Single-Cell Virtual Cytometer Allows User-Friendly and Versatile Analysis and Visualization of Multimodal Single Cell Rnaseq Datasets
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Human and Mouse CD Marker Handbook Human and Mouse CD Marker Key Markers - Human Key Markers - Mouse
Welcome to More Choice CD Marker Handbook For more information, please visit: Human bdbiosciences.com/eu/go/humancdmarkers Mouse bdbiosciences.com/eu/go/mousecdmarkers Human and Mouse CD Marker Handbook Human and Mouse CD Marker Key Markers - Human Key Markers - Mouse CD3 CD3 CD (cluster of differentiation) molecules are cell surface markers T Cell CD4 CD4 useful for the identification and characterization of leukocytes. The CD CD8 CD8 nomenclature was developed and is maintained through the HLDA (Human Leukocyte Differentiation Antigens) workshop started in 1982. CD45R/B220 CD19 CD19 The goal is to provide standardization of monoclonal antibodies to B Cell CD20 CD22 (B cell activation marker) human antigens across laboratories. To characterize or “workshop” the antibodies, multiple laboratories carry out blind analyses of antibodies. These results independently validate antibody specificity. CD11c CD11c Dendritic Cell CD123 CD123 While the CD nomenclature has been developed for use with human antigens, it is applied to corresponding mouse antigens as well as antigens from other species. However, the mouse and other species NK Cell CD56 CD335 (NKp46) antibodies are not tested by HLDA. Human CD markers were reviewed by the HLDA. New CD markers Stem Cell/ CD34 CD34 were established at the HLDA9 meeting held in Barcelona in 2010. For Precursor hematopoetic stem cell only hematopoetic stem cell only additional information and CD markers please visit www.hcdm.org. Macrophage/ CD14 CD11b/ Mac-1 Monocyte CD33 Ly-71 (F4/80) CD66b Granulocyte CD66b Gr-1/Ly6G Ly6C CD41 CD41 CD61 (Integrin b3) CD61 Platelet CD9 CD62 CD62P (activated platelets) CD235a CD235a Erythrocyte Ter-119 CD146 MECA-32 CD106 CD146 Endothelial Cell CD31 CD62E (activated endothelial cells) Epithelial Cell CD236 CD326 (EPCAM1) For Research Use Only. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -
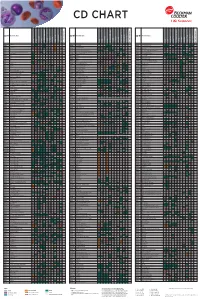
Flow Reagents Single Color Antibodies CD Chart
CD CHART CD N° Alternative Name CD N° Alternative Name CD N° Alternative Name Beckman Coulter Clone Beckman Coulter Clone Beckman Coulter Clone T Cells B Cells Granulocytes NK Cells Macrophages/Monocytes Platelets Erythrocytes Stem Cells Dendritic Cells Endothelial Cells Epithelial Cells T Cells B Cells Granulocytes NK Cells Macrophages/Monocytes Platelets Erythrocytes Stem Cells Dendritic Cells Endothelial Cells Epithelial Cells T Cells B Cells Granulocytes NK Cells Macrophages/Monocytes Platelets Erythrocytes Stem Cells Dendritic Cells Endothelial Cells Epithelial Cells CD1a T6, R4, HTA1 Act p n n p n n S l CD99 MIC2 gene product, E2 p p p CD223 LAG-3 (Lymphocyte activation gene 3) Act n Act p n CD1b R1 Act p n n p n n S CD99R restricted CD99 p p CD224 GGT (γ-glutamyl transferase) p p p p p p CD1c R7, M241 Act S n n p n n S l CD100 SEMA4D (semaphorin 4D) p Low p p p n n CD225 Leu13, interferon induced transmembrane protein 1 (IFITM1). p p p p p CD1d R3 Act S n n Low n n S Intest CD101 V7, P126 Act n p n p n n p CD226 DNAM-1, PTA-1 Act n Act Act Act n p n CD1e R2 n n n n S CD102 ICAM-2 (intercellular adhesion molecule-2) p p n p Folli p CD227 MUC1, mucin 1, episialin, PUM, PEM, EMA, DF3, H23 Act p CD2 T11; Tp50; sheep red blood cell (SRBC) receptor; LFA-2 p S n p n n l CD103 HML-1 (human mucosal lymphocytes antigen 1), integrin aE chain S n n n n n n n l CD228 Melanotransferrin (MT), p97 p p CD3 T3, CD3 complex p n n n n n n n n n l CD104 integrin b4 chain; TSP-1180 n n n n n n n p p CD229 Ly9, T-lymphocyte surface antigen p p n p n -

Anti-GPRC5D/CD3 Bispecific T Cell-Redirecting Antibody for the Treatment of Multiple Myeloma
Author Manuscript Published OnlineFirst on July 3, 2019; DOI: 10.1158/1535-7163.MCT-18-1216 Author manuscripts have been peer reviewed and accepted for publication but have not yet been edited. MCT-18-1216R1, Molecular Cancer Therapeutics, T. Kodama et al. Anti-GPRC5D/CD3 bispecific T cell-redirecting antibody for the treatment of multiple myeloma Tatsushi Kodama1, 2, Yu Kochi3, Waka Nakai2, Hideaki Mizuno2, Takeshi Baba2, Kiyoshi Habu2, Noriaki Sawada2, Hiroyuki Tsunoda2, Takahiro Shima3, Kohta Miyawaki3, Yoshikane Kikushige3, Yasuo Mori3, Toshihiro Miyamoto3, Takahiro Maeda4, and Koichi Akashi3, 4 Authors' Affiliations: 1Chugai Pharmabody Research Pte. Ltd., Singapore, 2Research Division, Chugai Pharmaceutical Co., Ltd., Kamakura, Kanagawa, Japan, 3Department of Medicine and Biosystemic Science, Kyushu University Graduate School of Medical Sciences, Fukuoka, Japan, 4Center for Cellular and Molecular Medicine, Kyushu University Hospital, Fukuoka, Japan Corresponding Authors: Tatsushi Kodama, Chugai Pharmabody Research Pte. Ltd., 3 Biopolis Drive, #07-11 to 16, Synapse, 138623, Singapore; Phone: + 65-6933-4860; Fax: + 65-6684-2257; E-mail: [email protected] Running Title: Anti-GPRC5D/CD3 bispecific T cell-redirecting antibody Keywords: GPRC5D, bispecific T cell-redirecting antibody, multiple myeloma Financial information: This study was funded by Chugai Pharmaceutical Co., Ltd. Conflict of interest statement: Tatsushi Kodama, Waka Nakai, Hideaki Mizuno, Takeshi Baba, Kiyoshi Habu, Noriaki Sawada, and Hiroyuki Tsunoda are employees of Chugai 1 Downloaded from mct.aacrjournals.org on September 24, 2021. © 2019 American Association for Cancer Research. Author Manuscript Published OnlineFirst on July 3, 2019; DOI: 10.1158/1535-7163.MCT-18-1216 Author manuscripts have been peer reviewed and accepted for publication but have not yet been edited. -

NICU Gene List Generator.Xlsx
Neonatal Crisis Sequencing Panel Gene List Genes: A2ML1 - B3GLCT A2ML1 ADAMTS9 ALG1 ARHGEF15 AAAS ADAMTSL2 ALG11 ARHGEF9 AARS1 ADAR ALG12 ARID1A AARS2 ADARB1 ALG13 ARID1B ABAT ADCY6 ALG14 ARID2 ABCA12 ADD3 ALG2 ARL13B ABCA3 ADGRG1 ALG3 ARL6 ABCA4 ADGRV1 ALG6 ARMC9 ABCB11 ADK ALG8 ARPC1B ABCB4 ADNP ALG9 ARSA ABCC6 ADPRS ALK ARSL ABCC8 ADSL ALMS1 ARX ABCC9 AEBP1 ALOX12B ASAH1 ABCD1 AFF3 ALOXE3 ASCC1 ABCD3 AFF4 ALPK3 ASH1L ABCD4 AFG3L2 ALPL ASL ABHD5 AGA ALS2 ASNS ACAD8 AGK ALX3 ASPA ACAD9 AGL ALX4 ASPM ACADM AGPS AMELX ASS1 ACADS AGRN AMER1 ASXL1 ACADSB AGT AMH ASXL3 ACADVL AGTPBP1 AMHR2 ATAD1 ACAN AGTR1 AMN ATL1 ACAT1 AGXT AMPD2 ATM ACE AHCY AMT ATP1A1 ACO2 AHDC1 ANK1 ATP1A2 ACOX1 AHI1 ANK2 ATP1A3 ACP5 AIFM1 ANKH ATP2A1 ACSF3 AIMP1 ANKLE2 ATP5F1A ACTA1 AIMP2 ANKRD11 ATP5F1D ACTA2 AIRE ANKRD26 ATP5F1E ACTB AKAP9 ANTXR2 ATP6V0A2 ACTC1 AKR1D1 AP1S2 ATP6V1B1 ACTG1 AKT2 AP2S1 ATP7A ACTG2 AKT3 AP3B1 ATP8A2 ACTL6B ALAS2 AP3B2 ATP8B1 ACTN1 ALB AP4B1 ATPAF2 ACTN2 ALDH18A1 AP4M1 ATR ACTN4 ALDH1A3 AP4S1 ATRX ACVR1 ALDH3A2 APC AUH ACVRL1 ALDH4A1 APTX AVPR2 ACY1 ALDH5A1 AR B3GALNT2 ADA ALDH6A1 ARFGEF2 B3GALT6 ADAMTS13 ALDH7A1 ARG1 B3GAT3 ADAMTS2 ALDOB ARHGAP31 B3GLCT Updated: 03/15/2021; v.3.6 1 Neonatal Crisis Sequencing Panel Gene List Genes: B4GALT1 - COL11A2 B4GALT1 C1QBP CD3G CHKB B4GALT7 C3 CD40LG CHMP1A B4GAT1 CA2 CD59 CHRNA1 B9D1 CA5A CD70 CHRNB1 B9D2 CACNA1A CD96 CHRND BAAT CACNA1C CDAN1 CHRNE BBIP1 CACNA1D CDC42 CHRNG BBS1 CACNA1E CDH1 CHST14 BBS10 CACNA1F CDH2 CHST3 BBS12 CACNA1G CDK10 CHUK BBS2 CACNA2D2 CDK13 CILK1 BBS4 CACNB2 CDK5RAP2 -

CD Markers Are Routinely Used for the Immunophenotyping of Cells
ptglab.com 1 CD MARKER ANTIBODIES www.ptglab.com Introduction The cluster of differentiation (abbreviated as CD) is a protocol used for the identification and investigation of cell surface molecules. So-called CD markers are routinely used for the immunophenotyping of cells. Despite this use, they are not limited to roles in the immune system and perform a variety of roles in cell differentiation, adhesion, migration, blood clotting, gamete fertilization, amino acid transport and apoptosis, among many others. As such, Proteintech’s mini catalog featuring its antibodies targeting CD markers is applicable to a wide range of research disciplines. PRODUCT FOCUS PECAM1 Platelet endothelial cell adhesion of blood vessels – making up a large portion molecule-1 (PECAM1), also known as cluster of its intracellular junctions. PECAM-1 is also CD Number of differentiation 31 (CD31), is a member of present on the surface of hematopoietic the immunoglobulin gene superfamily of cell cells and immune cells including platelets, CD31 adhesion molecules. It is highly expressed monocytes, neutrophils, natural killer cells, on the surface of the endothelium – the thin megakaryocytes and some types of T-cell. Catalog Number layer of endothelial cells lining the interior 11256-1-AP Type Rabbit Polyclonal Applications ELISA, FC, IF, IHC, IP, WB 16 Publications Immunohistochemical of paraffin-embedded Figure 1: Immunofluorescence staining human hepatocirrhosis using PECAM1, CD31 of PECAM1 (11256-1-AP), Alexa 488 goat antibody (11265-1-AP) at a dilution of 1:50 anti-rabbit (green), and smooth muscle KD/KO Validated (40x objective). alpha-actin (red), courtesy of Nicola Smart. PECAM1: Customer Testimonial Nicola Smart, a cardiovascular researcher “As you can see [the immunostaining] is and a group leader at the University of extremely clean and specific [and] displays Oxford, has said of the PECAM1 antibody strong intercellular junction expression, (11265-1-AP) that it “worked beautifully as expected for a cell adhesion molecule.” on every occasion I’ve tried it.” Proteintech thanks Dr. -
Cldn19 Clic2 Clmp Cln3
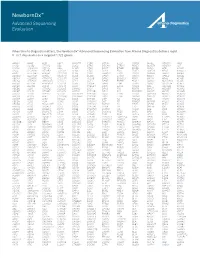
NewbornDx™ Advanced Sequencing Evaluation When time to diagnosis matters, the NewbornDx™ Advanced Sequencing Evaluation from Athena Diagnostics delivers rapid, 5- to 7-day results on a targeted 1,722-genes. A2ML1 ALAD ATM CAV1 CLDN19 CTNS DOCK7 ETFB FOXC2 GLUL HOXC13 JAK3 AAAS ALAS2 ATP1A2 CBL CLIC2 CTRC DOCK8 ETFDH FOXE1 GLYCTK HOXD13 JUP AARS2 ALDH18A1 ATP1A3 CBS CLMP CTSA DOK7 ETHE1 FOXE3 GM2A HPD KANK1 AASS ALDH1A2 ATP2B3 CC2D2A CLN3 CTSD DOLK EVC FOXF1 GMPPA HPGD K ANSL1 ABAT ALDH3A2 ATP5A1 CCDC103 CLN5 CTSK DPAGT1 EVC2 FOXG1 GMPPB HPRT1 KAT6B ABCA12 ALDH4A1 ATP5E CCDC114 CLN6 CUBN DPM1 EXOC4 FOXH1 GNA11 HPSE2 KCNA2 ABCA3 ALDH5A1 ATP6AP2 CCDC151 CLN8 CUL4B DPM2 EXOSC3 FOXI1 GNAI3 HRAS KCNB1 ABCA4 ALDH7A1 ATP6V0A2 CCDC22 CLP1 CUL7 DPM3 EXPH5 FOXL2 GNAO1 HSD17B10 KCND2 ABCB11 ALDOA ATP6V1B1 CCDC39 CLPB CXCR4 DPP6 EYA1 FOXP1 GNAS HSD17B4 KCNE1 ABCB4 ALDOB ATP7A CCDC40 CLPP CYB5R3 DPYD EZH2 FOXP2 GNE HSD3B2 KCNE2 ABCB6 ALG1 ATP8A2 CCDC65 CNNM2 CYC1 DPYS F10 FOXP3 GNMT HSD3B7 KCNH2 ABCB7 ALG11 ATP8B1 CCDC78 CNTN1 CYP11B1 DRC1 F11 FOXRED1 GNPAT HSPD1 KCNH5 ABCC2 ALG12 ATPAF2 CCDC8 CNTNAP1 CYP11B2 DSC2 F13A1 FRAS1 GNPTAB HSPG2 KCNJ10 ABCC8 ALG13 ATR CCDC88C CNTNAP2 CYP17A1 DSG1 F13B FREM1 GNPTG HUWE1 KCNJ11 ABCC9 ALG14 ATRX CCND2 COA5 CYP1B1 DSP F2 FREM2 GNS HYDIN KCNJ13 ABCD3 ALG2 AUH CCNO COG1 CYP24A1 DST F5 FRMD7 GORAB HYLS1 KCNJ2 ABCD4 ALG3 B3GALNT2 CCS COG4 CYP26C1 DSTYK F7 FTCD GP1BA IBA57 KCNJ5 ABHD5 ALG6 B3GAT3 CCT5 COG5 CYP27A1 DTNA F8 FTO GP1BB ICK KCNJ8 ACAD8 ALG8 B3GLCT CD151 COG6 CYP27B1 DUOX2 F9 FUCA1 GP6 ICOS KCNK3 ACAD9 ALG9 -

Early Growth Response 1 Regulates Hematopoietic Support and Proliferation in Human Primary Bone Marrow Stromal Cells
Hematopoiesis SUPPLEMENTARY APPENDIX Early growth response 1 regulates hematopoietic support and proliferation in human primary bone marrow stromal cells Hongzhe Li, 1,2 Hooi-Ching Lim, 1,2 Dimitra Zacharaki, 1,2 Xiaojie Xian, 2,3 Keane J.G. Kenswil, 4 Sandro Bräunig, 1,2 Marc H.G.P. Raaijmakers, 4 Niels-Bjarne Woods, 2,3 Jenny Hansson, 1,2 and Stefan Scheding 1,2,5 1Division of Molecular Hematology, Department of Laboratory Medicine, Lund University, Lund, Sweden; 2Lund Stem Cell Center, Depart - ment of Laboratory Medicine, Lund University, Lund, Sweden; 3Division of Molecular Medicine and Gene Therapy, Department of Labora - tory Medicine, Lund University, Lund, Sweden; 4Department of Hematology, Erasmus MC Cancer Institute, Rotterdam, the Netherlands and 5Department of Hematology, Skåne University Hospital Lund, Skåne, Sweden ©2020 Ferrata Storti Foundation. This is an open-access paper. doi:10.3324/haematol. 2019.216648 Received: January 14, 2019. Accepted: July 19, 2019. Pre-published: August 1, 2019. Correspondence: STEFAN SCHEDING - [email protected] Li et al.: Supplemental data 1. Supplemental Materials and Methods BM-MNC isolation Bone marrow mononuclear cells (BM-MNC) from BM aspiration samples were isolated by density gradient centrifugation (LSM 1077 Lymphocyte, PAA, Pasching, Austria) either with or without prior incubation with RosetteSep Human Mesenchymal Stem Cell Enrichment Cocktail (STEMCELL Technologies, Vancouver, Canada) for lineage depletion (CD3, CD14, CD19, CD38, CD66b, glycophorin A). BM-MNCs from fetal long bones and adult hip bones were isolated as reported previously 1 by gently crushing bones (femora, tibiae, fibulae, humeri, radii and ulna) in PBS+0.5% FCS subsequent passing of the cell suspension through a 40-µm filter. -

For Analyst. This Journal Is © the Royal Society of Chemistry 2019
Electronic Supplementary Material (ESI) for Analyst. This journal is © The Royal Society of Chemistry 2019 Title: Single-cell RNA-sequencing of migratory breast cancer cells: discovering genes associated with cancer metastasis Authors and affiliations: Yu-Chih Chen1, 2, Saswat Sahoo3, Riley Brien1, Seungwon Jung1, Brock Humphries4, Woncheol Lee1, Yu-Heng Cheng1, Zhixiong Zhang1, Kathryn E. Luker4, Max S. Wicha2, Gary D. Luker3,4,5, and Euisik Yoon*1, 3, 6 1 Department of Electrical Engineering and Computer Science, University of Michigan, 1301 Beal Avenue, Ann Arbor, MI 48109-2122; 2 Forbes Institute for Cancer Discovery, University of Michigan, 2800 Plymouth Rd., Ann Arbor, MI 48109, USA; 3 Department of Biomedical Engineering, University of Michigan, 2200 Bonisteel, Blvd. Ann Arbor, MI 48109-2099, USA 4 Center for Molecular Imaging, Department of Radiology, University of Michigan, 109 Zina Pitcher Place, Ann Arbor, MI 48109-2200, USA; 5 Department of Microbiology and Immunology, University of Michigan, 109 Zina Pitcher Place, Ann Arbor, MI 48109-2200, USA; 6 Center for Nanomedicine, Institute for Basic Science (IBS) and Graduate Program of Nano Biomedical Engineering (Nano BME), Yonsei University, Seoul 03722, Korea. *Corresponding authors Yu-Chih Chen 1301 Beal Avenue, Ann Arbor, MI 48109-2122, USA Tel: 734-272-7113; E-mail: [email protected]. Euisik Yoon 1301 Beal Avenue, Ann Arbor, MI 48109-2122, USA Tel: 734-615-4469; E-mail: [email protected]. Keywords: Cell Migration; RNA-Seq; Single Cell; Microfluidics; Cancer Metastasis. 1 Supplementary Table 1. Top-ranked 50 pathways (NCI-Nature pathway database) of migratory MDA-MB-231 cells as compared to wild-type ones. -

The Path to an Orally Administered Protein Therapeutic for the Treatment of Diabetes Mellitus
Syracuse University SURFACE Chemistry - Dissertations College of Arts and Sciences 12-2012 The Path to an Orally Administered Protein Therapeutic for the Treatment of Diabetes Mellitus Susan Clardy James Syracuse University Follow this and additional works at: https://surface.syr.edu/che_etd Part of the Chemistry Commons Recommended Citation James, Susan Clardy, "The Path to an Orally Administered Protein Therapeutic for the Treatment of Diabetes Mellitus" (2012). Chemistry - Dissertations. 196. https://surface.syr.edu/che_etd/196 This Dissertation is brought to you for free and open access by the College of Arts and Sciences at SURFACE. It has been accepted for inclusion in Chemistry - Dissertations by an authorized administrator of SURFACE. For more information, please contact [email protected]. Abstract Protein therapeutics like insulin and glucagon-like peptide-1 analogues are currently used as injectable medications for the treatment of diabetes mellitus. An orally administered protein therapeutic is predicted to increase patient adherence to medication and bring a patient closer to metabolic norms through direct effects on hepatic glucose production. The major problem facing oral delivery of protein therapeutics is gastrointestinal tract hydrolysis/proteolysis and the inability to passage the enterocyte. Herein we report the potential use of vitamin B12 for the oral delivery of protein therapeutics. We first investigated the ability of insulin to accommodate the attachment of B12 at the B1 vs. B29 amino acid position. The insulinotropic profile of both conjugates was evaluated in streptozotocin induced diabetic rats. Oral administration of the conjugates produced significant drops in blood glucose levels, compared to an orally administered insulin control, but no significant difference was observed between conjugates. -

Saporin Conjugated Monoclonal Antibody to the Transcobalamin Receptor Tcblr/CD320 Is Effective in Targeting and Destroying Cancer Cells
Journal of Cancer Therapy, 2013, 4, 1074-1081 http://dx.doi.org/10.4236/jct.2013.46122 Published Online August 2013 (http://www.scirp.org/journal/jct) Saporin Conjugated Monoclonal Antibody to the Transcobalamin Receptor TCblR/CD320 Is Effective in Targeting and Destroying Cancer Cells Edward V. Quadros1,2, Yasumi Nakayama1, Jeffrey M. Sequeira1 1Department of Medicine, SUNY-Downstate Medical Center, Brooklyn, USA; 2Department Cell Biology, SUNY-Downstate Medical Center, Brooklyn, USA. Email: [email protected] Received May 29th, 2013; revised June 30th, 2013; accepted July 8th, 2013 Copyright © 2013 Edward V. Quadros et al. This is an open access article distributed under the Creative Commons Attribution Li- cense, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. ABSTRACT Cobalamin uptake into cells is mediated by the CD320 receptor for transcobalamin-bound cobalamin. Optimum recep- tor expression is associated with proliferating cells and therefore, in many cancers this receptor expression is up regu- lated. Delivering drugs or toxins via this receptor provides increased targeting to cancer cells while minimizing toxicity to the normal tissues. Saporin conjugated monoclonal antibodies to the extracellular domain of TCblR were effectively internalized to deliver a toxic dose of Saporin to some cancer cell lines propagating in culture. Antibody concentration of 2.5 nM was effective in producing optimum inhibition of cell proliferation. The cytotoxic effect of mAb-Saporin appears to be dictated primarily by the level of receptor expression and therefore normal primary cells expressing low levels of CD320 were spared while tumor cell lines with higher CD320 expression were destroyed.