Statistical Computing Lesson 4
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Curriculum Vitae Gastaldo Luciana
CURRICULUM VITAE INFORMAZIONI PERSONALI Nome LUCIANA, GASTALDO Indirizzo VIA UNITA’ D’ITALIA, 2 10014 CALUSO (TO) Telefono 347 3090307 E-mail [email protected] Nazionalità Italiana Data di nascita 10 /03/196 4 ESPERIENZE LAVORATIVE ESCLUSIVE E CONDIVISE • Date (da – a) 2002 RIORDINO DELL ’ARCHIVIO STORICO DEI COMUNI DI STRAMBINO (TO ), BORGOMASINO (TO ) 2001 RIORDINO DELL ’ARCHIVIO STORICO DEI COMUNI DI ROMANO CANAVESE (TO ), PIVERONE (TO ) 2000 RIORDINO DELL ’ARCHIVIO STORICO DEL COMUNE DI LORANZE ’ (TO ) 1996 RIORDINO DELL ’ARCHIVIO STORICO DEI COMUNI DI BAIRO (TO ), NETRO (BI ) 1994 RIORDINO DELL ’ARCHIVIO STORICO DEL COMUNE DI DONATO (BI ) 1993 RIORDINO DELL ’ARCHIVIO STORICO DEL COMUNE DI ISSIGLIO (TO ) 1992 RIORDINO DELL ’ARCHIVIO STORICO DEI COMUNI DI ANDRATE (TO ), NOMAGLIO (TO ) 1990 - 1992 DIPENDENTE DEL LABORATORIO DI RESTAURO D I BENI LIBRARI PAOLO FERRARIS SPA . QUALE ADDETTO ALLA SCHEDATURA E CATALOGA ZIONE COMPUTERIZZATA DEL MATERIALE CARTACEO E MEMBRANACEO . IN COL LABORAZIONE CON CRISTINA CABRINI : 2018 RIORDINO DELL’ARCHIVIO DI DEPOSITO DEL COMUNE DI AGLIE’ (TO), CORIO (TO), CIGLIANO (VC), VALPERGA (TO), MERCENASCO (TO) 2018 RIORDINO DELL’ARCHIVIO STORICO DEL COMUNE DI CUORGNE’ (TO) 2017 -2018 RIORDINO DELL’ARCHIVIO DI DEPOSITO DEL COMUNE DI FAVRIA (TO) 2016 RIORDINO DELL’ARCHIVIO DI DEPOSITO DEL COMUNE DI BAIRO (TO) 2016 RIORDINO DELL’ARCHIVIO DI DEPOSITO DEL COMUNE DI CANDIA CANAVESE (TO) 2016 RIORDINO DELL’ARCHIVIO DI DEPOSITO DEL COMUNE DI VIALFRE’ (TO) 20 16 RIORDINO DELL’ARCHIVIO DI DEPOSITO DEL COMUNE DI -

Candia Canavese Comune Di Candia Canavese Schede Comunali PTC2
ASSESSORATO ALLA PIANIFICAZIONE TERRITORIALE Ufficio di Piano Territoriale di Coordinamento Aggiornamento e adeguamento del Piano Territoriale di Coordinamento Provinciale Variante al PTC1 ai sensi dell'art. 10 della legge regionale n. 56/77 s.m.i., secondo le procedure di cui all'art. 7 Adottata dal Consiglio provinciale con Deliberazione n. 26817 del 20/07/2010 Approvata dal Consiglio regionale con Deliberazione n. 121-29759 del 21/07/2011 (B.U.R. n. 32 del 11/08/2011) SCHEDE COMUNALI LUGLIO 2015 Comune di Candia Canavese Comune di Candia Canavese Schede comunali PTC2 INDICE 1. INFORMAZIONI GENERALI 3 2. CONFORMAZIONE FISICO-MORFOLOGICA 5 3. AREE DI PIANIFICAZIONE TERRITORIALE O PAESISTICA DI COMPETENZA REGIONALE O PROVINCIALE 6 4. AGRICOLTURA E FORESTE 7 5. SISTEMA INSEDIATIVO RESIDENZIALE 8 6. VOCAZIONI STORICO-CULTURALI E AMBIENTALI 10 7. INSEDIAMENTI ECONOMICO-PRODUTTIVI 11 8. INFRASTRUTTURE E MOBILITA' 12 9. ASSETTO IDROGEOLOGICO 14 Comune di Candia Canavese Schede comunali PTC2 1. INFORMAZIONI GENERALI Codice Istat 1050 Inquadramento territoriale Superficie comunale [ha] 913,2 Zona omogenea (art.27 Statuto C.M. approvato 14/4/15) ZONA 9 - EPOREDIESE Ambito di approfondimento sovracomunale (Art.9 NdA) 8 - Caluso Polarità e gerarchie territoriali (Art.19 NdA) - Ambito di diffusione urbana (Art.21-22 NdA) Sì 3 Comune di Candia Canavese Schede comunali PTC2 a. Popolazione e famiglie Fonte: ISTAT (Istituto nazionale di statistica) 1971 1981 1991 2001 2009 2010 2011 Popolazione residente 1.249 1.286 1.319 1.302 1.301 1.317 1.286 Numero di famiglie 570 570 580 Numero medio componenti 2,3 2,3 2,2 Densità abitativa [ab./ha] 1,4 1,4 1,4 Trend demografico 1971/2011 2,9% b. -

Pagina 1 Comune Sede Torino Sede Grugliasco Sede Orbassano Torino
Sede Sede Sede Comune Torino Grugliasco Orbassano Torino 21388 794 461 Moncalieri 987 51 29 Collegno 958 70 41 Numero di iscritti alle Rivoli 894 79 72 sedi UNITO di Torino, Settimo Torinese 832 22 10 Grugliasco e Nichelino 752 26 27 Orbassano distinte Chieri 713 55 14 Grugliasco 683 94 32 Venaria Reale 683 26 23 Ad es. sono 958 i Pinerolo 600 19 37 domiciliati a Collegno Chivasso 445 22 3 che sono iscritti a CdS San Mauro Torinese 432 21 7 Orbassano 404 27 31 sono 70 i domiciliati a Carmagnola 393 24 5 Collegno che sono Ivrea 381 23 1 iscritti a CdS con sede Cirié 346 14 12 Caselle Torinese 323 17 12 sono 41 i domiciliati a Rivalta di Torino 307 28 29 Collegno che sono Piossasco 292 16 25 iscritti a CdS con sede Beinasco 284 16 23 Alpignano 274 24 11 Volpiano 271 12 1 Pianezza 264 18 3 Vinovo 262 11 14 Borgaro Torinese 243 16 1 Giaveno 238 12 11 Rivarolo Canavese 232 7 Leini 225 10 4 Trofarello 224 18 5 Pino Torinese 212 8 3 Avigliana 189 14 16 Bruino 173 6 16 Gassino Torinese 173 10 1 Santena 161 13 4 Druento 159 8 6 Poirino 151 12 5 San Maurizio Canavese 151 8 7 Castiglione Torinese 149 8 2 Volvera 135 5 7 None 133 7 3 Carignano 130 4 1 Almese 124 10 4 Brandizzo 120 4 1 Baldissero Torinese 119 5 1 Nole 118 5 3 Castellamonte 116 5 Cumiana 114 6 9 La Loggia 114 7 3 Cuorgné 111 5 2 Cambiano 108 9 5 Candiolo 108 7 2 Pecetto Torinese 108 6 2 Buttigliera Alta 102 9 4 Luserna San Giovanni 101 7 8 Caluso 100 1 Pagina 1 Sede Sede Sede Comune Torino Grugliasco Orbassano Bussoleno 97 6 1 Rosta 90 12 4 San Benigno Canavese 88 2 Lanzo Torinese -

Ivrea and the Moraine Amphitheatre Visitami CONTENTS
VisitAMI VisitAMIIvrea and the Moraine Amphitheatre VisitAMI CONTENTS 1. Moraine Amphitheatre of Ivrea - AMI 7 Great care and attention have been put into preparing this guide to ensure its reliability and the accuracy of the information. However, Turismo Torino e Provincia would urge you to always check on timetables, prices, 2. Ivrea 8 addresses and accessibility of the sites, products and services mentioned. 3. MaAM 14 4. Things to see at AMI 18 5. Via Francigena Morenico-Canavesana 40 6. Nature in AMI 42 7. Flavours and fragrances 50 8. Events 52 Project: City of Ivrea. Creativity and design: Turismo Torino e Provincia. Thanks for their help: Ines Bisi, Brunella Bovo, Giuliano Canavese, Alessandro Chiesi, Cristiana Ferraro, Gabriella Gianotti, Laura Lancerotto, Mariangela Michieletto, Sara Rizzi, Francesca Tapparo, Norma Torrisi, Fabrizio Zanotti. Sent to press: 2016. This guide is the outcome of the work begun in 2013, VisitAMIcommissioned by the City of Ivrea, in which institutes and associations worked jointly as part of the ongoing project for promoting the Moraine Amphitheatre of Ivrea-AMI (Anfiteatro Morenico di Ivrea). The AMI is described page after page, making the guide a useful way for visitors to discover the many artistic resources and all the natural scenery made even more attractive when combined with the many outdoor activities available. And then there are details about the extensive offer of wine and food and the many events that, during the year, are able to offer a unique, delightful experience. AMI is all this and much more, whose hidden nooks and marvels can be discovered by tourists in the many routes proposed. -

Curriculum Vitae
CURRICULUM VITAE INFORMAZIONI PERSONALI Nome BARBATO SUSANNA Data di nascita 05/12/1972 Qualifica Segretario comunale Amministrazione COMUNE DI CUORGNE’ Responsabile Segreteria comunale convenzionata tra i Comuni di Incarico attuale Cuorgnè 50% e il Comune di Nole 50% Numero telefonico dell’ufficio 0124655210 E-mail istituzionale [email protected] TITOLI DI STUDIO E PROFESSIONALI ED ESPERIENZE LAVORATIVE Titolo di studio Laurea in economia conseguita presso l'Università degli studi di Torino il 18.03.1996 Altri titoli di studio e Iscritta all’Albo Nazionale dei Segretari Comunali e Provinciali per il professionali superamento del corso – concorso per l’accesso in carriera della durata di 18 mesi (gennaio 2002 – luglio 2003) seguito da 6 mesi di tirocinio pratico, presso la Scuola Superiore della Pubblica Amministrazione Locale – Roma. Dicembre 2006: conseguimento dell’idoneità a segretario generale (Fascia B) superando il relativo corso di abilitazione presso la Scuola Superiore della Pubblica Amministrazione Locale – Roma. Esperienze professionali (incarichi ricoperti) 01.02.1997 – 23. 12.2003 Comune di Rivara Responsabile del Servizio Economico Finanziario (ex VII q.f.) 29.12.2003 – 31.05.2007 Segretario Comunale (Fascia C) in convenzione fra i Comuni di Rivara e Ceresole Reale 01.06.2007 – 31.08.2009 Segretario comunale (Fascia B) in convenzione tra i Comuni di Rivara, Ceresole Reale e Cintano 01.09.2009 – 30.06.2013 Segretario Comunale (Fascia B) in convenzione tra i Comuni di Rivara, San Giorgio Canavese e Candia Canavese -
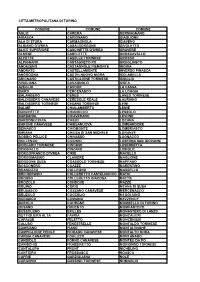
Città Metropolitana Di Torino Comune Comune Comune
CITTÀ METROPOLITANA DI TORINO COMUNE COMUNE COMUNE AGLIÈ CAREMA GERMAGNANO AIRASCA CARIGNANO GIAGLIONE ALA DI STURA CARMAGNOLA GIAVENO ALBIANO D'IVREA CASALBORGONE GIVOLETTO ALICE SUPERIORE CASCINETTE D'IVREA GRAVERE ALMESE CASELETTE GROSCAVALLO ALPETTE CASELLE TORINESE GROSSO ALPIGNANO CASTAGNETO PO GRUGLIASCO ANDEZENO CASTAGNOLE PIEMONTE INGRIA ANDRATE CASTELLAMONTE INVERSO PINASCA ANGROGNA CASTELNUOVO NIGRA ISOLABELLA ARIGNANO CASTIGLIONE TORINESE ISSIGLIO AVIGLIANA CAVAGNOLO IVREA AZEGLIO CAVOUR LA CASSA BAIRO CERCENASCO LA LOGGIA BALANGERO CERES LANZO TORINESE BALDISSERO CANAVESE CERESOLE REALE LAURIANO BALDISSERO TORINESE CESANA TORINESE LEINÌ BALME CHIALAMBERTO LEMIE BANCHETTE CHIANOCCO LESSOLO BARBANIA CHIAVERANO LEVONE BARDONECCHIA CHIERI LOCANA BARONE CANAVESE CHIESANUOVA LOMBARDORE BEINASCO CHIOMONTE LOMBRIASCO BIBIANA CHIUSA DI SAN MICHELE LORANZÈ BOBBIO PELLICE CHIVASSO LUGNACCO BOLLENGO CICONIO LUSERNA SAN GIOVANNI BORGARO TORINESE CINTANO LUSERNETTA BORGIALLO CINZANO LUSIGLIÈ BORGOFRANCO D'IVREA CIRIÈ MACELLO BORGOMASINO CLAVIERE MAGLIONE BORGONE SUSA COASSOLO TORINESE MAPPANO BOSCONERO COAZZE MARENTINO BRANDIZZO COLLEGNO MASSELLO BRICHERASIO COLLERETTO CASTELNUOVO MATHI BROSSO COLLERETTO GIACOSA MATTIE BROZOLO CONDOVE MAZZÈ BRUINO CORIO MEANA DI SUSA BRUSASCO COSSANO CANAVESE MERCENASCO BRUZOLO CUCEGLIO MEUGLIANO BURIASCO CUMIANA MEZZENILE BUROLO CUORGNÈ MOMBELLO DI TORINO BUSANO DRUENTO MOMPANTERO BUSSOLENO EXILLES MONASTERO DI LANZO BUTTIGLIERA ALTA FAVRIA MONCALIERI CAFASSE FELETTO MONCENISIO CALUSO FENESTRELLE MONTALDO -

Uffici Locali Dell'agenzia Delle Entrate E Competenza
TORINO Le funzioni operative dell'Agenzia delle Entrate sono svolte dalle: Direzione Provinciale I di TORINO articolata in un Ufficio Controlli, un Ufficio Legale e negli uffici territoriali di MONCALIERI , PINEROLO , TORINO - Atti pubblici, successioni e rimborsi Iva , TORINO 1 , TORINO 3 Direzione Provinciale II di TORINO articolata in un Ufficio Controlli, un Ufficio Legale e negli uffici territoriali di CHIVASSO , CIRIE' , CUORGNE' , IVREA , RIVOLI , SUSA , TORINO - Atti pubblici, successioni e rimborsi Iva , TORINO 2 , TORINO 4 La visualizzazione della mappa dell'ufficio richiede il supporto del linguaggio Javascript. Direzione Provinciale I di TORINO Comune: TORINO Indirizzo: CORSO BOLZANO, 30 CAP: 10121 Telefono: 01119469111 Fax: 01119469272 E-mail: [email protected] PEC: [email protected] Codice Ufficio: T7D Competenza territoriale: Circoscrizioni di Torino: 1, 2, 3, 8, 9, 10. Comuni: Airasca, Andezeno, Angrogna, Arignano, Baldissero Torinese, Bibiana, Bobbio Pellice, Bricherasio, Buriasco, Cambiano, Campiglione Fenile, Cantalupa, Carignano, Carmagnola, Castagnole Piemonte, Cavour, Cercenasco, Chieri, Cumiana, Fenestrelle, Frossasco, Garzigliana, Inverso Pinasca, Isolabella, La Loggia, Lombriasco, Luserna San Giovanni, Lusernetta, Macello, Marentino, Massello, Mombello di Torino, Moncalieri, Montaldo Torinese, Moriondo Torinese, Nichelino, None, Osasco, Osasio, Pancalieri, Pavarolo, Pecetto Torinese, Perosa Argentina, Perrero, Pinasca, Pinerolo, Pino Torinese, Piobesi Torinese, Piscina, Poirino, Pomaretto, -

ALLEGATO 6 PIANO PROVINCIALE PROV TORINO A.S
ALLEGATO 6 PIANO PROVINCIALE PROV TORINO a.s. 2010/2011 Dati WEBI A.S. 2009/2010 ISCRITTI SETTEMBRE sono esclusi scuole presso ospedali e carceri Grado scolastico Denominazione Indirizzo e n. civico Frazione o Località Comune Provincia PROV DI TORINO Istituto Comprensivo DI AIRASCA VIA STAZIONE 37 AIRASCA TORINO Scuola dell'infanzia . VIA DEL PALAZZO 13 AIRASCA TORINO Scuola dell'infanzia DI SCALENGHE PIAZZA COMUNALE 7 SCALENGHE TORINO Scuola primaria DANTE ALIGHIERI VIA STAZIONE 26 AIRASCA TORINO Scuola primaria PRINCIPESSA DI PIEMONTE VIA TORINO 1 SCALENGHE TORINO Scuola primaria DI SCALENGHE VIA MAESTRA 20 VIOTTO SCALENGHE TORINO Scuola secondaria di I grado . VIA STAZIONE 37 AIRASCA TORINO Scuola secondaria di I grado DI SCALENGHE VIA S. MARIA 40 PIEVE SCALENGHE TORINO Istituto Comprensivo ALMESE PIAZZA DELLA FIERA 3/2 ALMESE TORINO Scuola dell'infanzia PETER PAN BORGATA CHIESA 8 RUBIANA TORINO Scuola dell'infanzia LA GIOSTRA VIA PELISSERE 16/A VILLAR DORA TORINO Scuola primaria REGIONE PIEMONTE PIAZZA COMBA 1 RIVERA ALMESE TORINO Scuola primaria FALCONE - BORSELLINO PIAZZA DELLA CHIESA 16 MILANERE ALMESE TORINO Scuola primaria MONSIGNOR SPIRITO ROCCI PIAZZA DELLA FIERA 3 ALMESE TORINO Scuola primaria G. SIMONE GIRODO PIAZZA ROMA 6 RUBIANA TORINO Scuola primaria COLLODI VIA PELISSERE 1 VILLAR DORA TORINO Scuola secondaria di I grado RIVA ROCCI PIAZZA DELLA FIERA 3/2 ALMESE TORINO Circolo Didattico . VIA CAVOUR 45 ALPIGNANO TORINO Scuola dell'infanzia SERGIO BORELLO VIA EX INTERNATI 7 ALPIGNANO TORINO Scuola dell'infanzia GOBETTI VIA BARACCA 16 ALPIGNANO TORINO Scuola dell'infanzia G. RODARI VIA PIANEZZA 49 ALPIGNANO TORINO Scuola primaria ANTONIO GRAMSCI VIA CAVOUR 45 ALPIGNANO TORINO Scuola primaria F. -

1 L'appalto È Suddiviso Nei Seguenti Lotti: Lotto N.1 CIG 6586486C2E
L’appalto è suddiviso nei seguenti lotti: Lotto n.1 CIG 6586486C2E: Circoscrizioni del Comune di Torino dalla n.1 alla n.3. Lotto n.2 CIG 6586487D01: Circoscrizioni del Comune di Torino dalla n.4 alla n.6. Lotto n.3 CIG 6586488DD4: Circoscrizioni del Comune di Torino dalla n.7 alla n.10. Lotto n.4 CIG 6586489EA7: Comuni di Bruino, Candiolo, Cantalupa, Cumiana, Frossasco, None, Pinerolo, Piossasco, Roletto, Volvera. Lotto n.5 CIG 6586490F7A: Comuni di Airasca, Angrogna, Bibiana, Bobbio Pellice, Bricherasio, Buriasco, Campiglione Fenile, Castagnole Piemonte, Cavour, Cercenasco, Cesana Torinese, Claviere, Fenestrelle, Garzigliana, Inverso Pinasca, Lombriasco, Luserna San Giovanni, Lusernetta, Macello, Massello, Osasco, Osasio, Pancalieri, Perosa Argentina, Perrero, Pinasca, Piobesi, Piscina, Pomaretto, Porte, Pragelato, Prali, Pramollo, Prarostino, Rorà, Roure, Salza di Pinerolo, San Germano Chisone, San Pietro Val Lemina, San Secondo di Pinerolo, Sauze di Cesana, Scalenghe, Sestriere, Torre Pellice, Usseaux, Vigone, Villafranca Piemonte, Villar Pellice, Villar Perosa, Virle Piemonte. Lotto n.6 CIG 6586491052: Comuni di Borgaro Torinese, Collegno, Pianezza, Venaria Reale. Lotto n.7 CIG 6586492125: Comuni di Alpignano, Bardonecchia, Bruzolo, Bussoleno, Chiomonte, Coazze, Exilles, Giaglione, Giaveno, 1 Gravere, Meana di Susa, Moncenisio, Oulx, Rivoli, Salbertrand, Sauze d’Oulx, Trana, Valgioie, Venaus. Lotto n.8 CIG 65864931F8: Comuni di Ala di Stura, Balangero, Balme, Cafasse, Cantoira, Ceres, Chialamberto, Ciriè, Coassolo Torinese, Druento, Fiano, Germagnano, Givoletto, Groscavallo, Grosso, La Cassa, Lanzo Torinese, Lemie, Mathi, Mezzenile, Monastero di Lanzo, Nole, Pessinetto, Robassomero, Rubiana, San Gillio, San Maurizio Canavese, Traves, Usseglio, Val della Torre, Vallo Torinese, Varisella, Villanova Canavese, Viù. Lotto n.9 CIG 65864942CB: Comuni di Beinasco, Grugliasco, Orbassano, Reano, Rivalta di Torino, Rosta, Sangano, Villarbasse. -

Gara D'appalto Servizi Rd Carta
SCS - GARA D'APPALTO SERVIZI RD CARTA - ALLEGATO F: ISOLE ECOLOGICHE INDIRIZZI COMUNE LOCALITA' NOME UTENTE INDIRIZZO AGLIE' SANTA MARIA PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE BORGATA SANTA MARIA, 39 AGLIE' SANTA MARIA PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE BORGATA SANTA MARIA, 48 AGLIE' SANTA MARIA PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE BORGATA SANTA MARIA, 62 AGLIE' AGLIE' PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE CASCINE ANGELLE CHIUMINI, 0 AGLIE' AGLIE' PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE CASCINE CIARLIN, 0 AGLIE' SAN GRATO PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE CASCINE CIECK, 1 AGLIE' SANTA MARIA PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE CASCINE CONTINI, 13 AGLIE' MADONNA DELLE GRAZIE PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE CASCINE GEDDA, 0 AGLIE' SAN GRATO PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE CASCINE GERBOLA, 0 AGLIE' AGLIE' PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE CASCINE LUISETTA, 0 AGLIE' AGLIE' PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE CASCINE MALESINA, 24 AGLIE' MADONNA DELLE GRAZIE PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE CASCINE VOLPATTI, 132 AGLIE' AGLIE' PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE CORSO CAVOUR, 8 AGLIE' AGLIE' PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE PIAZZA UMBERTO I, 1 AGLIE' AGLIE' PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE STRADA BELVEDERE, 6 AGLIE' AGLIE' PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE STRADA PER BAIRO, 6 AGLIE' SAN GRATO PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE STRADA PER CUCEGLIO, 0 AGLIE' AGLIE' PUNTO RACCOLTA PIAZZOLE ISOLE ECOLOGICHE STRADA POLLINO, 0 AGLIE' AGLIE' PUNTO RACCOLTA -

Elenco Dei Comuni Della Cintura E Numero Dei Buoni
ELENCO DEI COMUNI DELLA CINTURA E NUMERO DEI BUONI NECESSARI ELENCO DEI COMUNI DELLA CINTURA E NUMERO DEI BUONI NECESSARI La seguente tabella interessa i recapiti urgenti e i servizi TODAY, SPEED e SPEED + con partenza da Torino. Per le località non presenti nell’elenco la tariffa chilometrica è di €. 0,95 AL Km. (A/R) Balangero .......................... 12 Brandizzo .............................3 Caramagna Piemonte ....20 A Baldissero Canavese ....... 18 Bricherasio .......................20 Caravino ............................20 Acqui Terme .....................40 Baldissero d’Alba ............20 Brosso ................................ 24 Carema ..............................30 Agliè ....................................14 Baldissero Torinese .......... 6 Bruzolo ............................... 17 Carignano ............................5 Airasca ................................10 Balme ................................. 24 Bruino ...................................8 Carmagnola ....................... 12 Ala di Stura ....................... 24 Banchette ......................... 24 Brusasco ............................ 16 Casalborgone ...................14 Alba .................................... 26 Barbania ............................. 13 Buriasco .............................14 Casale Monferrato .......... 22 Albiano D’Ivrea ................ 24 Barbaresco .......................30 Burolo d’Ivrea .................. 24 Casalgrasso ....................... 13 Alessandria ....................... 48 Bardonecchia ................... 38 Busano -

Elenco Dei Collaudatori Cemento Armato Aggiornato Al 6 Novembre 2017 Sez Matr Cognome Nome Studio
Elenco dei Collaudatori cemento armato Aggiornato al 6 novembre 2017 Sez Matr Cognome Nome Studio A 1445 ACCORNERO Pier Franco Torino A 3851 AGHEMO Umberto Collegno A 3960 AGNESE Francesco Torino A 5603 ALBERA Igor Torino A 4351 ALBERTINO Giampiero Carmagnola A 3802 ALBORGHETTI Alessandra Torino A 2379 ALESSI Giovanni Bruino A 9361 ALOISIO Vincenzo Chivasso A 4176 ALPE Paolo Rivoli A 3492 ANCAROLA Filomena Pino Torinese A 5557 ANGELINI Walter Torino A 2356 ANTONACCIO Vincenzo Torino A 2360 ANTONACI Francesco Torino A 3681 ANTONINO Francesca Paola Collegno A 5414 APRA' Paolo Torino A 3054 ARAGONA Guido Torino A 1882 ARBEZZANO Sisto Vittorio Lanzo Torinese A 3194 ARGENTO Emanuele Trana A 2950 ARIAGNO Fulvio Torino A 1550 ARNAUD Gian Luigi Torino A 5757 ARROBIO Iacopo Dario Sant'Antonino di Susa A 4435 ARTUSO Mario Moncalieri A 3638 ASSALONI Fabio Torrazza Piemonte A 5014 AUDINO Emanuela Torino A 5325 AVERSA Davide Nole A 1826 BAGNUS Elda Pinerolo A 4411 BALBO Riccardo Torino A 2895 BALDIZZONE Valter Avigliana A 1971 BALLESTRACCI Roberto Gassino Torinese A 1090 BALTERI Enrico Torino A 4259 BANCHIO Gianluca Pinerolo A 1714 BARACCA Vittorio Torino A 5317 BARBANO Giuliana Torino A 3098 BARILLA' Giuseppe Susa A 5758 BAROSIO Michela Torino A 5585 BASSO Monica Ivrea A 5335 BECCASIO Luigino Torino A 4655 BECCIU Carlo Torino A 4685 BELLA Andrea Giuseppe Moncalieri A 3494 BELLIARDI Enrico Maria Torino A 4215 BELLINI Elisabetta Torino A 2278 BENCINI Enrico Sauze D'Oulx A 4095 BENEDETTO Laura Strambino A 3077 BERGERETTI Roberto Pinerolo A 4852 BERNARDI