modified as a smooth metric to measure the statistical distance between Dirac mixtures on the manifold of planar dual quaternions. Samples of reduced size are then ob- tained by minimizing the probability divergence via Riemannian optimization while interpreting the correlation between rotation and translation. We further deploy the proposed scheme for non- parametric modeling of estimates for nonlinear SE(2) estimation. Simulations show superior tracking performance of the sample reduction-based filter compared with Monte Carlo-based as well as parametric model-based planar dual quaternion filters. Figure 1: Examples of the proposed sample reduction tech- I. INTRODUCTION nique for planar rigid motions. Here, 2000 random samples Estimation of planar motions is ubiquitous and play a (yellow) drawn from different underlying distributions are fundamental role in many application scenarios, such as optimally approximated by 20 samples (blue) on the manifold odometry and scene reconstruction, object tracking as well of planar dual quaternions. as remote sensing, etc [1]–[5]. Planar motions, incorporating both rotations and translations on a plane, are mathematically described by elements belonging to the two-dimensional spe- which can be easily violated under large noise levels (e.g., cial Euclidean group SE(2). -

Design of a Customized Multi-Directional Layered Deposition System Based on Part Geometry
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by UT Digital Repository Design of a customized multi-directional layered deposition system based on part geometry. Prabhjot Singh, Yong-Mo Moon, Debasish Dutta, Sridhar Kota Abstract Multi-Direction Layered Deposition (MDLD) reduces the need for supports by depositing on a part along multiple directions. This requires the design of a new mechanism to re- orient the part, such that the deposition head can approach from different orientations. We present a customized compliant parallel kinematic machine design configured to deposit a set of part geometries. Relationships between the process planning for the MDLD of a part geometry and considerations in the design of the customized machine mechanism are illustrated. MDLD process planning is based on progressive part decomposition and kinematic machine design uses dual number algebra and screw theory. 1. Introduction The past decade has seen the development of numerous Layered Manufacturing (LM) techniques. The main advantage afforded by LM is its ability to produce geometrically complex parts without specialized tooling in a relatively short period of time. LM processes are characterized by the need for sacrificial structures to support overhanging regions of the part. This necessitates time consuming post- processing and degrades part quality. Multi-Direction Layered Deposition (MDLD) Systems such as [3][4][5][7] build parts without supports by depositing a part along multiple directions. Depending on the process, either the deposition nozzle or the base table has multi-axis kinematics (refer Figure 1). (b) (a) Figure 1: (a) Deposition Table with rotational and translational actuation (b) Deposition nozzle mounted on a multi-axis robotic arm. -

Dual Quaternions in Spatial Kinematics in an Algebraic Sense
Turk J Math 32 (2008) , 373 – 391. c TUB¨ ITAK˙ Dual Quaternions in Spatial Kinematics in an Algebraic Sense Bedia Akyar Abstract This paper presents the finite spatial displacements and spatial screw motions by using dual quaternions and Hamilton operators. The representations are considered as 4 × 4 matrices and the relative motion for three dual spheres is considered in terms of Hamilton operators for a dual quaternion. The relation between Hamilton operators and the transformation matrix has been given in a different way. By considering operations on screw motions, representation of spatial displacements is also given. Key Words: Dual quaternions, Hamilton operators, Lie algebras. 1. Introduction The matrix representation of spatial displacements of rigid bodies has an important role in kinematics and the mathematical description of displacements. Veldkamp and Yang-Freudenstein investigated the use of dual numbers, dual numbers matrix and dual quaternions in instantaneous spatial kinematics in [9] and [10], respectively. In [10], an application of dual quaternion algebra to the analysis of spatial mechanisms was given. A comparison of representations of general spatial motion was given by Rooney in [8]. Hiller- Woernle worked on a unified representation of spatial displacements. In their paper [7], the representation is based on the screw displacement pair, i.e., the dual number extension of the rotational displacement pair, and consists of the dual unit vector of the screw axis AMS Mathematics Subject Classification: 53A17, 53A25, 70B10. 373 AKYAR and the associate dual angle of the amplitude. Chevallier gave a unified algebraic approach to mathematical methods in kinematics in [4]. This approach requires screw theory, dual numbers and Lie groups. -

LIE ALGEBRAS ARE INFINITESIMAL GROUPS Throughout K Is a Field
LIE ALGEBRAS ARE INFINITESIMAL GROUPS RUDOLF TANGE Throughout k is a field and δ is a “dual number” satisfying δ2 = 0. Furthermore g is a Lie algebra over k which is the Lie algebra of a group G. We denote the identity of G by I. Whenever X ∈ g = TI (G), the tangent space of G at I, we consider the corresponding group element I + δX of which you should think as “I with an infinitesimal bit added in the direction X”. You should think of δ as being a very small number of k = R and calculate upto the first order. 2 More formally, δ is the image of δ0 in R = R(δ) := k[δ0]/(δ0), the quotient 2 of the polynomial ring k[δ0] by the ideal (δ0), and I + δX is an element of G(R), the points of G over R.1 The commutator Now we embed G into some GLn. Our computations below will take place in Matn(R). The inverse of I + δX is I − δX: (I + δX)(I − δX) = I − δX + δX − δ2X2 = I. Note that the elements I + δX form a commutative subgroup of G(R). To capture something of the noncommutativity we need to look at second order terms. To do this we add another dual number η to our ring R, that 2 2 is, we work with the ring R = R(δ, η) := k[δ0, η0]/(δ0, η0), where we denote the images of δ0 and η0 by δ and η. Let X, Y ∈ g. We compute the group commutator of I + δX and I + δY : (I + δX)(I + ηY )(I − δX)(I − ηY ) = (I + ηY + δX + δηXY )(I − ηY − δX + δηXY ) = I − ηY − δX + δηXY + ηY − δηY X + δX − δηXY + δηXY = I + δη(XY − YX) = I + δη[X, Y ]. -

Symmetry, Geometry, and Quantization with Hypercomplex
SYMMETRY, GEOMETRY, AND QUANTIZATION WITH HYPERCOMPLEX NUMBERS VLADIMIR V. KISIL Abstract. These notes describe some links between the group SL2(R), the Heisenberg group and hypercomplex numbers – complex, dual and double num- bers. Relations between quantum and classical mechanics are clarified in this framework. In particular, classical mechanics can be obtained as a theory with noncommutative observables and a non-zero Planck constant if we replace complex numbers in quantum mechanics by dual numbers. Our considera- tion is based on induced representations which are build from complex-/dual- /double-valued characters. Dynamic equations, rules of additions of proba- bilities, ladder operators and uncertainty relations are discussed. Finally, we prove a Calder´on–Vaillancourt-type norm estimation for relative convolutions. Contents Introduction 2 1. Preview: Quantum and Classical Mechanics 3 1.1. Axioms of Mechanics 3 1.2. “Algebra” of Observables 3 1.3. Non-Essential Noncommutativity 4 1.4. Quantum Mechanics from the Heisenberg Group 5 1.5. Classical Noncommutativity 6 1.6. Summary 8 2. Groups, Homogeneous Spaces and Hypercomplex Numbers 9 2.1. The Group SL2(R) and Its Subgroups 9 2.2. Action of SL2(R) as a Source of Hypercomplex Numbers 9 2.3. Orbits of the Subgroup Actions 11 2.4. The Heisenberg Group and Symplectomorphisms 13 3. Linear Representations and Hypercomplex Numbers 15 3.1. Hypercomplex Characters 15 3.2. Induced Representations 16 3.3. Similarity and Correspondence: Ladder Operators 18 3.4. Ladder Operators 19 arXiv:1611.05650v1 [math-ph] 17 Nov 2016 3.5. Induced Representations of the Heisenberg Group 21 4. -
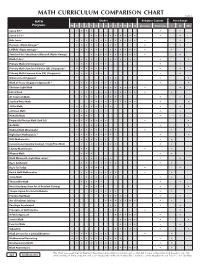
Math Curriculum Comparison Chart
MATH CURRICULUM COMPARISON CHART ©2018 MATH Grades Religious Content Price Range Programs PK K 1 2 3 4 5 6 7 8 9 10 11 12 Christian N/Secular $ $$ $$$ Saxon K-3 * • • • • • • Saxon 3-12 * • • • • • • • • • • • • Bob Jones • • • • • • • • • • • • • • • Horizons (Alpha Omega) * • • • • • • • • • • • LIFEPAC (Alpha Omega) * • • • • • • • • • • • • • • • Switched-On Schoolhouse/Monarch (Alpha Omega) • • • • • • • • • • • • Math•U•See * • • • • • • • • • • • • • • • • Primary Math (US) (Singapore) * • • • • • • • • • Primary Math Standards Edition (SE) (Singapore) * • • • • • • • • • Primary Math Common Core (CC) (Singapore) • • • • • • • • Dimensions (Singapore) • • • • • Math in Focus (Singapore Approach) * • • • • • • • • • • • Christian Light Math • • • • • • • • • • • • • • Life of Fred • • • • • • • • • • • • • • A+ Tutorsoft Math • • • • • • • • • • • Starline Press Math • • • • • • • • • • • • ShillerMath • • • • • • • • • • • enVision Math • • • • • • • • • McRuffy Math • • • • • • Purposeful Design Math (2nd Ed.) • • • • • • • • • Go Math • • • • • • • • • Making Math Meaningful • • • • • • • • • • • RightStart Mathematics * • • • • • • • • • • MCP Mathematics • • • • • • • • • Conventional (Spunky Donkey) / Study Time Math • • • • • • • • • • Liberty Mathematics • • • • • Miquon Math • • • • • Math Mammoth (Light Blue series) * • • • • • • • • • Ray's Arithmetic • • • • • • • • • • Ray's for Today • • • • • • • Rod & Staff Mathematics • • • • • • • • • • Jump Math • • • • • • • • • • ThemeVille Math • • • • • • • Beast Academy (from