Nuclear Penalized Multinomial Regression with an Application to Predicting at Bat Outcomes in Baseball
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2016 PHILADELPHIA PHILLIES (71-91) Fourth Place, National League East Division, -24.0 Games Manager: Pete Mackanin, 2Nd Season
2016 PHILADELPHIA PHILLIES (71-91) Fourth Place, National League East Division, -24.0 Games Manager: Pete Mackanin, 2nd season 2016 SEASON RECAP: Philadelphia went 71-91 (.438) in 2016, an eight-win improvement from the previous year (63 W, .388 win %) … It marked the Phillies fourth consecutive season under .500 (73- PHILLIES PHACTS 89 in both 2013 & 2014, 63-99 in 2015), which is their longest streak since they posted seven consecutive Record: 71-91 (.438) losing seasons from 1994 to 2000 ... The Phillies finished in 4th place in the NL East, 24.0 games behind Home: 37-44 the Washington Nationals, and posted 90 or more losses in a season for the 39th time in club history … Road: 34-47 Philadelphia had 99 losses in 2015, marking the first time they have had 90+ losses in back-to-back Current Streak: Won 1 Last 5 Games: 1-4 seasons since 1996-97 (95, 94) … Overall, the club batted .240 this year with a .301 OBP, .384 SLG, Last 10 Games: 2-8 .685 OPS, 427 extra-base hits (231 2B, 35 3B, 161 HR) and a ML-low 610 runs scored (3.77 RPG) … Series Record: 18-28-6 Phillies pitchers combined for a 4.63 ERA (739 ER, 1437.0 IP), which included a 4.41 ERA for the starters Sweeps/Swept: 6/9 and a 5.01 mark for the pen. PHILLIES AT HOME HOT START, COOL FINISH: Philadelphia began the season with a 24-17 record over their first 41 th Games Played: 81 games … Their .585 winning percentage over that period (4/4-5/18) was the 6 -best in MLB, trailing Record: 37-44 (.457) only the Chicago Cubs (.718, 28-11), Baltimore Orioles (.615, 24-15), Boston Red Sox (.610, 25-16), CBP (est. -

September 12, 2011
September 12, 2011 Page 1 of 30 Clips (September 12, 2011) September 12, 2011 Page 2 of 30 From LATimes.com Angels let one get away against the Yankees Peter Bourjos drops a fly ball in the seventh inning that leads to a 6-5 win for New York and leaves the Angels 2 1/2 games behind Texas. By Baxter Holmes After racing in the shadows for much of the season, the Angels now find themselves in the spotlight during their American League West pennant race with the Texas Rangers. But Sunday, when the glare was upon them with a chance to sweep the New York Yankees, they blinked. Angels outfielder Peter Bourjos dropped a fly ball in the seventh inning when he lost track of it in the sun, allowing the Yankees to take the lead that Mariano Rivera held on to with his 599th save, giving the Yankees a 6-5 win at Angel Stadium. The Angels are 21/2 games behind Texas in the AL West with 16 games remaining, the next 10 of which are on the road, starting Monday with a three-game series in Oakland. "It's a play I've got to make," Bourjos said. "It was a turning point in the game, and we lost the game right there." Angels Manager Mike Scioscia wasn't too hard on the 24-year-old, who has been an excellent outfielder for the Angels this season but missed that ball and overran one in the fourth that Eric Chavez turned into a double. "This is not an easy outfield with the wind and the sun, and that ball was flying today," Scioscia said. -

St. Louis Cardinals (45-40) at San Francisco Giants (46-38) Game #86 N AT&T Park N July 3, 2014 Carlos Martinez (1-3, 4.13) Vs
St. Louis Cardinals (45-40) at San Francisco Giants (46-38) Game #86 N AT&T Park N July 3, 2014 Carlos Martinez (1-3, 4.13) vs. Madison Bumgarner (9-5, 2.90) K BIRD WATCHING: The 2013 National League Champion St. Louis Cardinals are in the midst of their 123rd TODAY’S GAME : The Cardinals conclude a 10- season of play in the National League...St. Louis shutout the San Francisco Giants 2-0 behind the pitching of game/11-day road trip through the National Adam Wainwright (7.2 IP), Pat Neshek (0.1) and Trevor Rosenthal (1.0, SV #25). Matt Carpenter and Matt Hol - League West Division (COL 2-1, LA-1-3, SF-3) this liday each had RBI singles in the 3rd inning to provide the Cardinals offense... STANDINGS SNAPSHOT: The Car - afternoon. Today, the Cardinals play the third of dinals are in 2nd place in the N.L. Central, 5.5 games back of 1st place Milwaukee and one half game in front a three-game series with the 2012 World Cham - of 3rd place Pittsburgh, who were tied for second place for all of two hours last night...St. Louis owns the N.L.’s pion San Francisco Giants at 2:45 p.m. Central 6th-best winning pct. (.529) through 85 games. time. Following the game, the Cardinals depart K back to St. Louis and a 4th of July tilt with Miami CARPENTER NAILS THE GIANTS: Matt Carpenter is batting .524 (11-21) against the Giants this season, ranking at Busch Stadium to begin a seven-game homes - first among MLB batters. -

A's News Clips, Wednesday, April 27, 2011 Brandon Mccarthy
A’s News Clips, Wednesday, April 27, 2011 Brandon McCarthy, Oakland A's offense struggle in loss to Los Angeles Angels By Joe Stiglich, Oakland Tribune ANAHEIM -- A's starter Brandon McCarthy was left in long enough to allow 14 hits Tuesday night against the Los Angeles Angels. Some were dinks. Some were well-struck. They all hurt, and the Angels handed the A's an 8-3 defeat in front of 37,228 fans at Angel Stadium. That clinched the three-game series for Los Angeles and assured the A's a losing record on their seven-game road trip against American League West foes. After Jered Weaver shut them out Monday, it appeared the A's were getting their easiest assignment of the series against rookie right-hander Tyler Chatwood. The A's scraped together just six hits. After taking the lead on Conor Jackson's two-run homer in the third, the A's didn't notch another hit until Kevin Kouzmanoff's double with two outs in the ninth. "It's just one of those things we've got to put behind us and try to salvage the series," Jackson said. The A's will try to avoid a three-game sweep Wednesday against former Athletic Dan Haren, who brings a 4-1 record and 1.46 ERA into the game. McCarthy came in with a 2.10 ERA. He gave up 14 hits in 51/3 innings and left with the A's trailing 7-3. It was the most hits allowed by an A's starter since Barry Zito surrendered 15 in a July 8, 2003, game against Tampa Bay. -

THURSDAY, AUGUST 3, 2017 at HOUSTON ASTROS LH Blake Snell (0-6, 4.87) Vs
THURSDAY, AUGUST 3, 2017 at HOUSTON ASTROS LH Blake Snell (0-6, 4.87) vs. RH Collin McHugh (0-0, 4.22) First Pitch: 8:10 p.m. ET | Location: Minute Maid Park, Houston, Texas | TV: Fox Sports Sun | Radio: WDAE 620 AM, WGES 680 AM (Sp.) Game No.: 110 (56-53) | Road Game No.: 58 (27-30) | All-Time Game No.: 3,186 (1,476-1,709) | All-Time Road Game No.: 1,594 (667-926) April: 12-14 | May: 17-13 | June: 13-13 | July: 12-13 | August: 2-0 | Pre-All-Star: 47-43 | Post-All-Star: 9-10 BOUND FOR COOPERSTOWN—3B Evan Longoria has agreed to do- RAYS vs. ASTROS—The winner of tonight’s game will win the season se- nate his batting helmet from Tuesday’s game, when he recorded the sec- ries, currently tied 3-3…the Rays have not lost the season series to Hous- ond cycle in Rays history, to the National Baseball Hall of Fame in Cooper- ton since 2008 (1-2), winning five consecutively (2010-11, 2013-15) and stown, N.Y. …it will be the second artifact Longo has sent to Cooperstown, finishing in a tie (3-3) last season…the Rays own a 27-18 (.600) record following the bat he used on Sep 28, 2011 vs. NYY (“Game 162”) to hit a all-time…they are 12-7 at home, 15-11 in Houston…they are 21-12 (.636) Wild Card-clinching 12th-inning home run…for a detailed list of Rays ar- since the Astros joined the AL in 2013. -

42615 Layout 1
St. Louis Cardinals (12‐4) at Milwaukee Brewers (3‐15) Game #17 ◆ Miller Park ◆ April 26, 2015 Lance Lynn (1‐1, 1.56) vs. Mike Fiers (0‐2, 6.75) ❑ BIRD WATCHING: The 2014 N.L. Central Champion St. Louis Cardinals have opened their 124th sea‐ TODAY’S GAME: The Cardinals play the final of son of play with a 5‐0‐1 series record and are in 1st place in the NL Central 3 games ahead, of Chicago... three games today at Milwuakee (2‐0) and will St. Louis won 5‐3 last night, securing the 5th series win on the season...Kolten Wong picked up the be looking for their second series sweep on the game‐winning RBI in the 2nd inning with the team’s 1st triple this year...Matt Holliday hit a 3‐run season after winning three vs. CIN last weekend homer, his first home run of the year, and Matt Carpenter extended his hitting streak to 12 games. (4/17‐19)...St. Louis won the series (2‐1) vs. the ❑ WAINWRIGHT PLACED ON DL: Adam Wainwright injured his left ankle during his at‐bat in the 5th Nationals at Washington to begin this road trip... inning last night, causing him to leave the game after 4.0 shutout innings...the team placed Wainwright these two teams last saw each other eight days on the 15‐day disabled list earlier today with a left Achilles and low ankle injury and recalled catcher ago as the Brewers opened the home portion of Cody Stanley from Memphis (AAA)...Stanley had appeared in 15 games for the Redbirds and has a the Cardinals 2015 schedule...St. -

THURSDAY, APRIL 20, 2017 Vs. DETROIT TIGERS RH Erasmo Ramirez (1-0, 3.72) Vs
THURSDAY, APRIL 20, 2017 vs. DETROIT TIGERS RH Erasmo Ramirez (1-0, 3.72) vs. LH Daniel Norris (1-0, 2.19) First Pitch: 1:10 p.m. | Location: Tropicana Field, St. Petersburg, Fla. | TV: None | Radio: WDAE 620 AM Game No.: 17 (8-8) | Home Game No.: 10 (7-2) | All-Time Game No.: 3,093 (1,428-1,664) | All-Time Home Game No.: 1,550 (787-762) SALUTING JACKIE TOMORROW—Tomorrow the Rays organization will their worst season series vs. the Tigers. hold a Breaking Barriers event to commemorate the 70th anniversary of Ê Tigers DH Victor Martinez is a career .346/.409/.525 (116-for-335) Jackie Robinson breaking baseball’s color barrier in 1947…the Rays will hitter in 85 games vs. the Rays…that avg. ranks 3rd all-time among wear special T-shirts for BP…the Rays are also offering a Jackie Robinson Rays opponents (min. 250 PA), behind a pair of other former catch- Night ticket special for two (2) lower-box tickets for $42, available online at ers: MIN Joe Mauer (.358) and Hall of Famer Ivan Rodriguez raysbaseball.com/42 or at the Tropicana Field box office…many more pre- (.351)…at Tropicana Field, Martinez owns a .353 (66-for-187) mark. game festivities are planned; see separate release later today for details… MLB’s official Jackie Robinson Day was Saturday in Boston. SOUZA-PALOOZA—RF Steven Souza Jr. has reached base multiple times in 11 games this season, tied with KC Lorenzo Cain for most such RAY MATTER—The Rays won last night, 8-7, in walk-off fashion on a games in the AL…Souza leads the team with a .328 avg., 12 RBI (T-6th in throwing error by Tigers SS José Iglesias, allowing both the tying (Kevin AL), 10 walks (T-7th in AL), .426 OBP (7th in AL) and .421 avg. -

2016 Topps Updates Checklist
BASE TRADED PLAYERS US6 Chris Herrmann Arizona Diamondbacks® US7 Blaine Boyer Milwaukee Brewers™ US8 Pedro Alvarez Baltimore Orioles® US10 John Jaso Pittsburgh Pirates® US11 Erick Aybar Atlanta Braves™ US12 Matt Szczur Chicago Cubs® US14 Chris Capuano Milwaukee Brewers™ US16 Alexei Ramirez San Diego Padres™ US20 Junichi Tazawa Boston Red Sox® US22 Neil Walker New York Mets® US26 Jose Lobaton Washington Nationals® US28 Alfredo Simon Cincinnati Reds® US32 Juan Uribe Cleveland Indians® US35 Joaquin Benoit Toronto Blue Jays® US36 Yonder Alonso Oakland Athletics™ US37 Jon Niese New York Mets® US41 Mark Melancon Washington Nationals® US42 Andrew Miller Cleveland Indians® US46 Steven Wright Boston Red Sox® US47 Austin Romine New York Yankees® US49 Ivan Nova Pittsburgh Pirates® US51 Steve Pearce Baltimore Orioles® US55 Vince Velasquez Philadelphia Phillies® US60 Daniel Hudson Arizona Diamondbacks® US61 Jed Lowrie Oakland Athletics™ US64 Steve Pearce Baltimore Orioles® US66 Fernando Rodney Miami Marlins® US71 Kelly Johnson New York Mets® US75 Alex Colome Tampa Bay Rays™ US76 Yunel Escobar Angels® US77 Wade Miley Baltimore Orioles® US78 Jay Bruce New York Mets® US80 Aaron Hill Boston Red Sox® US82 Chad Qualls Colorado Rockies™ US83 Bud Norris Los Angeles Dodgers® US87 Asdrubal Cabrera New York Mets® US90 Jake McGee Colorado Rockies™ US91 Dan Jennings Chicago White Sox® US94 Adam Lind Seattle Mariners™ US95 Hector Neris Philadelphia Phillies® US97 Cameron Maybin Detroit Tigers® US98 Mike Bolsinger Los Angeles Dodgers® US100 Andrew Cashner Miami Marlins® -

Insert Text Here
ANGELS (9-16) @ ATHLETICS (15-12) RHP GARRETT RICHARDS (1-1, 3.65 ERA) vs. RHP JARROD PARKER (0-4, 8.10) O.Co COLISEUM – 7:07 PM PDT TV – KCOP RADIO – KLAA AM 830 TUESDAY, APRIL 30, 2013 GAME #26 (9-16) OAKLAND, CA ROAD GAME #14 (3-10) LEADING OFF: Tonight, the Angels play the sixth game (1- @ OAKLAND: In last meeting, Angels were swept at home 4) of a seven-day, seven-game road trip to Seattle (April by A’s for first time since Oct. 4-7, 2001…Angels are 0-4 THIS DATE IN ANGELS HISTORY 25-28; 1-3) and Oakland (April 29-May 1; 0-1)…Angels’ 9- against A’s for first time since starting 0-5 against Oakland April 30 16 mark after 25 games is tied for worst mark in club in 1990…Two of the three longest games in Angels history (2002) Angels scored 21 runs history (5th time, last, 1994)…Halos have dropped seven have come against the A’s (last night, 19 innings; 7/9/71, 20 on 22 hits defeating the Indians of last eight road games…LAA is 7-8 in last 15 contests innings)…A’s claimed 2012 season series 10-9 with the 21-2 at Jacobs Field…21 runs marked the second most in club but has dropped six of last eight games overall…Club is 5- Halos dropping seven of 10 contests at Angel Stadium history (26) and the 10-run 12 vs. A.L. West foes…2013 represents the Angels’ 53rd against Oakland…Halos have lost three straight season eighth inning marked the season in the Majors and 48th campaign in Anaheim. -

At Baltimore Orioles (67-49) Game #116 N Oriole Park at Camden Yards N August 10, 2014 Lance Lynn (11-8, 2.89) Vs
St. Louis Cardinals (61-54) at Baltimore Orioles (67-49) Game #116 N Oriole Park at Camden Yards N August 10, 2014 Lance Lynn (11-8, 2.89) vs. Kevin Gausman (6-3, 3.77) K BIRD WATCHING: The 2013 National League Champion St. Louis Cardinals are in the midst of their 123rd season TODAY’S GAME : The Cardinals continue a six- of play in the National League...St. Louis lost to Baltimore yesterday afternoon by a score of 10-3 as the Orioles hit game roadtrip with the last of a three-game se - three home runs. Jon Jay hit a solo home run and Jhonny Peralta hit two doubles in the game for the Cardinals... STANDINGS SNAPSHOT: St. Louis is in 3rd place in the N.L. Central, 3.0 games behind 1st place Milwau - ries at Baltimore today at 12:35 p.m. Today’s kee, a 0.5 game behind 2nd place Pittsburgh and 3.0 games in front of 4th place Cincinnati. game will be televised on Fox Sports Midwest K with Dan McLaughlin and Rick Hoston on the STREETCAR SERIES GOES NATIONAL: The Cardinals and Orioles (then-St. Louis Browns) used to share the same building in Sportsman’s Park in St. Louis and played in the 1944 World Series (Cardinals won 4-2) before the Browns call. Following the game, the Cardinals travel to moved to Baltimore and became the Orioles. The Cardinals play Baltimore for just the 3rd time in both teams his - Miami for a three-game series with the Marlins tories in the regular season...the Orioles came to Busch Stadium II in 2003 with St. -
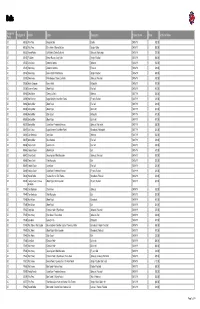
Hologram Prefix Hologram # Pitcher Batter Description Date of Game
Balls Hologram Additional Notes Prefix Hologram # Pitcher Batter Description Date of Game Price JD 540335 Felix Pena Rougned Odor Double 04/05/19 $80.00 JD 540338 Felix Pena Elvis Andrus // Nomar Mazara Single // Strike 04/05/19 $60.00 JD 540352 Hansel Robles Jeff Mathis // Delino DeShields Strike out // Bunt single 04/05/19 $75.00 JD 540355 Ty Buttrey Nomar Mazara // Joey Gallo Single // Foul ball 04/05/19 $60.00 JC 125355 Luis Garcia Asdrubal Cabrera Strike out 04/06/19 $50.00 JC 125343 Drew Smyly Andrelton Simmons Force out 04/06/19 $20.00 JC 125338 Drew Smyly Kevan Smith // Peter Bourjos Single // Foul ball 04/06/19 $60.00 JC 125339 Drew Smyly Peter Bourjos // Tommy La Stella Strike out // Foul ball 04/06/19 $50.00 JC 125356 Adrian Sampson Kevan Smith Hit by pitch 04/06/19 $40.00 JC 125359 Jeanmar Gomez Albert Pujols Foul ball 04/06/19 $40.00 JD 540392 Chris Martin Tommy La Stella Strike out 04/07/19 $50.00 JD 540394 Noe Ramirez Logan Forsythe // Isiah Kiner-Falefa Fly out // Foul ball 04/07/19 $20.00 JD 540366 Shelby Miller Albert Pujols Foul ball 04/07/19 $40.00 JD 540365 Shelby Miller Albert Pujols Ball in dirt 04/07/19 $40.00 JD 540368 Shelby Miller Zack Cozart Hit by pitch 04/07/19 $40.00 JD 540367 Shelby Miller Albert Pujols Ball in dirt 04/07/19 $40.00 JD 540372 Shelby Miller Justin Bour // Andrelton Simmons Strike out // Ball in dirt 04/07/19 $50.00 JD 540387 Luis Garcia Logan Forsythe // Isiah Kiner-Falefa Ground out // Hit by pitch 04/07/19 $40.00 JD 540384 Cam Bedrosian Joey Gallo Strike out 04/07/19 $50.00 JD 540377 Shelby -

PHILADELPHIA PHILLIES (32-44) Vs
PHILADELPHIA PHILLIES (32-44) vs. SAN FRANCISCO GIANTS (48-28) Sunday, June 26, 2016 – AT&T Park – 4:05 p.m. EDT – Game 77; Road 39 RHP Aaron Nola (5-7, 4.11) vs. RHP Johnny Cueto (11-1, 2.06) LAST NIGHT’S ACTION: The Phillies beat the Giants, 3-2, in a come-from-behind win, to snap their 6-game losing streak at AT&T Park … Starter Jeremy Hellickson (5-6) earned the win after allowing 2 PHILLIES PHACTS runs – 1 earned – in 6.0 innings … Trailing 2-0 in the 7th inning, the Phillies scored 3 runs on an RBI Record: 32-44 (.421) single by Andres Blanco and a 2-run homer to dead center field by Cameron Rupp … The relief Home: 16-22 combination of rookie Edubray Ramos, David Hernandez and Jeanmar Gomez each pitched a scoreless Road: 16-22 inning with Gomez getting his 20th save of the season. Current Streak: Won 1 Last 5 Games: 2-3 th Last 10 Games: 2-8 SAVING THE DAY: Last night, Jeanmar Gomez became the 19 different Phillie in club history to Series Record: 9-13-2 have 20 saves in a season and only the second of Latino descent joining Jose Mesa who did it three Sweeps/Swept: 2/6 times (2001-03) … He is the first Phillies closer in a decade to amass 20 saves before July 1, the last being Tom Gordon in 2006 who had 21 (in 22 chances) by July 1 … He is the fastest Phillie ever to PHILLIES VS.