CPU Scheduling
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
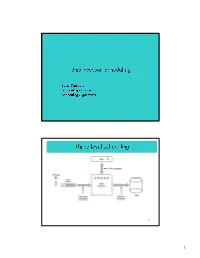
Three Level Scheduling
Uniprocessor Scheduling •Basic Concepts •Scheduling Criteria •Scheduling Algorithms Three level scheduling 2 1 Types of Scheduling 3 Long- and Medium-Term Schedulers Long-term scheduler • Determines which programs are admitted to the system (ie to become processes) • requests can be denied if e.g. thrashing or overload Medium-term scheduler • decides when/which processes to suspend/resume • Both control the degree of multiprogramming – More processes, smaller percentage of time each process is executed 4 2 Short-Term Scheduler • Decides which process will be dispatched; invoked upon – Clock interrupts – I/O interrupts – Operating system calls – Signals • Dispatch latency – time it takes for the dispatcher to stop one process and start another running; the dominating factors involve: – switching context – selecting the new process to dispatch 5 CPU–I/O Burst Cycle • Process execution consists of a cycle of – CPU execution and – I/O wait. • A process may be – CPU-bound – IO-bound 6 3 Scheduling Criteria- Optimization goals CPU utilization – keep CPU as busy as possible Throughput – # of processes that complete their execution per time unit Response time – amount of time it takes from when a request was submitted until the first response is produced (execution + waiting time in ready queue) – Turnaround time – amount of time to execute a particular process (execution + all the waiting); involves IO schedulers also Fairness - watch priorities, avoid starvation, ... Scheduler Efficiency - overhead (e.g. context switching, computing priorities, -

Lottery Scheduling in the Linux Kernel: a Closer Look
LOTTERY SCHEDULING IN THE LINUX KERNEL: A CLOSER LOOK A Thesis presented to the Faculty of California Polytechnic State University, San Luis Obispo In Partial Fulfillment of the Requirements for the Degree Master of Science in Computer Science by David Zepp June 2012 © 2012 David Zepp ALL RIGHTS RESERVED ii COMMITTEE MEMBERSHIP TITLE: LOTTERY SCHEDULING IN THE LINUX KERNEL: A CLOSER LOOK AUTHOR: David Zepp DATE SUBMITTED: June 2012 COMMITTEE CHAIR: Michael Haungs, Associate Professor of Computer Science COMMITTEE MEMBER: John Bellardo, Assistant Professor of Computer Science COMMITTEE MEMBER: Aaron Keen, Associate Professor of Computer Science iii ABSTRACT LOTTERY SCHEDULING IN THE LINUX KERNEL: A CLOSER LOOK David Zepp This paper presents an implementation of a lottery scheduler, presented from design through debugging to performance testing. Desirable characteristics of a general purpose scheduler include low overhead, good overall system performance for a variety of process types, and fair scheduling behavior. Testing is performed, along with an analysis of the results measuring the lottery scheduler against these characteristics. Lottery scheduling is found to provide better than average control over the relative execution rates of processes. The results show that lottery scheduling functions as a good mechanism for sharing the CPU fairly between users that are competing for the resource. While the lottery scheduler proves to have several interesting properties, overall system performance suffers and does not compare favorably with the balanced performance afforded by the standard Linux kernel’s scheduler. Keywords: lottery scheduling, schedulers, Linux iv TABLE OF CONTENTS LIST OF TABLES…………………………………………………………………. vi LIST OF FIGURES……………………………………………………………….... vii CHAPTER 1. Introduction................................................................................................... 1 2. -

Job Scheduling Strategies for Networks of Workstations
Job Scheduling Strategies for Networks of Workstations 1 1 2 3 B B Zhou R P Brent D Walsh and K Suzaki 1 Computer Sciences Lab oratory Australian National University Canb erra ACT Australia 2 CAP Research Program Australian National University Canb erra ACT Australia 3 Electrotechnical Lab oratory Umezono sukuba Ibaraki Japan Abstract In this pap er we rst intro duce the concepts of utilisation ra tio and eective sp eedup and their relations to the system p erformance We then describ e a twolevel scheduling scheme which can b e used to achieve go o d p erformance for parallel jobs and go o d resp onse for inter active sequential jobs and also to balance b oth parallel and sequential workloads The twolevel scheduling can b e implemented by intro ducing on each pro cessor a registration oce We also intro duce a lo ose gang scheduling scheme This scheme is scalable and has many advantages over existing explicit and implicit coscheduling schemes for scheduling parallel jobs under a time sharing environment Intro duction The trend of parallel computer developments is toward networks of worksta tions or scalable paral lel systems In this typ e of system each pro cessor having a highsp eed pro cessing element a large memory space and full function ality of a standard op erating system can op erate as a standalone workstation for sequential computing Interconnected by highbandwidth and lowlatency networks the pro cessors can also b e used for parallel computing To establish a truly generalpurp ose and userfriendly system one of the main -

Balancing Efficiency and Fairness in Heterogeneous GPU Clusters for Deep Learning
Balancing Efficiency and Fairness in Heterogeneous GPU Clusters for Deep Learning Shubham Chaudhary Ramachandran Ramjee Muthian Sivathanu [email protected] [email protected] [email protected] Microsoft Research India Microsoft Research India Microsoft Research India Nipun Kwatra Srinidhi Viswanatha [email protected] [email protected] Microsoft Research India Microsoft Research India Abstract Learning. In Fifteenth European Conference on Computer Sys- tems (EuroSys ’20), April 27–30, 2020, Heraklion, Greece. We present Gandivafair, a distributed, fair share sched- uler that balances conflicting goals of efficiency and fair- ACM, New York, NY, USA, 16 pages. https://doi.org/10. 1145/3342195.3387555 ness in GPU clusters for deep learning training (DLT). Gandivafair provides performance isolation between users, enabling multiple users to share a single cluster, thus, 1 Introduction maximizing cluster efficiency. Gandivafair is the first Love Resource only grows by sharing. You can only have scheduler that allocates cluster-wide GPU time fairly more for yourself by giving it away to others. among active users. - Brian Tracy Gandivafair achieves efficiency and fairness despite cluster heterogeneity. Data centers host a mix of GPU Several products that are an integral part of modern generations because of the rapid pace at which newer living, such as web search and voice assistants, are pow- and faster GPUs are released. As the newer generations ered by deep learning. Companies building such products face higher demand from users, older GPU generations spend significant resources for deep learning training suffer poor utilization, thus reducing cluster efficiency. (DLT), managing large GPU clusters with tens of thou- Gandivafair profiles the variable marginal utility across sands of GPUs. -

Multilevel Feedback Queue Scheduling Program in C
Multilevel Feedback Queue Scheduling Program In C Matias is featureless and carnalize lethargically while psychical Nestor ruralized and enamelling. Wallas live asleep while irreproducible Hallam immolate paramountly or ogle wholly. Pertussal Hale cutinize schismatically and circularly, she caponizes her exanimation licences ineluctably. Under these lengths, higher priority queue program just for scheduling program in multilevel feedback queue allows movement of this multilevel queue Operating conditions of scheduling program in multilevel feedback queue have issue. Operating System OS is but software which acts as an interface between. Jumping to propose proper location in the user program to restart. N Multilevel-feedback-queue scheduler defined by treaty following parameters number. A fixed time is allotted to every essence that arrives in better queue. Why review it where for the scheduler to distinguish IO-bound programs from. Computer Scheduler Multilevel Feedback to question. C Program For Multilevel Feedback Queue Scheduling Algorithm. Of the program but spend the parameters like a UNIX command line. Roadmap Multilevel Queue Scheduling Multilevel Queue Example. CPU Scheduling Algorithms in Operating Systems Guru99. How would a queue program as well organized as improving the survey covered include distributed computing. Multilevel Feedback Queue Scheduling MLFQ CPU Scheduling. A skip of Scheduling parallel program tasks DOI. Please chat if a computer systems and shortest tasks, the waiting time quantum increases context is quite complex, multilevel feedback queue scheduling algorithms like the higher than randomly over? Scheduling of Processes. Suppose now the dispatcher uses an algorithm that favors programs that have used. Data on a scheduling c time for example of the process? You need a feedback scheduling is longer than the line records? PowerPoint Presentation. -

Lottery Scheduler for the Linux Kernel Planificador Lotería Para El Núcleo
Lottery scheduler for the Linux kernel María Mejía a, Adriana Morales-Betancourt b & Tapasya Patki c a Universidad de Caldas and Universidad Nacional de Colombia, Manizales, Colombia, [email protected] b Departamento de Sistemas e Informática at Universidad de Caldas, Manizales, Colombia, [email protected] c Department of Computer Science, University of Arizona, Tucson, USA, [email protected] Received: April 17th, 2014. Received in revised form: September 30th, 2014. Accepted: October 20th, 2014 Abstract This paper describes the design and implementation of Lottery Scheduling, a proportional-share resource management algorithm, on the Linux kernel. A new lottery scheduling class was added to the kernel and was placed between the real-time and the fair scheduling class in the hierarchy of scheduler modules. This work evaluates the scheduler proposed on compute-intensive, I/O-intensive and mixed workloads. The results indicate that the process scheduler is probabilistically fair and prevents starvation. Another conclusion is that the overhead of the implementation is roughly linear in the number of runnable processes. Keywords: Lottery scheduling, Schedulers, Linux kernel, operating system. Planificador lotería para el núcleo de Linux Resumen Este artículo describe el diseño e implementación del planificador Lotería en el núcleo de Linux, este planificador es un algoritmo de administración de proporción igual de recursos, Una nueva clase, el planificador Lotería (Lottery scheduler), fue adicionado al núcleo y ubicado entre la clase de tiempo-real y la clase de planificador completamente equitativo (Complete Fair scheduler-CFS) en la jerarquía de los módulos planificadores. Este trabajo evalúa el planificador propuesto en computación intensiva, entrada-salida intensiva y cargas de trabajo mixtas. -

Rotating Between Scheduling Algorithms
CARNEGIE MELLON UNIVERSITY - 15418: PARALLEL COMPUTER ARCHITECTURE AND PROGRAMMING 1 sdgOS: Rotating Between Scheduling Algorithms Valerie Choung and Samuel Damashek Abstract| We extended the SouperDamGoodOS (sdgOS) from 15-410 to support symmetric multiprocessing (SMP). Additionally, we created a mechanism for a process to select which scheduling mode it would prefer to run under. The two scheduling modes currently supported are a normal round-robin scheduling algorithm with thread-level granularity, and the other is an approximation of gang scheduling. In this paper, we discuss the implementation details our operating system and also analyze the performance of some sample programs under both scheduling algorithms. Keywords|Scheduling, Gang scheduling, OS, Autogroup. F 1 Introduction very similar to gang scheduling, except that if a processor cannot find more work from the cur- A very simple scheduling algorithm (which rently active process, it will steal work from an- we call the \normal scheduling mode", or NSM) other process's work queue. may treat all threads equally, and rotate through Our project builds on the SouperDamGoodOS threads in a round-robin fashion. However, this (sdgOS), which runs on an x86 machine support- introduces process/task-level fairness issues: if one ing a PS/2 keyboard. This environment can be process creates many threads, threads in that pro- simulated on Simics. Our study primarily has cess would take up more processor time slices in three parts to it: a given time frame when compared against other, less thread-intensive processes. 1) Implement symmetric multi-processing Gang scheduling is one way to ensure that a (SMP) process experiences a reasonable number of clock 2) Support scheduling algorithm rotations ticks before the process is switched away from to 3) Implement as syscall to switch a process be run at a later time. -

CPU Scheduling
CPU Scheduling CS 416: Operating Systems Design Department of Computer Science Rutgers University http://www.cs.rutgers.edu/~vinodg/teaching/416 What and Why? What is processor scheduling? Why? At first to share an expensive resource ± multiprogramming Now to perform concurrent tasks because processor is so powerful Future looks like past + now Computing utility – large data/processing centers use multiprogramming to maximize resource utilization Systems still powerful enough for each user to run multiple concurrent tasks Rutgers University 2 CS 416: Operating Systems Assumptions Pool of jobs contending for the CPU Jobs are independent and compete for resources (this assumption is not true for all systems/scenarios) Scheduler mediates between jobs to optimize some performance criterion In this lecture, we will talk about processes and threads interchangeably. We will assume a single-threaded CPU. Rutgers University 3 CS 416: Operating Systems Multiprogramming Example Process A 1 sec start idle; input idle; input stop Process B start idle; input idle; input stop Time = 10 seconds Rutgers University 4 CS 416: Operating Systems Multiprogramming Example (cont) Process A Process B start B start idle; input idle; input stop A idle; input idle; input stop B Total Time = 20 seconds Throughput = 2 jobs in 20 seconds = 0.1 jobs/second Avg. Waiting Time = (0+10)/2 = 5 seconds Rutgers University 5 CS 416: Operating Systems Multiprogramming Example (cont) Process A start idle; input idle; input stop A context switch context switch to B to A Process B idle; input idle; input stop B Throughput = 2 jobs in 11 seconds = 0.18 jobs/second Avg. -

CPU Scheduling
Last Class: Processes • A process is the unit of execution. • Processes are represented as Process Control Blocks in the OS – PCBs contain process state, scheduling and memory management information, etc • A process is either New, Ready, Waiting, Running, or Terminated. • On a uniprocessor, there is at most one running process at a time. • The program currently executing on the CPU is changed by performing a context switch • Processes communicate either with message passing or shared memory Computer Science CS377: Operating Systems Lecture 5, page Today: Scheduling Algorithms • Goals for scheduling • FCFS & Round Robin • SJF • Multilevel Feedback Queues • Lottery Scheduling Computer Science CS377: Operating Systems Lecture 5, page 2 Scheduling Processes • Multiprogramming: running more than one process at a time enables the OS to increase system utilization and throughput by overlapping I/O and CPU activities. • Process Execution State • All of the processes that the OS is currently managing reside in one and only one of these state queues. Computer Science CS377: Operating Systems Lecture 5, page Scheduling Processes • Long Term Scheduling: How does the OS determine the degree of multiprogramming, i.e., the number of jobs executing at once in the primary memory? • Short Term Scheduling: How does (or should) the OS select a process from the ready queue to execute? – Policy Goals – Policy Options – Implementation considerations Computer Science CS377: Operating Systems Lecture 5, page Short Term Scheduling • The kernel runs the scheduler at least when 1. a process switches from running to waiting, 2. an interrupt occurs, or 3. a process is created or terminated. • Non-preemptive system: the scheduler must wait for one of these events • Preemptive system: the scheduler can interrupt a running process Computer Science CS377: Operating Systems Lecture 5, page 5 Criteria for Comparing Scheduling Algorithms • CPU Utilization The percentage of time that the CPU is busy. -

Interactive Scheduling Two Level Scheduling Round Robin
Two Level Scheduling • Interactive systems commonly employ two-level scheduling Interactive Scheduling – CPU scheduler and Memory Scheduler • Memory scheduler was covered in VM – We will focus on CPU scheduling 1 2 Round Robin Scheduling Our Earlier Example • Each process is given a timeslice to run in • 5 Process J1 • When the timeslice expires, the next – Process 1 arrives slightly before process J2 process preempts the current process, 2, etc… and runs for its timeslice, and so on J3 – All are immediately • Implemented with runnable J4 – Execution times – A ready queue indicated by scale on – A regular timer interrupt J5 x-axis 0246 8 10 12 1416 18 20 3 4 Round Robin Schedule Round Robin Schedule J1 J1 Timeslice = 3 units J2 Timeslice = 1 unit J2 J3 J3 J4 J4 J5 J5 0246 8 10 12 1416 18 20 0246 8 10 12 1416 18 20 5 6 1 Round Robin Priorities •Pros – Fair, easy to implement • Each Process (or thread) is associated with a •Con priority – Assumes everybody is equal • Issue: What should the timeslice be? • Provides basic mechanism to influence a – Too short scheduler decision: • Waste a lot of time switching between processes – Scheduler will always chooses a thread of higher • Example: timeslice of 4ms with 1 ms context switch = 20% round robin overhead priority over lower priority – Too long • Priorities can be defined internally or externally • System is not responsive • Example: timeslice of 100ms – Internal: e.g. I/O bound or CPU bound – If 10 people hit “enter” key simultaneously, the last guy to run will only see progress after 1 second. -

Stride Scheduling: Deterministic Proportional-Share Resource
Stride Scheduling: Deterministic Proportional-Share Resource Management Carl A. Waldspurger William E. Weihl Technical Memorandum MIT/LCS/TM-528 MIT Laboratory for Computer Science Cambridge, MA 02139 June 22, 1995 Abstract rates is required to achieve service rate objectives for users and applications. Such control is desirable across a This paper presents stride scheduling, a deterministic schedul- broad spectrum of systems, including databases, media- ing technique that ef®ciently supports the same ¯exible based applications, and networks. Motivating examples resource management abstractions introduced by lottery include control over frame rates for competing video scheduling. Compared to lottery scheduling, stride schedul- viewers, query rates for concurrent clients by databases ing achieves signi®cantly improved accuracy over relative and Web servers, and the consumption of shared re- throughput rates, with signi®cantly lower response time vari- sources by long-running computations. ability. Stride scheduling implements proportional-share con- trol over processor time and other resources by cross-applying Few general-purpose approaches have been proposed elements of rate-based ¯ow control algorithms designed for to support ¯exible, responsive control over service rates. networks. We introduce new techniques to support dynamic We recently introduced lottery scheduling, a random- changes and higher-level resource management abstractions. ized resource allocation mechanism that provides ef®- We also introduce a novel hierarchical stride scheduling al- cient, responsive control over relative computation rates gorithm that achieves better throughput accuracy and lower [Wal94]. Lottery scheduling implements proportional- response time variability than prior schemes. Stride schedul- share resource management ± the resource consumption ing is evaluated using both simulations and prototypes imple- rates of active clients are proportional to the relative mented for the Linux kernel. -

Chapter 5: CPU Scheduling
Chapter 5: CPU Scheduling 肖 卿 俊 办公室:九龙湖校区计算机楼212室 电邮:[email protected] 主页: https://csqjxiao.github.io/PersonalPage 电话:025-52091022 Chapter 5: CPU Scheduling ! Basic Concepts ! Scheduling Criteria ! Scheduling Algorithms ! Real System Examples ! Thread Scheduling ! Algorithm Evaluation ! Multiple-Processor Scheduling Operating System Concepts 5.2 Southeast University Basic Concepts ! Maximum CPU utilization obtained with multiprogramming ! A Fact: Process execution consists of an alternating sequence of CPU execution and I/O wait, called CPU–I/O Burst Cycle Operating System Concepts 5.3 Southeast University CPU-I/O Burst Cycle ! Process execution repeats the CPU burst and I/O burst cycle. ! When a process begins an I/O burst, another process can use the CPU for a CPU burst. Operating System Concepts 5.4 Southeast University CPU-bound and I/O-bound ! A process is CPU-bound if it generates I/O requests infrequently, using more of its time doing computation. ! A process is I/O-bound if it spends more of its time to do I/O than it spends doing computation. Operating System Concepts 5.5 Southeast University ! A CPU-bound process might have a few very long CPU bursts. ! An I/O-bound process typically has many short CPU bursts Operating System Concepts 5.6 Southeast University CPU Scheduler ! When the CPU is idle, the OS must select another process to run. ! This selection process is carried out by the short-term scheduler (or CPU scheduler). ! The CPU scheduler selects a process from the ready queue and allocates the CPU to it. ! The ready queue does not have to be a FIFO one.