Projective Replay Analysis: a Reflective Approach for Aligning Educational Games to Their Goals
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Law in the Virtual World: Should the Surreal World of Online Communities Be Brought Back to Earth by Real World Laws
Volume 16 Issue 1 Article 5 2009 Law in the Virtual World: Should the Surreal World of Online Communities be Brought Back to Earth by Real World Laws David Assalone Follow this and additional works at: https://digitalcommons.law.villanova.edu/mslj Part of the Entertainment, Arts, and Sports Law Commons, and the Internet Law Commons Recommended Citation David Assalone, Law in the Virtual World: Should the Surreal World of Online Communities be Brought Back to Earth by Real World Laws, 16 Jeffrey S. Moorad Sports L.J. 163 (2009). Available at: https://digitalcommons.law.villanova.edu/mslj/vol16/iss1/5 This Comment is brought to you for free and open access by Villanova University Charles Widger School of Law Digital Repository. It has been accepted for inclusion in Jeffrey S. Moorad Sports Law Journal by an authorized editor of Villanova University Charles Widger School of Law Digital Repository. Assalone: Law in the Virtual World: Should the Surreal World of Online Comm Comments LAW IN THE VIRTUAL WORLD: SHOULD THE SURREAL WORLD OF ONLINE COMMUNITIES BE BROUGHT BACK TO EARTH BY REAL WORLD LAWS?' I. INTRODUCTION In 2003, the world of online interaction changed forever with the advent of the online community of Second Life. 2 Prior to Sec- ond Life and other massive multiplayer online role-playing games ("MMORPGs"), online communications were primarily restricted to e-mail, instant messenger and chat rooms. 3 Though thousands of Internet users could, among other things, engage in online sales of goods at websites such as Amazon.com, no system gave users the ability to personally interact with one another.4 With game de- signer Linden Lab's introduction of Second Life, however, users now have an Internet platform through which they can truly com- municate on a face-to-face basis.5 The online virtual world of Sec- 1. -

Game Engine Prepares for the Future by Optimizing
Success Story Intel® Software Partner Program Game Engine Prepares for the Gaming Focus Future by Optimizing for Multi-Core Intel® Processors The Intel® Software Partner Program guides The Game Creators toward the multi-core future for their FPS Creator X10* development environment. The Game Creators, based in Lancashire, United Kingdom, helps independent “DirectX* 10 lets games game developers cut down the time required to make new titles and reduce render hundreds of enemy characters, each with their the complexity of supporting the latest hardware. Intuitive, drag-and-drop own individual behaviors. interfaces automate otherwise-tedious details for the developer. While high- That kind of scenario is quality 3-D games can be created in this fashion without writing a line of incredibly CPU-intensive, code, the FPS Creator X10* product also provides the capability to modify so it’s critical to have very solid multi-threading built game elements by means of a simple scripting language. By building optimized into the engine.” support for the latest PC hardware into the platform, The Game Creators - Lee Bamber, CEO and FPS Creator relieves game developers from difficult tasks like multi-threading, which X10* Lead Engineer, The Game Creators allows them to focus on their games instead of performance details. Challenge: Prepare the FPS Creator* game- Meeting the needs of independent game developers development environment to create titles that take better advantage of FPS Creator X10* provides building blocks for assembling high-quality first-person shooter games without current and future generations of coding. Multi-threading within the platform enables the finished product to make good use of multiple PC hardware. -

The Different Types of Tools You Can Use to Make Games • the Various Media and Skills Needed • Resources That Will Help You Start Your Game Development Journey
This free e-book is an introduction to the art of video game creation. Learn about: • The different types of tools you can use to make games • The various media and skills needed • Resources that will help you start your game development journey TheGameCreators CEO, Lee Bamber, introduces you to this e-book. With over 25 years of game making experience he has some great nuggets of information to share with you to help you on your way. How to start making video games - TheGameCreators – www.thegamecreators.com Page 1 Introduction Lee Bamber – CEO of TheGameCreators I published my first game maker a great many years ago, and to this day the question I’ve answered countless times has been “How do I make a game?”. As you can imagine the answer has changed over the years as the landscape of games technology evolved; from tiny efforts knocked up in a few weeks to games so epic they need hundreds of people and millions of dollars to produce. Today, my answer is to provide you with this little starter guide, introducing a range of game makers that meet a range of needs from non-coding game creation to professional games programming. The first time I heard the above question was in my own ten-year-old head, coinciding with the arrival of my first computer, and only Christmas present that year, the VIC-20. This hugely underpowered 8- bit brick had just over 3Kb of programmable memory, but it had several games and a book on how to code - naturally I was hooked for life. -

One Level 5 Barbarian for 94800 Won: the International Effects Of
FOR SALE--ONE LEVEL 5 BARBARIAN FOR 94,800 WON: THE INTERNATIONAL EFFECTS OF VIRTUAL PROPERTY AND THE LEGALITY OF ITS OWNERSHIP Alisa B. Steinberg* TABLE OF CONTENTS I. INTRODUCTION ......................................... 382 II. WHY ALL THE FUSS ABOUT VIRTUAL PROPERTY-WHAT IS IT AND How DID IT DEVELOP?. ..... 386 A. Types of MMORPGs ............................. ..... 386 B. Virtual Property Versus Real- World Property ......... ..... 389 C. TraditionalProperty Theories as Applied to Virtual Property ................................ ..... 390 D. The CurrentSituation ............................ ..... 393 III. EULA AS A METHOD OF PRIVATE REGULATION ............... 395 IV. How COUNTRIES HAVE REACTED TO VIRTUAL PROPERTY ISSUES ................................................ 398 A. Virtual Propertyand Taxation .......................... 399 B. Gold Farming ....................................... 403 C. CriminalLaw and Virtual Property ...................... 407 D. The United States' Missed Opportunity ................... 410 V. POTENTIAL SOLUTIONS TO THE PROBLEMS WITH VIRTUAL PROPERTY ............................................. 412 A. Adverse Possessionas a Tool to Establish a Claim to Virtual Property .............................. 412 B. Civil Law Countriesv. Common Law Countries ............ 417 VI. CONCLUSION ...................................... ..... 419 * J.D., University of Georgia School of Law, 2009; B.A., History and Political Science, Emory University 2005. The author gratefully acknowledges the help of Jim Cronon and Jim -

Game Developer
ANNIVERSARY10 ISSUE >>PRODUCT REVIEWS TH 3DS MAX 6 IN TWO TAKES YEAR MAY 2004 THE LEADING GAME INDUSTRY MAGAZINE >>VISIONARIES’ VISIONS >>JASON RUBIN’S >>POSTMORTEM THE NEXT 10 YEARS CALL TO ACTION SURREAL’S THE SUFFERING THE BUSINESS OF EEVERVERQQUESTUEST REVEALEDREVEALED []CONTENTS MAY 2004 VOLUME 11, NUMBER 5 FEATURES 18 INSIDE EVERQUEST If you’re a fan of making money, you’ve got to be curious about how Sony Online Entertainment runs EVERQUEST. You’d think that the trick to running the world’s most successful subscription game 24/7 would be a closely guarded secret, but we discovered an affable SOE VP who’s happy to tell all. Read this quickly before SOE legal yanks it. By Rod Humble 28 THE NEXT 10 YEARS OF GAME DEVELOPMENT Given the sizable window of time between idea 18 and store shelf, you need to have some skill at predicting the future. We at Game Developer don’t pretend to have such skills, which is why we asked some of the leaders and veterans of our industry to give us a peek into what you’ll be doing—and what we’ll be covering—over the next 10 years. 36 28 By Jamil Moledina POSTMORTEM 32 THE ANTI-COMMUNIST MANIFESTO 36 THE GAME DESIGN OF SURREAL’S Jason Rubin doesn’t like to be treated like a nameless, faceless factory worker, and he THE SUFFERING doesn’t want you to be either. At the D.I.C.E. 32 Before you even get to the problems you typically see listed in our Summit, he called for lead developers to postmortems, you need to nail down your design. -

Recognizing Virtual Property Rights, It's About Time John S
Seton Hall University eRepository @ Seton Hall Law School Student Scholarship Seton Hall Law 2010 Recognizing Virtual Property Rights, It's About Time John S. Chao Seton Hall Law Follow this and additional works at: https://scholarship.shu.edu/student_scholarship Part of the Intellectual Property Law Commons, and the Internet Law Commons Recommended Citation Chao, John S., "Recognizing Virtual Property Rights, It's About Time" (2010). Law School Student Scholarship. 45. https://scholarship.shu.edu/student_scholarship/45 RECOGNZING VIRTUAL PROPERTY RIGHTS, IT’S ABOUT TIME John S. Chao I. Introduction Today’s technological advances have brought about a new social phenomenon, a new way for people to interact and communicate with one another, virtual worlds. 1 These virtual worlds are made up of people from across the globe that connect and interact with each other inside the virtual world where the participants are represented by visual depictions of user customizable avatars.2 Virtual worlds have evolved and developed from simple chat rooms and text based Multi-User Dimensions (“MUDs”) on bulletin board servers (“BBS”) where the number of users that can simultaneously log in was limited to a handful of users to today’s massive multiplayer online role playing games (“MMORPGs”) which can host millions of users simultaneously.3 In these virtual worlds, players can make new friends or adventure with old friends, explore exotic locales, purchase islands, design and market new fashion lines, slay dragons, and 1 Where the Internet brought about worldwide communication through emails, message boards, and websites, virtual worlds allow users to interact with each other not merely through text but visually within a three dimensional environment created specifically to allow for more intimate social interactions and game play. -

PDF Download Sticker Dolly Dressing Dolls Pdf Free Download
STICKER DOLLY DRESSING DOLLS Author: Fiona Watt,Vici Leyhane Number of Pages: 34 pages Published Date: 17 Feb 2014 Publisher: Usborne Publishing Ltd Publication Country: London, United Kingdom Language: English ISBN: 9780746075487 DOWNLOAD: STICKER DOLLY DRESSING DOLLS Sticker Dolly Dressing Dolls PDF Book The authors: challenge simplified rhetoric about school behaviour help practitioners identify real areas and effective methods for improvement. The SAT and ACT verbal portionstest important reading comprehension skills that many students are unprepared for or need extra help with. Explanations and examples are illustrated throughout with detailed colour charts. ProceedingsOn behalf of the Program Committee, it is our pleasure to present the p- ceedings of the 12th International Symposium on Recent Advances in Intrusion Detection systems (RAID 2009),which took place in Saint-Malo,France, during September 23-25. With a few minutes of practice a day, you can change the way you interact with everyone around you. That is, until now. Much stronger coverage of social history than its competitors. This book allows you unprecedented access to the way the masters of the craft approach their work. Do you wish there was a fast and easy way to study for the exam AND boost your score. This comprehensive handbook has it all. Sticker Dolly Dressing Dolls Writer Features a foreword by Dennis McKenna, cover art by Beau Deeley, and thirty color illustrations by various artists, including Alex Grey, Android Jones, Martina Hoffmann, Luke Brown, Carey Thompson, Adam Scott Miller, Randal Roberts, along with Jay Bryan, Cyb, Orryelle Defenestrate-Bascule, Art Van D'lay, Stuart Griggs, Jay Lincoln, Gwyllm Llwydd, Shiptu Shaboo, Marianna Stelmach, and Mister Strange. -
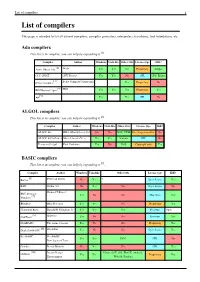
List of Compilers 1 List of Compilers
List of compilers 1 List of compilers This page is intended to list all current compilers, compiler generators, interpreters, translators, tool foundations, etc. Ada compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [2] Aonix Object Ada Atego Yes Yes Yes Proprietary Eclipse GCC GNAT GNU Project Yes Yes No GPL GPS, Eclipse [3] Irvine Compiler Irvine Compiler Corporation Yes Proprietary No [4] IBM Rational Apex IBM Yes Yes Yes Proprietary Yes [5] A# Yes Yes GPL No ALGOL compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? ALGOL 60 RHA (Minisystems) Ltd No No DOS, CP/M Free for personal use No ALGOL 68G (Genie) Marcel van der Veer Yes Yes Various GPL No Persistent S-algol Paul Cockshott Yes No DOS Copyright only Yes BASIC compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [6] BaCon Peter van Eerten No Yes ? Open Source Yes BAIL Studio 403 No Yes No Open Source No BBC Basic for Richard T Russel [7] Yes No No Shareware Yes Windows BlitzMax Blitz Research Yes Yes No Proprietary Yes Chipmunk Basic Ronald H. Nicholson, Jr. Yes Yes Yes Freeware Open [8] CoolBasic Spywave Yes No No Freeware Yes DarkBASIC The Game Creators Yes No No Proprietary Yes [9] DoyleSoft BASIC DoyleSoft Yes No No Open Source Yes FreeBASIC FreeBASIC Yes Yes DOS GPL No Development Team Gambas Benoît Minisini No Yes No GPL Yes [10] Dream Design Linux, OSX, iOS, WinCE, Android, GLBasic Yes Yes Proprietary Yes Entertainment WebOS, Pandora List of compilers 2 [11] Just BASIC Shoptalk Systems Yes No No Freeware Yes [12] KBasic KBasic Software Yes Yes No Open source Yes Liberty BASIC Shoptalk Systems Yes No No Proprietary Yes [13] [14] Creative Maximite MMBasic Geoff Graham Yes No Maximite,PIC32 Commons EDIT [15] NBasic SylvaWare Yes No No Freeware No PowerBASIC PowerBASIC, Inc. -
AGK Meets .NET Beginners Guide
AGK Meets .NET Beginners Guide If you are a fan of the .NET family of languages – C#, Visual Basic, and so forth – and you own a copy of AGK, then you’ve got a new toy to play with. The AGK Wrapper for .NET is an open source project that provides a coupling between the AGK library and the Common Language Runtime (the source can be found at http://agkwrapper.codeplex.com/, the compiled binaries are available from your order history). Now, before you get too excited, it should be noted that as-is the wrapper is Windows only, for a variety of reasons that I won’t get into here. So if you are planning on making the next cross-platform blockbuster, you may want to get dirty with C++ or stick to Tier 1 Basic. But if your target is Windows, or you want the rapid prototyping power of C#/VB, then read on. For this example I’ll be using C#, but most of what I’m doing applies to VB as well (and I’ll throw some VB specific notes in as well). Getting Started First, you need to create new project. I’m going to start with a Console project, because it is a nice minimal setup with few dependencies and only a couple settings that need to be adjusted. 1 | by Conner Irwin AGK Meets .NET Beginners Guide Once we’ve created the console project, we need to change a few things. For one, we need to change it from a console application to a normal Windows application (since I assume you don’t want a command line popping up with your game window!). -

Proquest Dissertations
INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UMI films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality of this reproduction is dependent upon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adversely affect reproduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-hand comer and continuing from left to right in equal sections with small overlaps. Photographs included in the original manuscript have been reproduced xerographically in this copy. Higher quality 6” x 9” black and white photographic prints are available for any photographs or illustrations appearing in this copy for an additional charge. Contact UMI directly to order. Bell & Howell Information and Learning 300 North Zeeb Road, Ann Artx)r, Ml 48106-1346 USA 800-521-0600 UMI* PLAY BY THE RULES: THE CREATION OF BASKETBALL AND THE PROGRESSIVE ERA. 1891-1917 DISSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Marc Thomas Horger, M.A. The Ohio State University 2001 Dissertation Committee: Approved by Professor K. -

Table of Contents
AN INTERPRETIVE PHENOMENOLOGICAL INQUIRY INTO FULFILLMENT OF CHOICE THEORY’S FOUR BASIC PSYCHOLOGICAL NEEDS THROUGH CONSOLE VIDEO GAME ENGAGEMENT A dissertation submitted to the Kent State University College and Graduate School of Education, Health, and Human Services in partial fulfillment of the requirements for the degree of Doctor of Philosophy By Joseph R. Alexander May 2015 © Copyright, 2015 by Joseph R. Alexander All Rights Reserved ii A dissertation written by Joseph R. Alexander B.A., Ohio University, 2007 M.A., Kent State University, 2010 Ph.D., Kent State University, 2015 Approved by ___________________________, Co-director, Doctoral Dissertation Committee Betsy Page ___________________________, Co-director, Doctoral Dissertation Committee Steve Rainey ___________________________, Member, Doctoral Dissertation Committee Alicia R. Crowe Accepted by ___________________________, Director, School of Lifespan Development and Mary M. Dellmann-Jenkins Educational Sciences ___________________________, Dean, College Education, Health, and Human Daniel F. Mahony Services iii ALEXANDER, JOSEPH R., May 2015 Counseling and Human Development Services AN INTERPRETIVE PHENOMENOLOGICAL INQUIRY INTO FULFILLMENT OF CHOICE THEORY’S FOUR BASIC PSYCHOLOGICAL NEEDS THROUGH CONSOLE VIDEO GAME ENGAGEMENT (219 pp.) Co-Directors of Dissertation: Steve Rainey, Ph.D. Betsy Page, Ed.D. This study sought to understand how people satisfy needs by engaging in console-based video games and ultimately help counselors understand clients’ need fulfillment by video games. Data has been collected on the players’ experiences and thoughts on how console-based video games meet the four basic psychological needs of choice theory. After reviewing the participants’ data, patterns and themes have been generated and reported from the dialog of the participants. These patterns and themes were used to inform professional counselor readers how to assist video game playing clients understand their basic psychological needs more efficiently. -

The Living Dungeon: Space, Convention, and Reinvention in Dungeon Games
The Living Dungeon: Space, Convention, and Reinvention in Dungeon Games by Zachary Selman Palmer thesis submitted in partial fulfillment of the requirements for the degree of #aster of rts Department of Digital Humanities %niversity of lberta & Zachary Selman Palmer, 2019 Abstract cross digital and tabletop gaming, the ‘dungeon’ has been a generic setting with enduring popularity for decades. staple of games of medieval fantasy-themed adventure, the traditional dungeon is a subterranean labyrinth full of monsters, traps, and treasures into which brave or foolish adventurers face danger for glory or gold. This thesis recogni0es ‘the dungeon’ as it relates to game production and game culture as a peculiarly rich spatial concept. Through this work, I ans-er ans-ering not just “-hat is a dungeon?6 – but, more provocatively, “-hat could be a dungeon?6 or 4-hat does a dungeon do56 Ultimately, I argue the dungeon operates much like a genre, establishing a commonly-understood range of expectations for game creators and a comfortable range of expectations for game audiences and providing opportunities for subversion. I turn to game studies, implementation of genre as more than a taxonomic label, but a communication tool that provides a range of predictable expressions and experiences for creators and audiences that also creates the possibility for subversion. I argue that the dungeon convention provides much the same advantages of a genre to game creators and game audiences. s a dungeon is a convention of space and not a cultural work in itself, my understanding of genre is supplemented by an understanding of space as actively and culturally constructed through human action.