Volume 22 Spring 2021 the Journal of Undergraduate Research In
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

(ITEP) Application for Admission in 2020
Integrated Teacher Education Program (ITEP) Application For Admission in 2020 Name: Last First Middle Former Address: Number and Street City Zip Code Telephone: Cell Home Email: Date of Birth: Semester you expect to complete Associate’s degree: Semester that you expect to start at CSUF: Accepted Early Childhood Special CSUF Applied, no response yet Credential Education (ECSE) application Applied, waitlisted Sought: Mild/Moderate status: Not yet applied Moderate/Severe Please indicate your completion status for the following classes (see equivalents on next page): Equivalents to Required Your Equivalent CSUF Classes Community College Course Status CAS 101: Intro to Child Completed Development (required for In Progress all applicants) Not Yet Enrolled CAS 201: Child Family Completed Community (required for In Progress all applicants) Not Yet Enrolled SPED 371: Exceptional Completed Individual (required for all In Progress applicants) Not Yet Enrolled CAS 250: Intro to EC Completed Curriculum (required for In Progress ECSE) Not Yet Enrolled CAS 306: Health, Safety, & Completed Nutrition (required for In Progress ECSE) Not Yet Enrolled MATH 303A: Math for Completed Elementary (required for In Progress Mild/Mod & Mod/Severe) Not Yet Enrolled ENGL 341: Children’s Completed Literature (required for In Progress Mild/Mod & Mod/Severe) Not Yet Enrolled Completed GE Certification In Progress Not Yet Enrolled Please attach an unofficial transcript from all community colleges and/or universities that you have attended. Submit materials to EC 503 at CSUF or [email protected] Integrated Teacher Education Program (ITEP) Application For Admission in 2020 Credential Early Childhood (ECSE) Mild/Moderate Moderate/Severe Core Classes: Core Classes: Core Classes: 1. -

A Statistical Study Nicholas Lambrianou 13' Dr. Nicko
Examining if High-Team Payroll Leads to High-Team Performance in Baseball: A Statistical Study Nicholas Lambrianou 13' B.S. In Mathematics with Minors in English and Economics Dr. Nickolas Kintos Thesis Advisor Thesis submitted to: Honors Program of Saint Peter's University April 2013 Lambrianou 2 Table of Contents Chapter 1: The Study and its Questions 3 An Introduction to the project, its questions, and a breakdown of the chapters that follow Chapter 2: The Baseball Statistics 5 An explanation of the baseball statistics used for the study, including what the statistics measure, how they measure what they do, and their strengths and weaknesses Chapter 3: Statistical Methods and Procedures 16 An introduction to the statistical methods applied to each statistic and an explanation of what the possible results would mean Chapter 4: Results and the Tampa Bay Rays 22 The results of the study, what they mean against the possibilities and other results, and a short analysis of a team that stood out in the study Chapter 5: The Continuing Conclusion 39 A continuation of the results, followed by ideas for future study that continue to project or stem from it for future baseball analysis Appendix 41 References 42 Lambrianou 3 Chapter 1: The Study and its Questions Does high payroll necessarily mean higher performance for all baseball statistics? Major League Baseball (MLB) is a league of different teams in different cities all across the United States, and those locations strongly influence the market of the team and thus the payroll. Year after year, a certain amount of teams, including the usual ones in big markets, choose to spend a great amount on payroll in hopes of improving their team and its player value output, but at times the statistics produced by these teams may not match the difference in payroll with other teams. -

Dr. John Hernandez Accepts Position of Irvine Valley College President
CONTACT: Letitia Clark, MPP - 949.582.4920 - [email protected] FOR IMMEDIATE RELEASE: May 28, 2020 Dr. John Hernandez Accepts Position of Irvine Valley College President MISSION VIEJO, CA— A nationwide search, candidate interviews, and public forums were held via Zoom in the selection process to identify the next Irvine Valley College President. After a several month process, a decision has been made, and Chancellor Kathleen Burke has announced that she is recommending that Dr. John Hernandez serve in the role as Irvine Valley College’s new president. Dr. Hernandez has been an educator for over 30 years – 22 of those years in administration. He was appointed President of Santiago Canyon College (Orange, CA) in July 2017 and served as Interim President there from July 2016 until his permanent appointment. Prior to that, he was the college’s Vice President for Student Services (2005 to July 2016). Before joining Santiago Canyon College, Dr. Hernandez was Associate Vice President and Dean of Students at Cal Poly Pomona; Associate Dean for Student Development at Santa Ana College and Assistant Dean for Student Affairs at California State University, Fullerton. Additionally, Dr. Hernandez has been an adjunct instructor in the Student Development in the Higher Education graduate program at California State University, Long Beach and taught counseling and student development courses at various colleges as well. Dr. Hernandez will immediately begin the transition process from his role as President of Santiago Canyon College within the Rancho Santiago Community College District. He is expected to start at Irvine Valley College on August 1, 2020, pending ratification of his contract by the South Orange County Community College District (SOCCCD) Board of Trustees. -

Psychometric G: Definition and Substantiation
Psychometric g: Definition and Substantiation Arthur R. Jensen University of Culifornia, Berkeley The construct known as psychometric g is arguably the most important construct in all of psychology largelybecause of its ubiquitous presence in all tests of mental ability and its wide-ranging predictive validity for a great many socially significant variables, including scholastic performance and intellectual attainments, occupational status, job performance, in- come, law abidingness, and welfare dependency. Even such nonintellec- tual variables as myopia, general health, and longevity, as well as many other physical traits, are positively related to g. Of course, the causal con- nections in the whole nexus of the many diverse phenomena involving the g factor is highly complex. Indeed, g and its ramifications cut across the behavioral sciences-brainphysiology, psychology, sociology-perhaps more than any other scientific construct. THE DOMAIN OF g THEORY It is important to keep in mind the distinction between intelligence and g, as these terms are used here. The psychology of intelligence could, at least in theory, be based on the study of one person,just as Ebbinghaus discov- ered some of the laws of learning and memory in experimentswith N = 1, using himself as his experimental subject. Intelligence is an open-ended category for all those mental processes we view as cognitive, such as stimu- lus apprehension, perception, attention, discrimination, generalization, 39 40 JENSEN learning and learning-set acquisition, short-term and long-term memory, inference, thinking, relation eduction, inductive and deductive reasoning, insight, problem solving, and language. The g factor is something else. It could never have been discovered with N = 1, because it reflects individual di,fferences in performance on tests or tasks that involve anyone or moreof the kinds of processes just referred to as intelligence. -

Rancho Santiago Community College District Sustainability Plan
Rancho Santiago Community College District Sustainability Plan Produced by February 2015 ACKNOWLEDGMENTS Trustees Claudia C. Alvarez Arianna P. Barrios John R. Hanna Lawrence R. “Larry” Labrado Jose Solorio Nelida Mendoza Yanez Phillip E. Yarbrough Alana V. Voechting, Student Trustee Chancellor Raúl Rodríguez, Ph.D. Presidents Erlinda Martinez, Ed.D., – Santa Ana College John Weispfenning, Ph.D., – Santiago Canyon College Sustainable RSCCD Committee Members Delmis Alvarado, Classified Staff Kelsey Bain, Classified Staff Michael Collins, Ed.D., Vice President – Santa Ana College Douglas Deaver, Ph.D., Associate Professor Philosophy Leah Freidenrich, Professor Library & Information Science Peter Hardash, Vice Chancellor – Business Operations & Fiscal Services Judy Iannaccone, Director – Public Affairs & Publications Steve Kawa, Vice President – Santiago Canyon College James Kennedy, Vice President – Centennial Education Center Laurene Lugo, Classified Staff Carri Matsumoto, Assistant Vice Chancellor – Facilities Lisa McKowan-Bourguignon, Asst. Professor Mathematics Kimo Morris, Ph.D., Asst. Professor Biology Kyle Murphy, Student Representative – Santa Ana College Elisabeth Pechs – Orange County SBDC Jose Vargas, Vice President – Orange Education Center Nathan Sunderwood, Student Representative – Santiago Canyon College Other Contributors Matt Sullivan, Consultant – Newcomb Anderson McCormick Danielle Moultak, Project Manager – Newcomb Anderson McCormick Sustainability Plan i TABLE OF CONTENTS SECTION 1. EXECUTIVE -

2020-2021 SCC-OEC Catalog
215 Catalog 2020-2021 216 SCC Catalog 2020-2021 SANTIAGO CANYON COLLEGE—CONTINUING EDUCATION INSTRUCTIONAL CALENDAR CONTINUING EDUCATION DIVISION JUNE 2020 JANUARY 2021 INSTRUCTIONAL CALENDAR 2020-2021 S M T W T F S S M T W T F S 1 2 3 4 5 6 1 2 FALL SEMESTER 2020 7 8 9 10 11 12 13 3 4 5 6 7 8 9 August 17–21 Faculty projects 14 15 16 17 18 19 20 10 11 12 13 14 15 16 21 22 23 24 25 26 27 17 18 19 20 21 22 23 August 24 INSTRUCTION BEGINS 28 29 30 24 25 26 27 28 29 30 September 7 Labor Day — Holiday 31 November 11 Veterans’ Day — Holiday JULY 2020 FEBRUARY 2021 November 23–28 Thanksgiving recess S M T W T F S S M T W T F S December 18 INSTRUCTION ENDS 1 2 3 4 1 2 3 4 5 6 December 21–January 8 Winter recess 5 6 7 8 9 10 11 7 8 9 10 11 12 13 12 13 14 15 16 17 18 14 15 16 17 18 19 20 SPRING SEMESTER 2021 19 20 21 22 23 24 25 21 22 23 24 25 26 27 January 8, 11, 12 Faculty projects 26 27 28 29 30 31 28 January 13 INSTRUCTION BEGINS January 18 Martin Luther King, Jr. — Holiday AUGUST 2020 MARCH 2021 February 12 Lincoln’s Birthday (Observed) S M T W T F S S M T W T F S February 15 President’s Day — Holiday 1 1 2 3 4 5 6 March 29–April 3 OSpring recess* 2 3 4 5 6 7 8 7 8 9 10 11 12 13 14 15 16 17 18 19 20 May 27 OEC Commencement 9 10 11 12 13 14 15 16 17 18 19 20 21 22 21 22 23 24 25 26 27 May 27 INSTRUCTION ENDS 23 24 25 26 27 28 29 28 29 30 31 May 231 Memorial Day — Holiday 30 31 SUMMER SESSION 2021 APRIL 2021 June 1 INSTRUCTION BEGINS** SEPTEMBER 2020 S M T W T F S July 4 Independence Day — Holiday Observed July 5 S M T W T F S 1 2 3 August 7 INSTRUCTION ENDS** 1 2 3 4 5 4 5 6 7 8 9 10 6 7 8 9 10 11 12 11 12 13 14 15 16 17 13 14 15 16 17 18 19 18 19 20 21 22 23 24 * OEC Spring recess dates may be adjusted to correspond to unified school district instructional calendar. -

Scc Curriculum & Instruction
Fall 2020 September 21, 2020 SCC CURRICULUM & INSTRUCTION COUNCIL SCC B-104 1:30 p.m. Meeting Minutes Committee Members Present: L. Aguilera, J. Armstrong, E. Arteaga, D. Bailey, L. Camarco, S. Deeley, C. Evett, L. Fasbinder, A. Freese, A. Garcia, C. Gascon, S. Graham, E. Gutierrez, S. James, J. Kubicka-Miller, R. Lamourelle, C. Malone, S. McLean, R. Miller, M. Newman (Student Representative), N. Pecenkovic, S. Sanchez, N. Shekarabi, J. Shields, M. Stringer, R. Van Dyke-Kao, A. Voelcker, L. Wright Absent: T. Garbis, L. Martin Guests: J. Dennis, L. Espinosa, R. Felipe, M. Laney, N. Parent, B. Sos C. Evett called the meeting to order at 1:30 p.m. I. Approval of Minutes The Minutes for August 31, 2020 were approved. Mover: S. Sanchez Seconder: R. Miller Ayes: L. Aguilera, L. Camarco, S. Deeley, C. Evett, A. Freese, S. Graham, E. Gutierrez, S. James, J. Kubicka-Miller, R. Lamourelle, C. Malone, S. McLean, R. Miller, M. Newman (Student Representative), N. Pecenkovic, S. Sanchez, N. Shekarabi, J. Shields, M. Stringer, R. Van Dyke-Kao, L. Wright Nays: None Abstentions: None Santiago Canyon College 1 What happens here matters. Fall 2020 September 21, 2020 II. Announcements a. Class Capacity C. Evett presented information on Class Capacity. The Curriculum Office updates the class capacity field in Colleague when a request is made. Collegial consultation should take place before the class capacity field is changed. The interim process for the Curriculum Office will be to request that the Dean and CIC Chair be copied when an update to the class capacity field in Colleague is requested. -
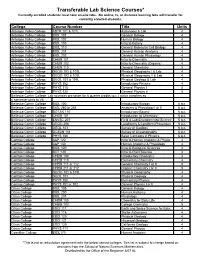
Transferable Lab Science Courses* Currently Enrolled Students Must Take On-Site Labs
Transferable Lab Science Courses* Currently enrolled students must take on-site labs. No online, tv, or distance learning labs will transfer for currently enrolled students. College Course Number Title Units Antelope Valley College ASTR 101 & 101L Astronomy & Lab 4 Antelope Valley College BIOL 101 General Biology 4 Antelope Valley College BIOL 102 Human Biology 4 Antelope Valley College BIOL 103 Intro to Botany 4 Antelope Valley College BIOL 110 General Molecular Cell Biology 4 Antelope Valley College BIOL 201 General Human Anatomy 4 Antelope Valley College BIOL 202 General Human Physiology 4 Antelope Valley College CHEM 101 Intro to Chemistry 5 Antelope Valley College CHEM 102 Intro to Chemistry (Organis) 4 Antelope Valley College CHEM 110 General Chemistry 5 Antelope Valley College GEOG 101 & 101L Physical Geography I & Lab 4 Antelope Valley College GEOG 102 & 102L Physical Geography II & Lab 4 Antelope Valley College GEOL 101 & 101L Physical Geology & Lab 4 Antelope Valley College PHYS 102 Introductory Physics 4 Antelope Valley College PHYS 110 General Physics I 5 Antelope Valley College PHYS 120 General Physics II 5 Bellevue Comm College: Lab sciences are taken for 6 quarter credits (q.c.) which transfers as 4 semester units to VU Bellevue Comm College BIOL 100 Introductory Biology 6 q.c. Bellevue Comm College BIOL 260 or 261 Anatomy & Physiology I or II 6 q.c. Bellevue Comm College BOTAN 110 Introductory Botany 6 q.c. Bellevue Comm College CHEM 101 Introduction to Chemistry 6 q.c. Bellevue Comm College ENVSC 207 Field & Lab Environmental Science 6 q.c. Bellevue Comm College GEOG 206 Landforms & Landform Processes 6 q.c. -

{Download PDF} the Sabermetric Revolution Assessing the Growth of Analytics in Baseball 1St Edition Ebook, Epub
THE SABERMETRIC REVOLUTION ASSESSING THE GROWTH OF ANALYTICS IN BASEBALL 1ST EDITION PDF, EPUB, EBOOK Benjamin Baumer | 9780812223392 | | | | | The Sabermetric Revolution Assessing the Growth of Analytics in Baseball 1st edition PDF Book Citations should be used as a guideline and should be double checked for accuracy. The Milwaukee Brewers have made a sabermetric shift under GM David Stearns, who took over in the fall of , and the new front office team of the Minnesota Twins also has sabermetric tendencies. The Sabermetric Revolution sets the record straight on the role of analytics in baseball. However, over the past two decades, a wider range of statistics made their way into barroom debates, online discussion groups, and baseball front offices. This is a very useful book. Subscribe to our Free Newsletter. But, be on guard, stats freaks: it isn't doctrinaire. He is the Robert A. Frederick E. Rocketed to popularity by the bestseller Moneyball and the film of the same name, the use of sabermetrics to analyze player performance has appeared to be a David to the Goliath of systemically advantaged richer teams that could be toppled only by creative statistical analysis. Also in This Series. Prospector largest collection. But how accurately can crunching numbers quantify a player's ability? Goodreads helps you keep track of books you want to read. The book is ideal for a reader who wishes to tie together the importance of everything they have digested from sites like Fangraphs , Baseball Prospectus , Hardball Times , Beyond the Box Score , and, even, yes, Camden Depot. Ryne rated it liked it May 27, Not because I rejected new age stats, but because I never sought them out. -

Does a Fitness Factor Contribute to the Association Between Intelligence
ARTICLE IN PRESS INTELL-00516; No of Pages 11 Intelligence xxx (2009) xxx–xxx Contents lists available at ScienceDirect Intelligence journal homepage: Does a fitness factor contribute to the association between intelligence and health outcomes? Evidence from medical abnormality counts among 3654 US Veterans Rosalind Arden a,⁎, Linda S. Gottfredson b, Geoffrey Miller c a Social, Genetic, Developmental and Psychiatry Centre, Institute of Psychiatry, King's College London, London SE5 8AF, United Kingdom b School of Education, University of Delaware, Newark, DE 19716, USA c Psychology Department, Logan Hall 160, University of New Mexico, MSC03 2220 Albuquerque, NM 87131-1161, USA article info abstract Available online xxxx We suggest that an over-arching ‘fitness factor’ (an index of general genetic quality that predicts survival and reproductive success) partially explains the observed associations between health Keywords: outcomes and intelligence. As a proof of concept, we tested this idea in a sample of 3654 US Fitness Vietnam veterans aged 31–49 who completed five cognitive tests (from which we extracted a g Intelligence factor), a detailed medical examination, and self-reports concerning lifestyle health risks (such Cognitive epidemiology as smoking and drinking). As indices of physical health, we aggregated ‘abnormality counts’ of Health physician-assessed neurological, morphological, and physiological abnormalities in eight Mutation load categories: cranial nerves, motor nerves, peripheral sensory nerves, reflexes, head, body, skin condition, and urine tests. Since each abnormality was rare, the abnormality counts showed highly skewed, Poisson-like distributions. The correlation matrix amongst these eight abnormality counts formed only a weak positive manifold and thus yielded only a weak common factor. -

UC Merced Proceedings of the Annual Meeting of the Cognitive Science Society
UC Merced Proceedings of the Annual Meeting of the Cognitive Science Society Title Dynamical cognitive models and the study of individual differences. Permalink https://escholarship.org/uc/item/4sn2v2j0 Journal Proceedings of the Annual Meeting of the Cognitive Science Society, 31(31) ISSN 1069-7977 Authors Kan, Kees Jan Van Der Maas, Han L.J. Publication Date 2009 Peer reviewed eScholarship.org Powered by the California Digital Library University of California Dynamical cognitive models and the study of individual differences Han van der Maas & Kees Jan Kan A large part of psychology concerns the study of individual differences. Why do people differ in personality? What is the structure of individual differences in intelligence? What are the roles of nurture and nature? Researchers in these fields collect data of many subjects and apply statistical methods, most notably latent structure modeling, to uncover the structure and to infer the underlying sources of the individual differences. Cognitive science usually does not concern individual differences. In cognitive models we focus on the general mechanisms of cognitive processes and not the individual properties. We believe that these two traditions of modeling cannot remain separated. Models of mechanisms necessarily precede models of individual differences. We argue against the use of latent structure models of individual differences in psychological processes that do not explicate the underlying mechanisms. Our main example is general intelligence, a concept based on the analysis of group data. Scores on cognitive tasks used in intelligence tests correlate positively with each other, i.e., they display a positive manifold of correlations. The positive manifold is arguably both the best established, and the most striking phenomenon in the psychological study of intelligence. -

Apply for a $500 SCHEC Need Help with Expenses After You Transfer?
Need help with expenses after you The South Coast Higher Education Council (SCHEC) is pleased to be offering several $500 scholarships for the 2017-2018 academic year. Transfer? Those who meet the following criteria are invited to . apply for a SCHEC Scholarship: Currently enrolled in a SCHEC institution and will be transferring as a full-time student to a SCHEC four-year college/university* Apply during the 2017-2018 academic year for a Have a 3.0 or higher cumulative GPA Applications must be postmarked no later than $500 March 10, 2017! SCHEC Application materials can be found at: http://www.schec.net Questions? Contact: Scholarship Melissa Sinclair at CSU Fullerton: [email protected] Carmen Di Padova at Alliant International University: [email protected] Alliant International University CSU Long Beach Rio Hondo College The following colleges, Argosy University Cypress College Saddleback College universities and Azusa Pacific University DeVry University Santa Ana College Biola University El Camino College Santiago Canyon College professional schools Brandman University Fullerton College Southern California University are members of the Cerritos College Golden West College Trident University International South Coast Higher Chapman University Hope International University Trinity Law School Citrus College Irvine Valley College UC, Irvine Education Council Coastline College Loma Linda University UC, Riverside (SCHEC): Concordia University Long Beach City College University of La Verne Columbia University Mt. San Antonio College University of Redlands CSPU, Pomona National University Vanguard University CSU, Dominguez Hills Orange Coast College Webster University CSU, Fullerton Pepperdine University—Irvine Whittier College .