COS 318: Operating Systems CPU Scheduling
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Comprehensive Review for Central Processing Unit Scheduling Algorithm
IJCSI International Journal of Computer Science Issues, Vol. 10, Issue 1, No 2, January 2013 ISSN (Print): 1694-0784 | ISSN (Online): 1694-0814 www.IJCSI.org 353 A Comprehensive Review for Central Processing Unit Scheduling Algorithm Ryan Richard Guadaña1, Maria Rona Perez2 and Larry Rutaquio Jr.3 1 Computer Studies and System Department, University of the East Caloocan City, 1400, Philippines 2 Computer Studies and System Department, University of the East Caloocan City, 1400, Philippines 3 Computer Studies and System Department, University of the East Caloocan City, 1400, Philippines Abstract when an attempt is made to execute a program, its This paper describe how does CPU facilitates tasks given by a admission to the set of currently executing processes is user through a Scheduling Algorithm. CPU carries out each either authorized or delayed by the long-term scheduler. instruction of the program in sequence then performs the basic Second is the Mid-term Scheduler that temporarily arithmetical, logical, and input/output operations of the system removes processes from main memory and places them on while a scheduling algorithm is used by the CPU to handle every process. The authors also tackled different scheduling disciplines secondary memory (such as a disk drive) or vice versa. and examples were provided in each algorithm in order to know Last is the Short Term Scheduler that decides which of the which algorithm is appropriate for various CPU goals. ready, in-memory processes are to be executed. Keywords: Kernel, Process State, Schedulers, Scheduling Algorithm, Utilization. 2. CPU Utilization 1. Introduction In order for a computer to be able to handle multiple applications simultaneously there must be an effective way The central processing unit (CPU) is a component of a of using the CPU. -

The Different Unix Contexts
The different Unix contexts • User-level • Kernel “top half” - System call, page fault handler, kernel-only process, etc. • Software interrupt • Device interrupt • Timer interrupt (hardclock) • Context switch code Transitions between contexts • User ! top half: syscall, page fault • User/top half ! device/timer interrupt: hardware • Top half ! user/context switch: return • Top half ! context switch: sleep • Context switch ! user/top half Top/bottom half synchronization • Top half kernel procedures can mask interrupts int x = splhigh (); /* ... */ splx (x); • splhigh disables all interrupts, but also splnet, splbio, splsoftnet, . • Masking interrupts in hardware can be expensive - Optimistic implementation – set mask flag on splhigh, check interrupted flag on splx Kernel Synchronization • Need to relinquish CPU when waiting for events - Disk read, network packet arrival, pipe write, signal, etc. • int tsleep(void *ident, int priority, ...); - Switches to another process - ident is arbitrary pointer—e.g., buffer address - priority is priority at which to run when woken up - PCATCH, if ORed into priority, means wake up on signal - Returns 0 if awakened, or ERESTART/EINTR on signal • int wakeup(void *ident); - Awakens all processes sleeping on ident - Restores SPL a time they went to sleep (so fine to sleep at splhigh) Process scheduling • Goal: High throughput - Minimize context switches to avoid wasting CPU, TLB misses, cache misses, even page faults. • Goal: Low latency - People typing at editors want fast response - Network services can be latency-bound, not CPU-bound • BSD time quantum: 1=10 sec (since ∼1980) - Empirically longest tolerable latency - Computers now faster, but job queues also shorter Scheduling algorithms • Round-robin • Priority scheduling • Shortest process next (if you can estimate it) • Fair-Share Schedule (try to be fair at level of users, not processes) Multilevel feeedback queues (BSD) • Every runnable proc. -

Processes Process States
Processes • A process is a program in execution • Synonyms include job, task, and unit of work • Not surprisingly, then, the parts of a process are precisely the parts of a running program: Program code, sometimes called the text section Program counter (where we are in the code) and other registers (data that CPU instructions can touch directly) Stack — for subroutines and their accompanying data Data section — for statically-allocated entities Heap — for dynamically-allocated entities Process States • Five states in general, with specific operating systems applying their own terminology and some using a finer level of granularity: New — process is being created Running — CPU is executing the process’s instructions Waiting — process is, well, waiting for an event, typically I/O or signal Ready — process is waiting for a processor Terminated — process is done running • See the text for a general state diagram of how a process moves from one state to another The Process Control Block (PCB) • Central data structure for representing a process, a.k.a. task control block • Consists of any information that varies from process to process: process state, program counter, registers, scheduling information, memory management information, accounting information, I/O status • The operating system maintains collections of PCBs to track current processes (typically as linked lists) • System state is saved/loaded to/from PCBs as the CPU goes from process to process; this is called… The Context Switch • Context switch is the technical term for the act -

Chapter 3: Processes
Chapter 3: Processes Operating System Concepts – 9th Edition Silberschatz, Galvin and Gagne ©2013 Chapter 3: Processes Process Concept Process Scheduling Operations on Processes Interprocess Communication Examples of IPC Systems Communication in Client-Server Systems Operating System Concepts – 9th Edition 3.2 Silberschatz, Galvin and Gagne ©2013 Objectives To introduce the notion of a process -- a program in execution, which forms the basis of all computation To describe the various features of processes, including scheduling, creation and termination, and communication To explore interprocess communication using shared memory and message passing To describe communication in client-server systems Operating System Concepts – 9th Edition 3.3 Silberschatz, Galvin and Gagne ©2013 Process Concept An operating system executes a variety of programs: Batch system – jobs Time-shared systems – user programs or tasks Textbook uses the terms job and process almost interchangeably Process – a program in execution; process execution must progress in sequential fashion Multiple parts The program code, also called text section Current activity including program counter, processor registers Stack containing temporary data Function parameters, return addresses, local variables Data section containing global variables Heap containing memory dynamically allocated during run time Operating System Concepts – 9th Edition 3.4 Silberschatz, Galvin and Gagne ©2013 Process Concept (Cont.) Program is passive entity stored on disk (executable -

Integrating Preemption Threshold Scheduling and Dynamic Voltage Scaling for Energy Efficient Real-Time Systems
Integrating Preemption Threshold Scheduling and Dynamic Voltage Scaling for Energy Efficient Real-Time Systems Ravindra Jejurikar1 and Rajesh Gupta2 1 Centre for Embedded Computer Systems, University of California Irvine, Irvine CA 92697, USA jeÞÞ@cec׺ÙciºedÙ 2 Department of Computer Science and Engineering, University of California San Diego, La Jolla, CA 92093, USA gÙÔØa@c׺Ùc×dºedÙ Abstract. Preemption threshold scheduling (PTS) enables designing scalable real-time systems. PTS not only decreases the run-time overhead of the system, but can also be used to decrease the number of threads and the memory require- ments of the system. In this paper, we combine preemption threshold scheduling with dynamic voltage scaling to enable energy efficient scheduling in real-time systems. We consider scheduling with task priorities defined by the Earliest Dead- line First (EDF) policy. We present an algorithm to compute threshold preemption levels for tasks with given static slowdown factors. The proposed algorithm im- proves upon known algorithms in terms of time complexity. Experimental results show that preemption threshold scheduling reduces on an average 90% context switches, even in the presence of task slowdown. Further, we describe a dynamic slack reclamation technique that working in conjunction with PTS that yields on an average 10% additional energy savings. 1 Introduction With increasing mobility and proliferation of embedded systems, low power consump- tion is an important aspect of embedded systems design. Generally speaking, the pro- cessor consumes a significant portion of the total energy, primarily due to increased computational demands. Scaling the processor frequency and voltage based on the per- formance requirements can lead to considerable energy savings. -

What Is an Operating System III 2.1 Compnents II an Operating System
Page 1 of 6 What is an Operating System III 2.1 Compnents II An operating system (OS) is software that manages computer hardware and software resources and provides common services for computer programs. The operating system is an essential component of the system software in a computer system. Application programs usually require an operating system to function. Memory management Among other things, a multiprogramming operating system kernel must be responsible for managing all system memory which is currently in use by programs. This ensures that a program does not interfere with memory already in use by another program. Since programs time share, each program must have independent access to memory. Cooperative memory management, used by many early operating systems, assumes that all programs make voluntary use of the kernel's memory manager, and do not exceed their allocated memory. This system of memory management is almost never seen any more, since programs often contain bugs which can cause them to exceed their allocated memory. If a program fails, it may cause memory used by one or more other programs to be affected or overwritten. Malicious programs or viruses may purposefully alter another program's memory, or may affect the operation of the operating system itself. With cooperative memory management, it takes only one misbehaved program to crash the system. Memory protection enables the kernel to limit a process' access to the computer's memory. Various methods of memory protection exist, including memory segmentation and paging. All methods require some level of hardware support (such as the 80286 MMU), which doesn't exist in all computers. -

Chapter 1. Origins of Mac OS X
1 Chapter 1. Origins of Mac OS X "Most ideas come from previous ideas." Alan Curtis Kay The Mac OS X operating system represents a rather successful coming together of paradigms, ideologies, and technologies that have often resisted each other in the past. A good example is the cordial relationship that exists between the command-line and graphical interfaces in Mac OS X. The system is a result of the trials and tribulations of Apple and NeXT, as well as their user and developer communities. Mac OS X exemplifies how a capable system can result from the direct or indirect efforts of corporations, academic and research communities, the Open Source and Free Software movements, and, of course, individuals. Apple has been around since 1976, and many accounts of its history have been told. If the story of Apple as a company is fascinating, so is the technical history of Apple's operating systems. In this chapter,[1] we will trace the history of Mac OS X, discussing several technologies whose confluence eventually led to the modern-day Apple operating system. [1] This book's accompanying web site (www.osxbook.com) provides a more detailed technical history of all of Apple's operating systems. 1 2 2 1 1.1. Apple's Quest for the[2] Operating System [2] Whereas the word "the" is used here to designate prominence and desirability, it is an interesting coincidence that "THE" was the name of a multiprogramming system described by Edsger W. Dijkstra in a 1968 paper. It was March 1988. The Macintosh had been around for four years. -
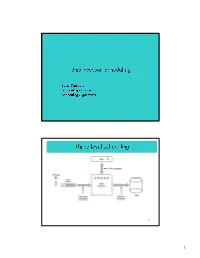
Three Level Scheduling
Uniprocessor Scheduling •Basic Concepts •Scheduling Criteria •Scheduling Algorithms Three level scheduling 2 1 Types of Scheduling 3 Long- and Medium-Term Schedulers Long-term scheduler • Determines which programs are admitted to the system (ie to become processes) • requests can be denied if e.g. thrashing or overload Medium-term scheduler • decides when/which processes to suspend/resume • Both control the degree of multiprogramming – More processes, smaller percentage of time each process is executed 4 2 Short-Term Scheduler • Decides which process will be dispatched; invoked upon – Clock interrupts – I/O interrupts – Operating system calls – Signals • Dispatch latency – time it takes for the dispatcher to stop one process and start another running; the dominating factors involve: – switching context – selecting the new process to dispatch 5 CPU–I/O Burst Cycle • Process execution consists of a cycle of – CPU execution and – I/O wait. • A process may be – CPU-bound – IO-bound 6 3 Scheduling Criteria- Optimization goals CPU utilization – keep CPU as busy as possible Throughput – # of processes that complete their execution per time unit Response time – amount of time it takes from when a request was submitted until the first response is produced (execution + waiting time in ready queue) – Turnaround time – amount of time to execute a particular process (execution + all the waiting); involves IO schedulers also Fairness - watch priorities, avoid starvation, ... Scheduler Efficiency - overhead (e.g. context switching, computing priorities, -

Comparing Systems Using Sample Data
Operating System and Process Monitoring Tools Arik Brooks, [email protected] Abstract: Monitoring the performance of operating systems and processes is essential to debug processes and systems, effectively manage system resources, making system decisions, and evaluating and examining systems. These tools are primarily divided into two main categories: real time and log-based. Real time monitoring tools are concerned with measuring the current system state and provide up to date information about the system performance. Log-based monitoring tools record system performance information for post-processing and analysis and to find trends in the system performance. This paper presents a survey of the most commonly used tools for monitoring operating system and process performance in Windows- and Unix-based systems and describes the unique challenges of real time and log-based performance monitoring. See Also: Table of Contents: 1. Introduction 2. Real Time Performance Monitoring Tools 2.1 Windows-Based Tools 2.1.1 Task Manager (taskmgr) 2.1.2 Performance Monitor (perfmon) 2.1.3 Process Monitor (pmon) 2.1.4 Process Explode (pview) 2.1.5 Process Viewer (pviewer) 2.2 Unix-Based Tools 2.2.1 Process Status (ps) 2.2.2 Top 2.2.3 Xosview 2.2.4 Treeps 2.3 Summary of Real Time Monitoring Tools 3. Log-Based Performance Monitoring Tools 3.1 Windows-Based Tools 3.1.1 Event Log Service and Event Viewer 3.1.2 Performance Logs and Alerts 3.1.3 Performance Data Log Service 3.2 Unix-Based Tools 3.2.1 System Activity Reporter (sar) 3.2.2 Cpustat 3.3 Summary of Log-Based Monitoring Tools 4. -

A Simple Chargeback System for SAS® Applications Running on UNIX and Linux Servers
SAS Global Forum 2007 Systems Architecture Paper: 194-2007 A Simple Chargeback System For SAS® Applications Running on UNIX and Linux Servers Michael A. Raithel, Westat, Rockville, MD Abstract Organizations that run SAS on UNIX and Linux servers often have a need to measure overall SAS usage and to charge the projects and users who utilize the servers. This allows an organization to pay for the hardware, software, and labor necessary to maintain and run these types of shared servers. However, performance management and accounting software is normally expensive. Purchasing such software, configuring it, and managing it may be prohibitive in terms of cost and in terms of having staff with the right skill sets to do so. Consequently, many organizations with UNIX or Linux servers do not have a reliable way to measure the overall use of SAS software and to charge individuals and projects for its use. This paper presents a simple methodology for creating a chargeback system on UNIX and Linux servers. It uses basic accounting programs found in the UNIX and Linux operating systems, and exploits them using SAS software. The paper presents an overview of the UNIX/Linux “sa” command and the basic accounting system. Then, it provides a SAS program that utilizes this command to capture and store monthly SAS usage statistics. The paper presents a second SAS program that reads the monthly SAS usage SAS data set and creates both a chargeback report and a general usage report. After reading this paper, you should be able to easily adapt the sample SAS programs to run on servers in your own environment. -

Lottery Scheduling in the Linux Kernel: a Closer Look
LOTTERY SCHEDULING IN THE LINUX KERNEL: A CLOSER LOOK A Thesis presented to the Faculty of California Polytechnic State University, San Luis Obispo In Partial Fulfillment of the Requirements for the Degree Master of Science in Computer Science by David Zepp June 2012 © 2012 David Zepp ALL RIGHTS RESERVED ii COMMITTEE MEMBERSHIP TITLE: LOTTERY SCHEDULING IN THE LINUX KERNEL: A CLOSER LOOK AUTHOR: David Zepp DATE SUBMITTED: June 2012 COMMITTEE CHAIR: Michael Haungs, Associate Professor of Computer Science COMMITTEE MEMBER: John Bellardo, Assistant Professor of Computer Science COMMITTEE MEMBER: Aaron Keen, Associate Professor of Computer Science iii ABSTRACT LOTTERY SCHEDULING IN THE LINUX KERNEL: A CLOSER LOOK David Zepp This paper presents an implementation of a lottery scheduler, presented from design through debugging to performance testing. Desirable characteristics of a general purpose scheduler include low overhead, good overall system performance for a variety of process types, and fair scheduling behavior. Testing is performed, along with an analysis of the results measuring the lottery scheduler against these characteristics. Lottery scheduling is found to provide better than average control over the relative execution rates of processes. The results show that lottery scheduling functions as a good mechanism for sharing the CPU fairly between users that are competing for the resource. While the lottery scheduler proves to have several interesting properties, overall system performance suffers and does not compare favorably with the balanced performance afforded by the standard Linux kernel’s scheduler. Keywords: lottery scheduling, schedulers, Linux iv TABLE OF CONTENTS LIST OF TABLES…………………………………………………………………. vi LIST OF FIGURES……………………………………………………………….... vii CHAPTER 1. Introduction................................................................................................... 1 2. -

CS 450: Operating Systems Sean Wallace <[email protected]>
Deadlock CS 450: Operating Systems Computer Sean Wallace <[email protected]> Science Science deadlock |ˈdedˌläk| noun 1 [ in sing. ] a situation, typically one involving opposing parties, in which no progress can be made: an attempt to break the deadlock. –New Oxford American Dictionary 2 Traffic Gridlock 3 Software Gridlock mutex_A.lock() mutex_B.lock() mutex_B.lock() mutex_A.lock() # critical section # critical section mutex_B.unlock() mutex_B.unlock() mutex_A.unlock() mutex_A.unlock() 4 Necessary Conditions for Deadlock 5 That is, what conditions need to be true (of some system) so that deadlock is possible? (Not the same as causing deadlock!) 6 1. Mutual Exclusion Resources can be held by process in a mutually exclusive manner 7 2. Hold & Wait While holding one resource (in mutex), a process can request another resource 8 3. No Preemption One process can not force another to give up a resource; i.e., releasing is voluntary 9 4. Circular Wait Resource requests and allocations create a cycle in the resource allocation graph 10 Resource Allocation Graphs 11 Process: Resource: Request: Allocation: 12 R1 R2 P1 P2 P3 R3 Circular wait is absent = no deadlock 13 R1 R2 P1 P2 P3 R3 All 4 necessary conditions in place; Deadlock! 14 In a system with only single-instance resources, necessary conditions ⟺ deadlock 15 P3 R1 P1 P2 R2 P2 Cycle without Deadlock! 16 Not practical (or always possible) to detect deadlock using a graph —but convenient to help us reason about things 17 Approaches to Dealing with Deadlock 18 1. Ostrich algorithm (Ignore it and hope it never happens) 2.